Elastic Stack 6.7.0 released
Die Version 6.7 des Elastic Stack ist da – und das Warten hat sich gelohnt! Es fühlt sich ein bisschen an, als wäre so kurz vor Ostern auch noch der Weihnachtsmann vorbeigekommen.
In diesem Blog-Post stellen wir Ihnen einige der Highlights der neuen Version vor. Wenn Sie mehr über die hier vorgestellten Features erfahren möchten, sehen Sie sich unsere Feature-spezifischen Einführungs-Blog-Posts an. Oder, besser noch: Probieren Sie die neue Version gleich aus! Version 6.7 kann in unserem Elasticsearch Service genutzt werden, dem einzigen gehosteten Elasticsearch-Angebot, das diese neuen Features bereithält. Wenn Sie die Verwaltung selbst übernehmen möchten, können Sie den Stack auch herunterladen und ihn in der von Ihnen bevorzugten Deployment-Umgebung einsetzen.
Elastic Maps: Zusätzliche Funktionen für die kartografische Darstellung von Geodaten in Kibana
Geodaten machen einen wichtigen Teil der Suche aus und ermöglichen eine Reihe von Anwendungsfällen, vom Ranking von Restaurants in der unmittelbaren Umgebung über Analysen zur Schlagkraft verschiedener Marketingkampagnen bis hin zur Suche nach Netzwerkbedrohungen rund um den Globus. Wir haben im Laufe der Jahre massiv in die Verbesserung unserer Funktionen zur Verarbeitung von Geodaten im gesamten Stack investiert – ob bessere Speichereffizienz und dramatische Verbesserung der Abfragegeschwindigkeit in Elasticsearch, zusätzliche Optionen zur Visualisierung von Geodaten in Kibana oder kostenloses Hosting von Grundkarten und Länder/Regionsgrenzen beim Elastic Maps Service.
Als nächsten Schritt in dieser Entwicklung führen wir jetzt Elastic Maps ein. Elastic Maps ist eine neue dedizierte Lösung, mit deren Hilfe Geodaten kartografisch aufbereitet, abgefragt und in Kibana visualisiert werden können. Mit dieser Lösung werden die bestehenden Optionen zur Visualisierung von Geodaten in Kibana beträchtlich erweitert. Dazu tragen Features bei wie:
