Rechenzentrumsübergreifende Replikation mit der Cluster-übergreifenden Replikation von Elasticsearch
Die rechenzentrumsübergreifende Replikation ist schon seit einiger Zeit eine Anforderung für missionskritische Anwendungen in Elasticsearch und wurde bisher zum Teil mit externen Technologien umgesetzt. Mit der Einführung der Cluster-übergreifenden Replikation in Elasticsearch 6.7 sind keine zusätzlichen Technologien erforderlich, um Daten über Rechenzentren, Geografien oder Elasticsearch-Cluster hinweg zu replizieren.
Mit der Cluster-übergreifenden Replikation (Cross-Cluster Replication, CCR) können Sie bestimmte Indizes von einem Elasticsearch-Cluster in einen oder mehrere Elasticsearch-Cluster replizieren. Neben der rechenzentrumsübergreifenden Replikation gibt es viele weitere Anwendungsfälle für CCR, inklusive Datenlokalität (Replizieren von Daten an einen Ort näher am Benutzer oder Anwendungsserver, z. B. indem ein Produktkatalog an 20 verschiedene Rechenzentren in aller Welt repliziert wird) oder Replikation von Daten aus einem Elasticsearch-Cluster in ein zentrales Reporting-Cluster (z. B. 1.000 Bankniederlassungen aus aller Welt schreiben in ihr lokales Elasticsearch-Cluster, das wiederum zu Reportingzwecken in einen Cluster in der Zentrale repliziert wird.
In diesem Tutorial für die rechenzentrumsübergreifende Replikation mit CCR werden wir kurz die CCR-Grundlagen ansprechen, Architekturoptionen und Kompromisse ansprechen, ein rechenzentrumsübergreifendes Beispieldeployment konfigurieren und verschiedene Verwaltungsbefehle hervorheben. Eine technische Einführung in CCR finden Sie unter Leader und Follower: Einführung in die Cluster-übergreifende Replikation in Elasticsearch.
CCR ist ein Platin-Feature und ist in der 30-tägigen Probelizenz enthalten, die Sie mit der Start Trial API oder direkt in Kibana aktivieren können.
Grundlagen zur Cluster-übergreifenden Replikation (CCR)
Die Replikation wird auf der Indexebene konfiguriert (oder auf Basis eines Indexmusters)
CCR wird in Elasticsearch auf der Indexebene konfiguriert. Da wir die Replikation auf der Indexebene konfigurieren, haben wir eine Vielzahl von Replikationsstrategien zur Auswahl und können sogar verschiedene Indizes in unterschiedliche Richtungen replizieren und differenzierte rechenzentrumsübergreifende Architekturen einrichten.
Replizierte Indizes sind schreibgeschützt
Ein Index kann von einem oder mehreren Elasticsearch-Clustern repliziert werden. Jeder Cluster, der den Index repliziert, pflegt eine schreibgeschützte Kopie des Index. Der aktive Index, der Schreibvorgänge akzeptiert, wird auch als Leader bezeichnet. Die passiven schreibgeschützten Kopien dieses Index nennt man Follower. Für die Auswahl eines neuen Leaders gibt es kein Konzept. Wenn ein Leader-Index nicht verfügbar ist (z. B. Ausfall eines Clusters oder Rechenzentrums), muss ein Anwendungs- oder Clusteradministrator explizit einen anderen Index (vermutlich in einem anderen Cluster) für die Schreibvorgänge auswählen.
Die CCR-Standardkonfiguration wurde für eine Vielzahl von Anwendungsfällen mit hohem Durchsatz ausgewählt
Ändern Sie die Standardwerte nur, wenn Sie sich ausführlich damit vertraut gemacht haben, wie sich die Änderung auf das System auswirken wird. Weitere Optionen finden Sie in der Create follower API, z. B. "max_read_request_operation_count" oder "max_retry_delay". Wir werden demnächst einen Blogeintrag dazu veröffentlichen, wie Sie diese Parameter für einzigartige Arbeitslasten anpassen können.
Sicherheitsanforderungen
Wie bereits im Leitfaden für erste Schritte mit CCR beschrieben, benötigt der Benutzer im Quell-Cluster die Clusterberechtigung „read_ccr“ und die Indexberechtigungen „monitor“ und „read“. Im Zielcluster benötigt der Benutzer die Clusterberechtigung „manage_ccr“ und die Indexberechtigungen „monitor“, „read“, „write“, und „manage_follow_index“. Zentralisierte Authentifizierungssysteme wie LDAP können ebenfalls verwendet werden.
