Elastic Machine Learningの注釈機能
Elasticsearchバージョン6.6以降のMachine Learningでは、ユーザーが注釈を付けることができます。注釈という手法で、ドメイン知識の記述をMachine Learningジョブに加えることが可能になります。ジョブの実行中、Machine Learningのアルゴリズムはデータの異常を捉えようとしますが、そのデータ自体に関する知識は何も持ち合わせていません。 たとえばそのデータがCPUの使用状況に関するものか、ネットワークのスループットに関するものかも知らずに分析しているのです。ユーザーによる注釈は、データについてユーザーが持つ知識でジョブの結果を増補する手段となります。
このブログ記事では、ユーザーが注釈を付加する仕組みと、さまざまなユースケースでの活用法をご紹介します。今回の分析では、オーストリアのチロル州政府が運営する公開データポータル「Hydro Online」が提供するデータを使用します。Hydro Onlineは累積降水量や河川の水位、合計積雪量をはじめ、気象センサーデータの調査に役立つインターフェースです。CSVデータを投入する際の確実な方法の1つとして、以前こちらの記事に登場したFile Data Visualizerが、今回も活躍します。
使い方
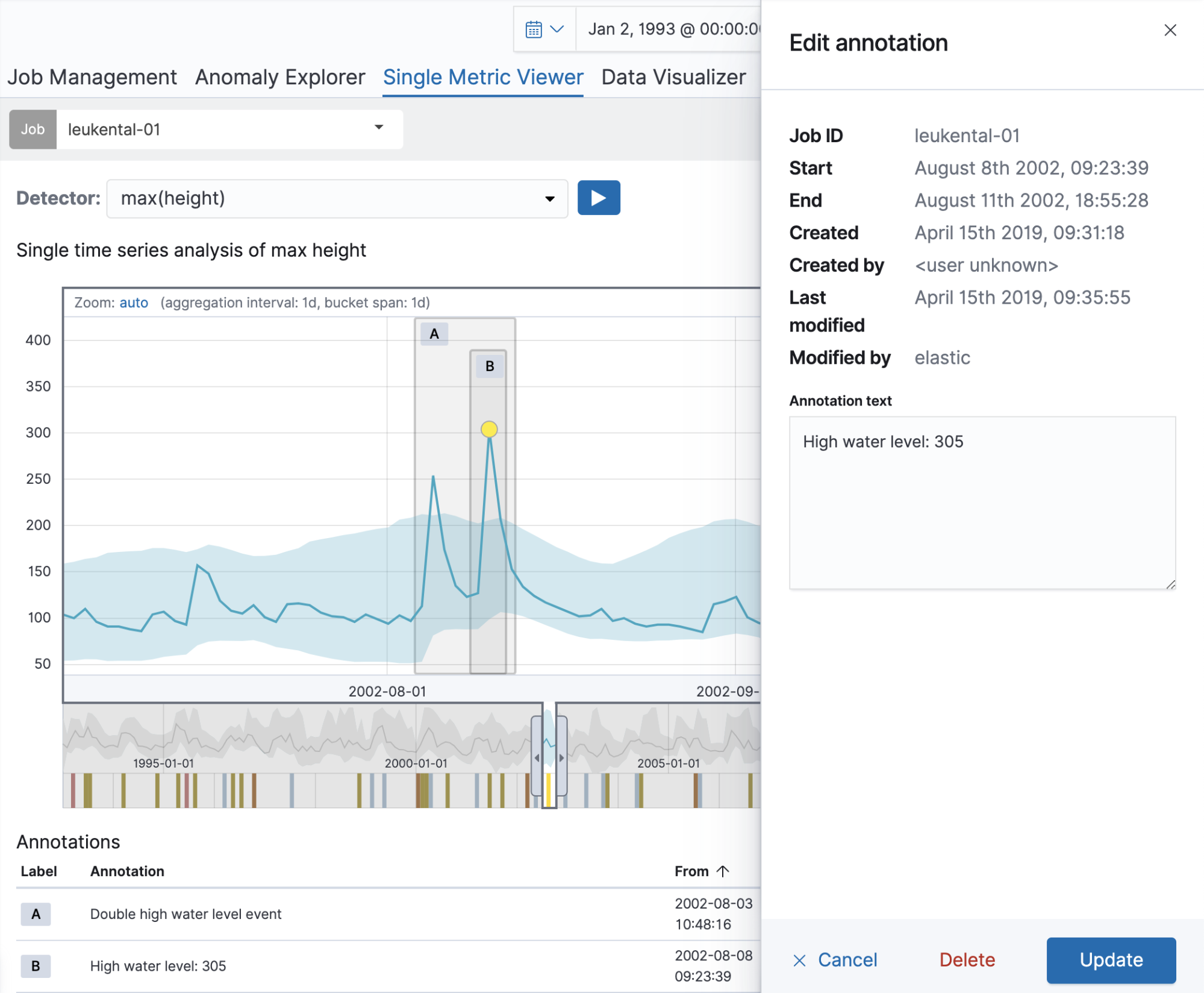
はじめに、Kössen(ケッセン)という町を流れるGrossache(グローサッヘ)川の推移を分析する単体のメトリックジョブを実行してみましょう。ジョブを作成したら、Single Metric Viewerを使用して分析結果に注釈を付けることができます。