使用索引生命周期管理实现热温冷架构
注意:不再建议使用本文所描述的节点属性(即 -Enode.attr.data=hot)来实现热温冷架构。Data #tiers 已通过使用 node.roles(即 node.roles: ["data_hot", "data_content"])将这一概念正式确定了下来。请查看 https://www.elastic.co/blog/elasticsearch-data-lifecycle-management-with-data-tiers 了解更新信息。
如果您已经使用节点属性实现了热温冷架构,建议对数据层采用 node.roles,然后使用迁移到数据层 API 或手动转换配置(即 ILM 策略、索引设置、索引模板),以使用数据层首选项。
此外,本文还提到了旧索引模板(即 PUT _template)以及引导索引的需要。旧索引模板已由可组合索引模板(即 PUT /_index_template)取代。如果您使用的是数据流,则无需引导索引。
索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能。ILM 是 Elasticsearch 的一部分,主要用来帮助您管理索引。
在本篇博客中,我们将探讨如何使用 ILM 实现热温冷架构。热温冷架构常用于日志或指标类的时序数据。例如,假设正在使用 Elasticsearch 聚合来自多个系统的日志文件。今天的日志正在频繁地被索引,且本周的日志搜索量最大(热)。上周的日志可能会被频繁搜索,但频率没有本周日志那么高(温)。上月日志的搜索频率可能较高,也可能较低,但最好保留一段时间以防万一(冷)。
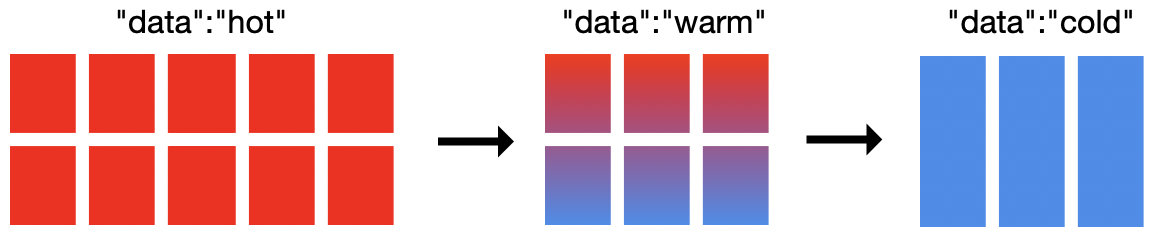
在上图中,这个集群有 19 个节点:10 个热节点、6 个温节点和 3 个冷节点。虽然使用 ILM 实现热温冷架构不需要 19 个节点,但至少需要有 2 个节点。如何确定集群规模取决于您的需求。 冷节点是可选的,它只是多提供一个建模级别来表示数据的存放位置。Elasticsearch 允许您定义哪些节点是热节点、温节点或冷节点。ILM 允许您定义何时在两个阶段之间移动,以及在进入那个阶段时如何处理索引。
对于热温冷架构,没有一成不变的设置。但是,通常而言,热节点需要较多的 CPU 资源和较快的 IO。对于温节点和冷节点来说,通常每个节点会需要更多的磁盘空间,但即便使用较少的 CPU 资源和较慢的 IO 设备,也能勉强应付。
好,我们开始吧……
配置分片分配感知
由于热温冷依赖于分片分配感知,因此,我们首先标记哪些节点是热节点、温节点和(可选)冷节点。此操作可以通过启动参数或在 elasticsearch.yml 配置文件中完成。例如:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(如果您当前使用的是 Elastic Cloud 上的 Elasticsearch 服务,则需要选择随 Elasticsearch 6.7+ 提供的热/温模板)
配置 ILM 策略
接下来,我们需要定义一个 ILM 策略。ILM 策略可以在您选择的任意多个索引中重用。ILM 策略分为四个主要阶段 - 热、温、冷和删除。您不需要在一个策略中定义每个阶段,ILM 会始终按该顺序执行各个阶段(跳过任何未定义的阶段)。对于每个阶段,您都需要定义进入该阶段的时间,还需要定义一组操作来按照您认为合适的方式管理索引。对于热温冷架构,您可以配置分配操作,将数据从热节点移动到温节点,继而再从温节点移动到冷节点。
除了在热温冷节点之间移动数据外,您还可以配置许多附加操作。滚动更新操作用于管理每个索引的大小或寿命。强制合并操作可用于优化索引。冻结操作可用于减少集群中的内存压力。此外,还有许多其他操作;请参考适用于您的 Elasticsearch 版本的文档,以了解可供使用的操作。
基本 ILM 策略
下面我们来看一个非常基本的 ILM 策略:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
