複数のデータ・センターにおける Elasticsearch クラスター間のレプリケーション
データセンター間のレプリケーションは、Elasticsearch のミッション・クリティカルな用途では、しばらくの間は要件となってきましたが、以前は他のテクノロジーによって部分的に解決されていました。Elasticsearch 6.7 でのクロス・クラスター・レプリケーションの導入により、データ・センター、地理的にも、または Elasticsearch クラスター全体にわたって、情報をレプリケートするための追加のテクノロジーは不要になります。
クラスター横断複製 (CCR) は、1つの Elasticsearch クラスターから1つ以上の Elasticsearch クラスターへの特定のインデックスのレプリケーションを可能にします。データの局所性を含む複数のレプリケーション(ユーザー/アプリケーション・サーバへの近い場所にデータをレプリケートする、製品カタログのレプリケーションを、20個の異なるデータセンターに複製するなど) に加えて、CCR にはさまざまな使用例(本社のクラスターへの1,000の銀行の支店から報告を目的としてレプリケーションするなど)があります。
このチュートリアルでは、CCR を使用したデータセンター間のレプリケーションについて、私たちは CCR の基本を簡単に紹介し、アーキテクチャオプションとトレードオフを強調し、データセンターを使用しない展開のサンプルを構成して、管理コマンドを強調します。CCR の技術概要については、「リーダーをフォローする: Elasticsearch でのクラスター間レプリケーションの概要」を参照してください。
CCR は、プラチナレベルの機能であり、試用版の API を通じて有効にするか、または Kibana から直接有効化できる30日間の試用ライセンスを使用できます。
クロスクラスターレプリケーション (CCR) の基本事項
レプリケーションはインデックス・レベル (またはインデックスパターンに基づいて)で構成される
CCR は Elasticsearch のインデックスレベルで構成されます。レプリケーションをインデックスレベルで構成することにより、一部のインデックスを一方向にレプリケートする、他のインデックスを別の方向に複製する、複数のデータセンターアーキテクチャなど、レプリケーションに関する多数の戦略を利用できます。
