Erstellen eines benutzerdefinierten ServiceNow-Incident-Dashboards in Canvas
Willkommen zurück! Dies ist der dritte und letzte Teil unserer Reihe zur Nutzung des Elastic Stack mit ServiceNow für die Incident-Verwaltung. Im ersten Blogeintrag haben wir das Projekt vorgestellt und ServiceNow so eingerichtet, dass Änderungen an Incidents automatisch zurück zu Elasticsearch übertragen werden. Im zweiten Beitrag haben wir die Logik implementiert, um ServiceNow und Elasticsearch über Warnungen und Transformationen miteinander zu kombinieren, und haben die Elasticsearch-Konfiguration angepasst.
Die Lösung ist an dieser Stelle komplett einsatzbereit. Uns fehlt jedoch das praktische (und ansprechende) Front-End für die Incident-Verwaltung! In diesem Blogeintrag erstellen wir das unten gezeigte Canvas-Workpad, damit die Benutzer unsere bisher geschaffenen Werte in leicht verständliche und nutzbare Daten umwandeln können.
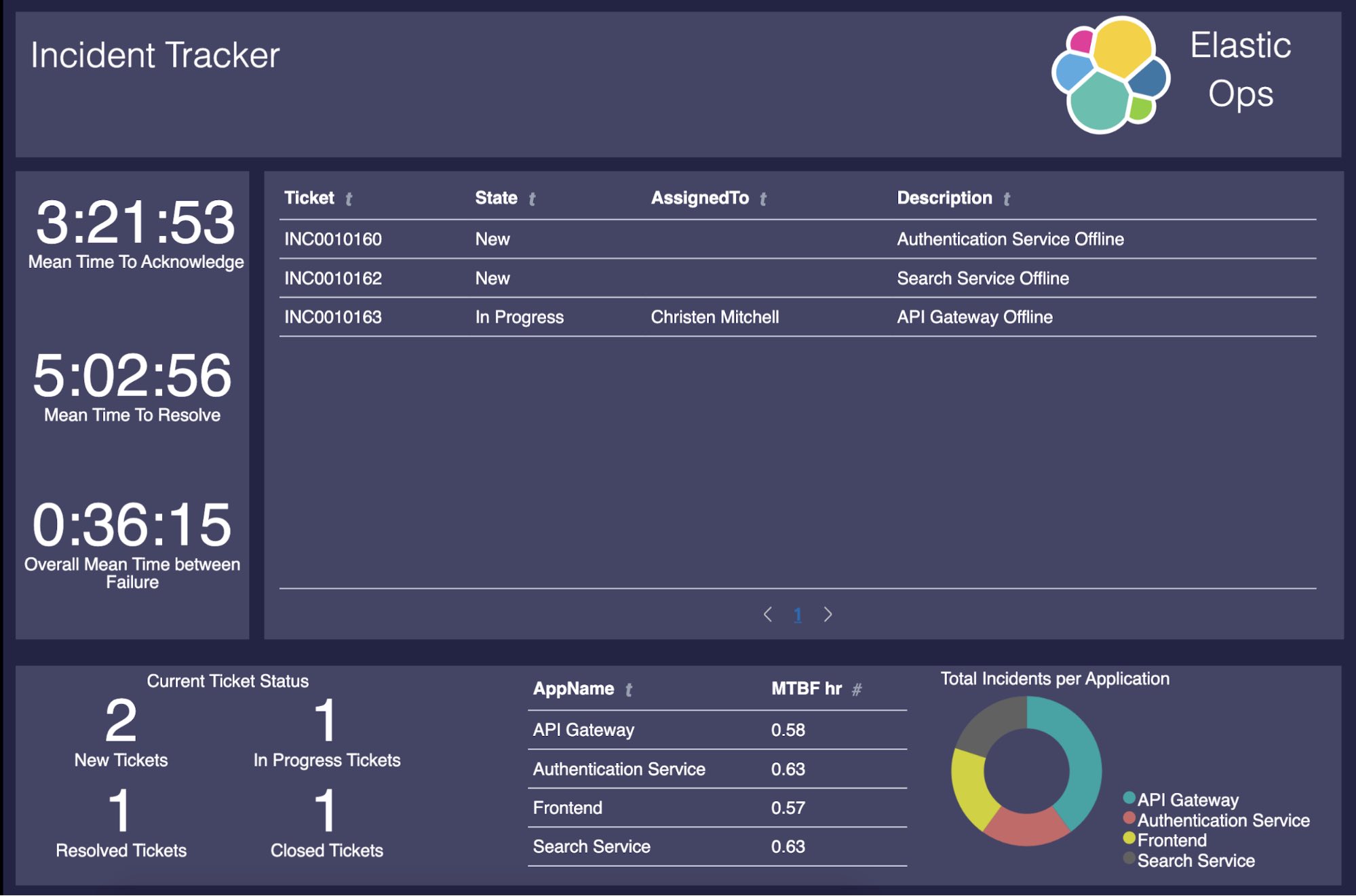
In unserem Dashboard werden wir Folgendes anzeigen:
- Offene, geschlossene, behobene und ausstehende Tickets
- MTTA (mittlere Dauer bis zur Bestätigung)
- MTTR (mittlere Wiederherstellungsfrist)
- MTBF (mittleres Intervall zwischen Fehlern) gesamt
- MTBF pro Anwendung
- Incident pro Anwendung
Lassen Sie uns anfangen.
