Setting Up an Advanced Logstash Pipeline
editSetting Up an Advanced Logstash Pipeline
editA Logstash pipeline in most use cases has one or more input, filter, and output plugins. The scenarios in this section build Logstash configuration files to specify these plugins and discuss what each plugin is doing.
The Logstash configuration file defines your Logstash pipeline. When you start a Logstash instance, use the
-f <path/to/file> option to specify the configuration file that defines that instance’s pipeline.
A Logstash pipeline has two required elements, input and output, and one optional element, filter. The input
plugins consume data from a source, the filter plugins modify the data as you specify, and the output plugins write
the data to a destination.
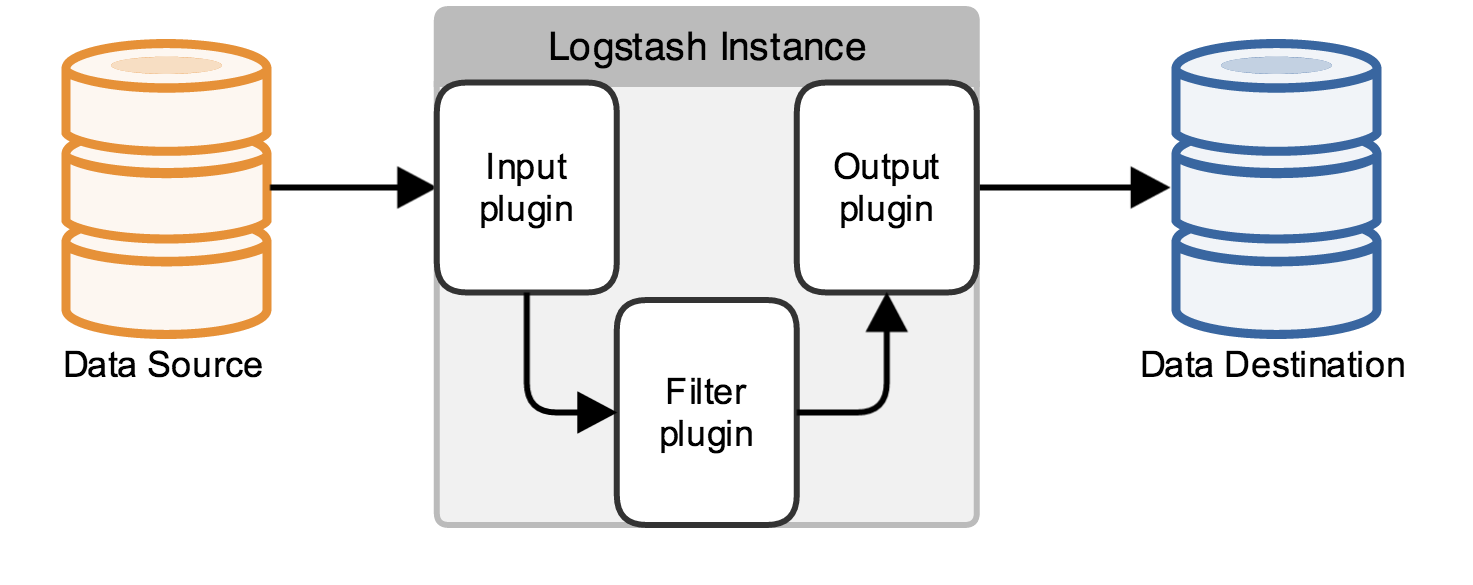
The following text represents the skeleton of a configuration pipeline:
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}
This skeleton is non-functional, because the input and output sections don’t have any valid options defined. The examples in this tutorial build configuration files to address specific use cases.
Paste the skeleton into a file named first-pipeline.conf in your home Logstash directory.
Parsing Apache Logs into Elasticsearch
editThis example creates a Logstash pipeline that takes Apache web logs as input, parses those logs to create specific, named fields from the logs, and writes the parsed data to an Elasticsearch cluster.
You can download the sample data set used in this example here. Unpack this file.