– Visualisierung mehrerer Ebenen und Datenquellen in derselben Karte
– dynamische datengestützte Formatierung auf Vektorebenen in Karten – Darstellung aggregierter Daten und von Daten auf der Ebene einzelner Dokumente – Steuerung der Sichtbarkeit einzelner Ebenen (anhand des Zoomwertes) für mehr Übersichtlichkeit
Und wie alles in Kibana verfügt auch Elastic Maps über die Abfrageleiste mit automatischer Vervollständigung, die das vom Elastic Stack gewohnte Such- und Abfrageerlebnis mit Antworten in Echtzeit ermöglicht.
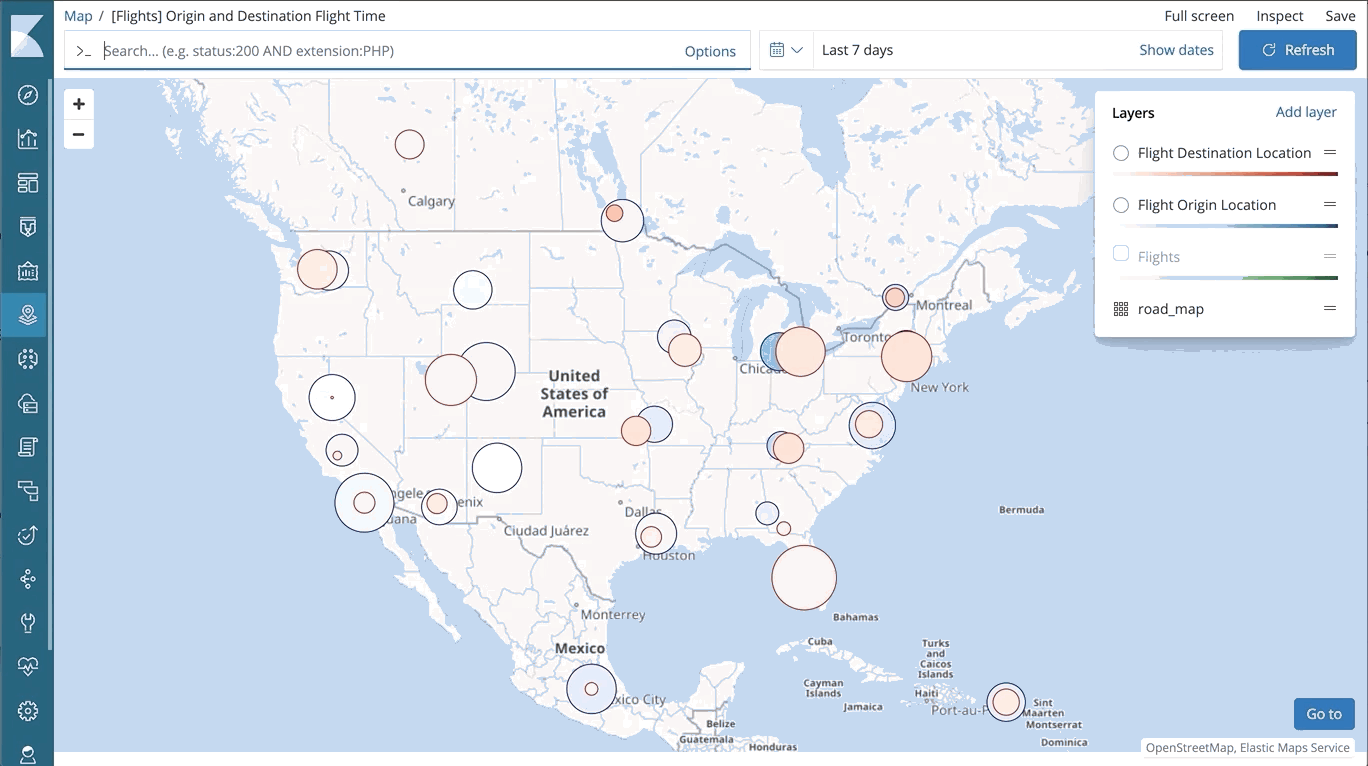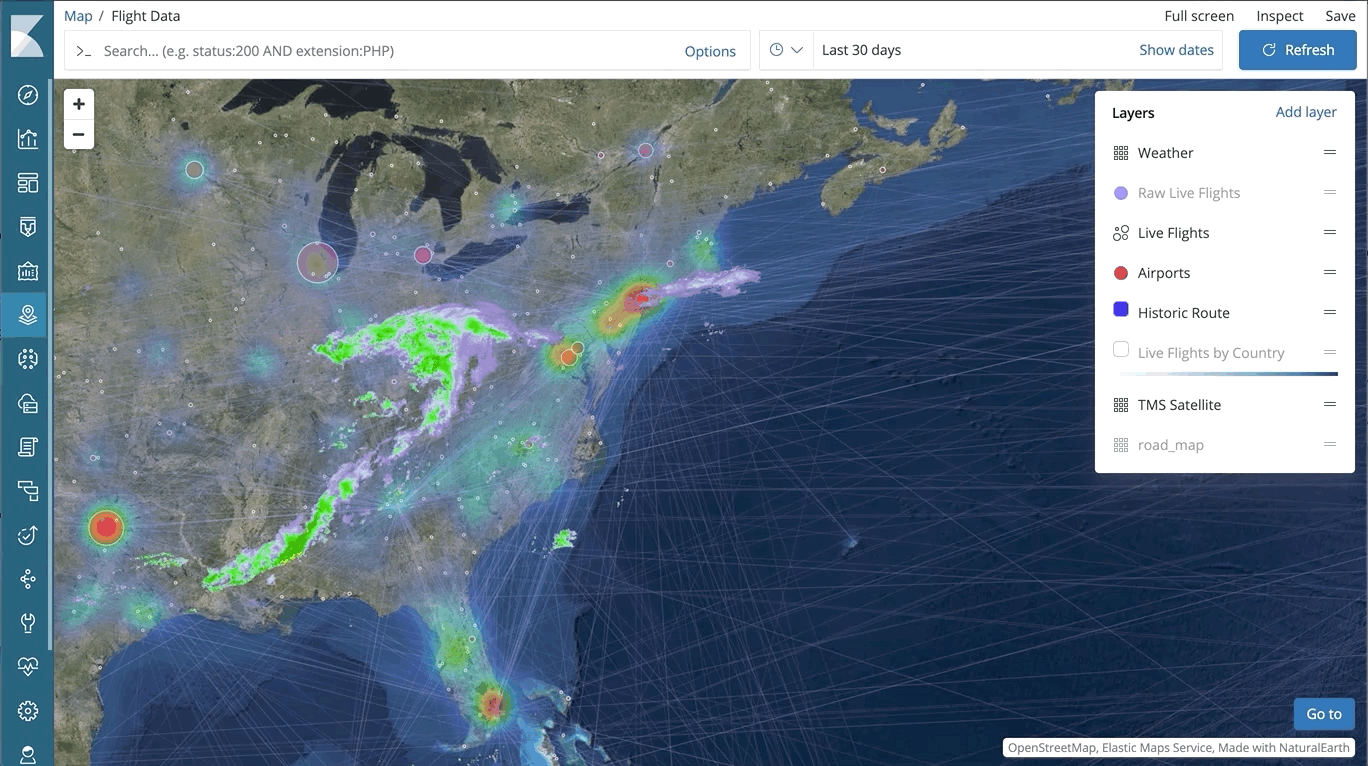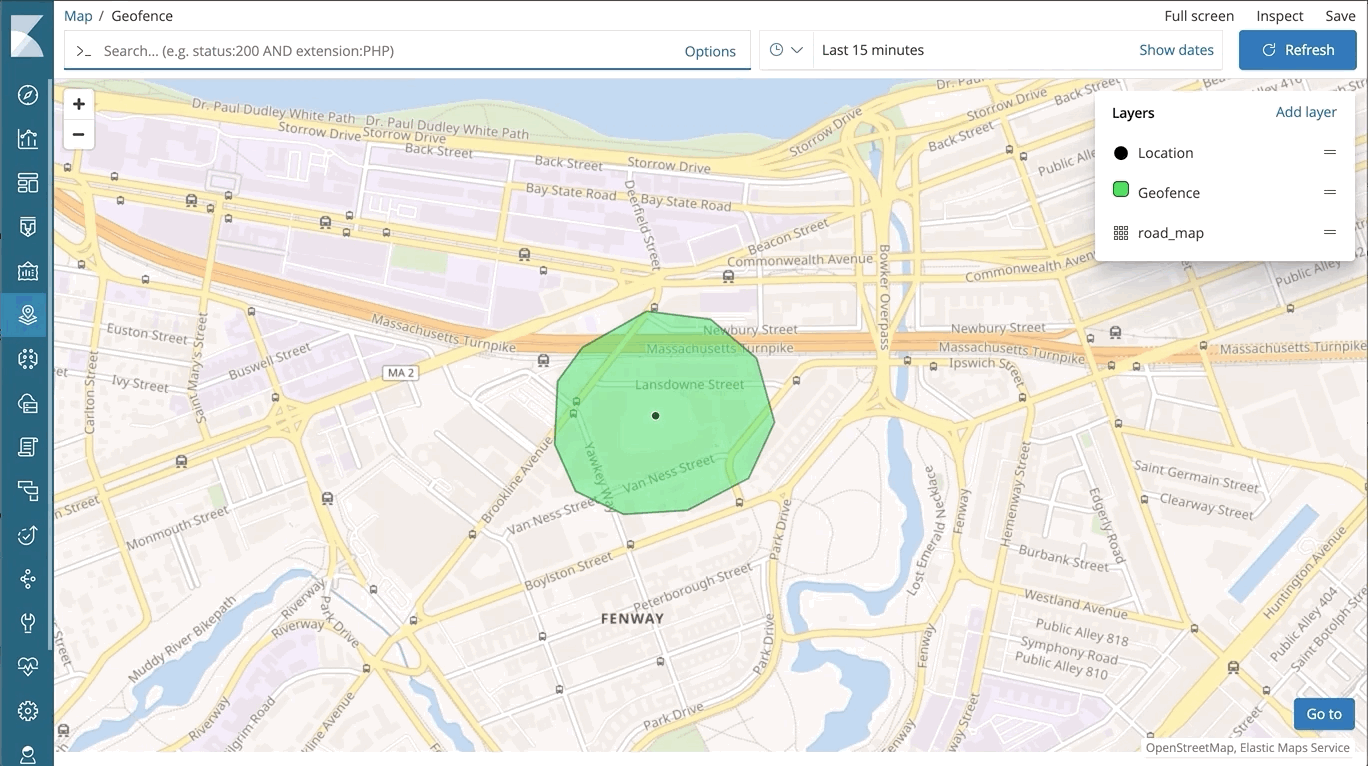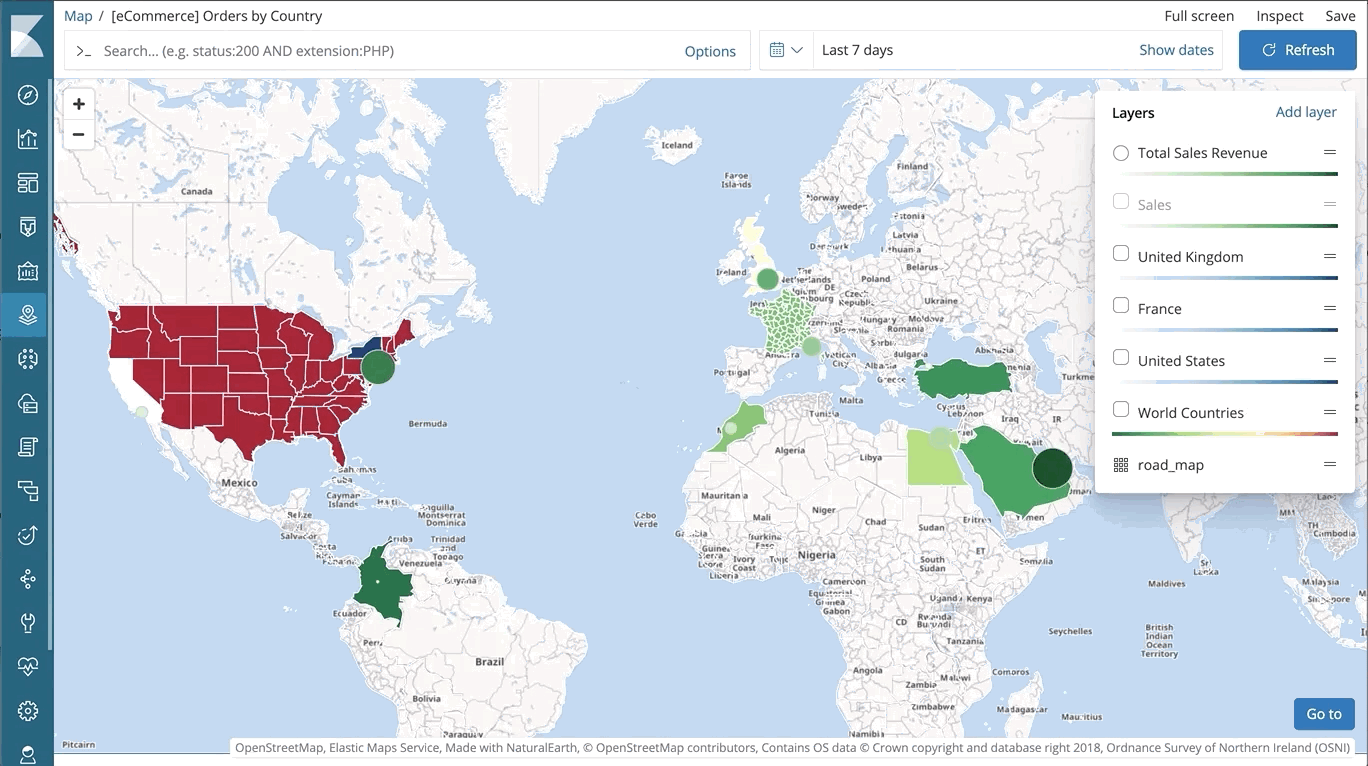
Eine Übersicht aller Details zu diesem Thema finden Sie in diesem Blog-Post zur Einführung von Elastic Maps.
