Tutorial: Disaster recovery based on uni-directional cross-cluster replication
editTutorial: Disaster recovery based on uni-directional cross-cluster replication
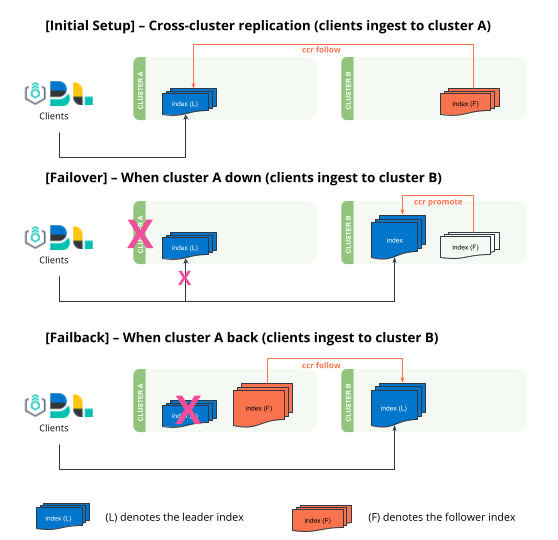
editLearn how to failover and failback between two clusters based on uni-directional cross-cluster replication. You can also visit Bi-directional disaster recovery to set up replicating data streams that automatically failover and failback without human intervention.
-
Setting up uni-directional cross-cluster replication replicated from
clusterAtoclusterB. -
Failover - If
clusterAgoes offline,clusterBneeds to "promote" follower indices to regular indices to allow write operations. All ingestion will need to be redirected toclusterB, this is controlled by the clients (Logstash, Beats, Elastic Agents, etc). -
Failback - When
clusterAis back online, it assumes the role of a follower and replicates the leader indices fromclusterB.
Cross-cluster replication provides functionality to replicate user-generated indices only. Cross-cluster replication isn’t designed for replicating system-generated indices or snapshot settings, and can’t replicate ILM or SLM policies across clusters. Learn more in cross-cluster replication limitations.
Prerequisites
editBefore completing this tutorial, set up cross-cluster replication to connect two clusters and configure a follower index.
In this tutorial, kibana_sample_data_ecommerce is replicated from clusterA to clusterB.
resp = client.cluster.put_settings(
persistent={
"cluster": {
"remote": {
"clusterA": {
"mode": "proxy",
"skip_unavailable": "true",
"server_name": "clustera.es.region-a.gcp.elastic-cloud.com",
"proxy_socket_connections": "18",
"proxy_address": "clustera.es.region-a.gcp.elastic-cloud.com:9400"
}
}
}
},
)
print(resp)
response = client.cluster.put_settings(
body: {
persistent: {
cluster: {
remote: {
"clusterA": {
mode: 'proxy',
skip_unavailable: 'true',
server_name: 'clustera.es.region-a.gcp.elastic-cloud.com',
proxy_socket_connections: '18',
proxy_address: 'clustera.es.region-a.gcp.elastic-cloud.com:9400'
}
}
}
}
}
)
puts response
const response = await client.cluster.putSettings({
persistent: {
cluster: {
remote: {
clusterA: {
mode: "proxy",
skip_unavailable: "true",
server_name: "clustera.es.region-a.gcp.elastic-cloud.com",
proxy_socket_connections: "18",
proxy_address: "clustera.es.region-a.gcp.elastic-cloud.com:9400",
},
},
},
},
});
console.log(response);
### On clusterB ###
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"clusterA": {
"mode": "proxy",
"skip_unavailable": "true",
"server_name": "clustera.es.region-a.gcp.elastic-cloud.com",
"proxy_socket_connections": "18",
"proxy_address": "clustera.es.region-a.gcp.elastic-cloud.com:9400"
}
}
}
}
}
resp = client.ccr.follow(
index="kibana_sample_data_ecommerce2",
wait_for_active_shards="1",
remote_cluster="clusterA",
leader_index="kibana_sample_data_ecommerce",
)
print(resp)
const response = await client.ccr.follow({
index: "kibana_sample_data_ecommerce2",
wait_for_active_shards: 1,
remote_cluster: "clusterA",
leader_index: "kibana_sample_data_ecommerce",
});
console.log(response);
### On clusterB ###
PUT /kibana_sample_data_ecommerce2/_ccr/follow?wait_for_active_shards=1
{
"remote_cluster": "clusterA",
"leader_index": "kibana_sample_data_ecommerce"
}
Writes (such as ingestion or updates) should occur only on the leader index. Follower indices are read-only and will reject any writes.
Failover when clusterA is down
edit-
Promote the follower indices in
clusterBinto regular indices so that they accept writes. This can be achieved by:- First, pause indexing following for the follower index.
- Next, close the follower index.
- Unfollow the leader index.