Beispielarchitekturen für die rechenzentrumsübergreifende Replikation
Produktions- und DR-Rechenzentren
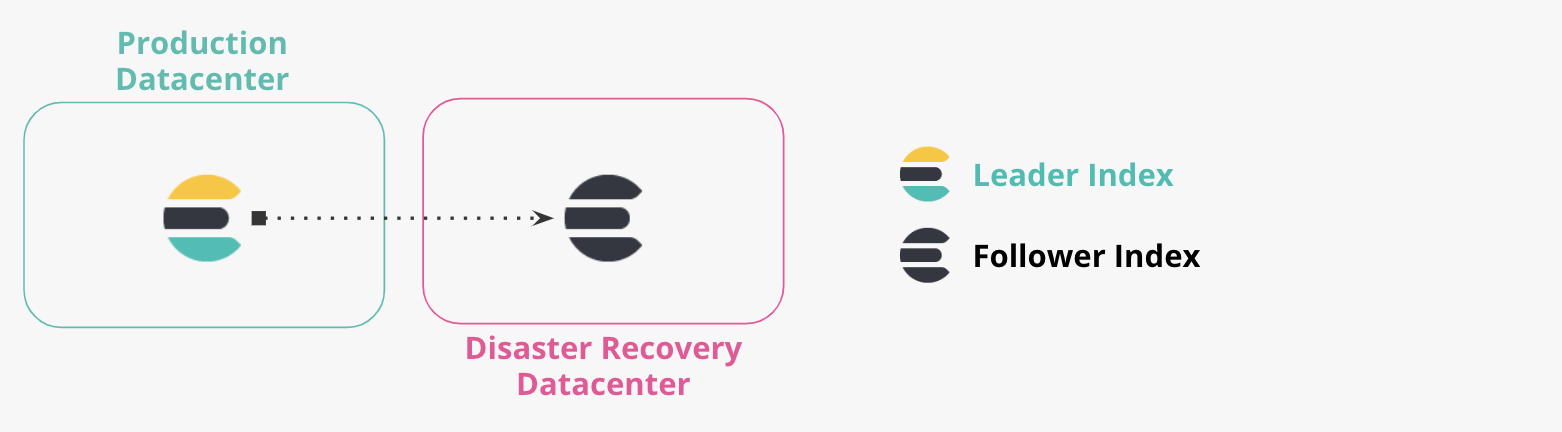
Mehr als zwei Rechenzentren
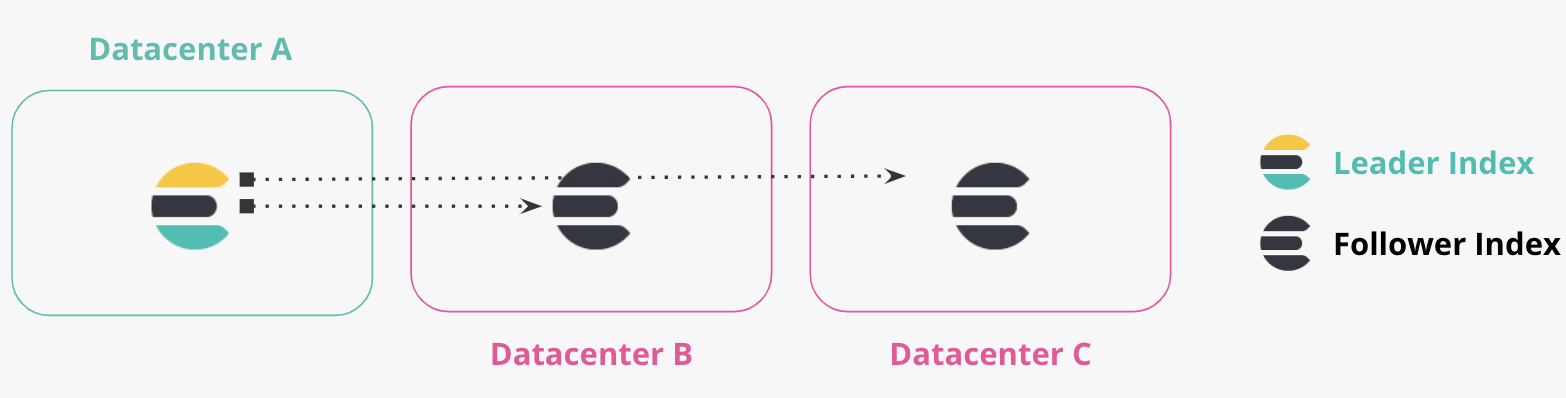
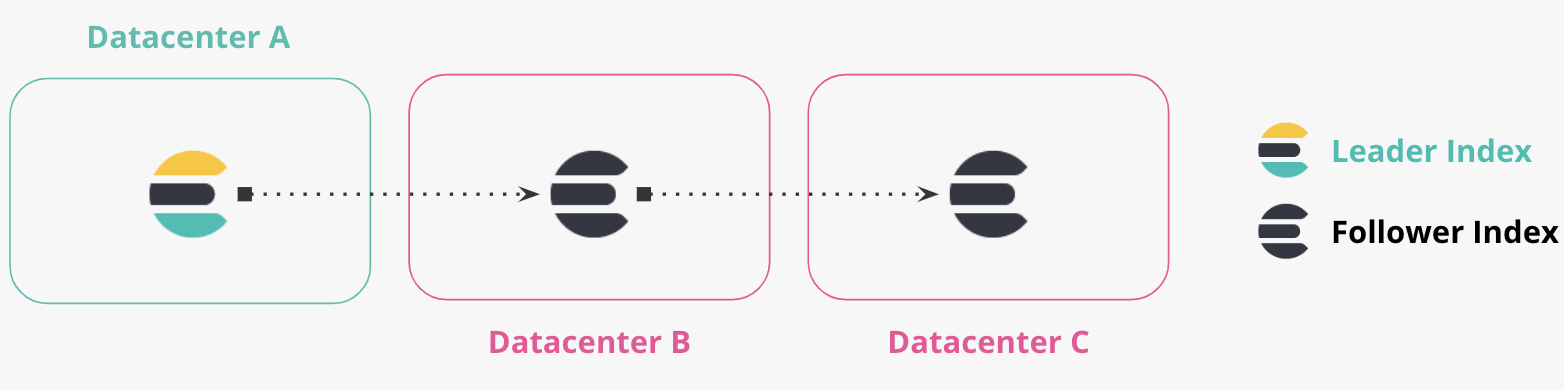
Verkettete Replikation