Elastic Uptime: Aktive Überwachung der Uptime von Diensten und Anwendungen
In den letzten Versionen haben wir eine Vielzahl neuer Features, wie Autodiscovery für Kubernetes sowie die Lösungen Elastic Infrastructure und Elastic Logs, eingeführt, die Elastic-Nutzern mit Verantwortung für die Überwachung von Infrastrukturen und Beobachtbarkeit helfen, ihre Abläufe zu optimieren. Aufbauend auf diesen Aktivitäten bieten wir jetzt mit Elastic Uptime eine neue Lösung, die es Nutzern ermöglicht, ohne viel Aufwand festzustellen, ob Anwendungsdienste nicht erreichbar sind oder langsam reagieren, und sich proaktiv über Probleme benachrichtigen zu lassen, noch bevor diese Dienste von der Anwendung aufgerufen werden.
Elastic Uptime basiert auf Heartbeat, einem ressourcenschonenden Datenübermittler für das Uptime-Monitoring, und kann sowohl innerhalb als auch außerhalb des Unternehmensnetzwerks bereitgestellt werden. Die Lösung benötigt lediglich Netzwerkzugriff auf den zu überwachenden HTTP-, TCP- oder ICMP-Endpunkt. Als Anwendungsfälle für Elastic Uptime kommen u. a. die Host-Verfügbarkeit, das Dienst-Monitoring, das Website-Monitoring und das API-Monitoring infrage.
Die Bereitstellung von Uptime-Daten erweitert das bestehende Angebot an Logs, Metriken und Tracing-Daten in Elasticsearch und ermöglicht es so, alle Daten des Nutzers in einem einzigen Operational Data Store zu verfolgen und zu verwalten.
Mehr über die neue Lösung Elastic Uptime erfahren Sie in diesem ausführlichen Blog-Post.
Elasticsearch
6.7 ist ein wichtiger Schritt für Elasticsearch. Wir führen mit dieser Version nicht nur etliche neue Features ein, sondern überführen auch verschiedene wichtige Elasticsearch-Features in den Status „allgemein verfügbar“ und weisen sie damit als reif für den Einsatz in Produktionsumgebungen aus.
Wie bereits im Elasticsearch-Blog-Post erwähnt: Wenn es für ein Elasticsearch-Feature eine dreibuchstabige Abkürzung gibt, ist dies ein starkes Indiz dafür, dass das Feature in 6.7 jetzt allgemein verfügbar ist.
Cluster-übergreifende Replikation (CCR) jetzt „allgemein verfügbar“
Kaum ein Feature wurde so sehnlich erwartet, wie die Cluster-übergreifende Replikation (Cross Cluster Replication – CCR), die als Betaversion in Version 6.5 ihr Elasticsearch-Debüt gab. Für die CCR gibt es eine Vielzahl von Anwendungsfällen, wie beispielsweise die Replikation über Rechenzentren und Regionen hinweg, die Replikation von Daten, um sie näher an den Anwendungsserver und Nutzer zu bringen, und die Aufrechterhaltung eines zentralisierten Reporting-Clusters durch Replikation einer großen Zahl kleinerer Cluster.
Die Cluster-übergreifende Replikation wird mit Version 6.7 nicht nur allgemein verfügbar gemacht, sondern wir haben sie auch benutzerfreundlicher gestaltet. Näheres dazu erfahren Sie im Blog-Post zur Veröffentlichung von Elasticsearch 6.7.
Index-Lifecycle-Management (ILM) jetzt „allgemein verfügbar“
Das in Elasticsearch 6.6 als Betaversion eingeführte Feature Index-Lifecycle-Management (ILM) ist jetzt allgemein verfügbar und reif für den Einsatz in Produktionsumgebungen.
Ein entscheidender Faktor für die Optimierung der Cluster-Performance und -Kosten ist die Festlegung, was mit den Elasticsearch-Indizes passieren soll, je älter sie werden. Das ILM hilft Elasticsearch-Administratoren bei der Definition und Automatisierung dieser Lifecycle-Management-Richtlinien, also dabei festzulegen, wie Daten verwaltet und im Laufe ihres Lebenszyklus von der „heißen“ über die „warme“ und die „kalte“ Phase in die Phase „löschen“ überführt werden sollen.
