Inspect log anomalies
editInspect log anomalies
editWhen the anomaly detection features of machine learning are enabled, you can use the Anomalies page in the Logs app to detect and inspect log anomalies and the log partitions where the log anomalies occur. This means you can easily see anomalous behavior without significant human intervention — no more manually sampling log data, calculating rates, and determining if rates are expected.
Anomalies automatically highlight periods where the log rate is outside expected bounds and therefore may be anomalous.
For example:
- A significant drop in the log rate might suggest that a piece of infrastructure stopped responding, and thus we’re serving fewer requests.
- A spike in the log rate could denote a DDoS attack. This may lead to an investigation of IP addresses from incoming requests.
You can also view log anomalies directly in the Machine Learning app.
Enable log rate analysis and anomaly detection
editCreate a machine learning job to detect anomalous log entry rates automatically.
- Select Anomalies, and you’ll be prompted to create a machine learning job which will carry out the log rate analysis.
- Choose a time range for the machine learning analysis.
- Add the Indices that contain the logs you want to analyze.
- Click Create ML job.
- You’re now ready to explore your log partitions.
Anomalies chart
editThe Anomalies chart shows an overall, color-coded visualization of the log entry rate,
partitioned according to the value of the Elastic Common Schema (ECS)
event.dataset field.
This chart helps you quickly spot increases or decreases in each partition’s log rate.
If you have a lot of log partitions, use the following to filter your data:
- Hover over a time range to see the log rate for each partition.
- Click or hover on a partition name to show, hide, or highlight the partition values.
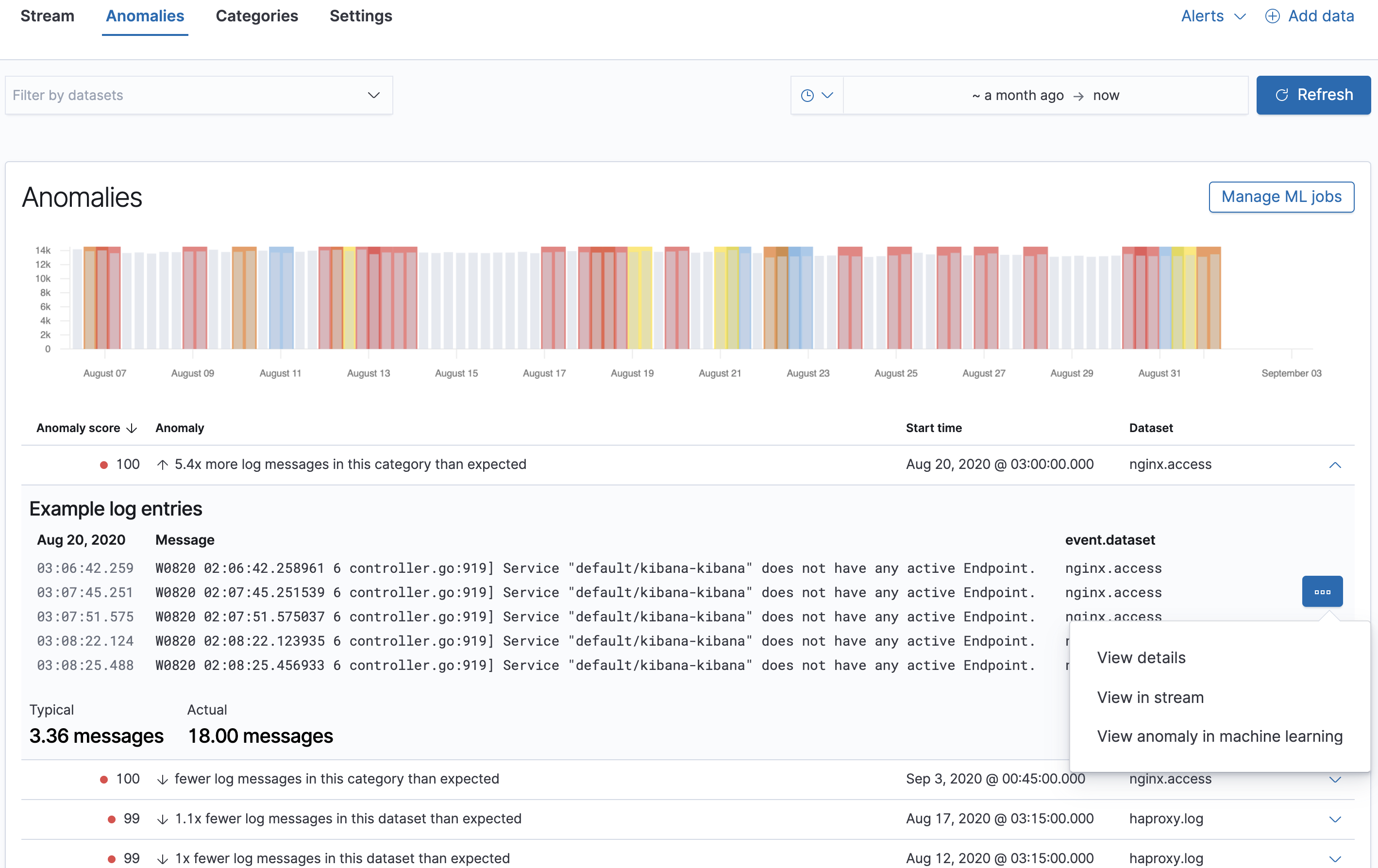
The chart shows the time range where anomalies were detected. The typical rate values are shown in gray, while the anomalous regions are color-coded and superimposed on top.
When a time range is flagged as anomalous, the machine learning algorithms have detected unusual log rate activity. This might be because:
- The log rate is significantly higher than usual.
- The log rate is significantly lower than usual.
- Other anomalous behavior has been detected. For example, the log rate is within bounds, but not fluctuating when it is expected to.
The level of anomaly detected in a time period is color-coded, from red, orange, yellow, to blue. Red indicates a critical anomaly level, while blue is a warning level.
To help you further drill down into a potential anomaly, you can view an anomaly chart for each partition. Anomaly scores range from 0 (no anomalies) to 100 (critical).
To analyze the anomalies in more detail, click View anomaly in machine learning, which opens the Anomaly Explorer in Machine Learning.