Prévision à la demande avec Machine Learning dans Elasticsearch
Remarque de l'éditeur (3 août 2021) : Cet article utilise des fonctionnalités obsolètes. Veuillez consulter la documentation sur le mappage de régions personnalisées avec le géocodage inverse pour obtenir des instructions en vigueur.
La prévision à la demande est la toute nouvelle fonctionnalité de machine learning contenue dans la version 6.1 d'X-Pack. Jusqu'ici, la solution Machine Learning d'Elastic était conçue pour exploiter les données historiques et prévoir la plage de valeurs normales à laquelle on pouvait s'attendre "maintenant". On la comparait ensuite aux données réellement enregistrées pour identifier les anomalies en temps réel. Avec la version 6.1, Machine Learning peut maintenant modéliser vos données et prédire plusieurs intervalles de temps dans le futur.
C'est ce que nous appelons la "prévision à la demande". Les utilisateurs peuvent exploiter le modèle prédictif d'une tâche de machine learning existante pour prévoir son évolution au fil des jours concernés par la prévision. Les résultats de la prévision sont écrits dans un index Elasticsearch, ce qui permet aux utilisateurs de comparer les résultats réels aux modèles prédictifs.
Planification et prévision de la capacité avec Machine Learning
On a souvent entendu dire que les performances passées ne présagent pas des résultats à venir. Il n'en demeure pas moins que le meilleur moyen de prédire des résultats en matière de planification de capacité reste d'utiliser les indicateurs de performances passés.
Comment déterminer le moment où une ressource donnée atteindra ses limites de capacité ? Par exemple, lorsque vous monitorez l'espace disque de votre serveur, vous avez besoin d'évaluer à quel moment vous ne disposerez plus d'espace libre. Vous pouvez donc utiliser les modèles de machine learning prédictif d'Elastic pour prévoir ce qui vous attend et identifier le moment où vous devrez ajouter des capacités de stockage au système.
Autre possibilité en matière de planification de capacité : prévoir un indicateur de volume associé à un moment donné dans le futur. Par exemple, vous pouvez tenter de prédire le nombre d'appels client auquel vous pouvez vous attendre un lundi après-midi. Grâce à l'analyse des données historiques et à l'utilisation de modèles de machine learning complexes, vous obtenez l'information dont vous avez besoin pour décider des effectifs et des ressources à mobiliser ce jour-là.
Vos premières prévisions
Vous pouvez exécuter des prévisions depuis l'onglet "Single Metric Viewer" de vos tâches de machine learning existantes. Une fois le système mis à jour vers la version 6.1, un nouveau bouton d'option s'affiche en haut à droite et vous permet de lancer des tâches de prévision.
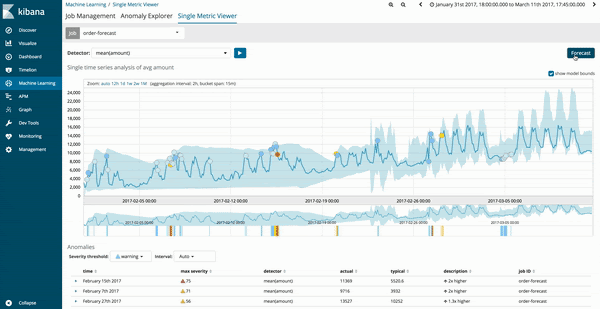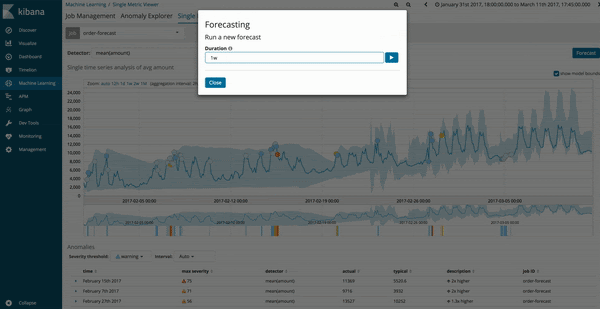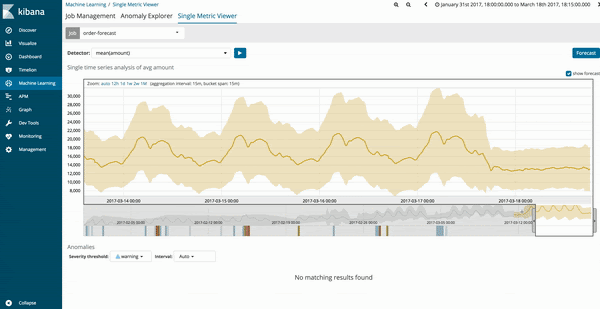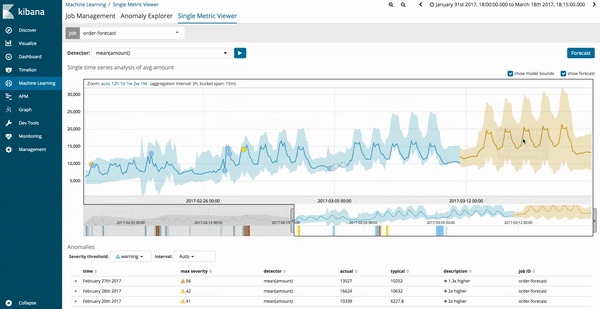