Mit der Veröffentlichung von Version 6.7 wird das Index-Lifecycle-Management nicht nur öffentlich verfügbar gemacht, sondern auch um neue Funktionen erweitert. Die wichtigste Neuerung dabei ist, dass Nutzer jetzt in der „kalten“ Phase den Index einfrieren können, sodass deutlich weniger Heap-Ressourcen für die Indexspeicherung benötigt werden. Mehr dazu und zu anderen ILM-Verbesserungen finden Sie im ausführlichen Blog-Post zu Elasticsearch 6.7.
Elasticsearch SQL (einschließlich Clients für JDBC und ODBC) jetzt „allgemein verfügbar“
Elasticsearch SQL, eingeführt in Version 6.3, ermöglicht es Nutzern, für die Interaktion mit ihren Elasticsearch-Daten und zu deren Abfrage eine ihnen sehr vertraute Syntax zu benutzen: SQL. Damit wurde der Kreis derjenigen, die die Leistungsfähigkeit der Elasticsearch-Volltextsuche für ihre eigenen Zwecke nutzen können, beträchtlich erweitert. Zusätzlich zur Unterstützung der SQL-Abfragesyntax beinhaltet Elasticsearch SQL auch Clients für JDBC und ODBC, mit denen sich Drittanbieter-Tools, die diese Treiber unterstützen, mit Elasticsearch als Backend-Datenspeicher verbinden können.
Es freut uns sehr, dass wir all diese Features nun allgemein verfügbar machen können. Ausführliche Details finden Sie im Blog-Post zur Veröffentlichung von Elasticsearch 6.7.
Wir können hier in der Tat nur an der Oberfläche von Elasticsearch 6.7 kratzen. Die neue Version enthält noch eine ganze Menge anderer Verbesserungen und Neuerungen. Die Einzelheiten erfahren Sie im Blog-Post zur Veröffentlichung von Elasticsearch 6.7.
Kibana
