使用 Elasticsearch 跨集群复制进行跨数据中心复制
长期以来,对于 Elasticsearch 上的任务关键型应用程序而言,跨数据中心复制一直都是一项硬性要求,之前通过利用其他技术这一问题部分得到了解决。在 Elasticsearch 6.7 中引入跨集群复制后,无需再依赖其他技术便可跨数据中心、跨地区或者跨 Elasticsearch 集群来复制数据。
跨集群复制 (CCR) 功能支持将特定索引从一个 ElasticSearch 集群复制到一个或多个 ElasticSearch 集群。除了跨数据中心复制之外,CCR 还有许多其他用例,包括数据本地化(将数据复制到距离用户/应用程序服务器更近的位置,例如,将产品目录复制到全球 20 个不同的数据中心),或者将数据从 Elasticsearch 集群复制到中央报告集群(例如,全球 1000 家银行分行都向其本地 Elasticsearch 集群写入数据,并复制回总部的集群用于报告)。
在本教程中,针对如何使用 CCR 进行跨数据中心复制,我们将简要介绍 CCR 基础知识,重点介绍架构选项和权衡事项,配置跨数据中心部署样例,并着重介绍一些管理命令。有关 CCR 技术层面的介绍,请参阅追随领导者:Elasticsearch 中的跨集群复制简介。
CCR 是一项白金级功能,可通过 30 天试用许可证进行体验,该许可证可通过开始试用 API 激活,也可以直接从 Kibana 激活。