注釈を作成するには、チャートの時間範囲の部分でドラッグします。右に表示される部分に、説明を追加することができます。下の例では、河川水位に異常が生じた範囲に注釈を付けています(この日、大規模な洪水が発生しました)。このように注釈を付けることで、ほかのユーザーもこの知識を活用することが可能になります。
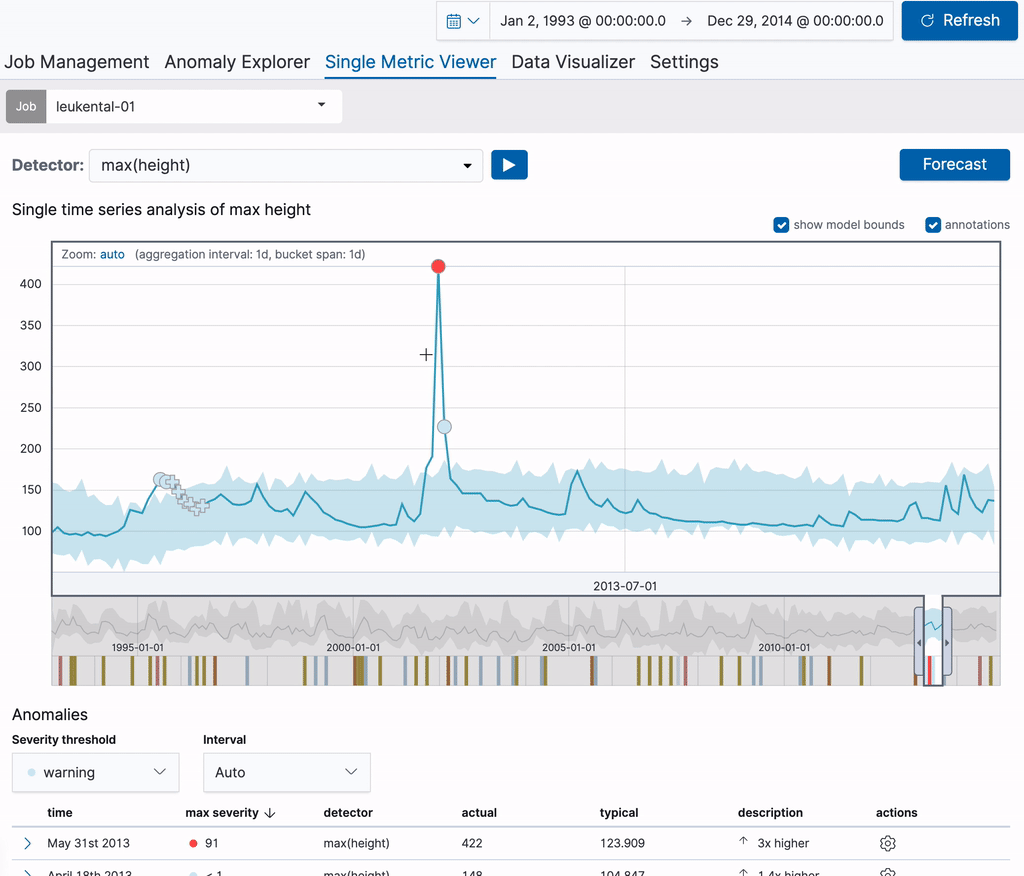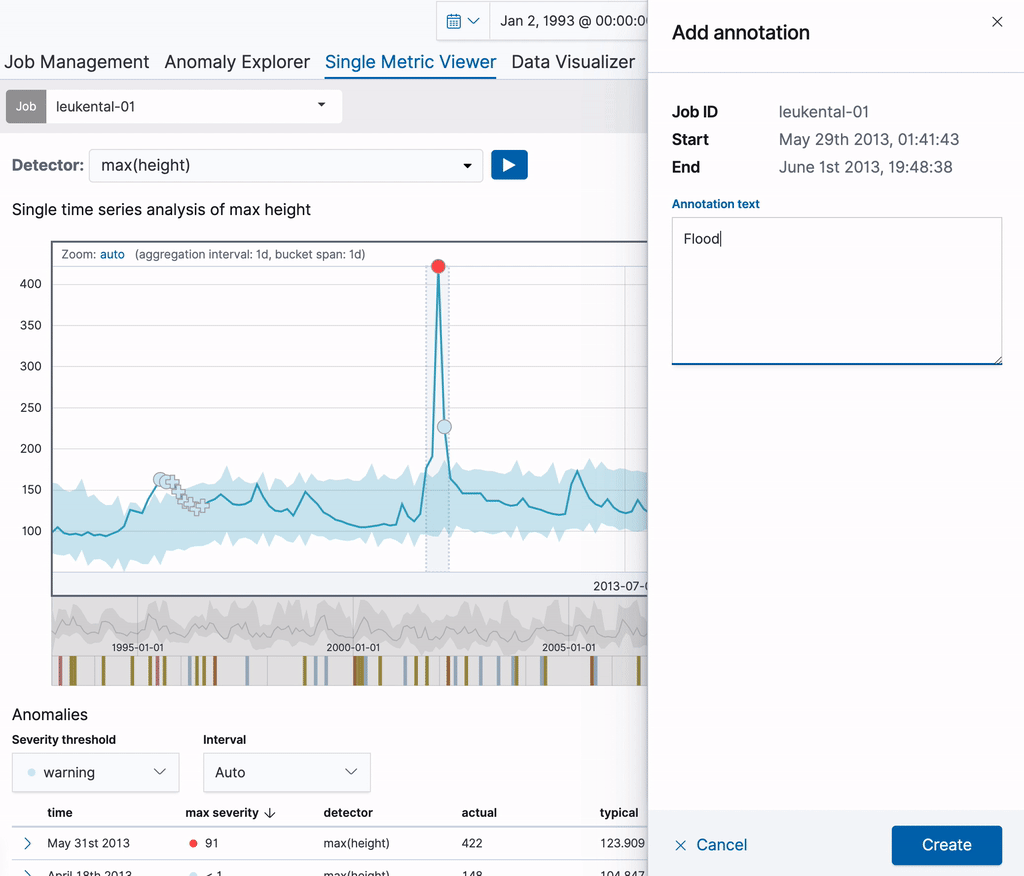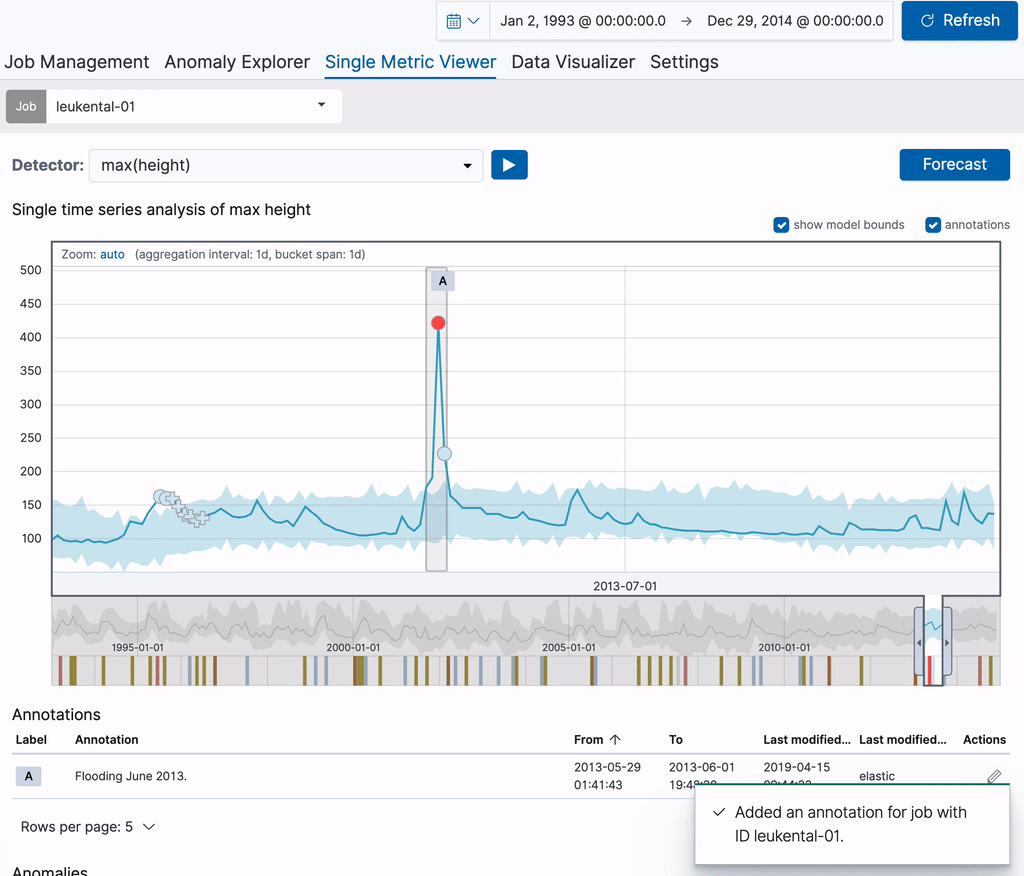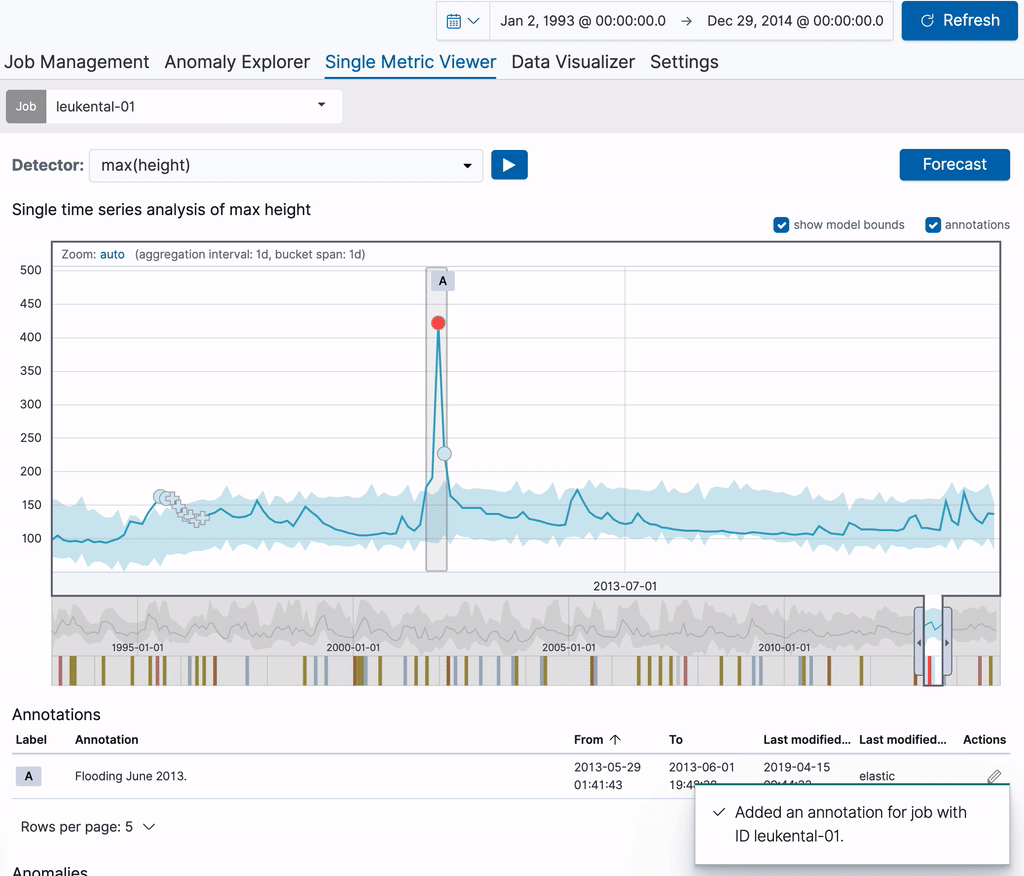
作成した注釈はチャート上と、下の注釈一覧の画面の両方で表示されます。表の1列目のラベルを使用すると、チャート上の注釈を特定できます。ラベルは画面で表示されている注釈に対し動的に作成されます。注釈の表の上にしばらくカーソルを合わせ、対応する注釈をチャート上で強調表示させることもできます。
各ジョブで作成された注釈は[Job Management]ページからも見ることができます。[Job Management]ページでリスト化されたジョブの行で詳細を表示し、注釈のタブを選択すると確認できます。表中で注釈の右側にはリンクがあり、ここからSingle Metric Viewerにジャンプできます。リンクを開くと、注釈を付けた時間範囲にフォーカスして表示されます。このパーマリンクは、他の人に共有することができます。また特定の異常について注釈を作成し、リンクをブックマークして後でもう一度見る、といった使い方をすることも可能です。

