Machine learning
editMachine learning
editAs data sets increase in size and complexity, the human effort required to inspect dashboards or maintain rules for spotting infrastructure problems, cyber attacks, or business issues becomes impractical. Elastic machine learning features such as anomaly detection and outlier detection make it easier to notice suspicious activities with minimal human interference.
Kibana includes a free Data Visualizer to learn more about your data. In particular, if your data is stored in Elasticsearch and contains a time field, you can use the Data Visualizer to identify possible fields for anomaly detection:
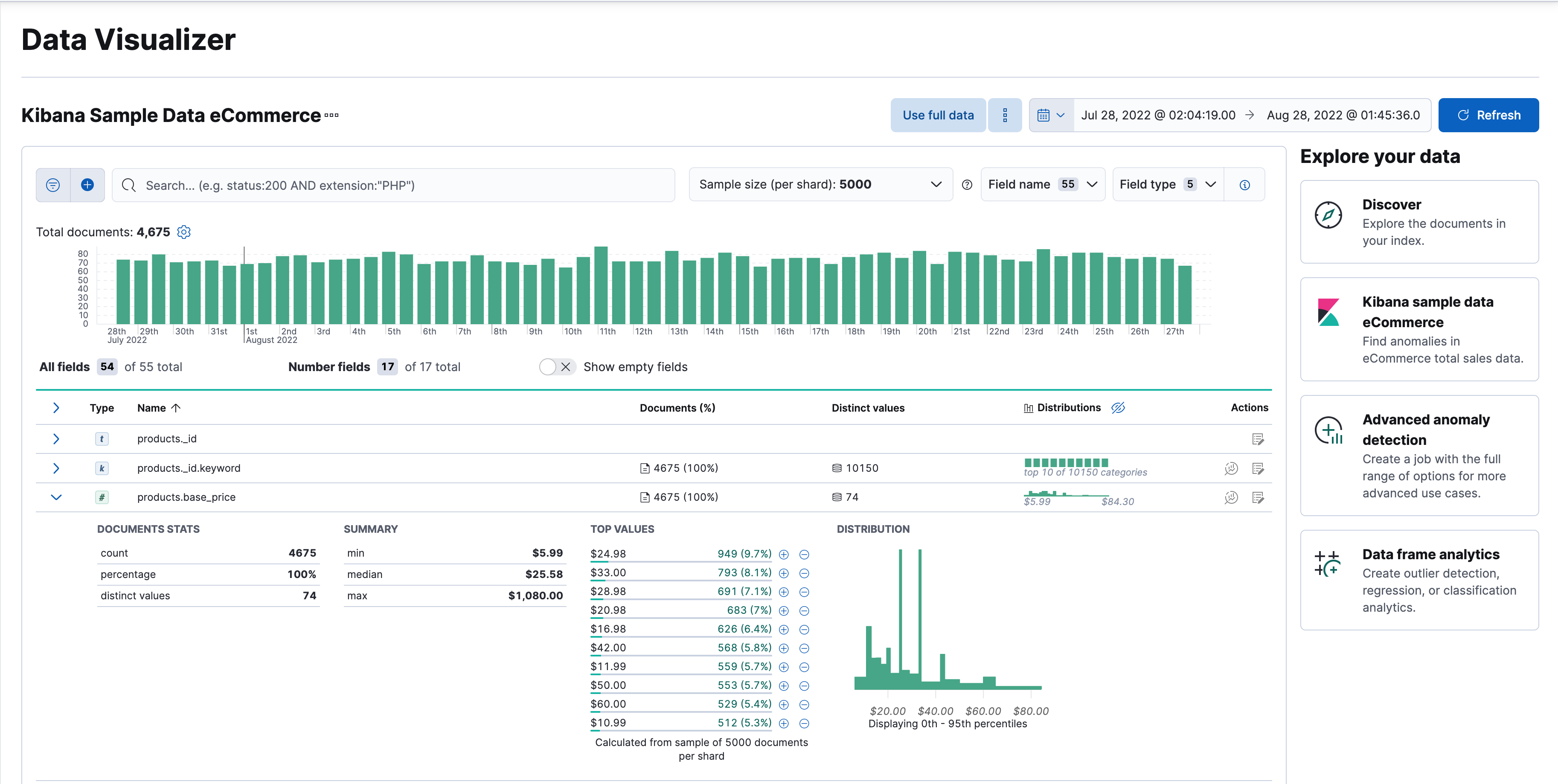
You can upload different file formats for analysis with the Data Visualizer.
File formats supported up to 500 MB:
- CSV
- TSV
- NDJSON
- Log files
File formats supported up to 60 MB:
- Microsoft Office files (Word, Excel, PowerPoint)
- Plain Text (TXT)
- Rich Text (RTF)
- Open Document Format (ODF)
The Data Visualizer identifies the file format and field mappings, and you can import the data into an Elasticsearch index. To change the default file size limit, see fileUpload:maxFileSize in advanced settings.