跨集群复制 (CCR) 基础知识
复制是在索引级别(或基于索引模式)配置的
CCR 是在 Elasticsearch 中的索引级别配置的。通过在索引级别配置复制,可以使用大量的复制策略,包括一些索引在一个方向复制,一些索引在另一个方向复制,以及细粒度的跨数据中心架构。
复制索引是只读的
索引可以由一个或多个 Elasticsearch 集群进行复制。每个复制索引的集群都维护一份索引的只读副本。能够接受写操作的主动索引称为领导者。索引的被动只读副本称为追随者。并不存在选举新领导者的概念,因此,当领导者索引不可用(如集群/数据中心中断)时,应用程序管理员或集群管理员必须为写入显式选择另一个索引,而这个索引很可能位于另一个集群中。
CCR 的默认值适用于各种高吞吐量用例
如果不十分了解调整值会对系统产生怎样的影响,则不建议更改默认值。 大多数选项可在 Create follower API 中找到,例如“max_read_request_operation_count”或“max_retry_delay”。我们很快会发布一篇文章,专门介绍如何针对独特的工作负载调优这些参数。
安全性要求
如 CCR 入门指南中所述,源集群中的用户必须具有“read_ccr”集群特权,以及“monitor”和“read”索引特权。在目标集群中,用户必须具有“manage_ccr”集群特权,以及“monitor”、“read”、“write”和“manage_follow_index”索引特权。另外,还可以使用集中身份验证系统,例如 LDAP。