同じ時間範囲に複数の注釈を作成すると、画面上で重ならないよう、注釈は水平方向にずらして表示されます。注釈を編集・削除する場合は、チャート上でクリックして操作することができます。この場合も右側に表示される画面で、説明文の編集や注釈の削除を実行できます。バージョン6.7以降では、注釈一覧表の編集ボタンでも同じ操作を実行可能です。[Job Management]ページにも同じ機能が搭載されています。
ここまで注釈の作成や動作に関する基本的な内容を紹介してきました。ここからは、さまざまなユースケースでの活用法を説明します。
注釈を使って予測される異常を検証する
Machine Learningジョブで未来予測を行った場合、注釈を使って実測データと突き合わせ、検証することができます。引き続きHydro Onlineの河川水位データを使用し、異常な結果に対して過去のイベントを注釈にする自動のオーバレイを表示してみましょう。データサイエンティストにとって、分析するソースデータと結果検証用のデータセットの両方を入手し、準備するという手順は珍しくありません。
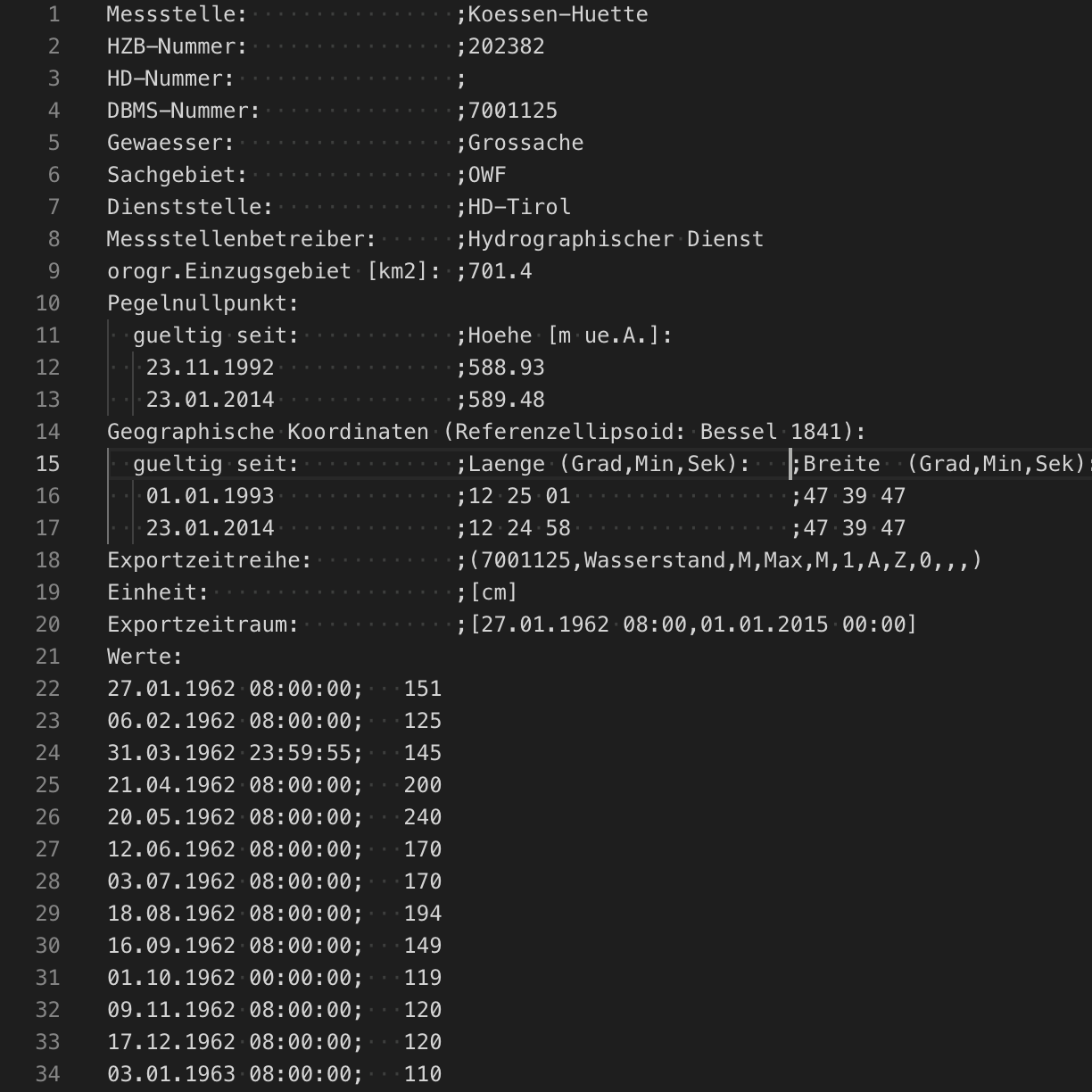
今回の分析には、生のデータセットが必要です。
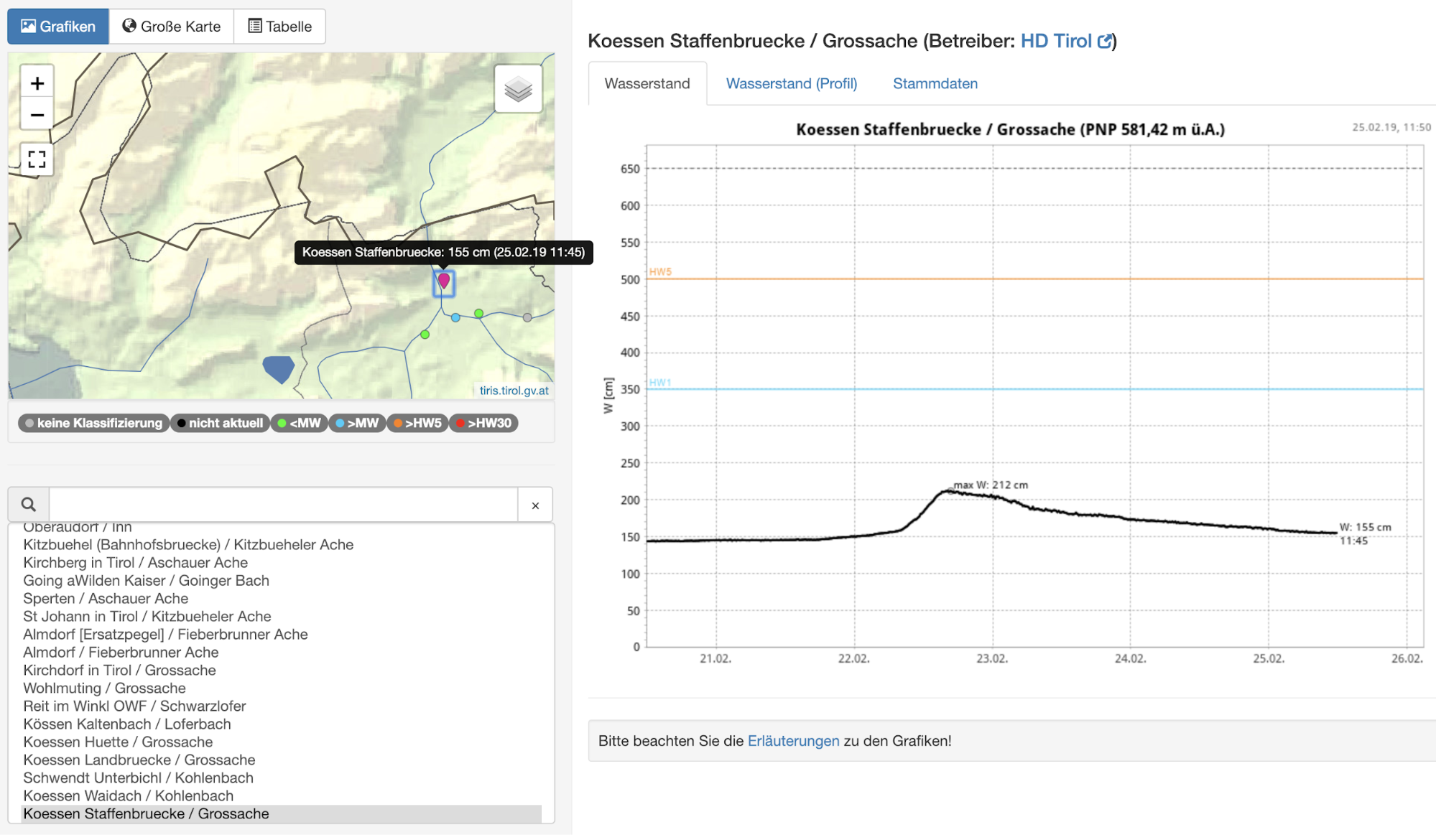
今回のケースでは幸運なことに、Webインターフェースでデータを調査できるだけでなく、過去データをダウンロードしてさらに深い分析を実施することができます。これから使用するグローサッヘ川の河川水位データは、“Huette”(ヒュッテ)という測定地で観測されたデータです。実測データに言及する注釈は、危険河川水位と洪水について説明した文書を参考に作成します。