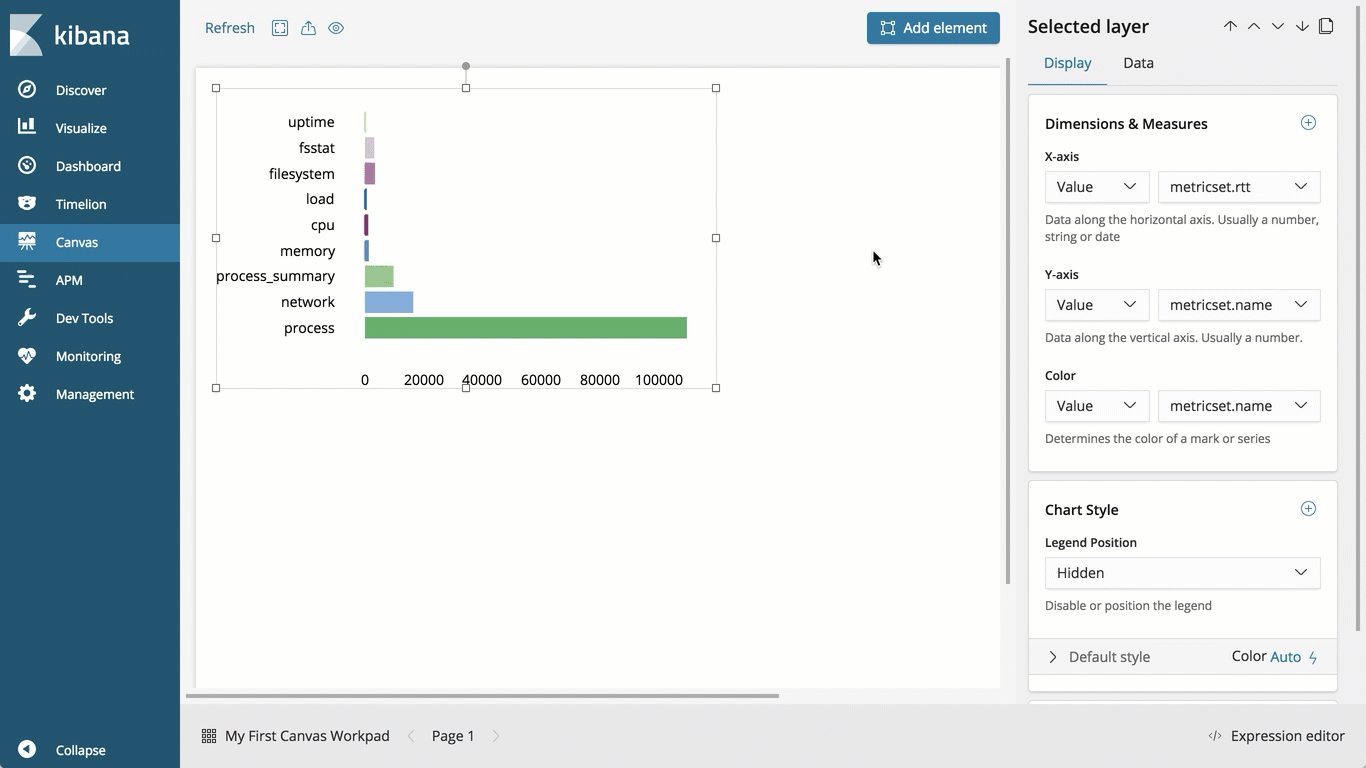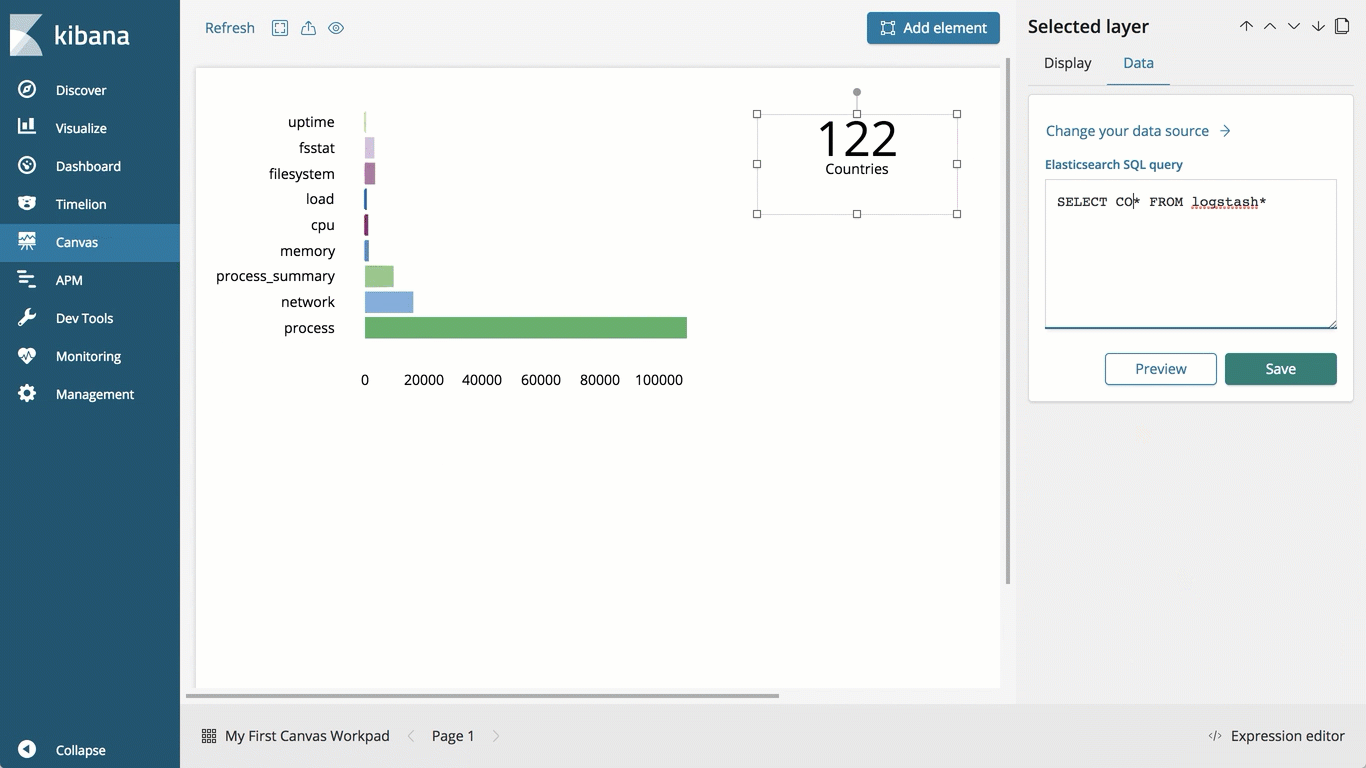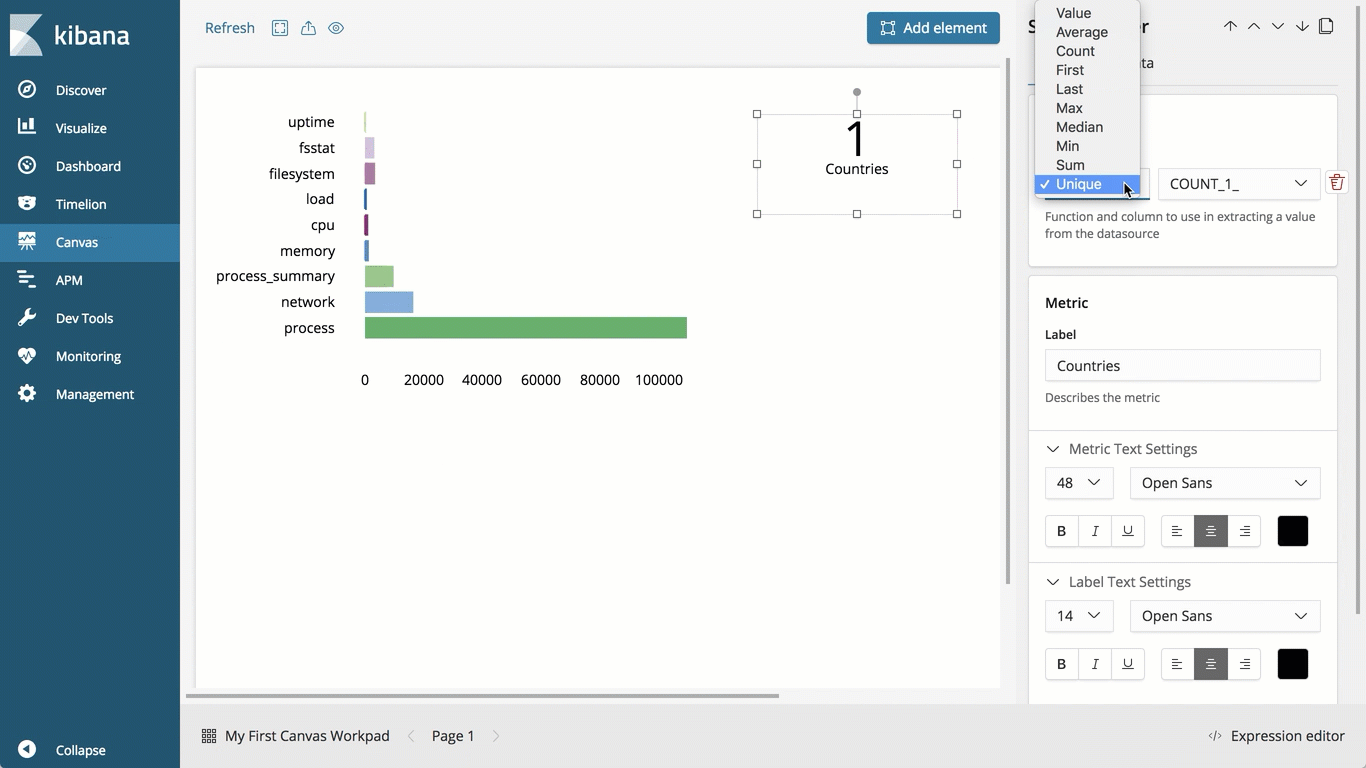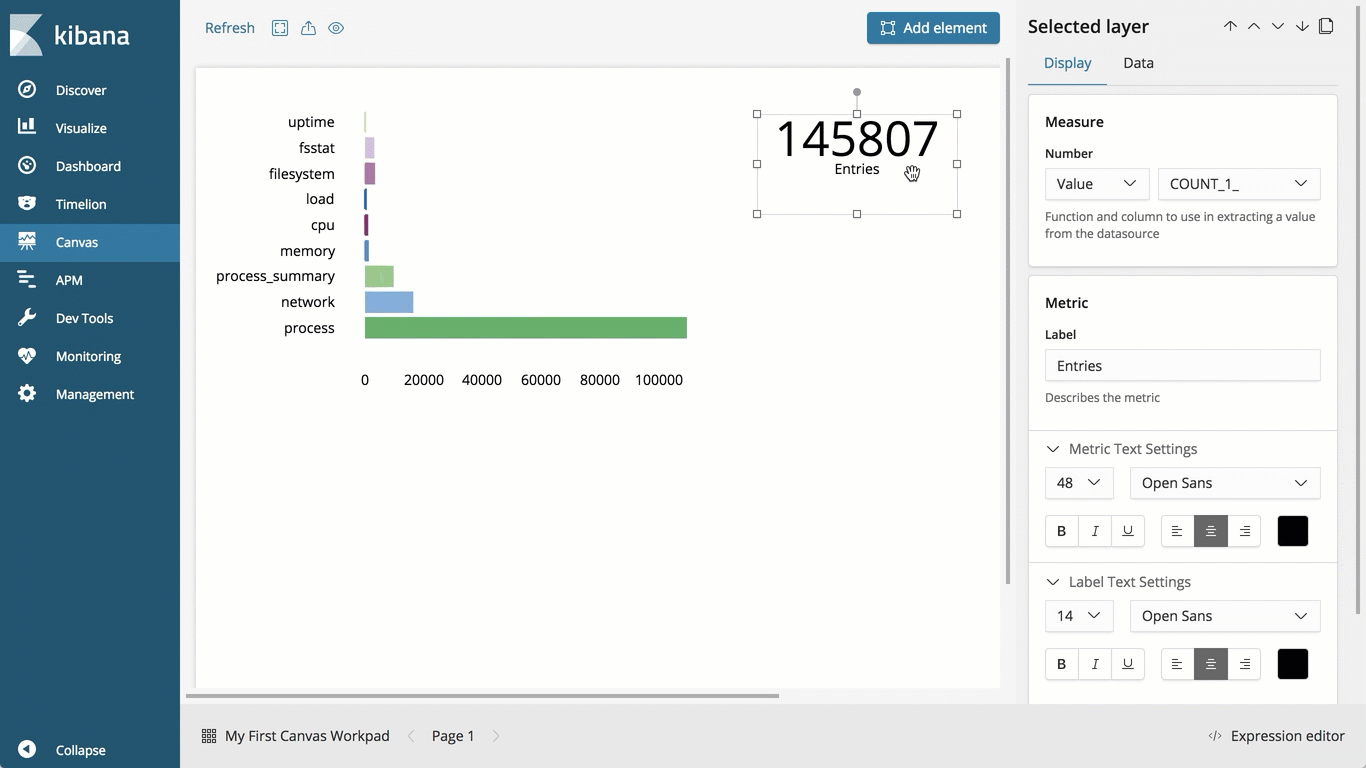
Canvas jetzt „allgemein verfügbar“
Canvas, als Betaversion seit Version 6.5 verfügbar, ermöglicht es Nutzern, Live-Daten aus Elasticsearch professionell aufzubereiten und zu präsentieren. Canvas erhält mit Veröffentlichung von Version 6.7 den Status „allgemein verfügbar“. Canvas eröffnet Nutzern ganz neue Möglichkeiten für das visuelle Präsentieren in Kibana. So können Sie Ihre Datenanalysen und Einblicke mit Canvas einem größerem Publikum nahebringen. Das Tool bietet uneingeschränkte Unterstützung für Elasticsearch SQL und ermöglicht es Elasticsearch-Nutzern – genau wie der JDBC- und der ODBC-Client –, die Reichweite und die Wirkung ihrer Daten auf ein breiteres Geschäftspublikum auszudehnen.