レプリケートされたインデックスは読み取り専用である
インデックスは、1つ以上の Elasticsearch クラスターによって複製できます。インデックスをレプリケートしている各クラスターは、インデックスの読み取り専用コピーを保持しています。アクティブなインデックス書き込みを受信できるのはリーダーといいます。そのインデックスのパッシブな読み取り専用コピーは、フォロワーと呼ばれます。新しいリーダーには選挙の概念はなく、リーダーインデックスが使用できない場合 (クラスターやデータセンターの停止など)、別のインデックスは、アプリケーションまたはクラスターアドミニストレーター (多くの場合別のクラスターでも可) によって書き込みが行われるよう明示的に選択する必要があります。
CCR の既定値は、多種多様な高スループットの用途で選択可能
値を調整することがシステムに与える影響を完全に理解していない限り、既定値を変更することはお勧めしません。 ほとんどのオプションは、"max_read_request_operation_count" や "max_retry_delay" などのフォロワーの作成 API にあります。すぐに、独自の作業負荷に合わせて、これらのパラメーターを調整するための情報を今後公開します。
セキュリティ要件
CCR 入門ガイドで説明しているように、ソース・クラスターのユーザーは、"read_ccr" クラスター特権、"監視"、および "読み取り" インデックスの特権を持っている必要があります。ターゲット・クラスター内では、「manage_ccr」クラスタ権限、「monitor」、「read」、「write」、「manage_follow_index」インデックスの権限が必要です。LDAP などの集中認証システムも使用できます。
複数データセンター CCR アーキテクチャの例
本番および DR データセンター
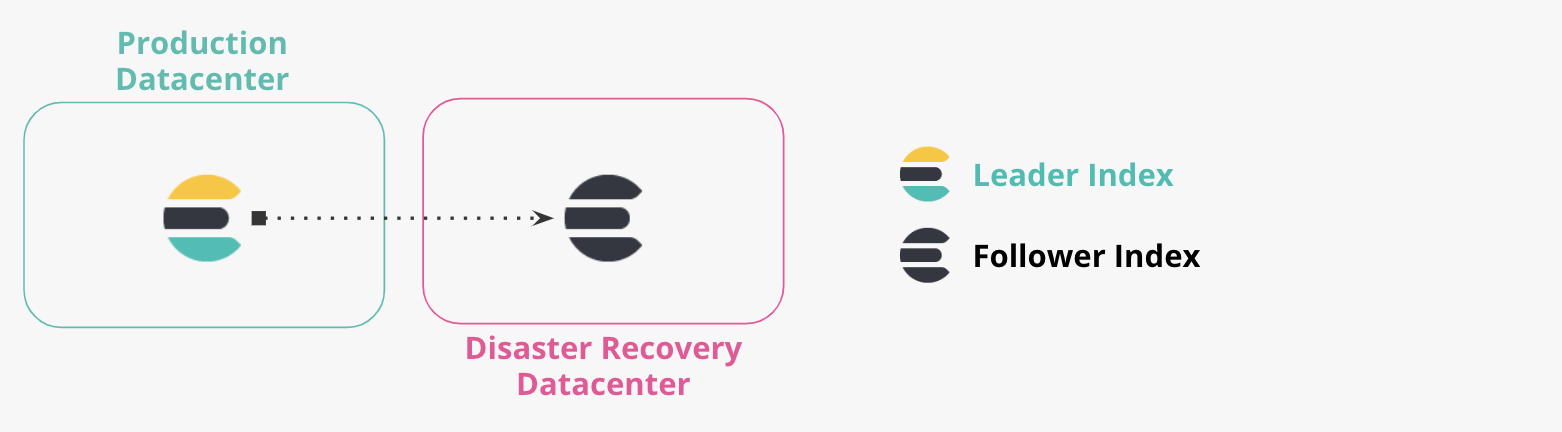
2つ以上のデータセンター
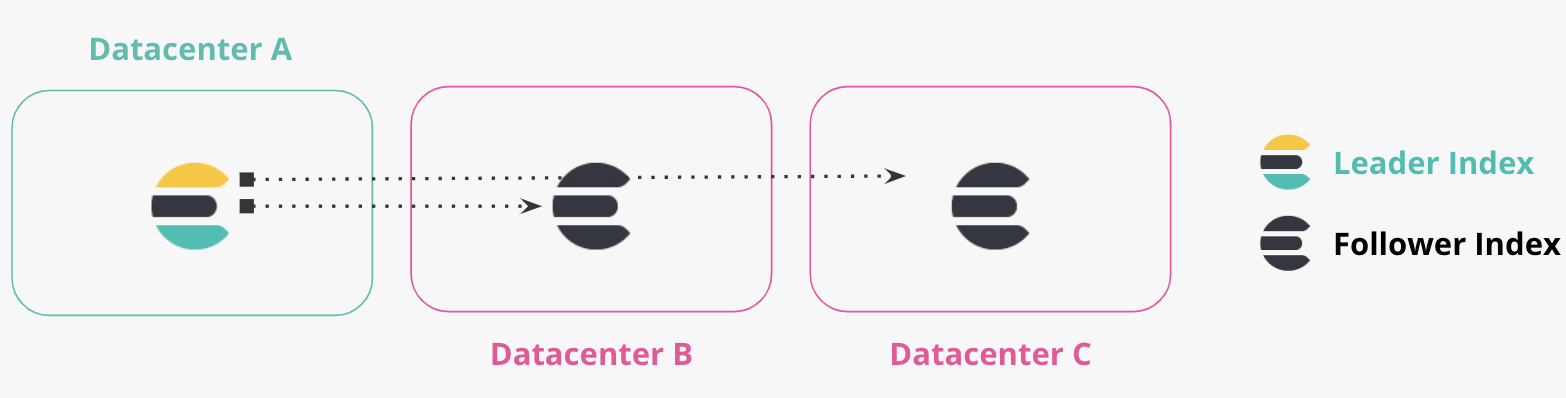
データは、datacenter A から複数のデータセンター (ダイアグラムの B と C) にレプリケートされます。データセンター B および C には、データセンター a 内のインデックスの読み取り専用コピーが現在保存されています。