|

|
Machine Learningの注釈は前半で説明したUIだけでなく、標準的な個別のElasticsearchインデックスにドキュメントとして格納されています。 注釈は標準的な各種のElasticsearch APIを使って手動で、あるいはプログラムを記述して作成することも可能です。注釈はバージョン固有のインデックスに格納され、.ml-annotations-readおよび.ml-annotations-writeのエイリアスからアクセスする必要があります。この事例ではMachine Learningジョブを作成する前に、過去の河川イベントを反映した注釈をあらかじめ追加しておきます。
{
"_index":".ml-annotations-6",
"_type":"_doc",
"_id":"DGNcAmoBqX9tiPPqzJAQ",
"_score":1.0,
"_source":{
"timestamp":1368870463669,
"end_timestamp":1371015709121,
"annotation":"2013 June; 770 m3/s; 500 houses flooded.",
"job_id":"annotations-leukental-4d-1533",
"type":"annotation",
"create_time":1554817797135,
"create_username":"elastic",
"modified_time":1554817797135,
"modified_username":"elastic"
}
}
ここまで完了したら、上述の注釈のjob_idフィールドに一致する名前を使用して手動作成した注釈を取り込めるようにし、河川水域の最大値における異常を検索します。河川の過去データをElasticsearchインデックスに投入した後でSingle Metricウィザードにジョブを表示すると、下の画面のようになります。
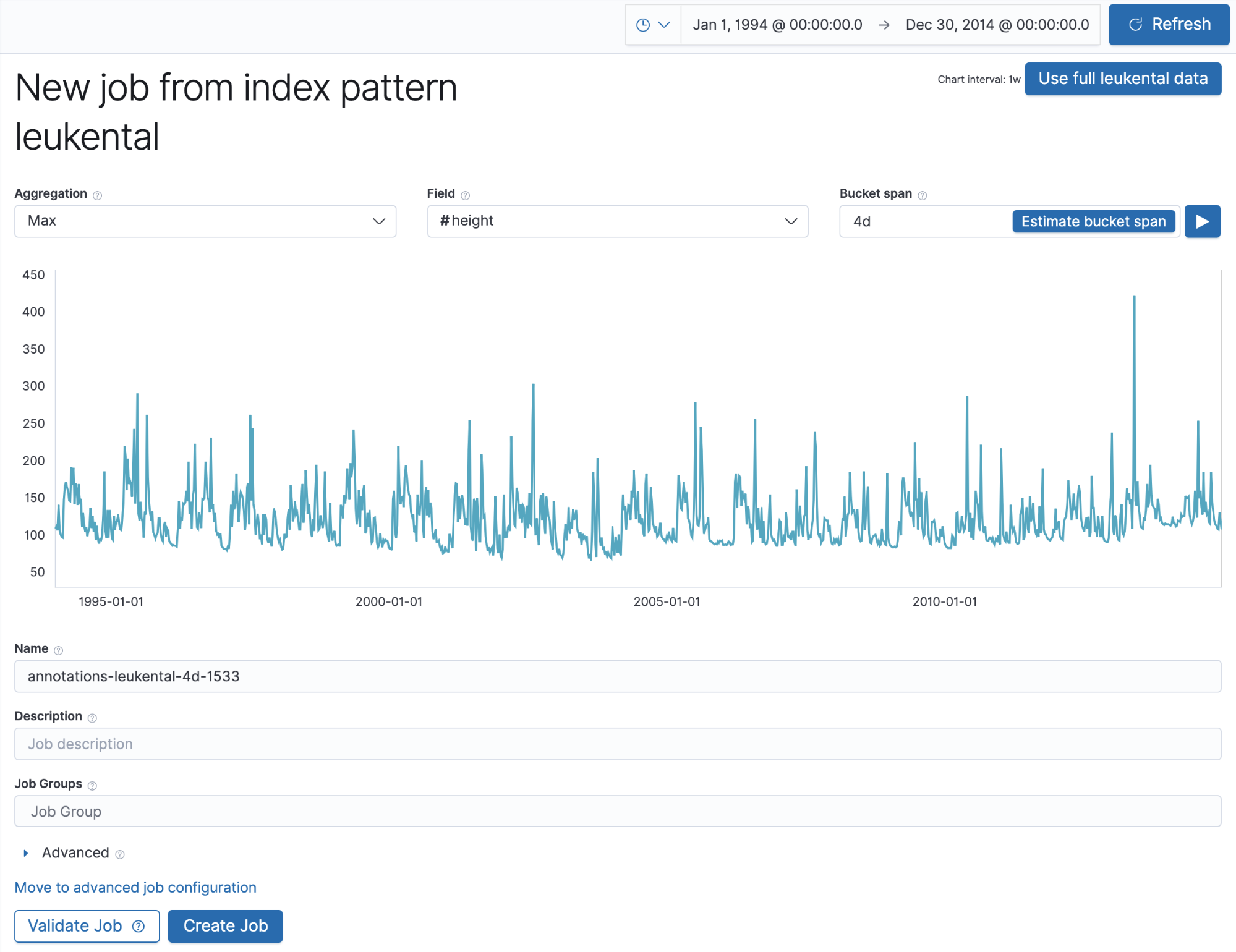
重要なのは、選択したジョブ名と注釈に使用した名前を一致させることです。ジョブを実行してSingle Metric Viewerに移動すると、Machine Learningジョブが検知した河川水位の異常に相当する注釈が表示されるはずです。
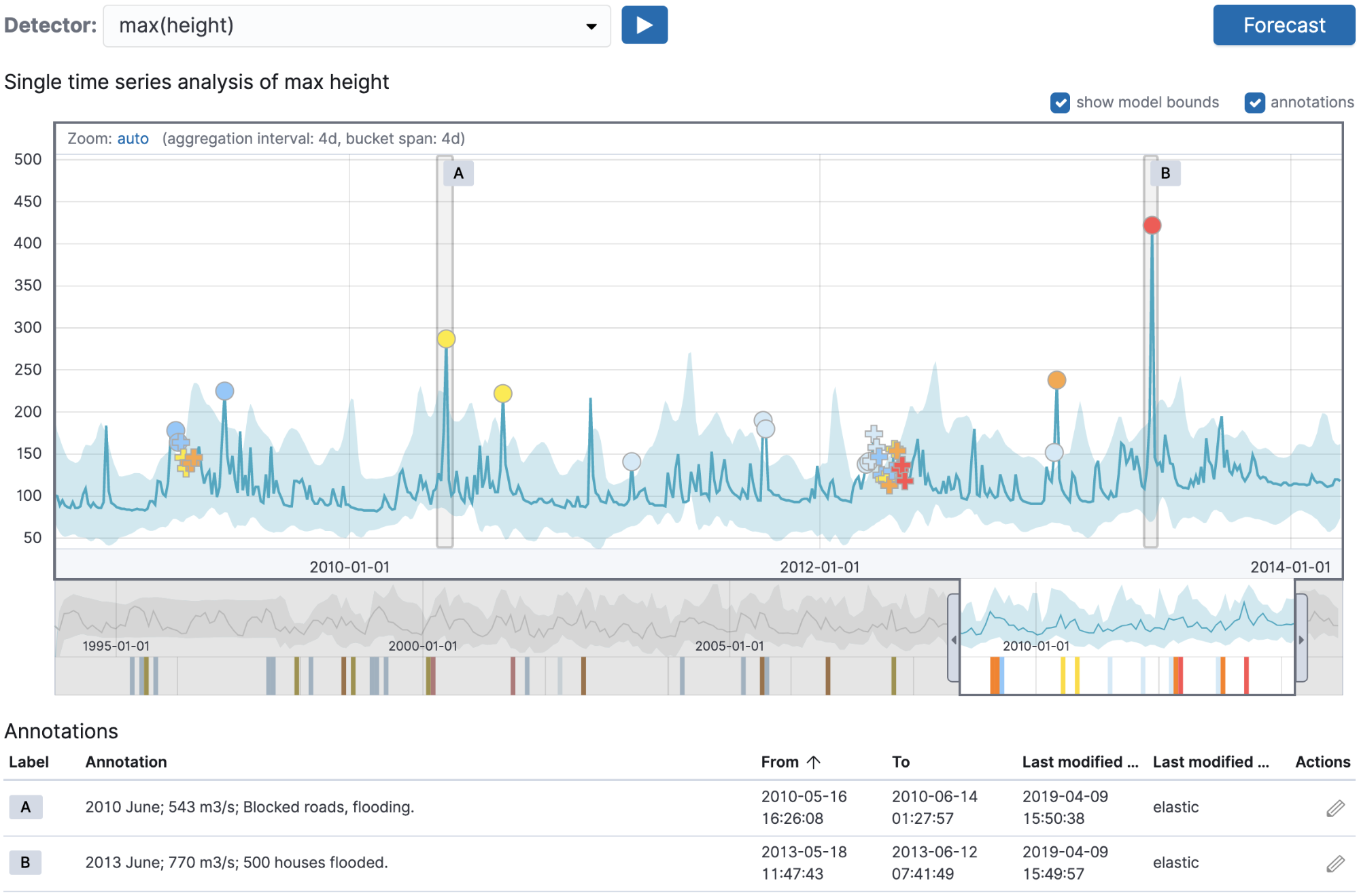
これは現在実行している分析の妥当性を、注釈として格納した既存の検証データと比較し、検証する非常に優れた手法です。
システムイベントの注釈
上の例はユーザーが生成する注釈でしたが、Machine Learningのバックエンドはシステムイベントが生じた場合に自動で注釈を作成します。
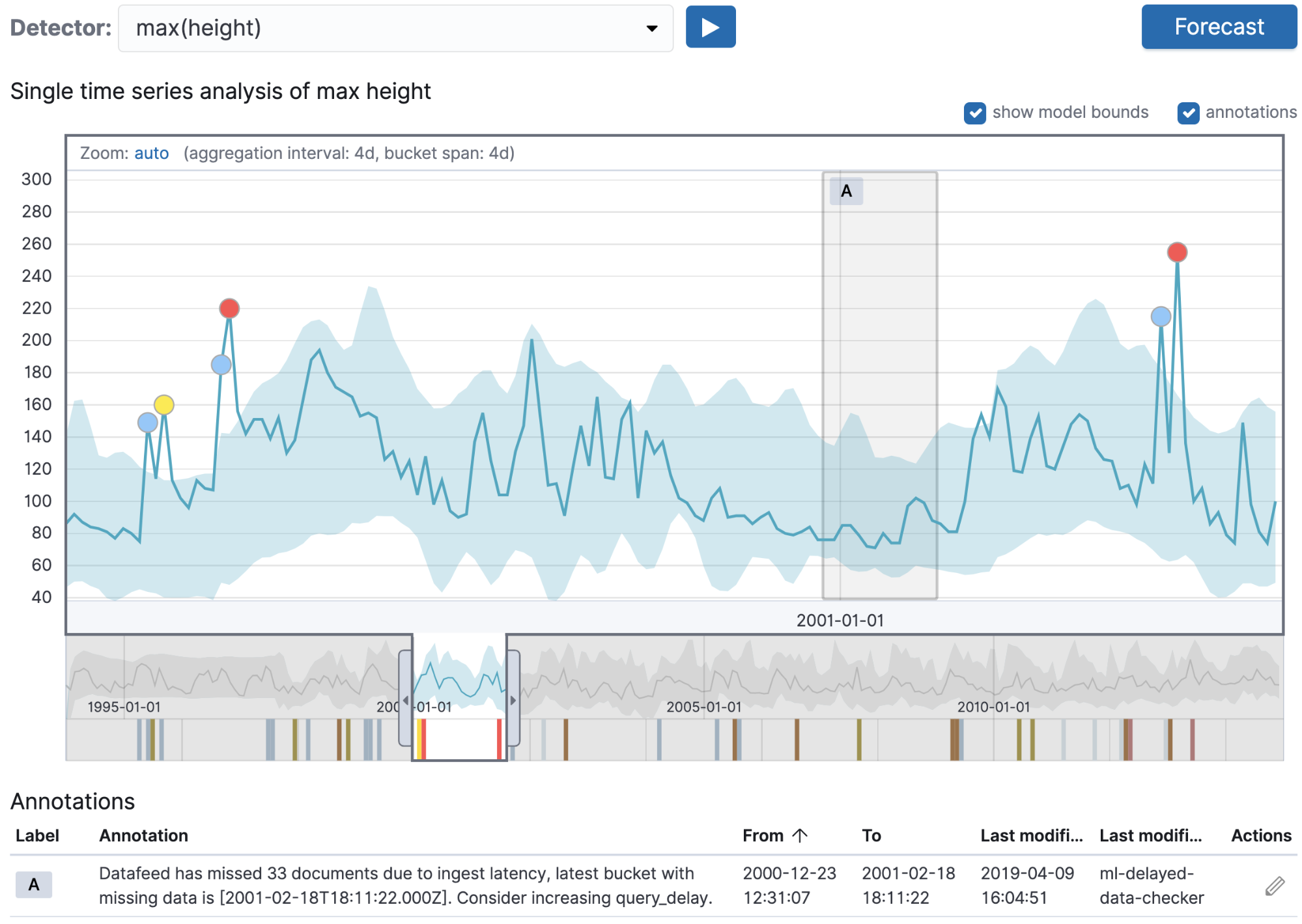
上のスクリーンショットは、自動で作成された注釈の例です。このケースではリアルタイムのMachine Learningジョブを実行していましたが、ジョブが必要とするペースに投入レートが追い付きませんでした。ドキュメントがインデックスに追加されたのは、ジョブがバケットで分析を実行した後のことでした。注釈が自動的作成されたことで、従来は検知やデバッグが難しかった問題が明るみに出ています。この注釈説明機能は、特定した問題の詳細を報告するだけでなく、解決策も提案します。すなわちこのケースでは、query_delay設定値の引き上げを提案しています。