跨数据中心 CCR 架构样例
生产和 DR 数据中心
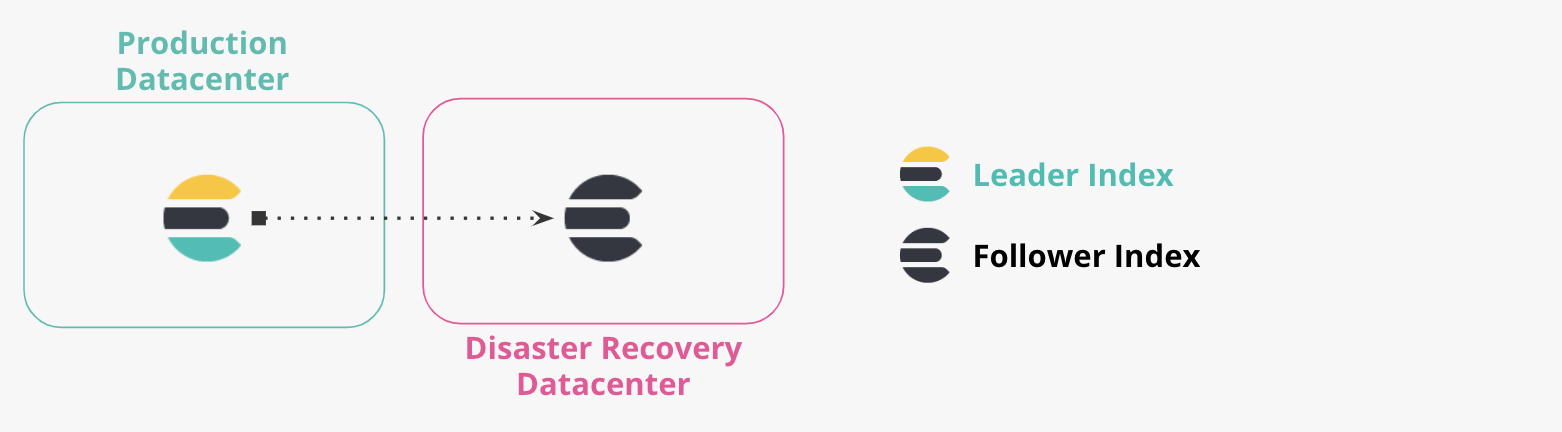
两个以上的数据中心
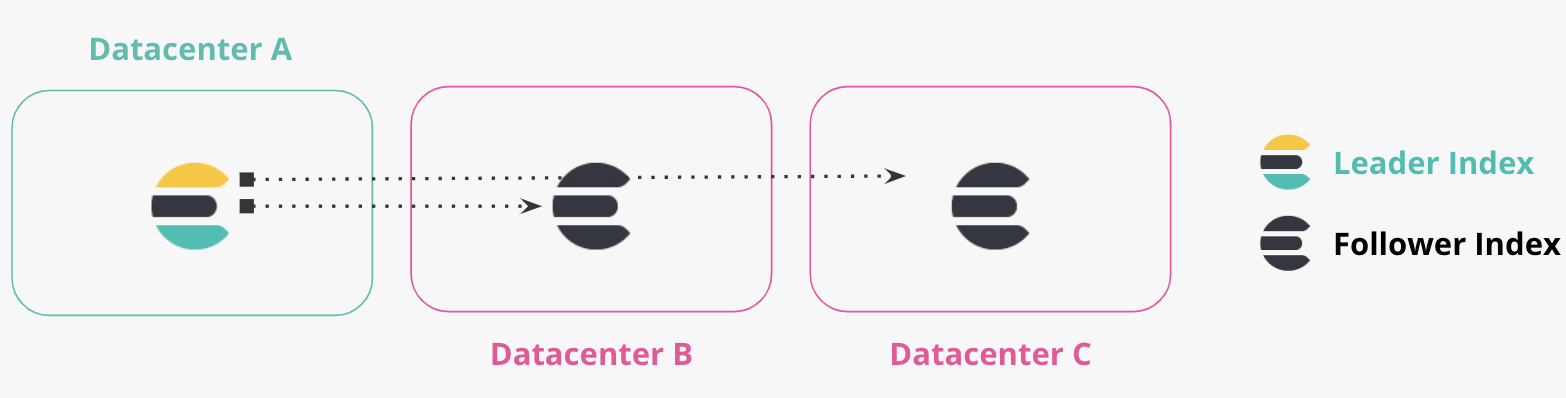
连锁复制
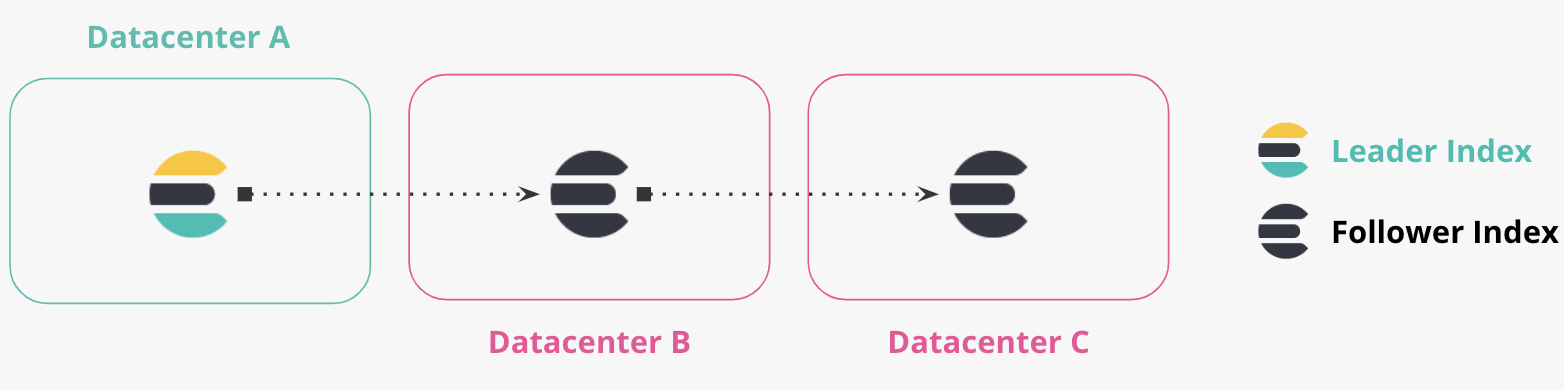
双向复制
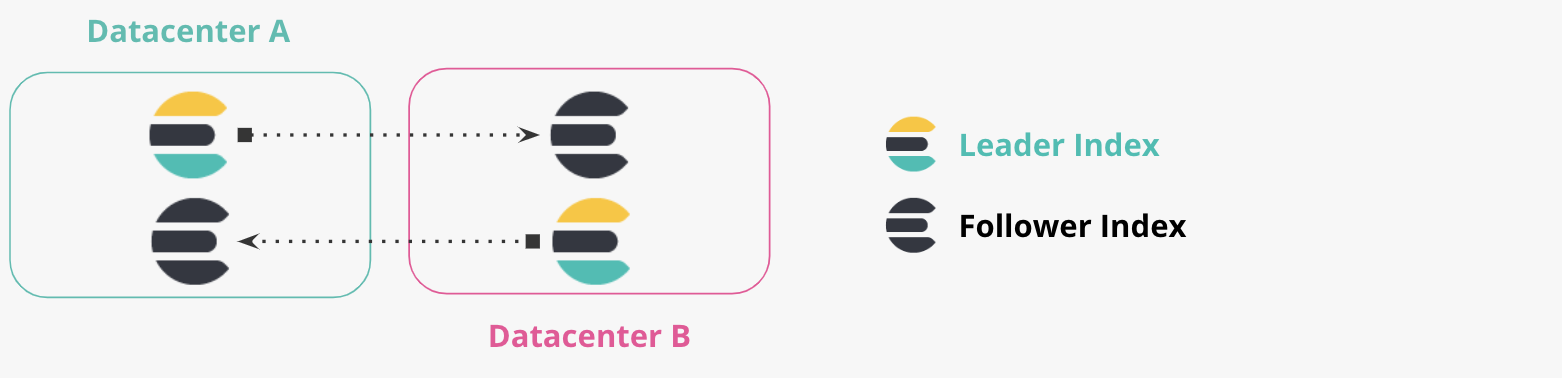
跨数据中心部署教程
1.设置
在本教程中,我们使用的两个集群都位于本地计算机上。您可以将集群随意放在任何喜欢的位置。
- “us-cluster”:这是“美国集群”,将在端口 9200 上本地运行。我们会将文档从美国集群复制到日本集群。
- “japan-cluster”:这是“日本集群”,将在端口 8200 上本地运行。该日本集群将维护一个来自美国集群的复制索引。
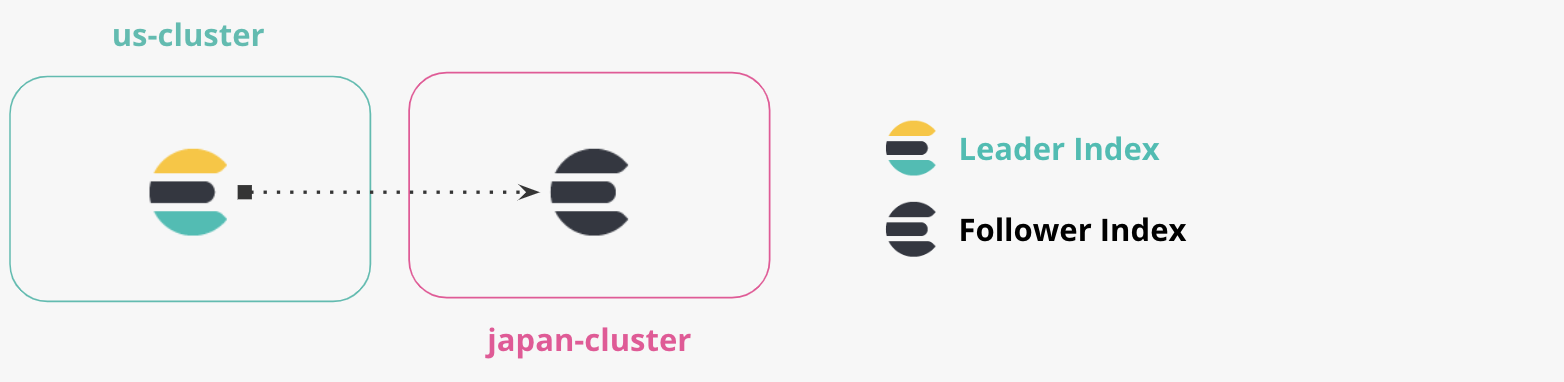
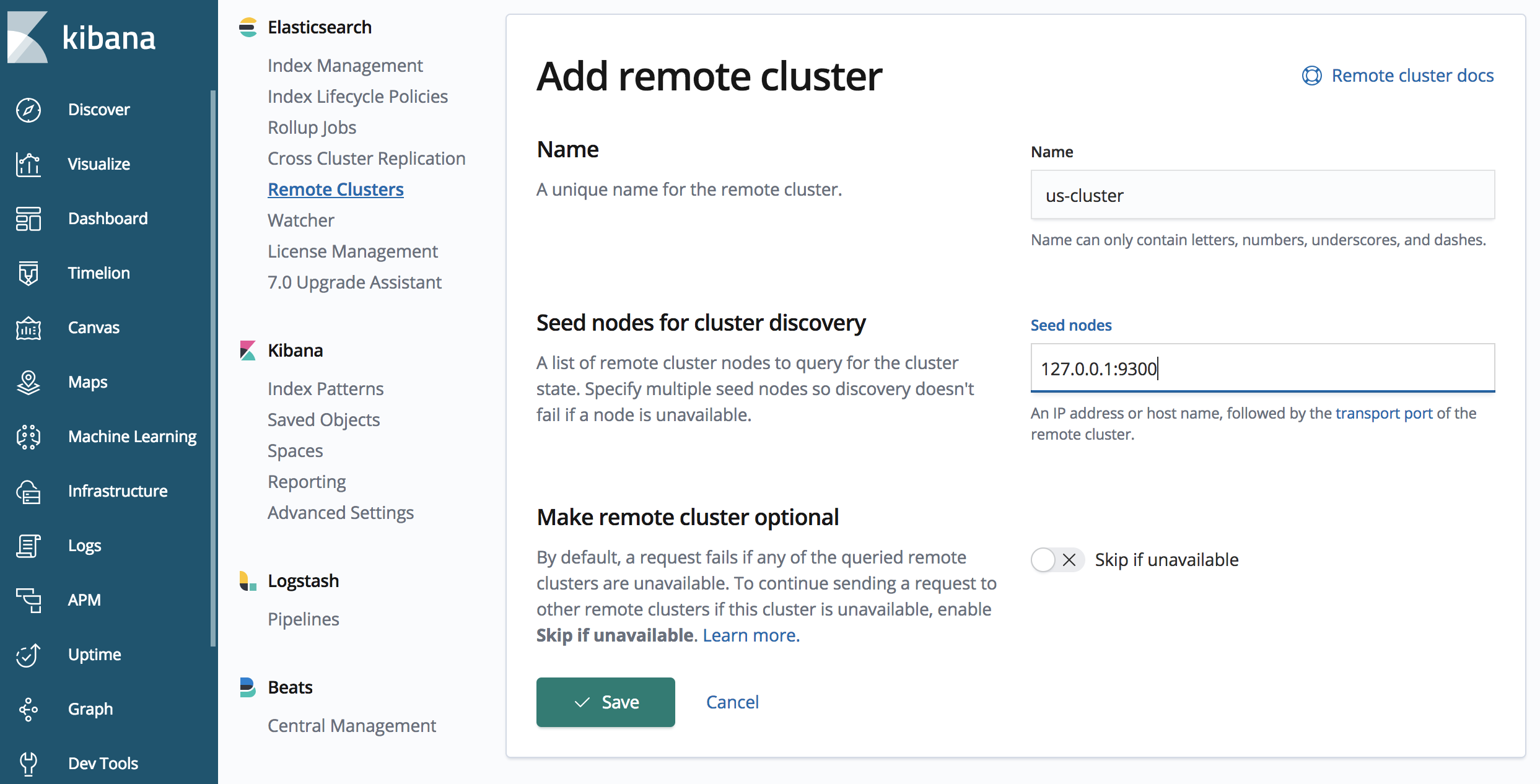
2.定义远程集群