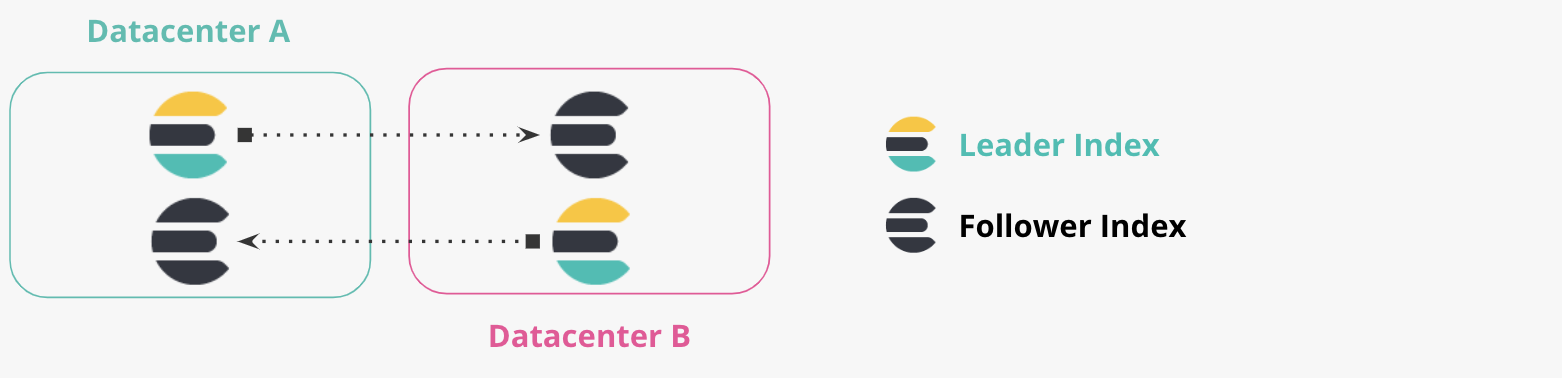
Bidirektionale Replikation
Tutorial: Rechenzentrumsübergreifendes Deployment
1. Einrichtung
Für dieses Tutorial verwenden wir zwei Cluster, die sich beide auf unserem lokalen Computer befinden. Sie können die Cluster an jedem beliebigen Ort unterbringen.
