全新推出 Elastic Stack Machine Learning
今天,我们非常荣幸地宣布,首次发布通过 X-Pack 提供的 Elastic Stack Machine Learning 功能。加入 Elastic 就像跳上了火箭船,但是经过 7 个月不可思议的工作,我们现已将 Prelert Machine Learning 技术完全集成到 Elastic Stack。这让我们很激动,而且我们非常迫切地想要收到用户的反馈。
温馨提示:请注意,不要太过激动,这项功能在 5.4.0 版本中尚标记为 beta。
Machine Learning
我们的目标是通过一系列工具为用户赋能,让他们可以从自己的 Elasticsearch 数据中获取价值和洞察。与此同时,我们将 Machine Learning 视为 Elasticsearch 搜索和分析能力的自然延伸。举例来说,Elasticsearch 能够让您在大量数据中,实时地搜索用户“steve”的交易,或者利用聚合和可视化,展示一段时间以来的十大畅销产品或交易趋势。而现在有了 Machine Learning 功能,您就可以更加深入地探究数据,例如 “有没有哪项服务的行为发生了变化?” 或者 “主机上是否运行有异常进程?” 那么要想回答这些问题,就必须要利用 Machine Learning 技术,通过数据自动构建主机或服务的行为模式。
不过, Machine Learning 目前是软件行业最被夸大其词的术语之一,因为从本质上来讲,它就是用来实现数据驱动型预测、决策和建模的一系列广泛的算法和方法。因此,我们有必要隔绝干扰信息,具体说说我们所做的工作。