Configuring Logstash for File Input
editTo start your Logstash pipeline, configure the Logstash instance to read from a file using the file input plugin.
Edit the first-pipeline.conf file to add the following text:
input {
file {
path => "/path/to/logstash-tutorial.log"
start_position => beginning
ignore_older => 0
}
}
|
The default behavior of the file input plugin is to monitor a file for new information, in a manner similar to the
UNIX |
|
|
The default behavior of the file input plugin is to ignore files whose last modification is greater than 86400s. To change this default behavior and process the tutorial file (which date can be much older than a day), we need to specify to not ignore old files. |
Replace /path/to/ with the actual path to the location of logstash-tutorial.log in your file system.
Parsing Web Logs with the Grok Filter Plugin
editThe grok filter plugin is one of several plugins that are available by default in
Logstash. For details on how to manage Logstash plugins, see the reference documentation for
the plugin manager.
Because the grok filter plugin looks for patterns in the incoming log data, configuration requires you to make
decisions about how to identify the patterns that are of interest to your use case. A representative line from the web
server log sample looks like this:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
The IP address at the beginning of the line is easy to identify, as is the timestamp in brackets. In this tutorial, use
the %{COMBINEDAPACHELOG} grok pattern, which structures lines from the Apache log using the following schema:
|
Information |
Field Name |
|
IP Address |
|
|
User ID |
|
|
User Authentication |
|
|
timestamp |
|
|
HTTP Verb |
|
|
Request body |
|
|
HTTP Version |
|
|
HTTP Status Code |
|
|
Bytes served |
|
|
Referrer URL |
|
|
User agent |
|
Edit the first-pipeline.conf file to add the following text:
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
After processing, the sample line has the following JSON representation:
{
"clientip" : "83.149.9.216",
"ident" : ,
"auth" : ,
"timestamp" : "04/Jan/2015:05:13:42 +0000",
"verb" : "GET",
"request" : "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"httpversion" : "HTTP/1.1",
"response" : "200",
"bytes" : "203023",
"referrer" : "http://semicomplete.com/presentations/logstash-monitorama-2013/",
"agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
}
Indexing Parsed Data into Elasticsearch
editNow that the web logs are broken down into specific fields, the Logstash pipeline can index the data into an
Elasticsearch cluster. Edit the first-pipeline.conf file to add the following text after the input section:
output {
elasticsearch {
}
}
With this configuration, Logstash uses http protocol to connect to Elasticsearch. The above example assumes Logstash
and Elasticsearch to be running on the same instance. You can specify a remote Elasticsearch instance using hosts
configuration like hosts => "es-machine:9092".
Enhancing Your Data with the Geoip Filter Plugin
editIn addition to parsing log data for better searches, filter plugins can derive supplementary information from existing
data. As an example, the geoip plugin looks up IP addresses, derives geographic
location information from the addresses, and adds that location information to the logs.
Configure your Logstash instance to use the geoip filter plugin by adding the following lines to the filter section
of the first-pipeline.conf file:
geoip {
source => "clientip"
}
The geoip plugin configuration requires data that is already defined as separate fields. Make sure that the geoip
section is after the grok section of the configuration file.
Specify the name of the field that contains the IP address to look up. In this tutorial, the field name is clientip.
Testing Your Initial Pipeline
editAt this point, your first-pipeline.conf file has input, filter, and output sections properly configured, and looks
like this:
input {
file {
path => "/Users/palecur/logstash-1.5.2/logstash-tutorial-dataset"
start_position => beginning
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {}
stdout {}
}
To verify your configuration, run the following command:
bin/logstash -f first-pipeline.conf --configtest
The --configtest option parses your configuration file and reports any errors. When the configuration file passes
the configuration test, start Logstash with the following command:
bin/logstash -f first-pipeline.conf
Try a test query to Elasticsearch based on the fields created by the grok filter plugin:
curl -XGET 'localhost:9200/logstash-$DATE/_search?q=response=200'
Replace $DATE with the current date, in YYYY.MM.DD format.