- us-cluster: Dies ist unser „US-Cluster“, den wir lokal auf Port 9200 ausführen werden. Wir werden Dokumente vom US-Cluster in unser Japan-Cluster replizieren.
- japan-cluster: Dies ist unser „Japan-Cluster“, den wir lokal auf Port 8200 ausführen werden. Der Japan-Cluster wird einen replizierten Index aus dem US-Cluster enthalten.
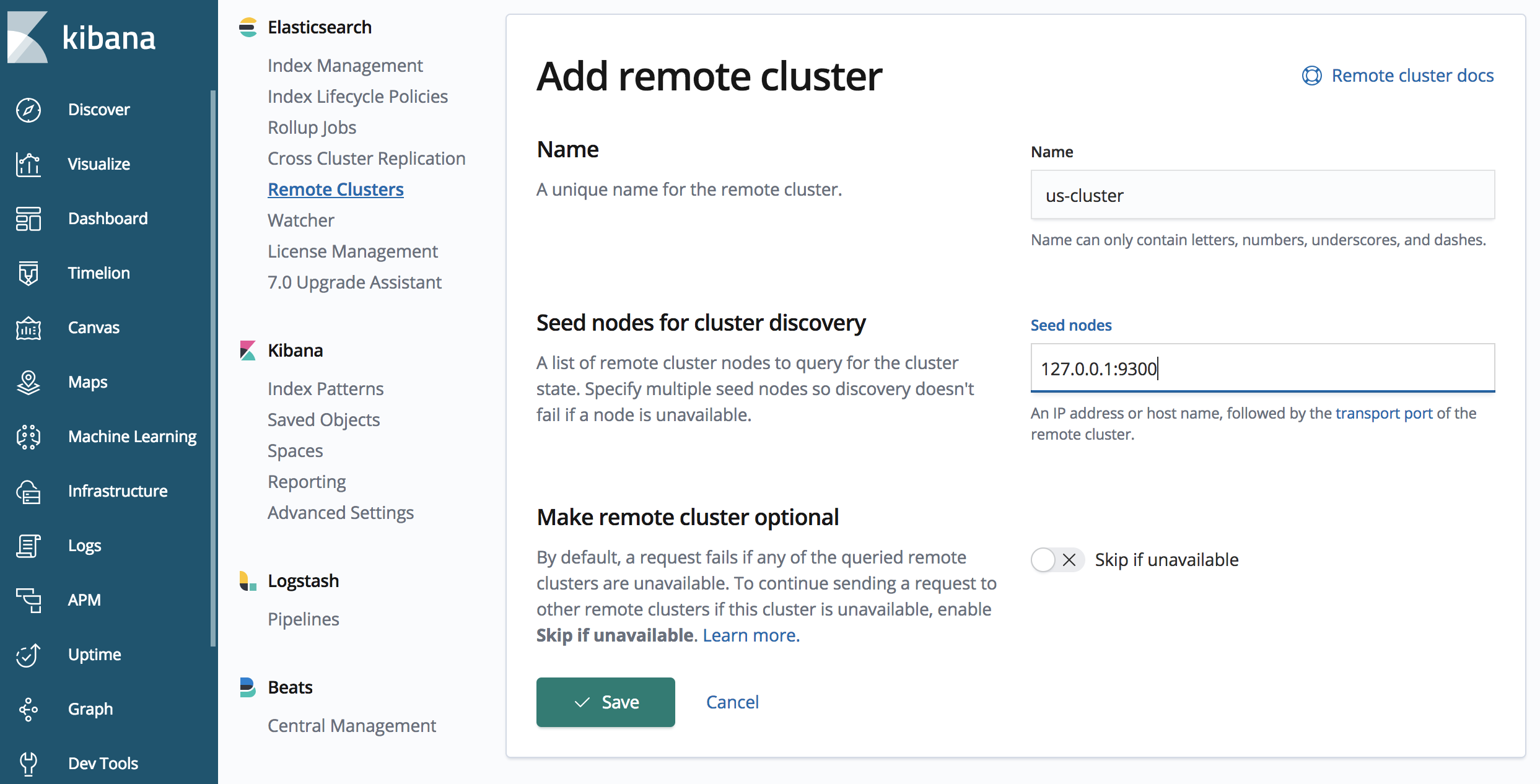
2. Remotecluster definieren
Bei der Einrichtung von CCR müssen die Elasticsearch-Cluster alle anderen Elasticsearch-Cluster kennen. Diese Anforderung gilt nur in eine Richtung, wenn der Zielcluster nur Verbindungen in eine Richtung zum Quellcluster herstellen muss. Wir definieren andere Elasticsearch-Cluster als Remotecluster und geben zu deren Beschreibung einen Alias ein.