当设置 CCR 时,Elasticsearch 集群必须知道其他 Elasticsearch 集群。这是一个单向要求,因为目标集群将保持与源集群的单向连接。我们将其他 Elasticsearch 集群定义为远程集群,并指定别名来描述它们。
我们需要确保“japan-cluster”知道“us-cluster”。CCR 中的复制是基于拉取模式的,不需要我们指定从“us-cluster”到“japan-cluster”的连接。
下面让我们通过“japan-cluster”上的 API 调用来定义“us-cluster”
# From the japan-cluster, we’ll define how the us-cluster can be accessed
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(对于基于 API 的命令,建议使用 Kibana 中的开发工具控制台,访问路径为:Kibana -> Dev tools(开发工具)-> Console(控制台))
上述 API 调用使用别名“us-cluster”(可从“127.0.0.1:9300”访问)来定义远程集群。可以指定一个或多个种子,通常建议指定多个种子,以免在握手阶段种子不可用。
有关配置远程集群的更多详细信息,请参阅关于定义远程集群的参考文档。
另外,还要注意连接到“us-cluster”的端口 9300,“us-cluster”侦听的是端口 9200 上的 HTTP 协议(这是默认端口,是在 elasticsearch.yml 文件中为“us-cluster”指定的)。但是,复制是使用 Elasticsearch 传输协议(用于节点到节点通信)进行的;默认为端口 9300。
Kibana 中有一个用于远程集群的管理 UI,我们将在本教程中介绍用于 CCR 的 UI 和 API。要在 Kibana 中访问远程集群 UI,请单击左侧导航面板中的“Management”(管理)(齿轮图标),然后导航到 Elasticsearch 部分中的“Remote Clusters”(远程集群)。
3.创建要复制的索引
我们下面在“us-cluster”上创建一个名为“products”的索引,然后将这个索引从源“us-cluster”复制到目标“japan-cluster”:
在“us-cluster”上:
# Create product index
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" :1,
"number_of_replicas" :0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
您可能已注意到“soft_deletes”设置。要使索引用作 CCR 的 Leader 索引,需要使用软删除(有关详细信息,请参阅不知道历史记录的人):