Since our sample has just one 200 HTTP response, we get one hit back:
{"took":2,
"timed_out":false,
"_shards":{"total":5,
"successful":5,
"failed":0},
"hits":{"total":1,
"max_score":1.5351382,
"hits":[{"_index":"logstash-2015.07.30",
"_type":"logs",
"_id":"AU7gqOky1um3U6ZomFaF",
"_score":1.5351382,
"_source":{"message":"83.149.9.216 - - [04/Jan/2015:05:13:45 +0000] \"GET /presentations/logstash-monitorama-2013/images/frontend-response-codes.png HTTP/1.1\" 200 52878 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",
"@version":"1",
"@timestamp":"2015-07-30T20:30:41.265Z",
"host":"localhost",
"path":"/path/to/logstash-tutorial-dataset",
"clientip":"83.149.9.216",
"ident":"-",
"auth":"-",
"timestamp":"04/Jan/2015:05:13:45 +0000",
"verb":"GET",
"request":"/presentations/logstash-monitorama-2013/images/frontend-response-codes.png",
"httpversion":"1.1",
"response":"200",
"bytes":"52878",
"referrer":"\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"",
"agent":"\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\""
}
}]
}
}
Try another search for the geographic information derived from the IP address:
curl -XGET 'localhost:9200/logstash-$DATE/_search?q=geoip.city_name=Buffalo'
Replace $DATE with the current date, in YYYY.MM.DD format.
Only one of the log entries comes from Buffalo, so the query produces a single response:
{"took":3,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0},
"hits":{"total":1,
"max_score":1.03399,
"hits":[{"_index":"logstash-2015.07.31",
"_type":"logs",
"_id":"AU7mK3CVSiMeBsJ0b_EP",
"_score":1.03399,
"_source":{
"message":"108.174.55.234 - - [04/Jan/2015:05:27:45 +0000] \"GET /?flav=rss20 HTTP/1.1\" 200 29941 \"-\" \"-\"",
"@version":"1",
"@timestamp":"2015-07-31T22:11:22.347Z",
"host":"localhost",
"path":"/path/to/logstash-tutorial-dataset",
"clientip":"108.174.55.234",
"ident":"-",
"auth":"-",
"timestamp":"04/Jan/2015:05:27:45 +0000",
"verb":"GET",
"request":"/?flav=rss20",
"httpversion":"1.1",
"response":"200",
"bytes":"29941",
"referrer":"\"-\"",
"agent":"\"-\"",
"geoip":{
"ip":"108.174.55.234",
"country_code2":"US",
"country_code3":"USA",
"country_name":"United States",
"continent_code":"NA",
"region_name":"NY",
"city_name":"Buffalo",
"postal_code":"14221",
"latitude":42.9864,
"longitude":-78.7279,
"dma_code":514,
"area_code":716,
"timezone":"America/New_York",
"real_region_name":"New York",
"location":[-78.7279,42.9864]
}
}
}]
}
}
Multiple Input and Output Plugins
editThe information you need to manage often comes from several disparate sources, and use cases can require multiple destinations for your data. Your Logstash pipeline can use multiple input and output plugins to handle these requirements.
This example creates a Logstash pipeline that takes input from a Twitter feed and the Filebeat client, then sends the information to an Elasticsearch cluster as well as writing the information directly to a file.
Reading from a Twitter feed
editTo add a Twitter feed, you need several pieces of information:
- A consumer key, which uniquely identifies your Twitter app, which is Logstash in this case.
- A consumer secret, which serves as the password for your Twitter app.
- One or more keywords to search in the incoming feed.
- An oauth token, which identifies the Twitter account using this app.
- An oauth token secret, which serves as the password of the Twitter account.
Visit https://dev.twitter.com/apps to set up a Twitter account and generate your consumer key and secret, as well as your OAuth token and secret.