这个策略规定,在索引存储时间达到 30 天后或者索引大小达到 50GB(基于主分片)时,就会滚动更新该索引并开始写入一个新索引。
ILM 和索引模板
接下来,我们需要将这个 ILM 策略与索引模板关联起来:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
注意:当使用滚动更新操作在索引模板中(而不是直接在索引上)指定 ILM 策略时,必需进行此关联。
对于包括滚动更新操作的策略,您还必须在创建索引模板后使用写入别名启动索引。
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
假设进行滚动更新的所有要求均得到正确满足,任何以 test-* 开头的新索引将在 30 天后或达到 50GB 时自动滚动更新。通过使用滚动更新管理以 max_size 开头的索引后,可以极大减少索引的分片数量,进而减少开销。
配置用于采集的 ILM 策略
Beats 和 Logstash 都支持 ILM,并在启用后将设置一个类似上例所示的默认策略。此外,Beats 和 Logstash 还将处理滚动更新操作的所有要求。这就意味着,当为 Beats 和 Logstash 启用 ILM 时,除非您的每天索引量很大(大于 50GB/天),否则索引大小将可能是确定何时创建新索引的主要因素(这是一件好事!)。从 7.0.0 开始,带有滚动更新的 ILM 将是 Beats 和 Logstash 的默认配置。
不过,由于针对热温冷架构没有一成不变的设置,因此,Beats 和 Logstash 将不会随附热温冷策略。我们可以制定一个适用于热温冷的新策略,并在这一过程中进行一些优化。
我们虽然可以更新 Beats 或 Logstash 默认策略,但这会模糊默认值和定制值之间的界限。此外,更新默认策略还会增加未来版本无法应用正确策略的风险*(7.0+ 的 Beats 模板默认值将会有更改)*。我们可以使用 Beats 和 Logstash 配置,通过其各自的配置来定义定制策略。这种方法也未尝不可,但您可能需要更改数百(或数千)个 Beats 的配置才能更改 ILM 策略。这里描述的第三种方法,通过利用多模板匹配来允许 Elasticsearch 保持对 ILM 策略的完全控制。
针对热温冷优化 ILM 策略
首先,让我们创建一个针对热温冷架构优化的 ILM 策略。再次强调,这不是一刀切的设置,您的要求将有所不同。
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority":50
}
}
},
"warm": {
"min_age":"7d",
"actions": {
"forcemerge": {
"max_num_segments":1
},
"shrink": {
"number_of_shards":1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority":25
}
}
},
"cold": {
"min_age":"30d",
"actions": {
"set_priority": {
"priority":0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age":"60d",
"actions": {
"delete": {}
}
}
}
}
}
热
这个 ILM 策略首先会将索引优先级设置为一个较高的值,以便热索引在其他索引之前恢复。30 天后或达到 50GB 时(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引。该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 7 天再进入温阶段。
温