Wir möchten sicherstellen, dass unser japan-cluster den us-cluster kennt. Die Replikation in CCR ist Pull-basiert, und wir müssen keine Verbindung vom us-cluster zum japan-cluster angeben.
Wir werden das us-cluster mit einem API-Aufruf im japan-cluster definieren.
# Wir definieren im japan-cluster, wie wir auf den us-cluster zugreifen werden
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(Für Befehle aus der Kibana-API empfehlen wir die Verwendung der Entwickler-Tools-Konsole in Kibana unter Kibana > Entwickler-Tools > Konsole)
Der gezeigte API-Aufruf definiert einen Remotecluster mit dem Alias „us-cluster“, der unter „127.0.0.1:9300“ erreichbar ist. Sie können einen oder mehrere Seeds angeben. Normalerweise ist es sinnvoll, mehr als einen Seed anzugeben, falls ein Seed während der Handshake-Phase nicht verfügbar ist.
Weitere Details zum Konfigurieren von Remoteclustern finden Sie in unserer Referenzdokumentation zum Definieren von Remoteclustern.
Beachten Sie außerdem den Port 9300 für die Verbindung zum us-cluster. Der us-cluster wartet auf Port 9200 auf HTTP-Protokollverbindungen (dies ist der Standardwert, der in der Datei „elasticsearch.yml“ für unser „us-cluster“ festgelegt ist). Für die Replikation wird jedoch das Elasticsearch-Transportprotokoll (für die Kommunikation zwischen Knoten) und der Standardport 9300 verwendet.
Für Remotecluster gibt es eine Verwaltungs-GUI in Kibana. In diesem Tutorial werden wir sowohl die GUI als auch die API für CCR besprechen. Um die Remotecluster-GUI in Kibana zu öffnen, klicken Sie auf „Management“ (Zahnradsymbol) im linken Navigationsbereich, und navigieren Sie zu „Remote Clusters“ im Elasticsearch-Bereich.
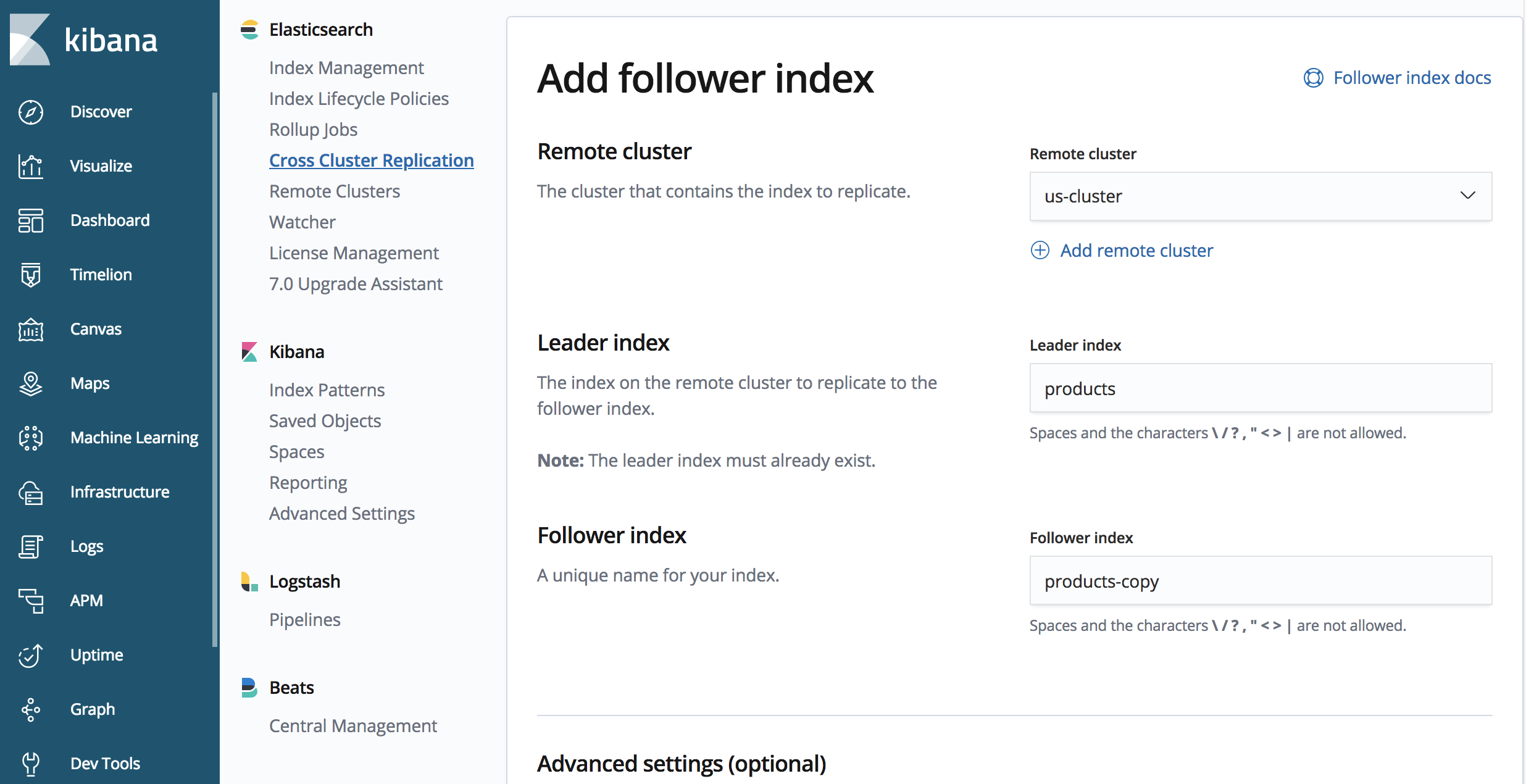
3. Index für die Replikation erstellen
Wir erstellen einen Index mit dem Namen „products“ in unserem us-cluster, und replizieren diesen Index aus unserer Quelle us-cluster an unser Ziel japan-cluster:
Im us-cluster:
# Index „product“ erstellen
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