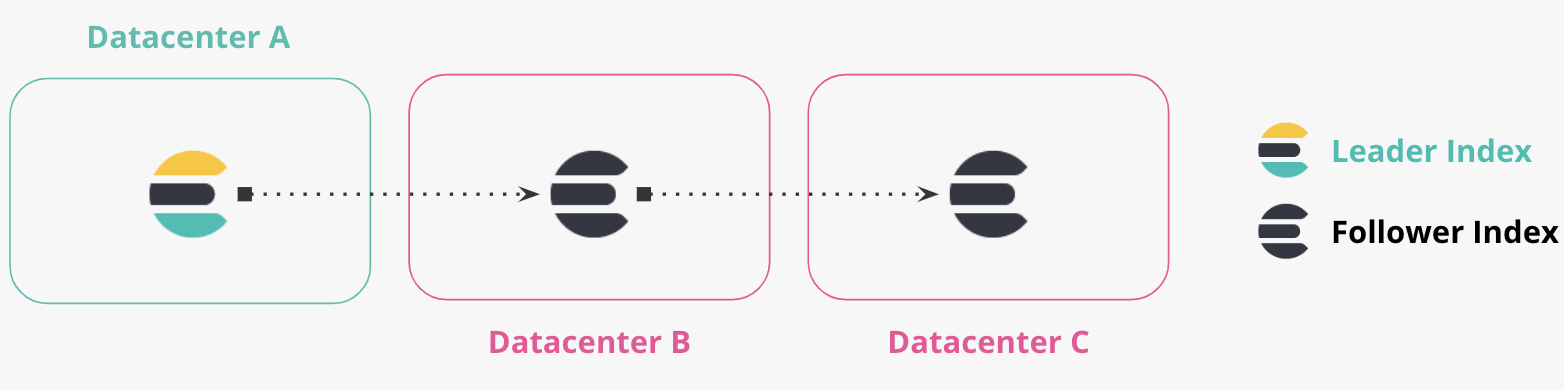
チェーンレプリケーション
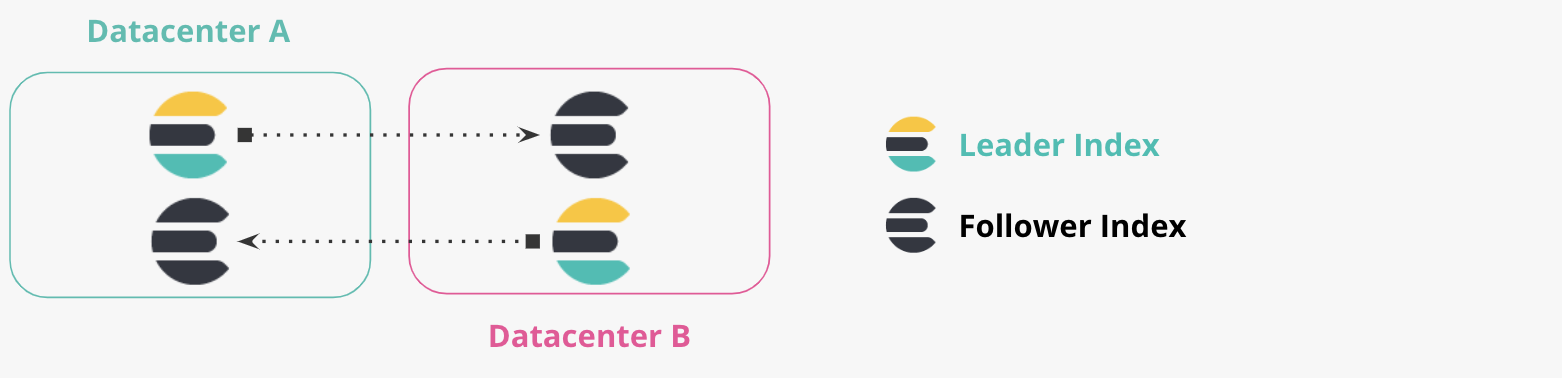
双方向のレプリケーション
データセンター間の導入に関するチュートリアル
1. セットアップ
このチュートリアルでは2つのクラスターを使用し、両方のクラスターはローカルコンピューター上にあります。どのような場所にいても、クラスターは自由に検索できます。
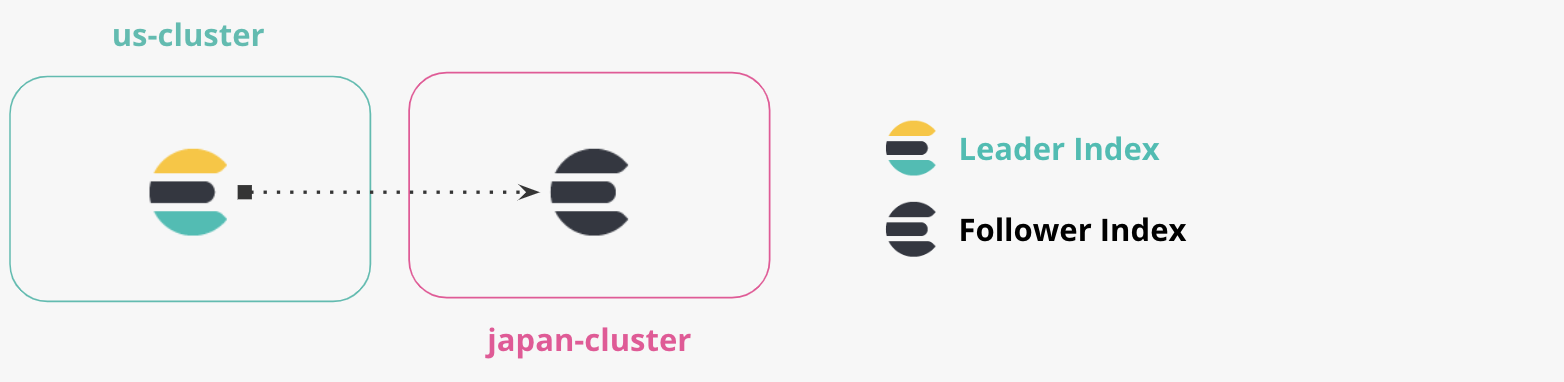
- 「us-cluster」: これは当社の「米国のクラスター」であり、ポート9200でローカルに実行します。ドキュメントは米国のクラスターから日本のクラスターに複製されます。
- ‘「japan-cluster」: 当社の「日本のクラスター」である、ポート8200でローカルに実行します。日本のクラスターでは、米国のクラスターからレプリケートされたインデックスを維持します。
2. リモートクラスターの定義
CCR を設定する場合、Elasticsearch クラスターは他の Elasticsearch クラスターを認識している必要があります。これは単一方向の要件であり、ターゲットクラスターはソースクラスターに対する単一方向の接続を維持します。他の Elasticsearch クラスターをリモートクラスターとして定義し、それらを説明するエイリアスを指定します。
日本のクラスターにおける「us-cluster」の認識を確保したいと思います。CCR でのレプリケーションはプルベースであるため、「us-cluster」から「japan-cluster」への接続を指定する必要はありません。
「japan-cluster」の API 呼び出しで 「us-cluster」 を定義します。
# From the japan-cluster, we’ll define how the us-cluster can be accessed
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"remote" : {
"us-cluster" : {
"seeds" : [
"127.0.0.1:9300"
]
}
}
}
}
}
