Alerts and rules
editAlerts and rules
editThe APM app allows you to define rules to detect complex conditions within your APM data and trigger built-in actions when those conditions are met.
The following rules are supported:
- Threshold rule: Alert when the latency or failed transaction rate is abnormal. Threshold rules can be as broad or as granular as you’d like, enabling you to define exactly when you want to be alerted—whether that’s at the environment level, service name level, transaction type level, and/or transaction name level.
- Anomaly rule: Alert when either the latency of a service is anomalous. Anomaly rules can be set at the environment level, service level, and/or transaction type level.
- Error count rule: Alert when the number of errors in a service exceeds a defined threshold. Error count rules can be set at the environment level, service level, and error group level.
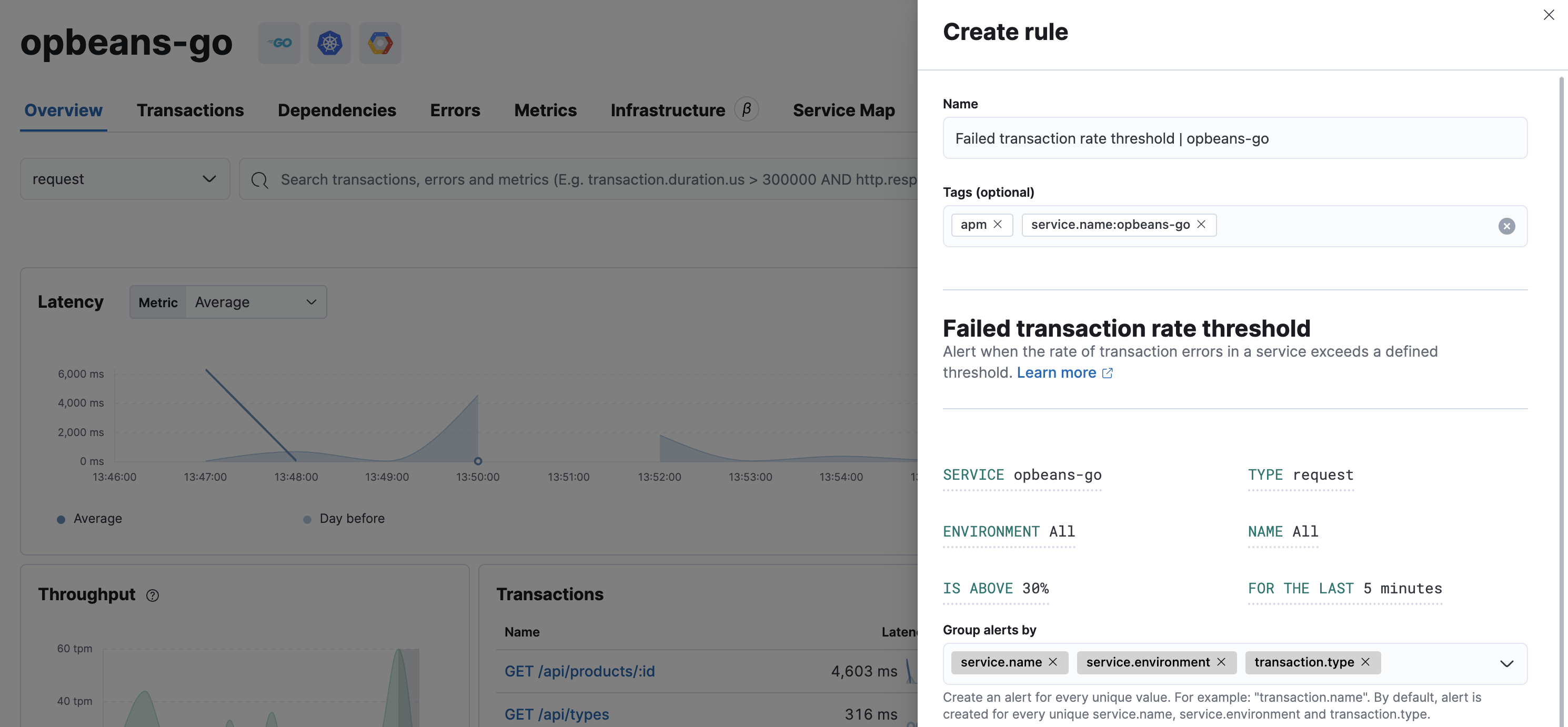
Below, we’ll walk through the creation of two APM rules.
