WARNING: Version 1.3 of Elasticsearch has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Cardinality Aggregation
editCardinality Aggregation
editAdded in 1.1.0.
A single-value metrics aggregation that calculates an approximate count of
distinct values. Values can be extracted either from specific fields in the
document or generated by a script.
Experimental!
This feature is marked as experimental, and may be subject to change in the future. If you use this feature, please let us know your experience with it!
Assume you are indexing books and would like to count the unique authors that match a query:
{
"aggs" : {
"author_count" : {
"cardinality" : {
"field" : "author"
}
}
}
}
This aggregation also supports the precision_threshold and rehash options:
{
"aggs" : {
"author_count" : {
"cardinality" : {
"field" : "author_hash",
"precision_threshold": 100,
"rehash": false
}
}
}
}
|
The |
|
|
If you computed a hash on client-side, stored it into your documents and want
Elasticsearch to use them to compute counts using this hash function without
rehashing values, it is possible to specify |
Counts are approximate
editComputing exact counts requires loading values into a hash set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This cardinality aggregation is based on the
HyperLogLog++
algorithm, which counts based on the hashes of the values with some interesting
properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of c, the implementation that we are using requires
about c * 8 bytes.
The following chart shows how the error varies before and after the threshold:
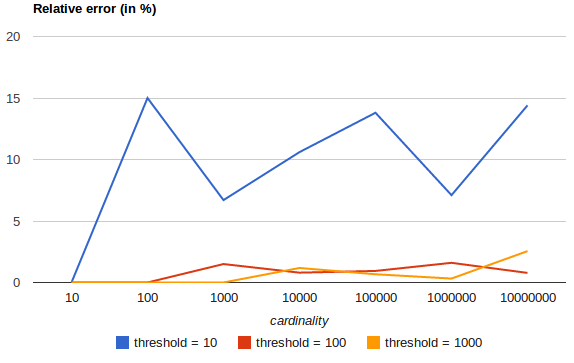
For all 3 thresholds, counts have been accurate up to the configured threshold (although not guaranteed, this is likely to be the case). Please also note that even with a threshold as low as 100, the error remains under 5%, even when counting millions of items.
Pre-computed hashes
editIf you don’t want Elasticsearch to re-compute hashes on every run of this
aggregation, it is possible to use pre-computed hashes, either by computing a
hash on client-side, indexing it and specifying rehash: false, or by using
the special murmur3 field mapper, typically in the context of a multi-field
in the mapping:
{
"author": {
"type": "string",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
With such a mapping, Elasticsearch is going to compute hashes of the author
field at indexing time and store them in the author.hash field. This
way, unique counts can be computed using the cardinality aggregation by only
loading the hashes into memory, not the values of the author field, and
without computing hashes on the fly:
{
"aggs" : {
"author_count" : {
"cardinality" : {
"field" : "author.hash"
}
}
}
}
rehash is automatically set to false when computing unique counts on
a murmur3 field.
Pre-computing hashes is usually only useful on very large and/or high-cardinality fields as it saves CPU and memory. However, on numeric fields, hashing is very fast and storing the original values requires as much or less memory than storing the hashes. This is also true on low-cardinality string fields, especially given that those have an optimization in order to make sure that hashes are computed at most once per unique value per segment.
Script
editThe cardinality metric supports scripting, with a noticeable performance hit
however since hashes need to be computed on the fly.
{
"aggs" : {
"author_count" : {
"cardinality" : {
"script": "doc['author.first_name'].value + ' ' + doc['author.last_name'].value"
}
}
}
}