(APIベースのコマンドについては Kibana 内で Dev tools コンソールを使用することをおすすめしますが、これは Kibana-> Dev tools-> Console) から入手できます。
API の呼び出しでは、"127.0.0.1: 9300" でエイリアス "us-cluster" を持つリモートクラスターにアクセスできます。1つ以上のシードを指定できますが、ハンドシェイクフェーズ中にシードが使用できない場合には、一般に複数を指定することをお勧めします。
リモートクラスターの構成の詳細については、リファレンスドキュメントを参照してください。
また、「us-cluster」と接続するためにポート9300に注意しても重要なのは、elasticsearch がポート9200で HTTP プロトコルを耳にしていることです (これはデフォルトであり、「us-cluster」の yml ファイルで指定されています)。ただし、レプリケーションは、Elasticsearch のトランスポートプロトコル (ノード間通信のため) を使用して行われます。デフォルトはポート9300です。
Kibana 内では、リモートクラスターの管理 UI があり、このチュートリアルでは、ui と CCR の API を順を追って説明します。Kibana のリモートクラスター UI にアクセスするには、左側のナビゲーション・パネルで [管理] (歯車アイコン) をクリックし、Elasticsearch のセクションで「リモート・クラスター」に移動します。
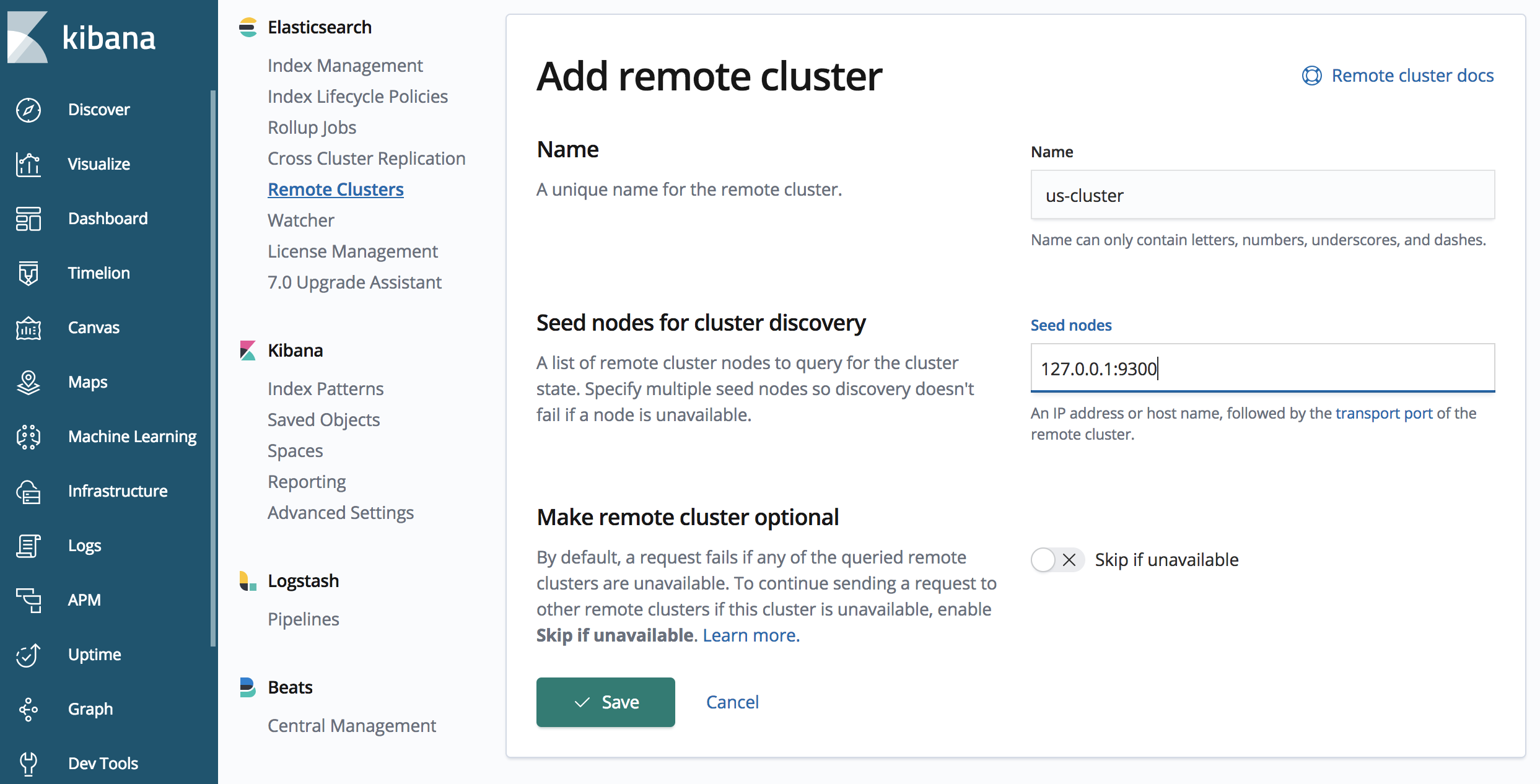 Kibanaの Elasticsearch Remote Cluster Management UI
Kibanaの Elasticsearch Remote Cluster Management UI
3. レプリケーションに使用するインデックスを作成する
「products」と呼ばれるインデックスを「us-cluster」に作成し、このインデックスをソース「 us-cluster」から「japan-cluster」に複製します:
"us-cluster" で、次のようになります。
# Create product index
PUT /products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0,