For a complete walkthrough of the Create rule flyout panel, including detailed information on each configurable property, see Kibana’s create and edit rules.
Example: create a latency anomaly rule
editLatency anomaly rules trigger when the latency of a service is abnormal. Because some parts of an application are more important than others, and have a different tolerance for latency, we’ll target a specific transaction within a service.
Before continuing, identify the service name, transaction type, and environment that you’d like to create a latency anomaly rule for. This guide will create an alert for all services based on the following criteria:
-
Service:
{your_service.name} -
Transaction:
{your_transaction.name} -
Environment:
{your_service.environment} - Severity level: critical
- Check every five minutes
- Send an alert to a Slack channel when the rule status changes
From any page in the APM app, select Alerts and rules > Create anomaly rule. Change the name of the rule, but do not edit the tags.
Based on the criteria above, define the following rule details:
-
Service -
{your_service.name} -
Type -
{your_transaction.name} -
Environment -
{your_service.environment} -
Has anomaly with severity -
critical -
Check every -
5 minutes
Next, add a connector type. Multiple connectors can be selected, but in this example we’re interested in Slack. Select Slack > Create a connector. Enter a name for the connector, and paste your Slack webhook URL. See Slack’s webhook documentation if you need to create one.
A default message is provided as a starting point for your alert.
You can use the Mustache template syntax, i.e., {{variable}}
to pass additional alert values at the time a condition is detected to an action.
A list of available variables can be accessed by selecting the
add variable button  .
.
Click Save. Your rule has been created and is now active!
Example: create an error count threshold alert
editThe error count threshold alert triggers when the number of errors in a service exceeds a defined threshold. Because some errors are more important than others, this guide will focus a specific error group ID.
Before continuing, identify the service name, environment name, and error group ID that you’d like to create a latency anomaly rule for. The easiest way to find an error group ID is to select the service that you’re interested in and navigating to the Errors tab.
This guide will create an alert for an error group ID based on the following criteria:
-
Service:
{your_service.name} -
Environment:
{your_service.environment} -
Error Grouping Key:
{your_error.ID} - Error rate is above 25 errors for the last five minutes
-
Group alerts by
service.nameandservice.environment - Check every 1 minute
- Send the alert via email to the site reliability team
From any page in the APM app, select Alerts and rules > Create error count rule. Change the name of the alert, but do not edit the tags.
Based on the criteria above, define the following rule details:
-
Service:
{your_service.name} -
Environment:
{your_service.environment} -
Error Grouping Key:
{your_error.ID} -
Is above -
25 errors -
For the last -
5 minutes -
Group alerts by -
service.nameservice.environment -
Check every -
1 minute
Select the Email connector and click Create a connector. Fill out the required details: sender, host, port, etc., and click save.
A default message is provided as a starting point for your alert.
You can use the Mustache template syntax, i.e., {{variable}}
to pass additional alert values at the time a condition is detected to an action.
A list of available variables can be accessed by selecting the
add variable button .
Click Save. The alert has been created and is now active!
View active alerts
editActive alerts are displayed and grouped in multiple ways in the APM app.