soft_deletes:无论何时删除或更新现有文档,都会发生软删除。通过将这些软删除一直保留到可配置的限度,可以将操作历史记录保留在领导者分片上,并在重新处理操作历史记录时供追随者分片任务使用。
当追随者分片从领导者复制操作时,它会在领导者分片上留下标记,这样领导者就知道追随者在历史记录中的所在位置。这些标记下面的软删除操作可以逐渐消失。基于这些标记,领导者分片将会保留这些操作,直到分片历史记录保留租用期结束(默认为 12 个小时)。此期间确定了追随者在有可能远远落后并需要从领导者处重新引导之前可以离线的时间。
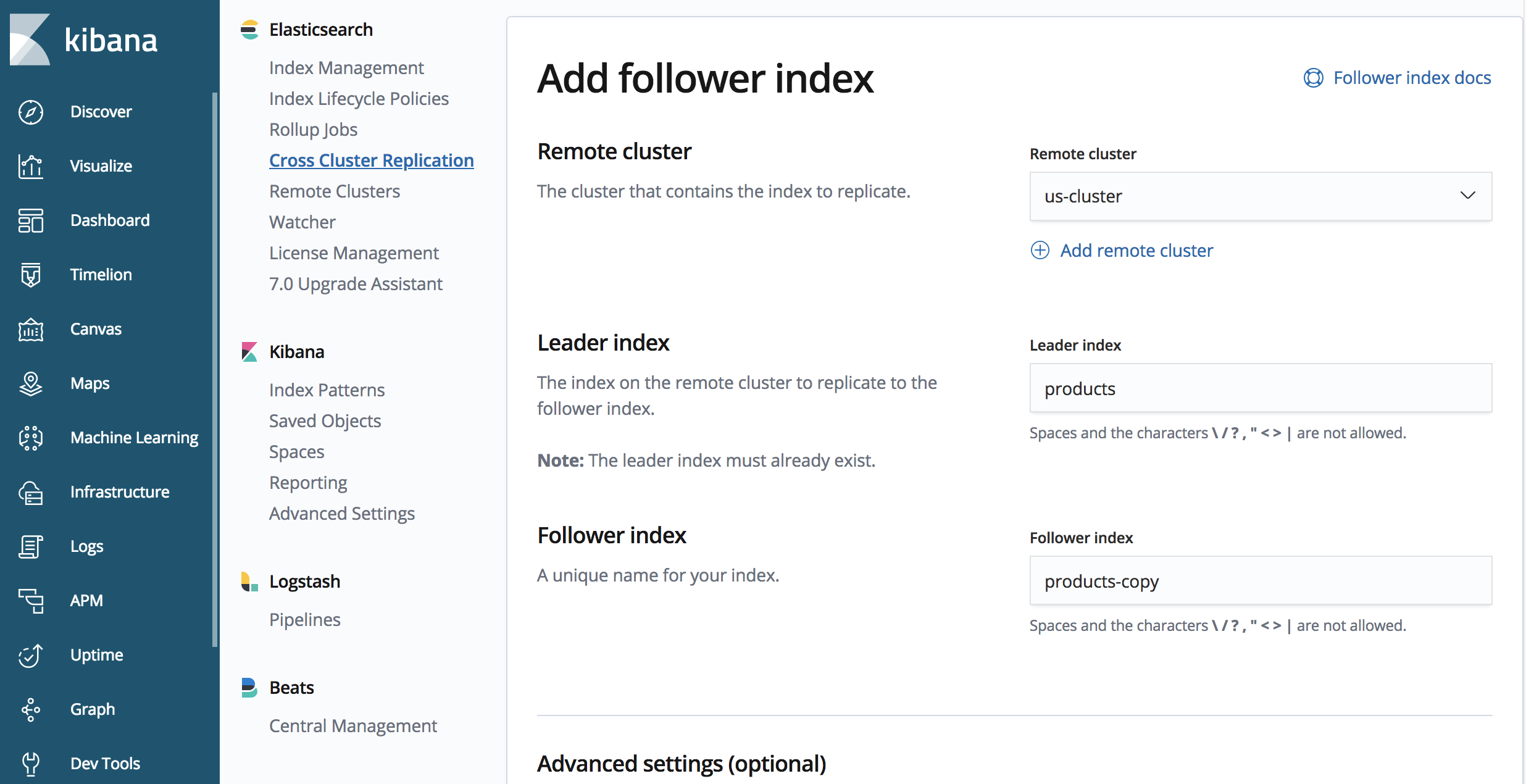
4.启动复制
至此,我们已经为远程集群创建了一个别名,并创建了一个我们要复制的索引,接下来我们启动复制。
在“japan-cluster”上:
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
该端点包含“products-copy”,这是“japan-cluster”集群中复制索引的名称。我们将从以前定义的“us-cluster”集群中进行复制,并且要复制的索引名称在“us-cluster”集群上称为“products”。
请务必注意,复制索引是只读的,不能接受写操作。
好了,就这么简单!我们已配置了要从一个 Elasticsearch 集群复制到另一个集群的索引!