Möglicherweise ist Ihnen die Einstellung „soft_deletes“ aufgefallen. Soft Deletes sind erforderlich, um einen Index als Leader für CCR verwenden zu können (weitere Informationen finden Sie unter Auf den Verlauf kommt es an):
soft_deletes: Ein Soft Delete tritt auf, wenn ein vorhandenes Dokument aktualisiert oder gelöscht wird. Durch die Aufbewahrung dieser Soft Deletes bis zu einem konfigurierbaren Limit entsteht ein Operationsverlauf auf den Leader-Shards, der den Follower-Shards für die Wiedergabe des Operationsverlaufs zur Verfügung gestellt wird.
Wenn eine Follower-Shard die Operationen vom Leader repliziert, hinterlässt sie Markierungen in den Leader-Shards, damit der Leader weiß, an welcher Stelle im Verlauf sich seine Follower befinden. Soft-Delete-Operationen unterhalb dieser Markierungen können durch Zusammenführungen entfernt werden. Oberhalb dieser Markierungen behalten die Leader-Shards diese Operationen maximal bis zur Freigabefrist für den Shard-Verlauf. Diese Frist beträgt standardmäßig zwölf Stunden. Diese Frist legt fest, wie lange ein Follower offline sein kann, bevor die Gefahr besteht, dass er unwiederbringlich zurückfällt und ein neues Bootstrapping vom Leader ausgeführt werden muss.
4. Replikation starten
Nachdem wir einen Alias für unseren Remotecluster und einen Index erstellt haben, den wir replizieren möchten, können wir die Replikation starten.
In unserem japan-cluster:
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
Der Endpunkt enthält „products-copy“. Dies ist der Name des replizierten Index in unserem Cluster „japan-cluster. Wir replizieren aus dem zuvor definierten Cluster us-cluster, und der replizierte Index hat den Namen „products“ im Cluster us-cluster.
Beachten Sie dabei, dass unser replizierter Index schreibgeschützt ist und keine Schreibvorgänge akzeptiert.
Das war’s auch schon! Wir haben einen Index für die Replikation von einem Elasticsearch-Cluster in einen anderen Cluster konfiguriert!