- Finally, open the follower index (which at this point is a regular index).
resp = client.ccr.pause_follow( index="kibana_sample_data_ecommerce2", ) print(resp) resp1 = client.indices.close( index="kibana_sample_data_ecommerce2", ) print(resp1) resp2 = client.ccr.unfollow( index="kibana_sample_data_ecommerce2", ) print(resp2) resp3 = client.indices.open( index="kibana_sample_data_ecommerce2", ) print(resp3)response = client.ccr.pause_follow( index: 'kibana_sample_data_ecommerce2' ) puts response response = client.indices.close( index: 'kibana_sample_data_ecommerce2' ) puts response response = client.ccr.unfollow( index: 'kibana_sample_data_ecommerce2' ) puts response response = client.indices.open( index: 'kibana_sample_data_ecommerce2' ) puts response
const response = await client.ccr.pauseFollow({ index: "kibana_sample_data_ecommerce2", }); console.log(response); const response1 = await client.indices.close({ index: "kibana_sample_data_ecommerce2", }); console.log(response1); const response2 = await client.ccr.unfollow({ index: "kibana_sample_data_ecommerce2", }); console.log(response2); const response3 = await client.indices.open({ index: "kibana_sample_data_ecommerce2", }); console.log(response3);### On clusterB ### POST /kibana_sample_data_ecommerce2/_ccr/pause_follow POST /kibana_sample_data_ecommerce2/_close POST /kibana_sample_data_ecommerce2/_ccr/unfollow POST /kibana_sample_data_ecommerce2/_open
-
On the client side (Logstash, Beats, Elastic Agent), manually re-enable ingestion of
kibana_sample_data_ecommerce2and redirect traffic to theclusterB. You should also redirect all search traffic to theclusterBcluster during this time. You can simulate this by ingesting documents into this index. You should notice this index is now writable.resp = client.index( index="kibana_sample_data_ecommerce2", document={ "user": "kimchy" }, ) print(resp)response = client.index( index: 'kibana_sample_data_ecommerce2', body: { user: 'kimchy' } ) puts responseconst response = await client.index({ index: "kibana_sample_data_ecommerce2", document: { user: "kimchy", }, }); console.log(response);### On clusterB ### POST kibana_sample_data_ecommerce2/_doc/ { "user": "kimchy" }
Failback when clusterA comes back
editWhen clusterA comes back, clusterB becomes the new leader and clusterA becomes the follower.
-
Set up remote cluster
clusterBonclusterA.resp = client.cluster.put_settings( persistent={ "cluster": { "remote": { "clusterB": { "mode": "proxy", "skip_unavailable": "true", "server_name": "clusterb.es.region-b.gcp.elastic-cloud.com", "proxy_socket_connections": "18", "proxy_address": "clusterb.es.region-b.gcp.elastic-cloud.com:9400" } } } }, ) print(resp)response = client.cluster.put_settings( body: { persistent: { cluster: { remote: { "clusterB": { mode: 'proxy', skip_unavailable: 'true', server_name: 'clusterb.es.region-b.gcp.elastic-cloud.com', proxy_socket_connections: '18', proxy_address: 'clusterb.es.region-b.gcp.elastic-cloud.com:9400' } } } } } ) puts responseconst response = await client.cluster.putSettings({ persistent: { cluster: { remote: { clusterB: { mode: "proxy", skip_unavailable: "true", server_name: "clusterb.es.region-b.gcp.elastic-cloud.com", proxy_socket_connections: "18", proxy_address: "clusterb.es.region-b.gcp.elastic-cloud.com:9400", }, }, }, }, }); console.log(response);### On clusterA ### PUT _cluster/settings { "persistent": { "cluster": { "remote": { "clusterB": { "mode": "proxy", "skip_unavailable": "true", "server_name": "clusterb.es.region-b.gcp.elastic-cloud.com", "proxy_socket_connections": "18", "proxy_address": "clusterb.es.region-b.gcp.elastic-cloud.com:9400" } } } } } -
Existing data needs to be discarded before you can turn any index into a follower. Ensure the most up-to-date data is available on
clusterBprior to deleting any indices onclusterA.resp = client.indices.delete( index="kibana_sample_data_ecommerce", ) print(resp)response = client.indices.delete( index: 'kibana_sample_data_ecommerce' ) puts response
const response = await client.indices.delete({ index: "kibana_sample_data_ecommerce", }); console.log(response);### On clusterA ### DELETE kibana_sample_data_ecommerce
-
Create a follower index on
clusterA, now following the leader index inclusterB.resp = client.ccr.follow( index="kibana_sample_data_ecommerce", wait_for_active_shards="1", remote_cluster="clusterB", leader_index="kibana_sample_data_ecommerce2", ) print(resp)const response = await client.ccr.follow({ index: "kibana_sample_data_ecommerce", wait_for_active_shards: 1, remote_cluster: "clusterB", leader_index: "kibana_sample_data_ecommerce2", }); console.log(response);### On clusterA ### PUT /kibana_sample_data_ecommerce/_ccr/follow?wait_for_active_shards=1 { "remote_cluster": "clusterB", "leader_index": "kibana_sample_data_ecommerce2" } -
The index on the follower cluster now contains the updated documents.
resp = client.search( index="kibana_sample_data_ecommerce", q="kimchy", ) print(resp)response = client.search( index: 'kibana_sample_data_ecommerce', q: 'kimchy' ) puts response
const response = await client.search({ index: "kibana_sample_data_ecommerce", q: "kimchy", }); console.log(response);### On clusterA ### GET kibana_sample_data_ecommerce/_search?q=kimchy
If a soft delete is merged away before it can be replicated to a follower the following process will fail due to incomplete history on the leader, see index.soft_deletes.retention_lease.period for more details.