索引进入温阶段后,ILM 会将索引收缩到 1 个分片,将索引强制合并为 1 个段,并将索引优先级设置为比热阶段低(但比冷阶段高)的值,通过分配操作将索引移动到温节点。完成该操作后,索引将等待 30 天(从滚动更新时算起)后进入冷阶段。
冷
索引进入冷阶段后,ILM 将再次降低索引优先级,以确保热索引和温索引得到先行恢复。然后,ILM 将冻结索引并将其移动到冷节点。完成该操作后,索引将等待 60 天(从滚动更新时算起)后进入删除阶段。
删除
我们还没有讨论过这个删除阶段。简单来说,删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
在 Kibana 中创建 ILM 策略
不喜欢写一大堆 JSON? (我也是。) 让我们使用 Kibana UI 来检查或创建策略:
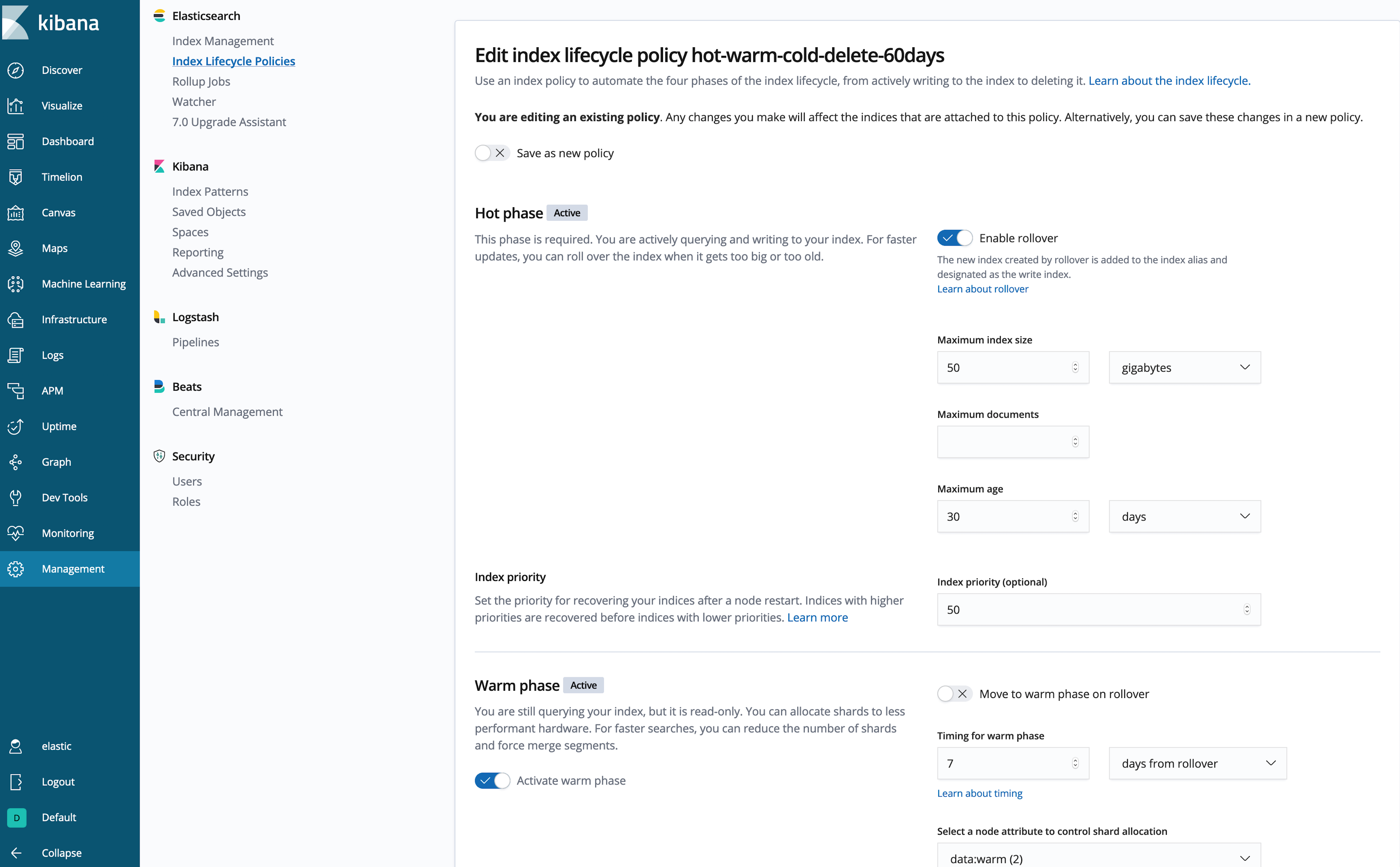 这样好多了!
这样好多了!
现在,我们需要将这个新的 hot-warm-cold-delete-60days 策略与 Beats 和 Logstash 索引关联起来,确保它们写入 hot 数据节点。由于 Beats 和 Logstash 都会默认管理其自己的模板,因此,我们将使用多模板匹配,为您要应用 ILM 策略的索引模式添加策略和分配规则。因为这个模板匹配 Beats 和 Logstash 索引模式,所以您需要知道想要匹配的索引模式。在这里,我们使用 logstash-、metricbeat- 和 filebeat-*,假设 Beats 和 Logstash 在其配置中启用了 ILM 支持,您可以在此添加任意数量的索引模式。如果在此处为不支持 ILM 的数据生产者添加索引模式,则需要手动满足此策略中针对滚动更新的要求。
PUT _template/hot-warm-cold-delete-60days-template
{
"order":10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Enabling ILM in Beats and/or Logstash
最后,让我们为 Beats 和 Logstash 启用 ILM。
对于 6.7 Beats:
output.elasticsearch:
ilm.enabled: true
对于 6.7 Logstash:
output {
elasticsearch {
ilm_enabled => true
}
}
由于在更新的版本中可能会发生更改,因此,请参考相应版本的文档,了解如何在 Beats 和 Logstash 中启用。
现在,任何与索引模式匹配的新索引都将在热节点上创建新索引,ILM 将应用 hot-warm-cold-delete-60days 策略。
更新 ILM 策略
您可以随时更新 ILM 策略。**但是,您对策略所做的更改将仅在阶段更改时应用。**例如,如果您的索引当前处于热阶段(并等待进入温阶段),则您对热阶段所做的任何更改都不会对该索引生效,但一旦索引进入温阶段,对温阶段的任何更改都会被获取到。这样做是为了避免对给定的阶段重复操作。您可以通过解释 API 查看索引的 ILM 状态。
由于使用了相同的底层机制,因此,关于如何实现热温架构预 ILM 的许多先前信息仍然适用。但是,现在有了 ILM,就不再需要 [Curator] (/guide/en/elasticsearch/client/curator/current/index.html)工具来实现这个模式了。
展望
从 7.0 版开始,当 Beats 和 Logstash 连接到支持生命周期管理的集群时,它们会默认使用索引生命周期管理。此外,Beats 已将大多数 ILM 设置从 output.elasticsearch.ilm 命名空间移动到 setup.ilm 命名空间。例如,请参阅 7.0 Filebeat 文档。而且,从 7.0 开始,系统索引(如 .watcher-history-*)可以由 ILM 管理。
ILM 可支持您为时序索引轻松实现类似热温冷这样的成本节约型架构。马上就试试,然后在讨论论坛上发布您的想法。祝您体验开心!