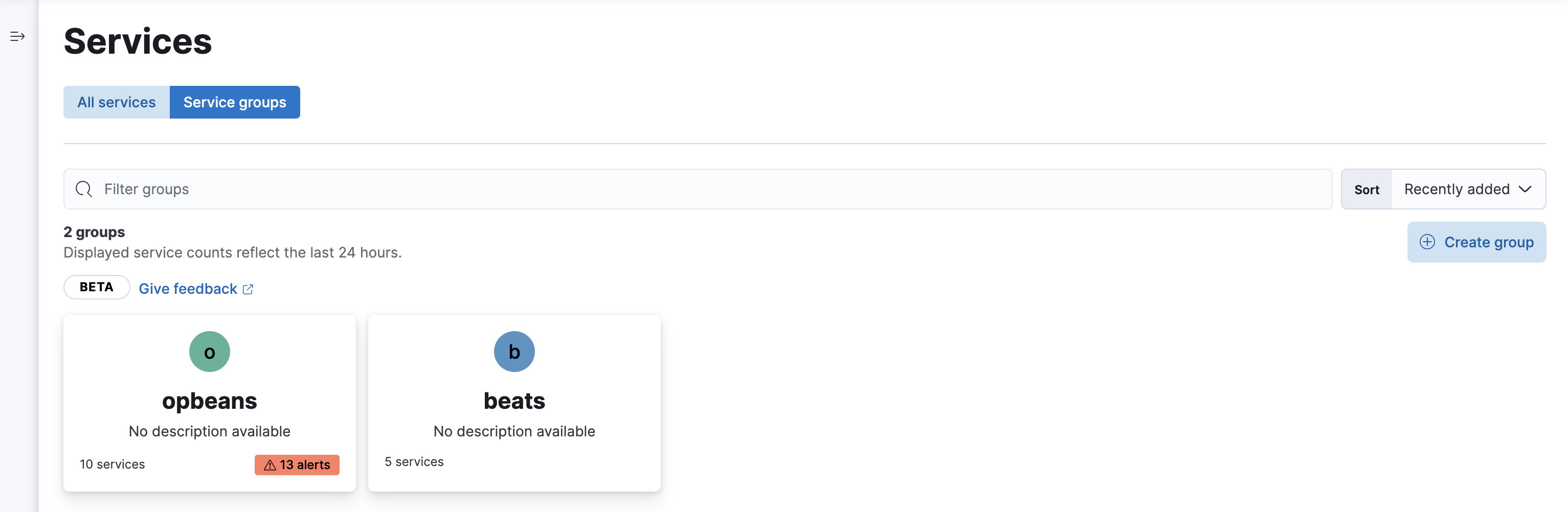
View alerts by service group
editIf you’re using the service groups feature, you can view alerts by service group. From the service group overview page, click the red alert indicator to open the Alerts tab with a predefined filter that matches the filter used when creating the service group.
View alerts by service
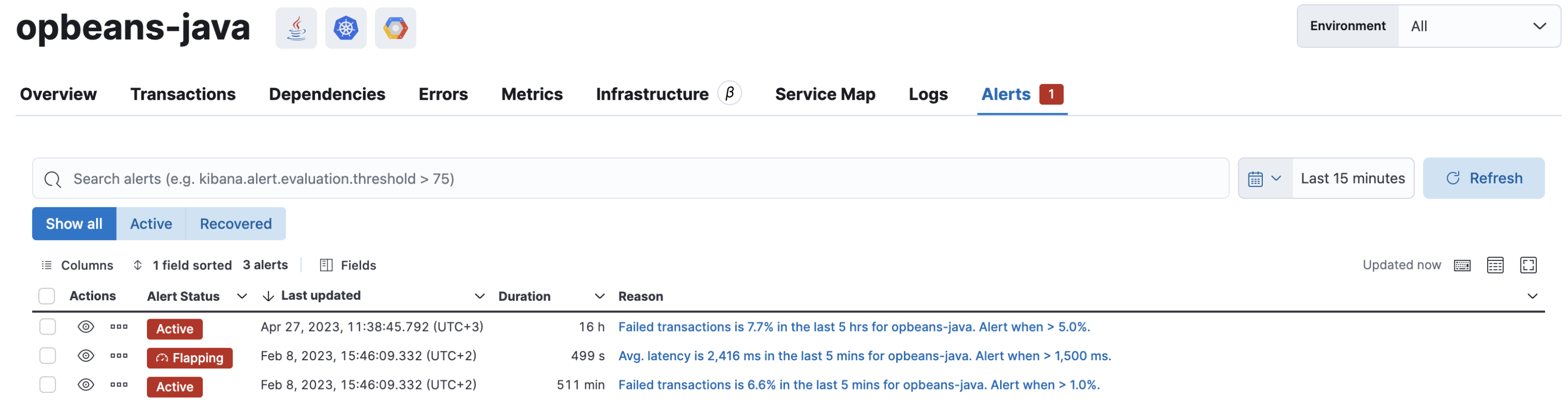
editAlerts can be viewed within the context of any service. After selecting a service, go to the Alerts tab to view any alerts that are active for the selected service.
Manage alerts and rules
editFrom the APM app, select Alerts and rules > Manage rules to be taken to the Kibana Rules page. From this page, you can disable, mute, and delete APM alerts.
More information
editSee Alerting for more information.
If you are using an on-premise Elastic Stack deployment with security, communication between Elasticsearch and Kibana must have TLS configured. More information is in the alerting prerequisites.