Kibana lokalisiert – den Anfang macht Chinesisch (vereinfacht)
Mit Version 6.7 ist Kibana zum ersten Mal in einer anderen Sprache als Englisch verfügbar. Die Lokalisierung ins (vereinfachte) Chinesisch ist der Startpunkt für eine breiter angelegte Lokalisierungsinitiative für Kibana. Neben der chinesischen Benutzeroberfläche wartet Kibana 6.7 auch mit einem neuen Lokalisierungs-Framework auf, der künftig die Unterstützung zusätzlicher Sprachen ermöglicht. Mit diesem Lokalisierungs-Framework erhalten Mitglieder der Elastic-Community Zugang zu den erforderlichen Tools, um eigene benutzerdefinierte Übersetzungen hinzufügen zu können.
Nähere Informationen zur allgemeinen Verfügbarkeit von Canvas, zur Kibana-Lokalisierung und zu anderen Features in Kibana 6.7 finden Sie im ausführlichen Blog-Post zur Einführung von Kibana 6.7.
Beats
Functionbeat jetzt allgemein verfügbar
Functionbeat ist eine neue Art von Beat, die in Serverless-Computing-Frameworks als Funktion bereitgestellt wird und Cloud-Infrastruktur-Logs und -Metriken nach Elasticsearch streamt. Dieses Feature wurde in Version 6.5 als Betaversion eingeführt und hat mit der Einführung der Version 6.7 den Status „allgemein verfügbar“ erhalten. Functionbeat unterstützt derzeit das AWS Lambda-Framework und kann Daten aus CloudWatch-Logs, SQS und Kinesis streamen.
Näheres zu Functionbeat und anderen Beats 6.7-Aktualisierungen finden Sie im Blog-Post zu Beats 6.7.
Elastic Logs und Elastic Infrastructure jetzt „allgemein verfügbar“
Die Lösungen Elastic Infrastructure und Elastic Logs wurden beide als Betafunktionen in Version 6.5 eingeführt. In Version 6.7 erhalten sie den Status „allgemein verfügbar“.
Elastic Logs ermöglicht das Überwachen von Logs in Echtzeit in einer kompakten und individuell anpassbaren Ansicht. Die Vorgehensweise ähnelt dabei dem Überwachen einer Datei – mit dem Unterschied, dass die Log-Einträge aus der gesamten Infrastruktur in einer einzelnen Streaming-Ansicht betrachtet werden können. Und dank einer eingebetteten Suchleiste, die ihre Ergebnisse über Elasticsearch bezieht, können Nutzer die Streaming-Ansicht problemlos auf die Logs eingrenzen, die für sie relevant sind.
Elastic Infrastructure bietet Nutzern einen Überblick über den Zustand aller Komponenten in ihrer Infrastruktur – Server, Kubernetes-Pods, Docker-Containers – und erleichtert so die Diagnose von Problemen anhand von Logs und Metriken. Die auf den Metricbeat-Funktionen zur automatischen Erkennung basierende maßgeschneiderte Benutzeroberfläche ermöglicht es den Nutzern, mit nur einem Klick eine interaktive Ansicht der Logs, Metriken und APM-Traces aufzurufen, in die sie dann tiefer eintauchen können.
Upgrade-Assistent zur Vorbereitung auf 7.0
7.0.0 steht vor der Tür (Informationen zur Betaversion finden Sie hier). Version 6.7 enthält einen Upgrade-Assistenten, der Ihnen dabei hilft, Ihre bestehende Elastic Stack-Umgebung für das Upgrade auf Version 7.0 vorzubereiten. Der Upgrade-Assistent, der sowohl APIs als auch UIs enthält, ist ein wichtiges Tool zur Cluster-Prüfung, das Ihnen bei der Planung Ihres Upgrades hilft und in der Lage ist, Warnungen zu künftig nicht mehr unterstützten Funktionen, Upgrade- oder neuindexierungspflichtige Indizes und vieles andere mehr zu erkennen, um den Umstieg auf Version 7.0 möglichst reibungslos zu gestalten.
Jetzt ausprobieren
Stellen Sie ein Cluster auf unserem Elasticsearch Service bereit oder laden Sie den Stack herunter und machen Sie sich selbst ein Bild von den neuesten Features.