时间序列异常检测
目前,X-Pack Machine Learning 功能的着眼点是,利用无监督式机器学习,提供 “时间序列异常检测” 功能。
随着时间的推移,我们计划增加更多 Machine Learning 功能,但是我们目前只专注于为用户存储的时间序列数据(例如日志文件、应用程序和性能指标、网络流量或 Elasticsearch 中的财务/交易数据)提供附加值。
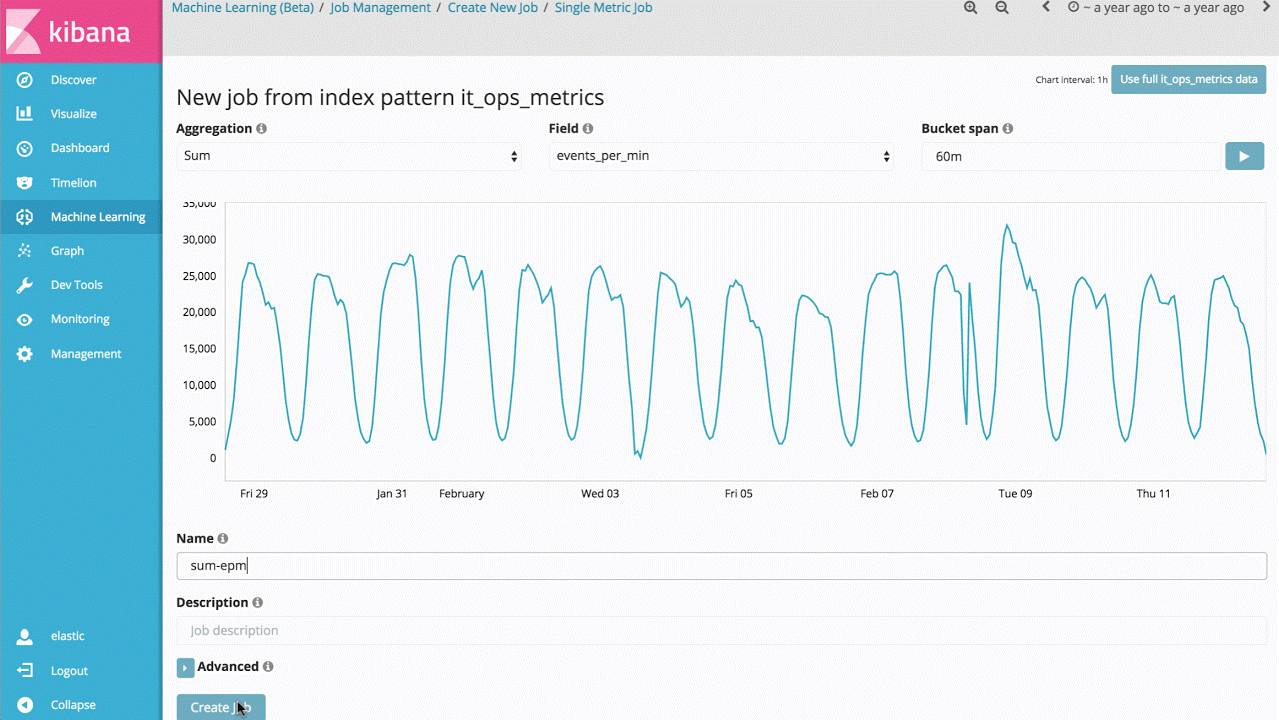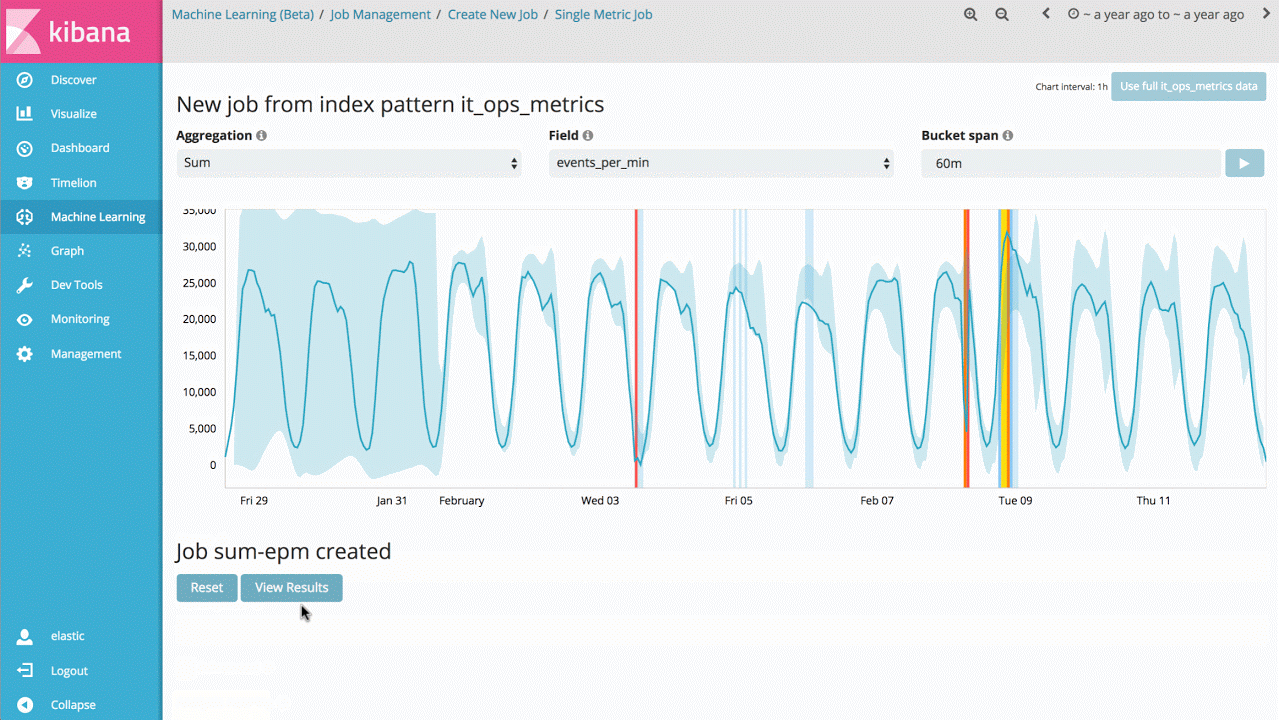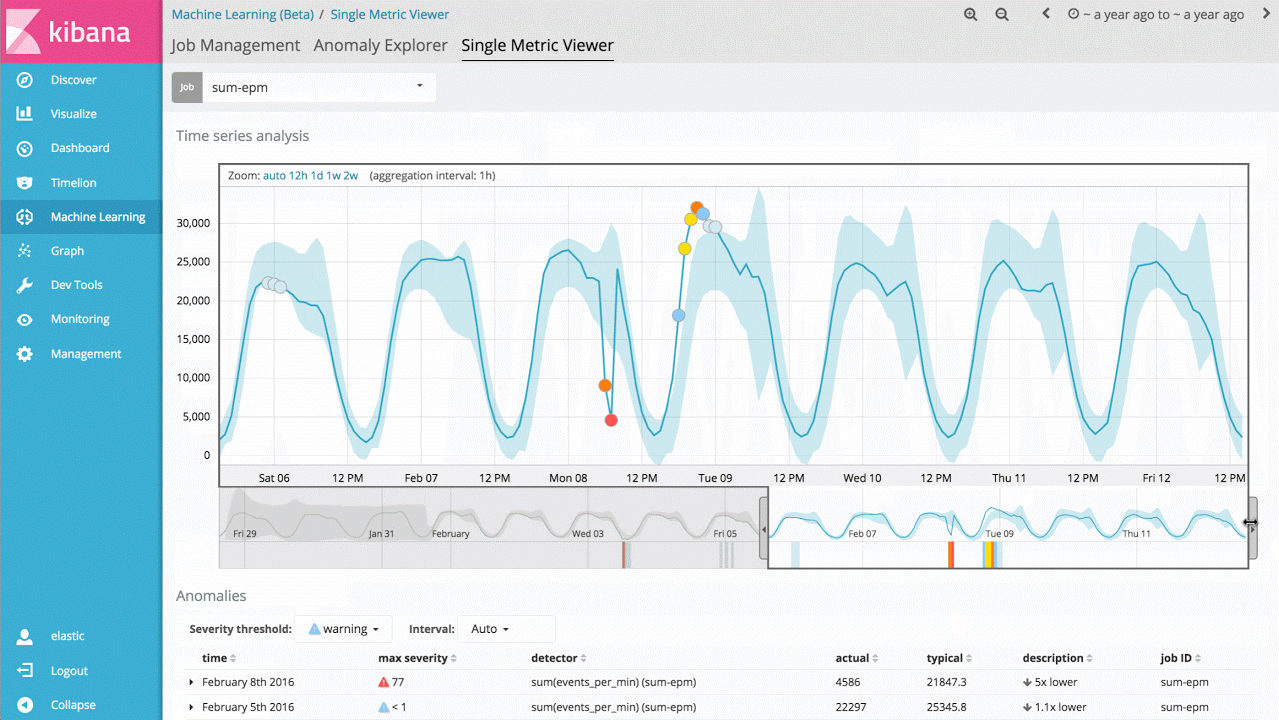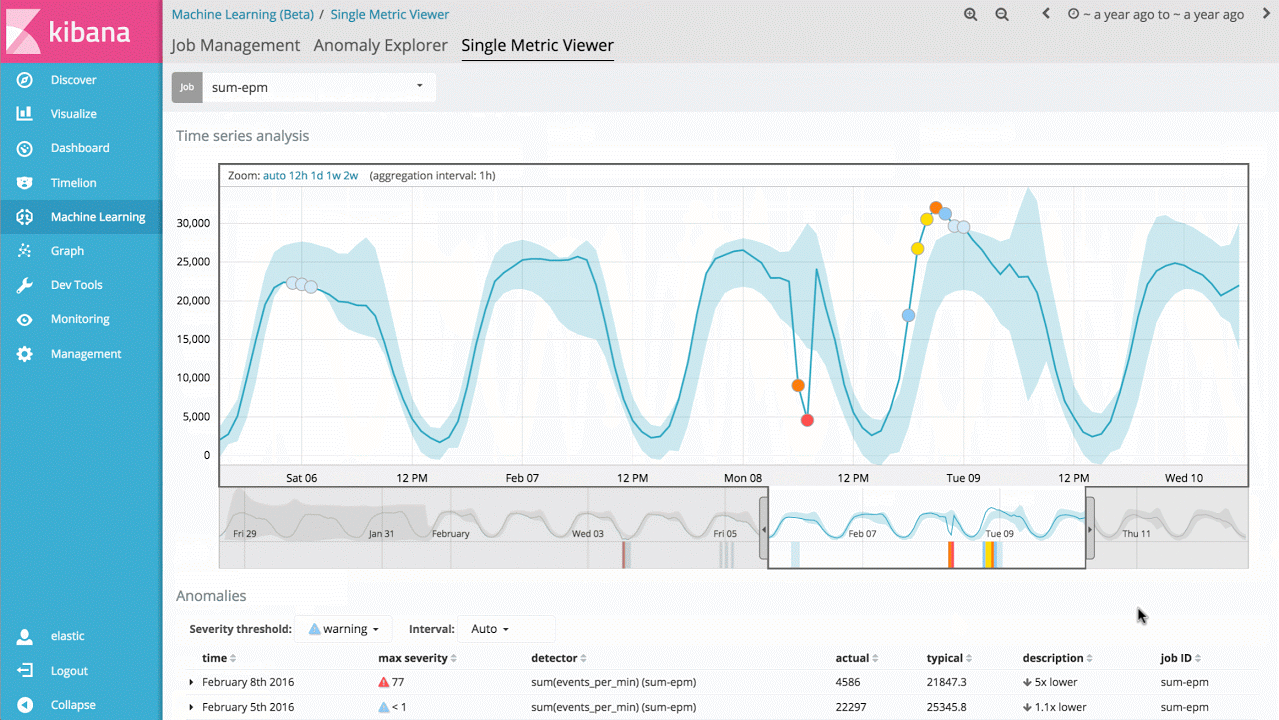