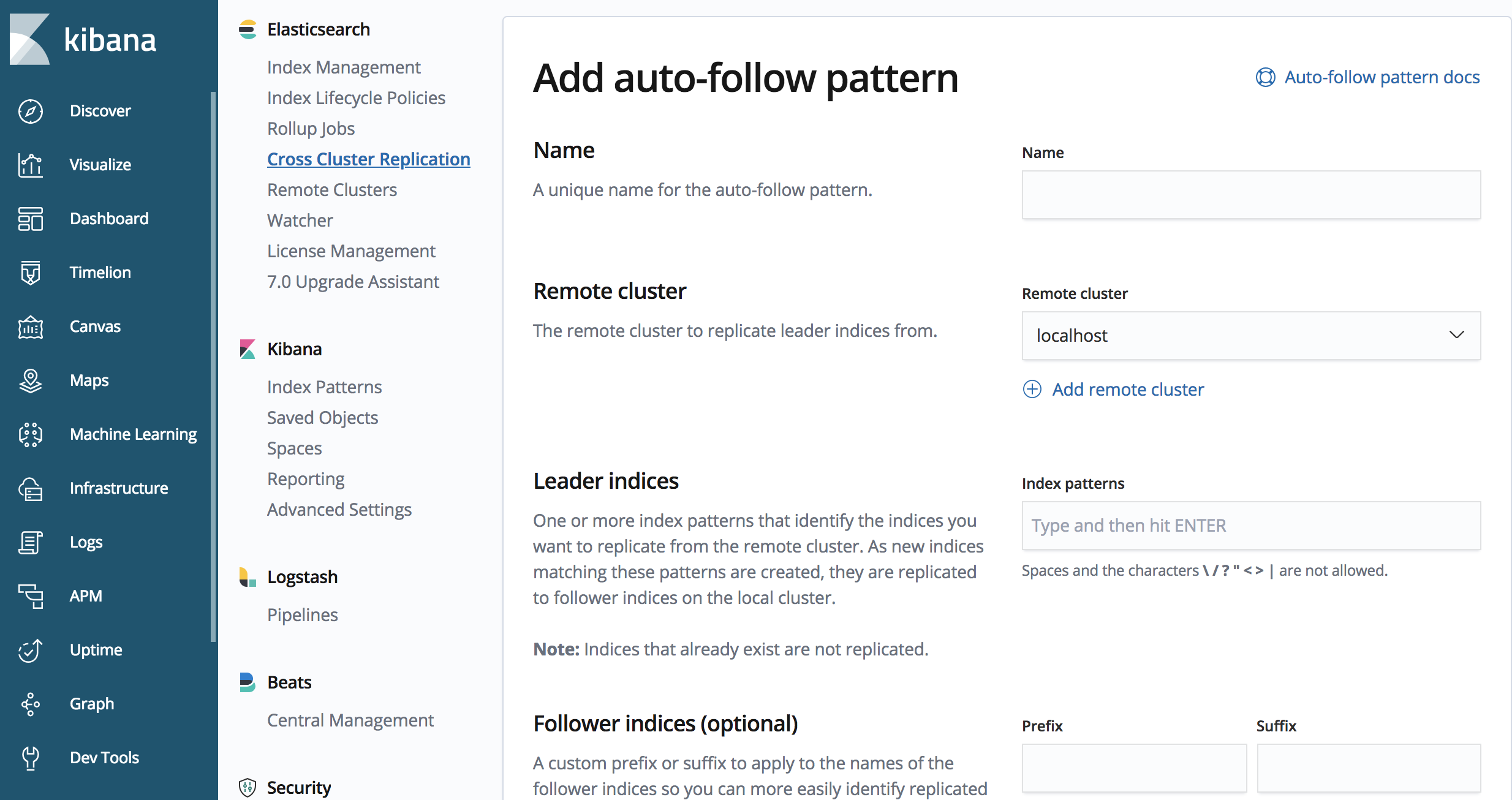
Replikation für Indexmuster starten
Vielleicht ist Ihnen aufgefallen, dass sich das gezeigte Beispiel nicht besonders gut für zeitbasierte Anwendungsfälle eignet, in denen ein Index pro Tag oder für eine bestimmte Datenmenge existiert. Die CCR API enthält Methoden, mit denen Sie automatische Follow-Muster definieren können, um festzulegen, welche Indexmuster repliziert werden.