Canvas-Workpad einrichten
In diesem Beitrag verwenden wir zahlreiche Canvas-Ausdrücke, da sämtliche Elemente in einem Workpad in der Praxis durch Ausdrücke dargestellt werden. Ausdrücke sind daher der einfachste Weg, um die Erstellung von Funktionen zu demonstrieren.
Falls Sie keine Daten in den Entity-zentrischen Indizes haben, die von den Transformationen ausgefüllt werden, kann es passieren, dass einige der folgenden Elemente eine Fehlermeldung aufgrund einer leeren Datentabelle ausgeben.
Bevor wir anfangen, öffnen wir zunächst Canvas:
- Erweitern Sie die Kibana-Toolbar.
- Falls Sie Version 7.8 oder höher verwenden, finden Sie diese Leiste unter Kibana, andernfalls befindet sie sich in der Liste der restlichen Symbole.
- Klicken Sie auf die Schaltfläche Workpad erstellen.
- Warten Sie, bis das Workpad erstellt wurde, und geben Sie ihm einen Namen. Sie können den Namen rechts unter Workpad-Einstellungen festlegen. Ich empfehle, „My Canvas Workpad“ zu „Incident Tracker“ zu ändern. Hier werden wir auch die Hintergrundfarbe in den nächsten Schritten festlegen.
- Um den Canvas-Ausdruck für eine bestimmte Komponente zu ändern, klicken Sie auf die Komponente und dann unten rechts auf den </> Expression editor.
Design einrichten
Zunächst legen wir das Hintergrunddesign für unser Canvas-Workpad fest:
- Legen Sie die Hintergrundfarbe auf #232344 fest.
- Erstellen Sie vier rechteckige Form-Elemente und legen Sie die Füllfarbe auf #444465 fest.
- Fügen Sie Logo und Text in der oberen Leiste sowie Firmenlogo, Firmenname und Titel hinzu.
Aktive Tickets anzeigen
Als nächstes werden wir die Tabelle in der Mitte so konfigurieren, dass die aktiven Tickets angezeigt werden. Dazu verwenden wir eine Kombination aus Elasticsearch SQL und Canvas-Ausdrücken zusammen mit einem „data table“-Element. Um das „data table“-Element zu erstellen, kopieren Sie den folgenden Canvas-Ausdruck in den Editor und klicken Sie auf „Ausführen“:
filters
| essql
query="SELECT incidentID as Ticket, LAST(state, updatedDate) as State, LAST(assignedTo, updatedDate) as AssignedTo, LAST(description, updatedDate) as Description FROM \"servicenow*\" group by Ticket ORDER BY Ticket ASC"
| filterrows fn={getCell "State" | any {eq "New"} {eq "On Hold"} {eq "In Progress"}}
| table
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false} paginate=true perPage=10
| render
In diesem Ausdruck führen wir die Abfrage aus und filtern anschließend alle Zeilen heraus mit Ausnahme der Zeilen, deren Feld „State“ einen der Werte „New“, „On Hold“ oder „In Progress“ hat.
An dieser Stelle ist die Tabelle vermutlich leer, da wir noch keine Daten haben. Dies liegt daran, dass unsere Geschäftsregel möglicherweise noch nicht ausgeführte wurde und Elasticsearch daher noch keine ServiceNow-Daten enthält. Wenn Sie möchten, können Sie jetzt einige fiktive Incidents erstellen. Achten Sie in diesem Fall darauf, Tickets mit verschiedenen Zuständen zu erstellen, damit die Tabelle möglichst realistisch aussieht.