示例 1 - 自动提醒关键绩效指标值的异常变化
要说这项技术最直观的用例,那就是可以识别指标值或事件速率偏离正常行为的情况。例如,服务响应时间有没有显著增加?网站访客预期数量与同一时段正常情况相比,是否存在明显差异?传统情况下,人们会利用规则、阈值或简单的统计方法来进行此类分析。但遗憾的是,这些简单的方法鲜少能够高效地处理实际数据,原因在于此类方法往往是基于无效的统计假设(例如:高斯分布),因此不支持趋势分析(长期性或周期性趋势),或者在信号发生变化时缺乏稳定性。
所以说, Machine Learning 功能的首个切入点是单一指标作业,您可以借此了解该产品如何学习正常模式,如何识别单变量时间序列数据中存在的异常。如果您发现的异常是有意义的,您就可以连续地实时运行这项分析,并在发生异常时发出警报。
尽管这看上去像是一个比较简单的用例,但是产品后台包含大量复杂的无监督式机器学习算法和统计模型,因此我们对于任意信号具有鲁棒性,并且能够准确反映。
此外,为了让该功能可以在 Elasticsearch 集群中像原生程序一样运行,我们对功能实现进行了优化,因此几秒钟即可分析数以百万计的事件。
示例 2 - 自动追踪数以千计的指标
Machine Learning 产品可以扩展到数十万指标和日志文件,那么下一步就是要同时分析多个指标。这些指标可能是来自同一个主机的多个相关指标,可能是来自同一个数据库或应用程序的性能指标,也可能是来自多个主机的多个日志文件。在这种情况下,我们可以直接单独分析,再将结果聚合到同一个窗口,展示整体的系统异常情况。