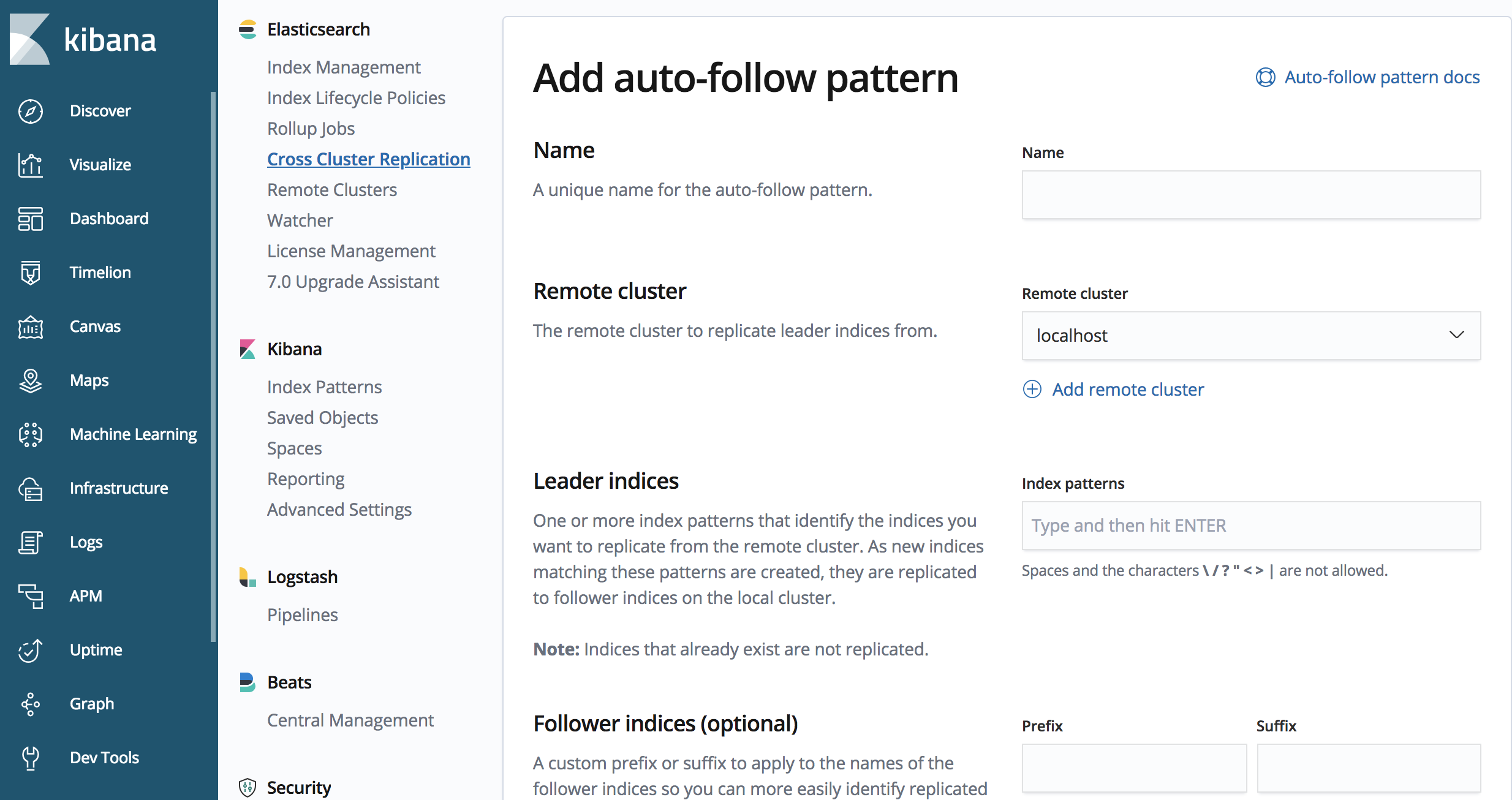
启动索引模式的复制
您可能已经注意到,对于基于时间的用例(即每天都有一个索引)或大量数据来说,上面的示例并不太适合。此外,CCR API 还包含定义自动跟随模式(即应复制哪些索引模式)的方法。
我们可以使用 CCR API 来定义自动跟随模式
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
上面的 API 调用样例将复制开头为“metricbeat”或“packetbeat”的索引。
我们还可以使用 Kibana 中的 CCR UI 来定义自动跟随模式。
5.测试复制设置
至此,我们已经拥有从“us-cluster”复制到“japan-cluster”的产品索引。接下来,我们插入一个测试文档,验证它是否已被复制。
在“us-cluster”集群上:
POST /products/_doc
{
"name" :"My cool new product"
}
现在,我们来查询一下“japan-cluster”,以确保文档已被复制:
GET /products-copy/_search
我们现在应该有一个文档,它是在“us-cluster”上编写的,并复制到“japan-cluster”。
{
"took" :1,
"timed_out" : false,
"_shards" : {
"total" :1,
"successful" :1,
"skipped" :0,
"failed" :0
},
"hits" : {
"total" :1,
"max_score" :1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" :1.0,
"_source" : {
"name" :"My cool new product"
}
}
]
}
}
跨数据中心管理备注
我们下面介绍一下用于 CCR 的一些管理 API、可调设置,并概述在 Elasticsearch 中将复制索引转换为普通索引的方法。
用于复制的管理 API
在 Elasticsearch 中有许多有用的用于 CCR 的管理 API。它们可能有助于调试复制、修改复制设置或收集详细的诊断信息。
# Return all statistics related to CCR
GET /_ccr/stats
# Pause replication for a given index
POST //_ccr/pause_follow