アラートの統合
Watcherは、Machine Learningにユーザー注釈機能が登場する以前からありました。機械学習機能で特定された異常に基づいてアラートを作成する機能です。単純な閾値に基づくアラートに比べると非常に高性能ですが、アラート受信者にとってはしばしば「細かすぎる」一面もあります。Machine Learningジョブを使用している場合、注釈を使用してWatcherがトリガーするアラートを整理し、他の関係者に共有すべきアラートを選別することができます。注釈は個別のElasticsearchインデックスに格納されているため、このインデックスでWatcherを使って新規に作成されたドキュメントに反応し、通知をトリガーするよう設定することができます。またWatcherは、Slackチャンネルにアラートを送信するように設定することも可能です。以下の例は、新規の注釈が作成された場合にSlackメッセージをトリガーするようWatcherを設定しています。
{
"trigger": {
"schedule": {
"interval":"5s"
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": [
".ml-annotations-read"
],
"rest_total_hits_as_int": true,
"body": {
"size":1,
"query": {
"range": {
"create_time": {
"gte": "now-9s"
}
}
},
"sort": [
{
"create_time": {
"order": "desc"
}
}
]
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gte":1
}
}
},
"actions": {
"notify-slack": {
"transform": {
"script": {
"source": "def payload = ctx.payload; DateFormat df = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'\"); payload.timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.timestamp))); payload.end_timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.end_timestamp))); return payload",
"lang": "painless"
}
},
"throttle_period_in_millis":10000,
"slack": {
"message": {
"to": [
"#<slack-channel>"
],
"text":"New Annotation for job *{{ctx.payload.hits.hits.0._source.job_id}}*: {{ctx.payload.hits.hits.0._source.annotation}}",
"attachments": [
{
"fallback":"View in Single Metric Viewer http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))",
"actions": [
{
"name": "action_name",
"style": "primary",
"type": "button",
"text":"View in Single Metric Viewer",
"url": "http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))"
}
]
}
]
}
}
}
}
}
上の設定で<slack-channel>を<kibana-host>に置き換えると、高度な監視を作成することができます。設定が完了すると、新しい注釈を作成するたびにSlackの通知を受信できます。通知には注釈の説明文と、Single Metric Viewerへのリンクが含まれています。

まとめ
Elasticsearch Machine Learningに新たに加わった注釈機能についてご紹介しました。UIから注釈を追加することも、システムの注釈をバックエンドタスクでトリガーさせることもできます。注釈は[Job Management]ページでブックマークしたり、リンクを他の人と共有できます。またプログラムを記述して外部データの注釈を作成し、実測データのオーバーレイとして検知した異常の検証に使用する活用法もあります。そしてWatcherやElasticsearchのSlack通知機能と組み合わせることにより、通知するアラートを絞り込む使い方もご紹介しました。注釈機能を楽しく使っていただければ幸いです。ご不明点などはディスカッションフォーラムも併せてご覧ください。