例如,假设我要处理来自一大组应用程序服务的响应时间,我可以直接分析各个服务一段时间以来的响应时间,分别确认各个行为异常的服务,同时展示整体的系统异常情况:
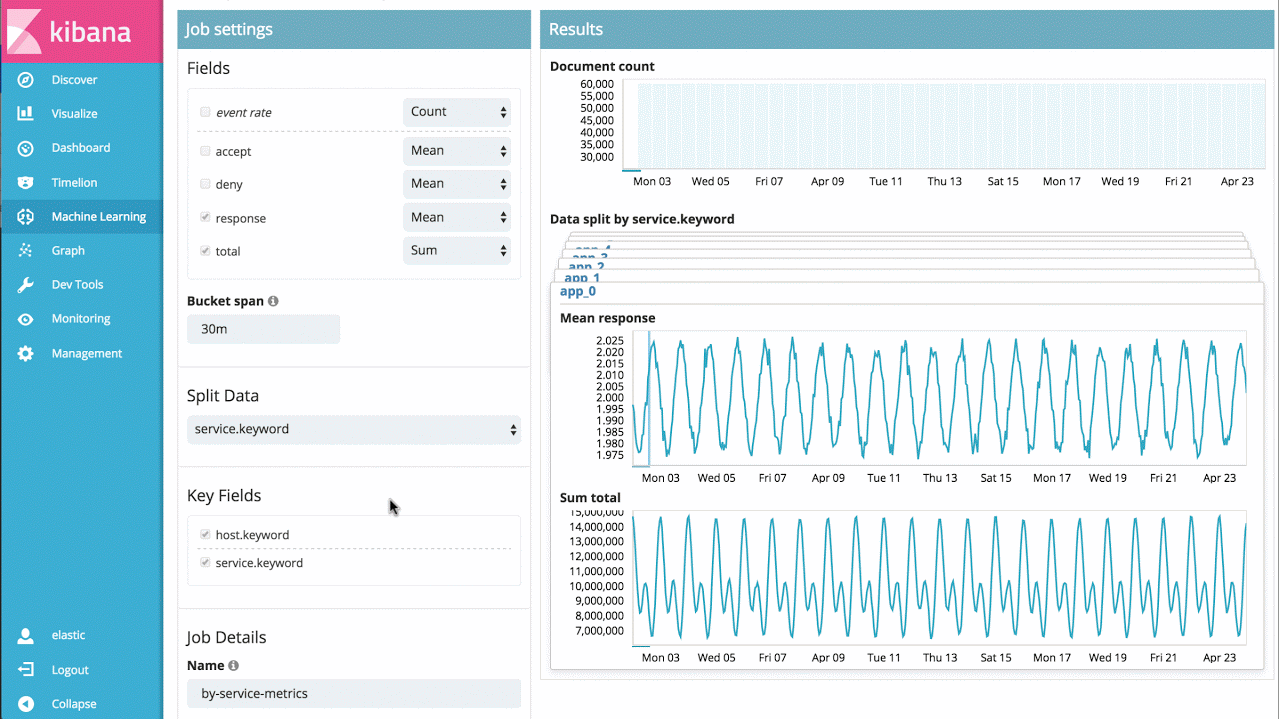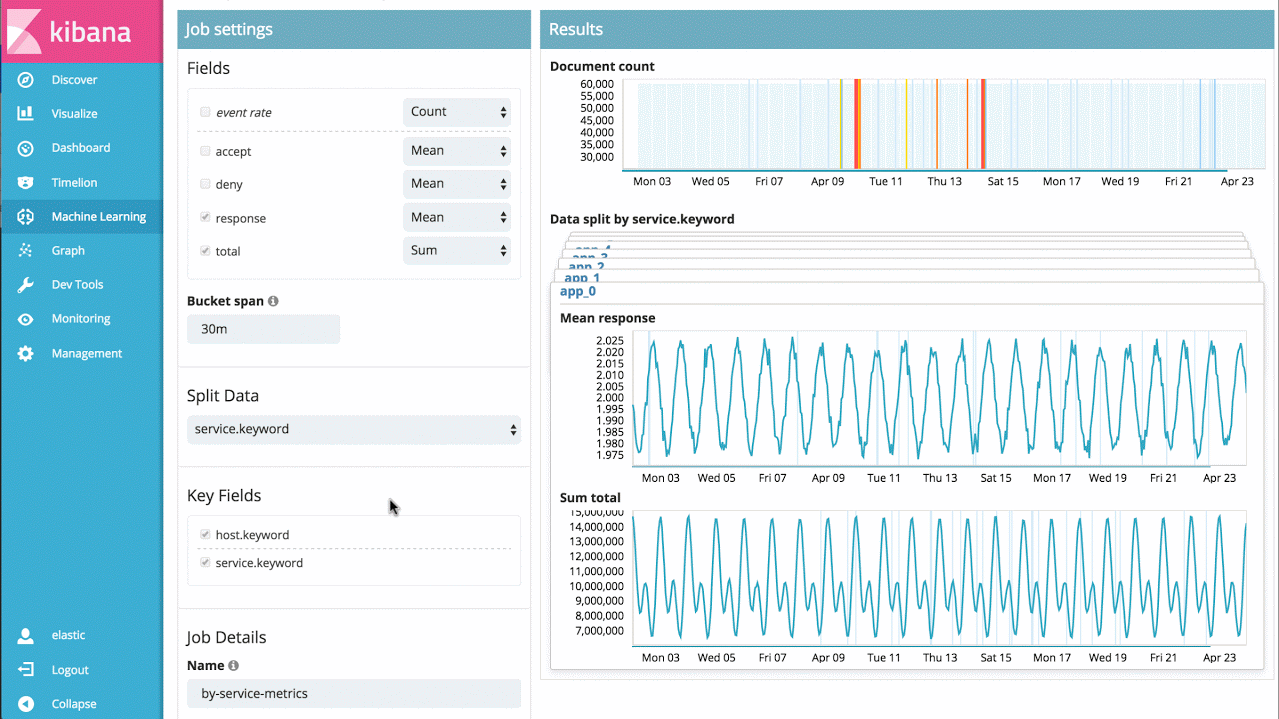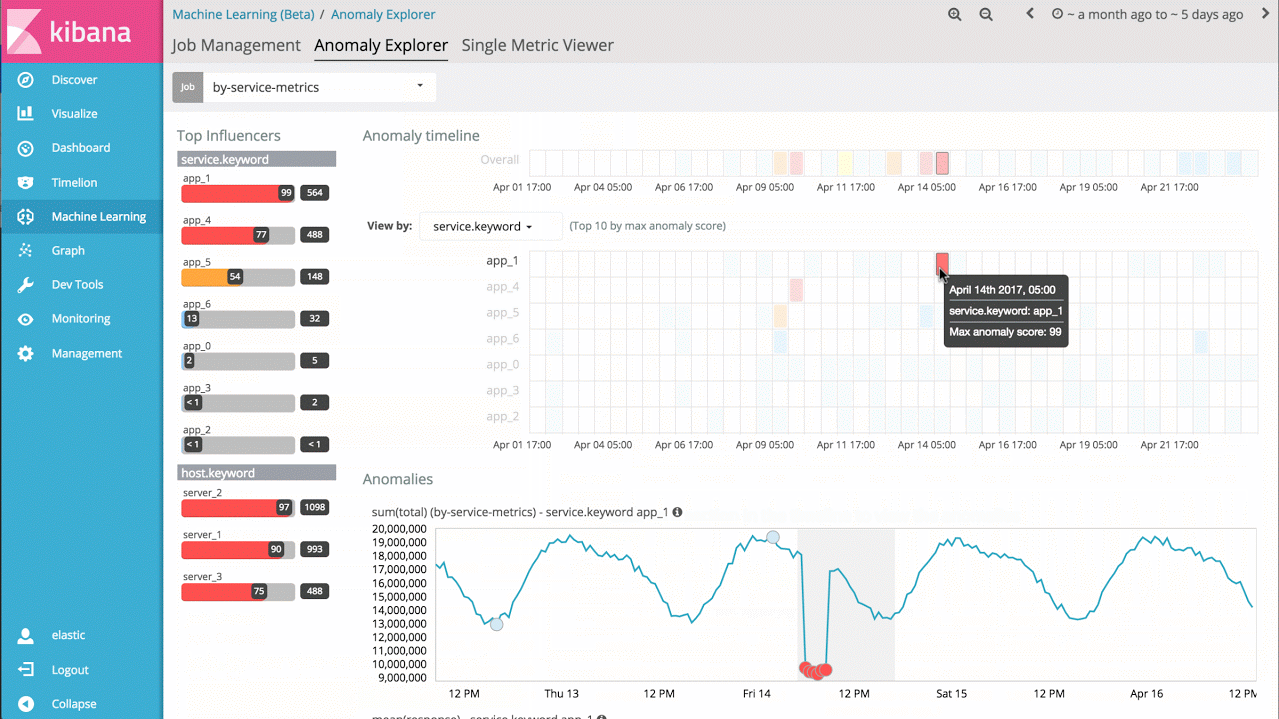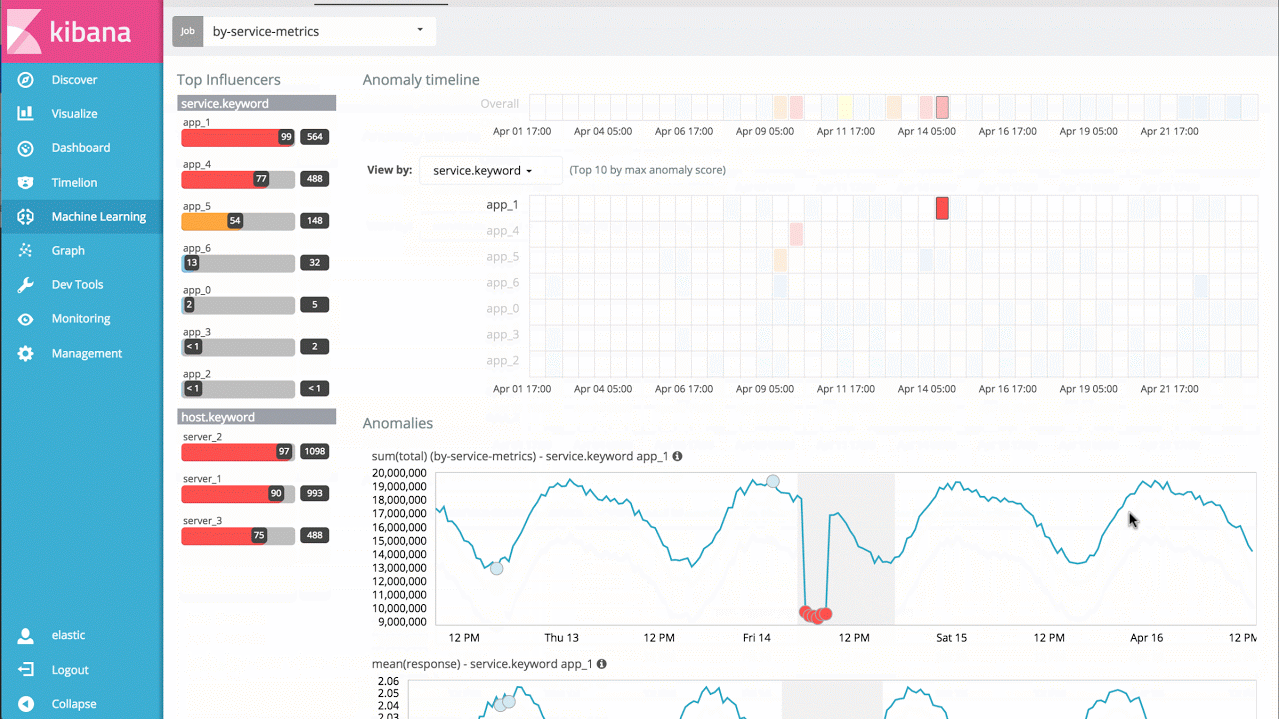
示例 3 - 高级作业