Use this information to add the following lines to the input section of the first-pipeline.conf file:
twitter {
consumer_key =>
consumer_secret =>
keywords =>
oauth_token =>
oauth_token_secret =>
}
The Filebeat Client
editThe filebeat client is a lightweight, resource-friendly tool that collects logs from files on the server and forwards these logs to your Logstash instance for processing. The Filebeat client uses the secure Beats protocol to communicate with your Logstash instance. The lumberjack protocol is designed for reliability and low latency. Filebeat uses the computing resources of the machine hosting the source data, and the Beats input plugin minimizes the resource demands on the Logstash instance.
In a typical use case, Filebeat runs on a separate machine from the machine running your Logstash instance. For the purposes of this tutorial, Logstash and Filebeat are running on the same machine.
Default Logstash configuration includes the Beats input plugin, which is designed to be resource-friendly. To install Filebeat on your data source machine, download the appropriate package from the Filebeat product page.
Create a configuration file for Filebeat similar to the following example:
filebeat:
prospectors:
-
paths:
- "/path/to/sample-log"
fields:
type: syslog
output:
logstash:
hosts: ["localhost:5043"]
tls:
certificate: /path/to/ssl-certificate.crt
certificate_key: /path/to/ssl-certificate.key
certificate_authorities: /path/to/ssl-certificate.crt
timeout: 15
|
Path to the file or files that Filebeat processes. |
|
|
Path to the SSL certificate for the Logstash instance. |
Save this configuration file as filebeat.yml.
Configure your Logstash instance to use the Filebeat input plugin by adding the following lines to the input section
of the first-pipeline.conf file:
beats {
port => "5043"
ssl => true
ssl_certificate => "/path/to/ssl-cert"
ssl_key => "/path/to/ssl-key"
}
|
Path to the SSL certificate that the Logstash instance uses to authenticate itself to Filebeat. |
|
|
Path to the key for the SSL certificate. |
Writing Logstash Data to a File
editYou can configure your Logstash pipeline to write data directly to a file with the
file output plugin.
Configure your Logstash instance to use the file output plugin by adding the following lines to the output section
of the first-pipeline.conf file:
file {
path => /path/to/target/file
}
Writing to multiple Elasticsearch nodes
editWriting to multiple Elasticsearch nodes lightens the resource demands on a given Elasticsearch node, as well as providing redundant points of entry into the cluster when a particular node is unavailable.
To configure your Logstash instance to write to multiple Elasticsearch nodes, edit the output section of the first-pipeline.conf file to read:
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
}
Use the IP addresses of three non-master nodes in your Elasticsearch cluster in the host line. When the hosts
parameter lists multiple IP addresses, Logstash load-balances requests across the list of addresses. Also note that
default port for Elasticsearch is 9200 and can be omitted in the configuration above.
Testing the Pipeline
editAt this point, your first-pipeline.conf file looks like this:
input {
twitter {
consumer_key =>
consumer_secret =>
keywords =>
oauth_token =>
oauth_token_secret =>
}
beats {
port => "5043"
ssl => true
ssl_certificate => "/path/to/ssl-cert"
ssl_key => "/path/to/ssl-key"
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => /path/to/target/file
}
}
Logstash is consuming data from the Twitter feed you configured, receiving data from Filebeat, and indexing this information to three nodes in an Elasticsearch cluster as well as writing to a file.
At the data source machine, run Filebeat with the following command:
sudo ./filebeat -e -c filebeat.yml -d "publish"
Filebeat will attempt to connect on port 5403. Until Logstash starts with an active Beats plugin, there won’t be any answer on that port, so any messages you see regarding failure to connect on that port are normal for now.
To verify your configuration, run the following command:
bin/logstash -f first-pipeline.conf --configtest
The --configtest option parses your configuration file and reports any errors. When the configuration file passes
the configuration test, start Logstash with the following command:
bin/logstash -f first-pipeline.conf
Use the grep utility to search in the target file to verify that information is present:
grep Mozilla /path/to/target/file
Run an Elasticsearch query to find the same information in the Elasticsearch cluster:
curl -XGET 'localhost:9200/logstash-2015.07.30/_search?q=agent=Mozilla'