WARNING: Version 6.0 of the Elastic Stack has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Categorizing log messages
editCategorizing log messages
editApplication log events are often unstructured and contain variable data. For example:
{"time":1454516381000,"message":"org.jdbi.v2.exceptions.UnableToExecuteStatementException: com.mysql.jdbc.exceptions.MySQLTimeoutException: Statement cancelled due to timeout or client request [statement:\"SELECT id, customer_id, name, force_disabled, enabled FROM customers\"]","type":"logs"}
You can use machine learning to observe the static parts of the message, cluster similar messages together, and classify them into message categories.
Categorization uses English tokenization rules and dictionary words in order to identify log message categories. As such, only English language log messages are supported.
The machine learning model learns what volume and pattern is normal for each category over time. You can then detect anomalies and surface rare events or unusual types of messages by using count or rare functions. For example:
PUT _xpack/ml/anomaly_detectors/it_ops_new_logs
{
"description" : "IT Ops Application Logs",
"analysis_config" : {
"categorization_field_name": "message",
"bucket_span":"30m",
"detectors" :[{
"function":"count",
"by_field_name": "mlcategory",
"detector_description": "Unusual message counts"
}],
"categorization_filters":[ "\\[statement:.*\\]"]
},
"analysis_limits":{
"categorization_examples_limit": 5
},
"data_description" : {
"time_field":"time",
"time_format": "epoch_ms"
}
}
|
The |
|
|
The resulting categories are used in a detector by setting |
The optional categorization_examples_limit property specifies the
maximum number of examples that are stored in memory and in the results data
store for each category. The default value is 4. Note that this setting does
not affect the categorization; it just affects the list of visible examples. If
you increase this value, more examples are available, but you must have more
storage available. If you set this value to 0, no examples are stored.
The optional categorization_filters property can contain an array of regular
expressions. If a categorization field value matches the regular expression, the
portion of the field that is matched is not taken into consideration when
defining categories. The categorization filters are applied in the order they
are listed in the job configuration, which allows you to disregard multiple
sections of the categorization field value. In this example, we have decided that
we do not want the detailed SQL to be considered in the message categorization.
This particular categorization filter removes the SQL statement from the categorization
algorithm.
If your data is stored in Elasticsearch, you can create an advanced job with these same properties:
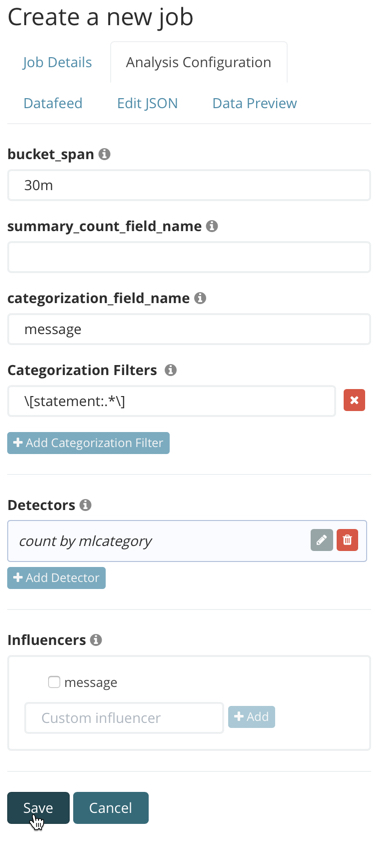
To add the categorization_examples_limit property, you must use the
Edit JSON tab and copy the analysis_limits object from the API example.
After you open the job and start the datafeed or supply data to the job, you can view the results in Kibana. For example:
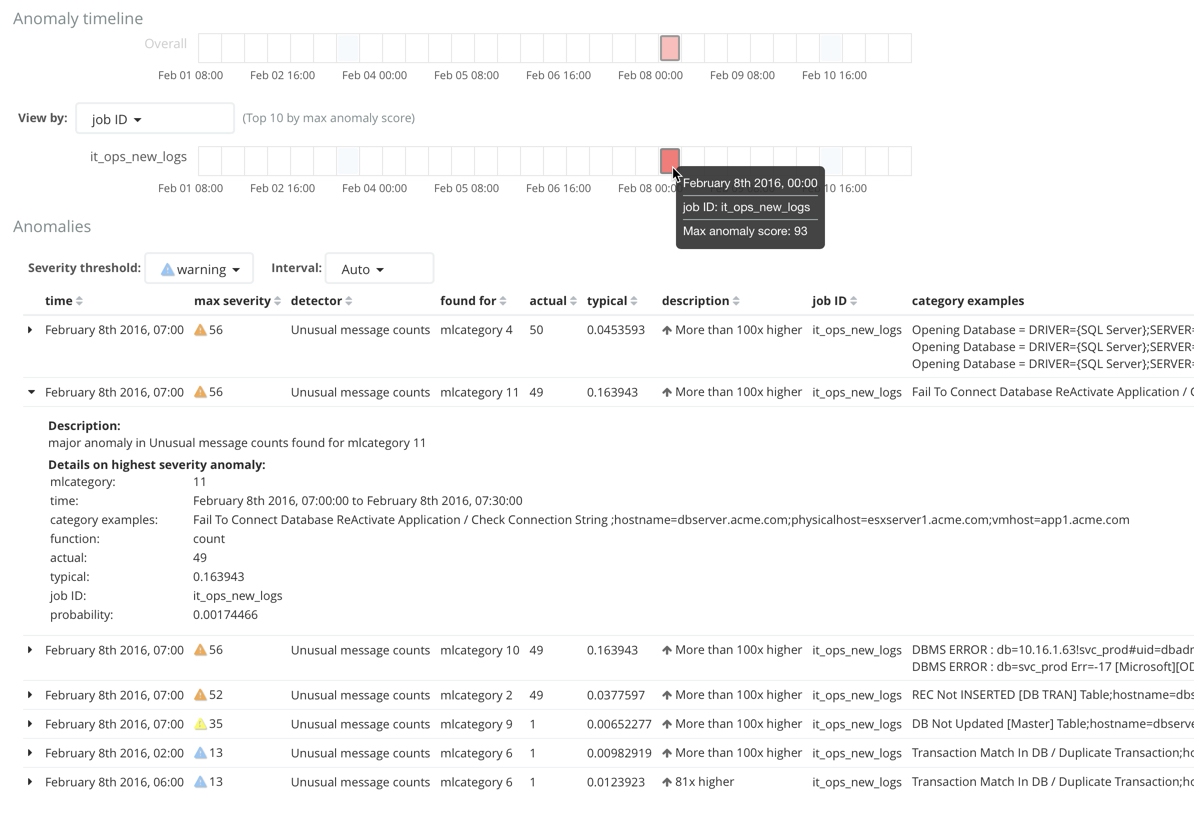
For this type of job, the Anomaly Explorer contains extra information for
each anomaly: the name of the category (for example, mlcategory 11) and
examples of the messages in that category. In this case, you can use these
details to investigate occurrences of unusually high message counts for specific
message categories.