最后,我们的产品还有大量更高级的用途。比方说,如果您想找出与整体相比行为异常的用户、异常的 DNS 流量,或者伦敦街头的拥堵路段,这时您就可以利用高级作业,灵活地分析 Elasticsearch 中存储的任何时间序列数据。
Elastic Stack 整合
Machine Learning 是 X-Pack 中的一项功能。这就意味着,安装 X-Pack 之后,就可以使用 Machine Learning 功能实时分析 Elasticsearch 中的时间序列数据。 Machine Learning 作业与索引和分片基本类似,能够跨 Elasticsearch 集群自动分布和管理。这还意味着 Machine Learning 作业对节点故障有很好的适应性。从性能角度看,紧密集成意味着数据永远不需要离开集群,而且我们可以利用 Elasticsearch 聚合极大地提高某些作业类型的性能。而紧密集成带来的另外一个好处就是,您可以直接从 Kibana 创建异常检测作业并查看结果。
由于这种方法对数据进行原位分析,数据从不离开集群,因此与将 Elasticsearch 数据集成到外部数据科学工具相比,这种方法能够带来显著的性能和运维优势。随着我们在这个领域开发出越来越多的技术,这种架构的优势将会更加显著。
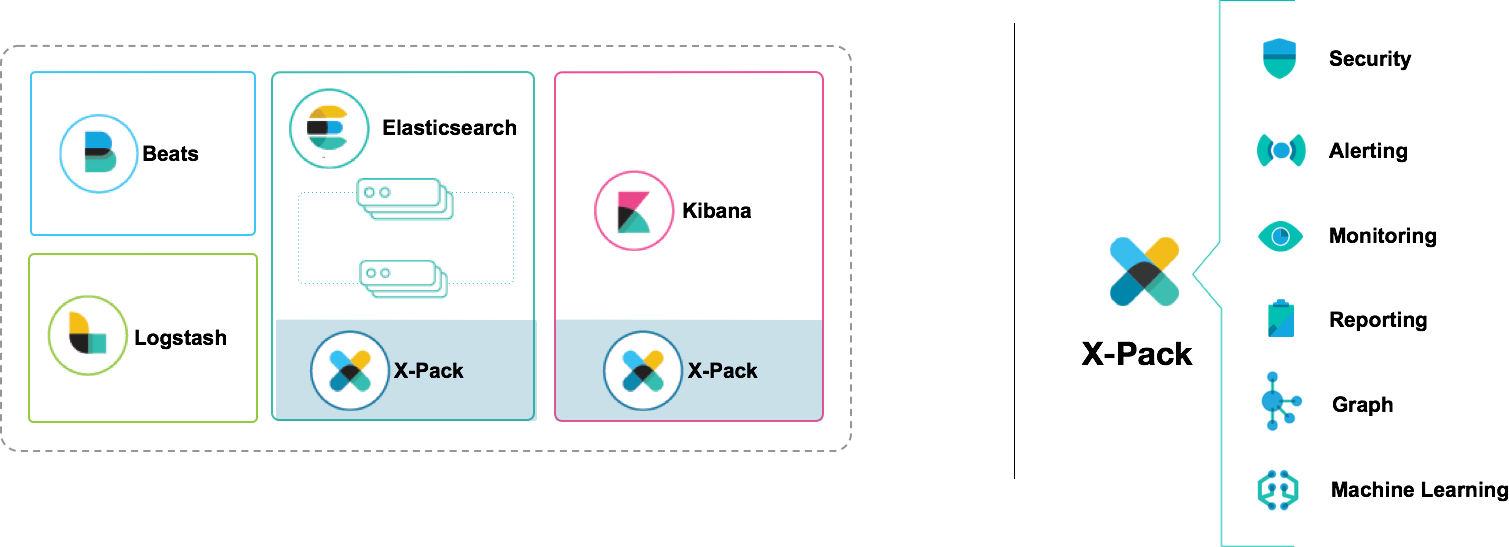
立即试用并反馈
这些 Machine Learning 功能是 X-Pack 5.4 中的 beta 功能,现已可用。我们急切地想要听听您的使用体会,所以请下载 5.4 版本,安装 X-Pack,然后直接联系我们,或者通过我们的讨论论坛联系我们。