Mittlere Dauer bis zur Bestätigung (MTTA) berechnen
Um die MTTA für Vorfälle anzuzeigen, fügen wir ein Metrikelement hinzu und verwenden den folgenden Canvas-Ausdruck.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'In Progress' as \"InProgress\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "InProgress" fn={getCell "InProgress" | formatdate "X" | math "value"}
| filterrows fn={getCell "InProgress" | gt 0}
| mapColumn "Duration" expression={math expression="InProgress - New"}
| math "mean(Duration)"
| metric "Mean Time To Acknowledge"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Dieser Ausdruck verwendet etwas kompliziertere Elasticsearch SQL-Funktionen, wie etwa PIVOT. Um die MTTA zu ermitteln, berechnen wir die Gesamtdauer zwischen Erstellung und Bestätigung und teilen diesen Wert durch die Anzahl der Incidents. Wir müssen PIVOT verwenden, da wir alle Änderungen der Nutzer am Ticket in ServiceNow speichern. Dies bedeutet, dass alle Änderungen an Zustand, Notizen, zugewiesenen Personen usw. an Elasticsearch übertragen werden. Damit lassen sich fantastische Analysen über die Ergebnisse ausführen. Allerdings müssen wir daher auch die PIVOT-Funktion auf die Daten anwenden, um je eine Zeile pro Incident für den Status „New“ und die Statusänderung zu „In Progress“ zu erhalten.
Anschließend können wir die Dauer bis zur Bestätigung berechnen, indem wir den Erstellungszeitpunkt des Incidents vom Bestätigungszeitpunkt subtrahieren. Wir berechnen die MTTA, indem wir die „mean“-Funktion auf dieses Dauerfeld anwenden.
Mittlere Wiederherstellungsfrist (MTTR) berechnen
Um die MTTR für Vorfälle anzuzeigen, fügen wir ein Metrikelement hinzu und verwenden den folgenden Canvas-Ausdruck:
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'Resolved' as \"Resolved\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "Resolved" fn={getCell "Resolved" | formatdate "X" | math "value"}
| filterrows fn={getCell "Resolved" | gt 0}
| mapColumn "Duration" expression={math expression="Resolved - New"}
| math "mean(Duration)"
| metric "Mean Time To Resolve"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Wie auch bei der MTTA-Berechnung verwenden wir die PIVOT-Funktion, da wir eine Zusammenfassung pro Incident betrachten möchten. Im Gegensatz zur MTTA betrachten wir jedoch den Zeitpunkt der Erstellung und den Zeitpunkt der Behebung. Dies liegt daran, dass wir für die MTTR die Dauer bis zur Behebung der Tickets ermitteln. Die Logik ist sehr ähnlich wie bei der MTTA-Berechnung, daher werde ich die Details nicht noch einmal wiederholen.
Mittleres Intervall zwischen Fehlern (MTBF) gesamt berechnen
Nachdem wir MTTA und MTTR berechnet haben, können wir die MTBF pro Anwendung ermitteln. Dazu verwenden wir zwei Transformationen: app_incident_summary_transform und calculate_uptime_hours_online_transfo. Diese beiden Transformationen sind eine große Hilfe bei der Berechnung der MTBF gesamt. Die MTBF wird in Stunden gemessen, und unsere Transformation rechnet in Sekunden. Daher berechnen wir den Mittelwert für alle Apps und multiplizieren das Ergebnis anschließend mit 3600 (Sekunden in einer Stunde).
Wir erstellen ein weiteres Metrikelement mit dem folgenden Canvas-Ausdruck:
filters
| essql query="SELECT AVG(mtbf) * 3600 as MTBF FROM app_incident_summary"
| math "MTBF"
| metric "Overall Mean Time between Failure"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Mittleres Intervall zwischen Fehlern (MTBF) pro Anwendung berechnen
Nachdem wir den MTBF-Gesamtwert berechnet haben, können wir die MTBF pro Anwendung mühelos anzeigen. Wir verwenden den folgenden Canvas-Ausdruck, um ein neues „data table“-Element zu erstellen und die Daten in einer Tabelle anzuzeigen. Ich runde die MTBF pro Anwendung auf zwei Nachkommastellen, um die Lesbarkeit zu verbessern.
filters
| essql
query="SELECT app_name as AppName, ROUND(mtbf,2) as \"MTBF hr\" FROM app_incident_summary"
| table paginate=false
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Behobene Tickets berechnen
Wir brauchen Erfolgserlebnisse, daher fügen wir einen Zähler für die abgeschlossenen Tickets zu unserem Workpad hinzu. Dieses einfache Metrikelement ruft alle Incidents mit dem Status „Resolved“ ab und zählt die Anzahl der eindeutigen Incident-IDs mit der „math“-Funktion.
filters
| essql query="SELECT state,incidentID FROM \"servicenow*\" where state = 'Resolved'"
| math "unique(incidentID)"
| metric "Resolved Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Incidents pro Anwendung berechnen
Als nächstes erstellen wir ein Kreisdiagramm, um die Anzahl der eindeutigen Incidents pro Anwendung zu zählen. Sie können ein Markdown-Element mit dem Text „Incidents gesamt pro Anwendung“ über dem Diagramm erstellen, um den Kontext des Kreisdiagramms zu erklären.