# Resume replication, in most cases after it has been paused
POST //_ccr/resume_follow
{
}
# Unfollow an index (stopping replication for the destination index), which first requires replication to be paused
POST //_ccr/unfollow
# Statistics for a following index
GET //_ccr/stats
# Remove an auto-follow pattern
DELETE /_ccr/auto_follow/
# View all auto-follow patterns, or get an auto-follow pattern by name
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
有关 CCR 管理 API 的更多详细信息,请参阅 Elasticsearch 参考文档。
将追随者索引转换为普通索引
我们可以使用上述管理 API 的子集,将追随者索引转换为在 Elasticsearch 中的能够接受写操作的普通索引。
在上述示例中,我们进行了相当简单的设置。请记住,“japan-cluster”上复制“products-copy”索引是只读的,它不能接受任何写操作。如果希望将“products-copy”索引转换为 Elasticsearch 中的普通索引(能够接受写操作),我们可以执行下列命令。请记住,原始索引(“products”)上的写操作可以继续,在将“products-copy”索引转换为普通 Elasticsearch 索引之前,可能需要先将写操作限定在“products”索引上。
# Pause replication
POST //_ccr/pause_follow
# Close the index
POST /my_index/_close
# Unfollow
POST //_ccr/unfollow
# Open the index
POST /my_index/_open
继续探索 Elasticsearch 中的跨集群复制 (CCR)
我们编写本指南的宗旨是帮助您在 Elasticsearch 中开始使用 CCR,并希望在让您熟悉 CCR、了解各种 CCR API(包括 Kibana 中提供的 UI)和尝试使用该功能方面有所帮助。其他资源包括跨集群复制入门指南和跨集群复制 API 参考指南。
一如既往,请在我们的讨论论坛上留下反馈和问题,我们一定尽快回答。