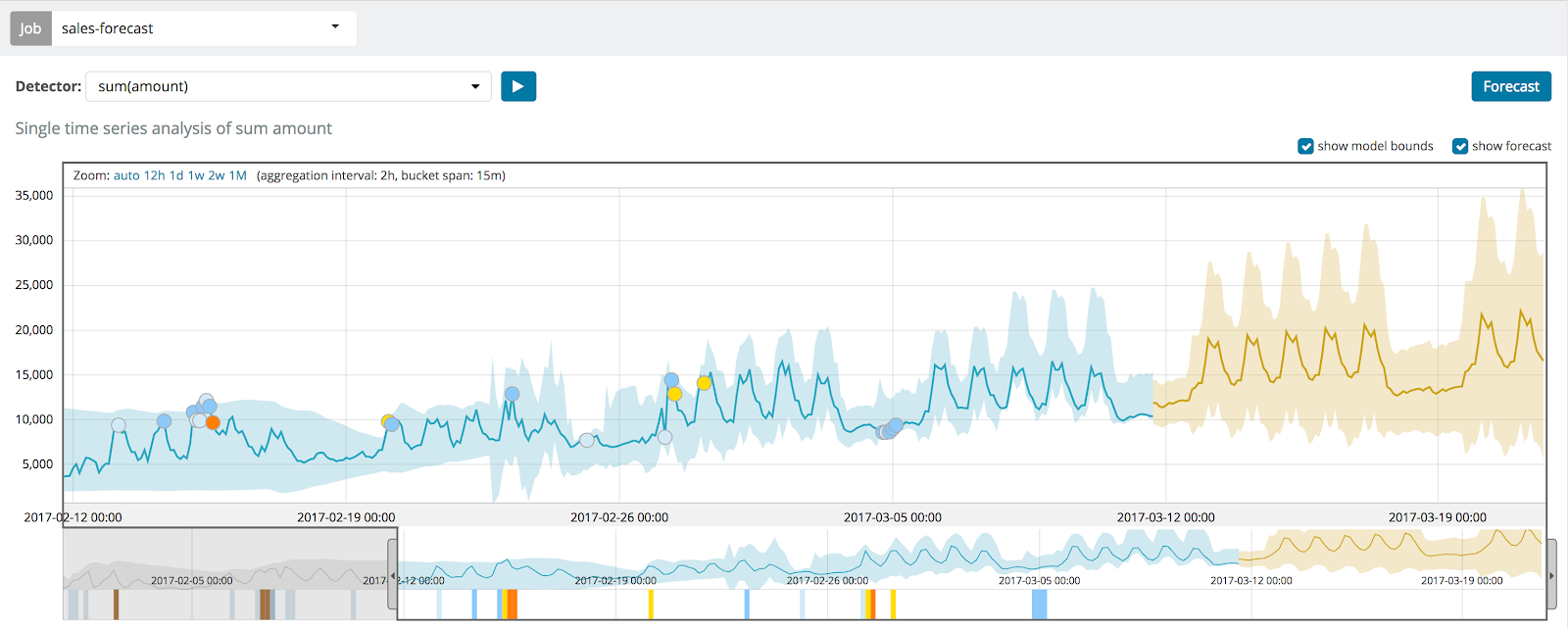
Les résultats de la prédiction de la tâche de machine learning sont représentés par une courbe de tendance jaune foncé, et le niveau de confiance du modèle par une bande jaune clair. Plus la bande jaune clair est étroite, plus le niveau de confiance de la prédiction est élevé. A contrario, plus elle est large, plus le niveau de confiance du modèle prédictif est faible.
Ce qu'il faut garder à l'esprit au moment de créer un modèle prédictif
Lorsque vous créez des modèles prédictifs, vous devez tenir compte de différents éléments pour mieux comprendre les résultats. Les résultats des prévisions peuvent être différents de ceux que vous imaginiez et cela ne fonctionne pas avec tous les ensembles de données.
Avant d'exécuter une tâche de machine learning prédictif, nous vous recommandons de collecter un volume suffisant de données historiques. Idéalement, vous devez disposer de trois semaines de données ou de trois intervalles complets de données périodiques. Si vous exécutez une prévision à un moment prématuré de la phase d'apprentissage, c'est-à-dire avant que le modèle ne soit bien établi, vos résultats seront probablement inutilisables.
Si le niveau de confiance de la prévision se trouve en deçà des limites raisonnables, le modèle prédictif s'arrête prématurément. La tâche de prévision s'interrompt et un message semblable à celui ci-dessous s'affiche, indiquant que le niveau de confiance se trouve hors des limites acceptables.

Les résultats des prévisions sont bien plus faciles à interpréter si l'option "Model Plot" est activée. Cette option est activée par défaut sur les tâches à indicateur unique. Pour activer l'option "Model Plot" sur les tâches à plusieurs indicateurs, vous devez configurer l'option "model-plot-config" dans les paramètres de la tâche de machine learning.
Pour permettre le suivi des prévisions hors de "Single Metric Viewer", chacune d'entre elles dispose d'un identifiant unique : forecast_ID. Cela vous permet de rechercher chacune de vos prévisions séparément. Par ailleurs, vous pouvez exécuter plusieurs prévisions pour un même indicateur, mais l'interface utilisateur n'affiche que les cinq dernières prévisions exécutées pour un indicateur unique. Pour autant, toutes les prévisions restent disponibles et occupent l'espace d'indexation correspondant. Les résultats des prévisions sont automatiquement supprimés au bout de 14 jours si vous les exécutez depuis l'interface utilisateur. En revanche, si vous utilisez directement l'API, vous pouvez définir le délai d'expiration des données. Pour en savoir plus, consultez le documentation relative aux tâches de prévision.
Machine Learning est inclus dans les abonnements Platinum Elastic. Pour l'essayer gratuitement, vous pouvez télécharger la version d'essai d'X-Pack.