filters
| essql
query="SELECT incidentID as IncidentCount, app_name as AppName FROM \"servicenow*\""
| pointseries color="AppName" size="unique(IncidentCount)"
| pie hole=41 labels=false legend="se" radius=0.72
palette={palette "#01A4A4" "#CC6666" "#D0D102" "#616161" "#00A1CB" "#32742C" "#F18D05" "#113F8C" "#61AE24" "#D70060" gradient=false} tilt=1
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Aktuelle Ticketstatus berechnen
Dieser Abschnitt enthält vier Metrikelemente. Sie alle verwenden sehr ähnliche Canvas-Ausdrücke, jeweils mit kleinen Änderungen. Kurz gesagt rufen wir die letzte Aktualisierung pro Incident ab und verwenden die Canvas-Ausdrucksfunktion „filterrows“, um die gewünschten Zeilen anhand des Status beizubehalten. Anschließend können wir die Anzahl der eindeutigen Incidents zählen.
Verwenden Sie den folgenden Ausdruck und aktualisieren Sie den Status von „New“ zum jeweils gewünschten Ausdruck. Vergessen Sie nicht, den Text der Metrik von „New Tickets“ zum jeweiligen Status zu ändern.
filters
| essql
query="SELECT incidentID, LAST(state, updatedDate) as State FROM \"servicenow*\" group by incidentID" count=1000
| filterrows fn={getCell "State" | eq 'New'}
| math "unique(incidentID)"
| metric "New Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Fertiges Produkt
Nachdem wir also alle Komponenten unseres Canvas-Workpad erstellt haben, erhalten wir dieses extrem nützliche Incident-Verwaltungs-Dashboard:
Wir sind fertig, und Sie können Ihr erlerntes Wissen umsetzen!
Das wars! Auf unserer Reise haben wir verschiedene Komponenten des Elastic Stack verwendet, um MTTA, MTTR und MTBF für ServiceNow-Incidents zu berechnen, und haben diese Informationen anschließend in einem nützlichen und optisch ansprechenden Dashboard präsentiert. Dabei haben wir gelernt, dass diese Informationen parallel zu Ihren tatsächlichen Daten existieren, anstatt in einem separaten Tool. Diese Metriken liefern eine gute Wissensbasis, mit der wir die Integrität einer Anwendung im Verhältnis zu den gemeldeten Incidents überprüfen können. Ein sehr niedriger MTBF-Wert bedeutet beispielsweise, dass eine Anwendung sehr fehleranfällig ist. Ein hoher MTTA-Wert deutet darauf hin, dass es sehr lange dauert, bis die Untersuchung zu einem Fehler beginnt.
Falls Sie nur mitgelesen und die Schritte nicht selbst ausprobiert haben, möchte ich Sie dazu ermutigen, die Ärmel hochzukrempeln und selbst Hand anzulegen. Sie können eine kostenlose Testversion von Elastic Cloud einrichten und mit Ihrer vorhandenen ServiceNow-Instanz oder mit einer persönlichen Entwickler-Instanz verwenden.
Falls Sie neben ServiceNow-Daten auch weitere Quellen wie GitHub, Google Drive und mehr durchsuchen möchten, können Sie den vorab erstellten ServiceNow-Connector in Elastic Workplace Search verwenden. Workplace Search bietet ein einheitliches Sucherlebnis für Ihre Teams mit relevanten Ergebnissen aus sämtlichen Inhaltsquellen. Die Lösung ist ebenfalls in Ihrer Elastic Cloud-Testversion enthalten.
In diesem Blogeintrag haben Sie erfahren, wie Sie Ihre Daten nutzen können, um diese Metriken nachzuverfolgen. Als weiterführendes Beispiel können Sie etwa Incidents auf Basis Ihrer Logs, Infrastrukturmetriken, APM-Traces oder Ihrer Machine Learning-Anomalien erstellen. Falls Sie dieses Canvas-Dashboard noch benutzerfreundlicher gestalten möchten, können Sie beispielsweise Links zu den Apps in Kibana (Logs, APM usw.) oder zu Ihren eigenen Dashboards hinzufügen, um die Suche nach der Ursache für das jeweilige Problem zu beschleunigen.
Falls Ihnen diese Beitragsreihe gefallen hat, empfehle ich Ihnen die folgenden Links (in englischer Sprache):
- When to use Data Transforms
- Getting started with machine learning
- Intro to Canvas: A new way to tell visual stories in Kibana
- Hinzufügen von Links mit dem Canvas-Metrikelement und mit Markdown
Viel Spaß!