If Elastic Stack security features are enabled, users must have the necessary privileges to use machine learning features. Refer to Set up machine learning features.
There are limitations in machine learning features that affect Kibana. For more information, refer to Machine learning.
Data drift
editThis functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
You can find the data drift view in Machine Learning > Data Visualizer in Kibana or by using the global search field. The data drift view shows you the differences in each field for two different time ranges in a given data view. The view helps you to visualize the changes in your data over time and enables you to understand its behavior better.
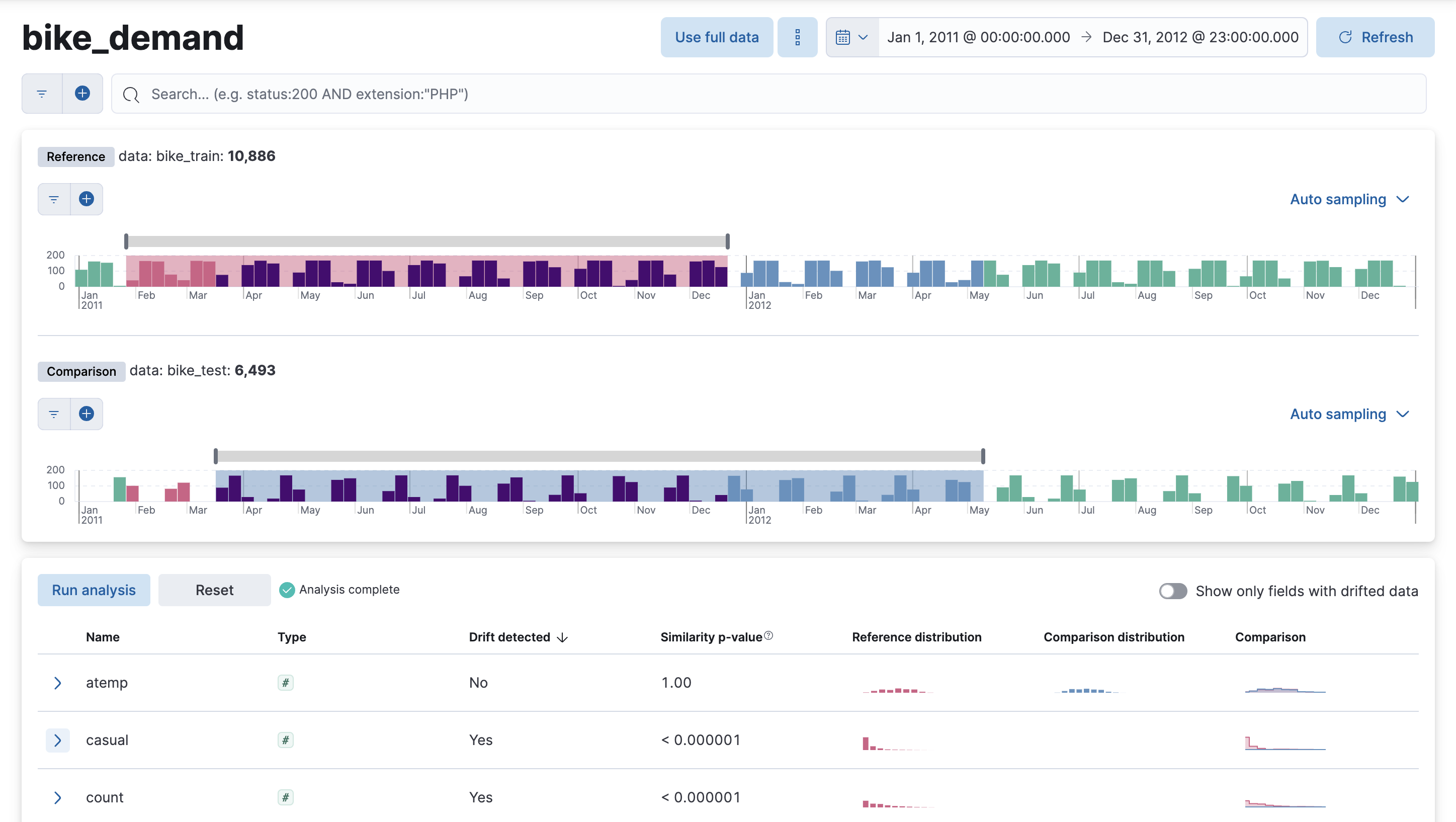
Select a data view that you want to analyze, then select a time range for the reference and the comparison data in the appearing histogram chart. You can adjust the time range for both the reference and the comparison data by moving the respective brushes. When you finished setting the time ranges, click Run analysis.
You can decide whether you want to see all the fields in the data view or only the ones that contains drifted data. The analysis results table displays the fields, their types, if drift is detected, the p-value that indicates how significant the detected change is, the reference and comparison distribution, and the comparison chart. You can expand the results for a particular field by clicking the arrow icon at the beginning of the field’s row.