Mit der CCR API können wir ein automatisches Follow-Muster definieren
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
Der gezeigte API-Beispielaufruf repliziert einen Index, der mit „metricbeat“ oder „packetbeat“ beginnt.
Wir können automatische Follow-Muster auch in der CCR-GUI in Kibana definieren.
5. Replikation testen
Unser Index „products“ wird jetzt aus us-cluster nach japan-cluster repliziert, und wir können ein Testdokument einfügen, um zu überprüfen, ob es repliziert wird.
Im Cluster us-cluster:
POST /products/_doc
{
"name" : "My cool new product"
}
Anschließend fragen wir das japan-cluster ab, um zu überprüfen, ob das Dokument repliziert wurde:
GET /products-copy/_search
Wir sollten ein einziges Dokument sehen, das im us-cluster geschrieben und in den japan-cluster repliziert wurde.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
Rechenzentrumsübergreifende Verwaltungsknoten
Ich zeige Ihnen jetzt einige der Verwaltungs-APIs für CCR, konfigurierbare Einstellungen und die Methode, mit der Sie einen replizierten Index in einen normalen Index in Elasticsearch konvertieren können.
Verwaltungs-APIs für die Replikation
Für CCR in Elasticsearch haben Sie verschiedene nützliche Verwaltungs-APIs zur Auswahl. Mit diesen APIs können Sie Replikationsfehler beheben, Replikationseinstellungen ändern oder ausführliche Diagnosedaten sammeln.
# Alle CCR-Statistiken zurückgeben
GET /_ccr/stats
# Replikation für einen bestimmten Index pausieren
POST //_ccr/pause_follow
# Replikation fortsetzen, normalerweise nachdem sie pausiert wurde
POST //_ccr/resume_follow
{
}
# Following eines Index aufheben (Replikation für den Zielindex beenden). Dafür muss die Replikation zunächst pausiert werden
POST //_ccr/unfollow
# Statistiken für einen Follower-Index
GET //_ccr/stats
# Automatisches Follow-Muster entfernen
DELETE /_ccr/auto_follow/
# Alle automatischen Follow-Muster anzeigen, oder ein automatisches Follow-Muster nach Name abrufen
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
Weitere Details zu den Verwaltungs-APIs für CCR finden Sie in der Elasticsearch-Referenzdokumentation.
Follower-Index in einen normalen Index konvertieren
Wir können einen Teil der beschriebenen Verwaltungs-APIs verwenden, um einen Follower-Index Schritt für Schritt in einen normalen Index in Elasticsearch zu konvertieren, der Schreibvorgänge akzeptieren kann.
In unserem obigen Beispiel haben wir ein recht einfaches Setup verwendet. Der replizierte Index „products-copy“ in unserem japan-cluster ist schreibgeschützt und akzeptiert keine Schreibvorgänge. Falls wir den Index „products-copy“ in einen normalen Index in Elasticsearch konvertieren möchten, der Schreibvorgänge akzeptiert, dann stehen uns die folgenden Befehle zur Verfügung. Beachten Sie, dass unser ursprünglicher Index („products“) weiterhin Schreibvorgänge akzeptiert. Daher sollten wir zunächst die Schreibvorgänge im Index „products“ einschränken, bevor wir unseren Index „products-copy“ in einen normalen Elasticsearch-Index konvertieren.
# Replikation pausieren
POST //_ccr/pause_follow
# Index schließen
POST /my_index/_close
# Following aufheben
POST //_ccr/unfollow
# Index öffnen
POST /my_index/_open
Machen Sie sich mit der Cluster-übergreifenden Replikation (CCR) von Elasticsearch vertraut
Wir haben diese Anleitung geschrieben, um Ihnen den Einstieg in CCR in Elasticsearch zu erleichtern, und hoffen, dass Sie sich mit CCR vertraut machen, die verschiedenen CCR APIs (und die verschiedenen GUIs in Kibana) kennenlernen und dieses neue Feature ausprobieren werden. Weitere Ressourcen finden Sie unter anderem im Beitrag Erste Schritte mit der Cluster-übergreifenden Replikation und in der API-Referenzanleitung für die Cluster-übergreifende Replikation.
Wir immer können Sie Ihr Feedback oder Ihre Fragen in unseren Diskussionsforen hinterlassen, und wir werden schnellstmöglich darauf antworten.