"soft_deletes" : {
"enabled" : true
}
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
"soft_deletes" の設定にお気づきかもしれません。CCR のリーダーインデックスとして機能するインデックスには、論理削除が必要です (ご存知ない方はこちらを参照してください)。
soft_deletes: 論理削除は、既存のドキュメントが削除または更新されたときに発生します。これらの論理削除を構成可能な制限まで保持することで、工程の履歴をリーダーシャードに保持し、工程の履歴を再現することでフォロワーシャードの作業に使用できるようになります。
フォロワーシャードがリーダーから操作を複製すると、リーダーシャードにマーカーが残され、リーダーのフォロワーの位置がわかるようになります。これらのマーカーの下にあるソフト削除された操作は、破棄対象となります。これらのマーカーの上にあるリーダーシャードは、シャード履歴保持リースの期間 (デフォルトは12時間) これらの操作を保持します。この期間により、致命的が遅れてリーダーから再ブートストラップされるリスクが生じる前にフォロワーをオフラインにできる期間が決定されます。
4. レプリケーションの開始
リモートクラスターのエイリアスを作成し、レプリケートするインデックスを作成したので、次にレプリケーションを開始しましょう。
「japan-cluster」において:
PUT /products-copy/_ccr/follow
{
"remote_cluster" : "us-cluster",
"leader_index" : "products"
}
このエンドポイントには ' product-copy ' が含まれていますが、これは "japan-cluster ' クラスター内の複製さインデックスの名前です。前に定義した ' us-cluster ' クラスターからレプリケートしていますが、レプリケートしようとしているインデックスの名前は、' us-cluster ' クラスター上の ' product ' と呼ばれています。
重要なのは、レプリケートされたインデックスが読み取り専用であり、書き込み操作を受け付けることができないという点です。
これでElasticsearch クラスター間で複製を行うインデックスを構成しました!
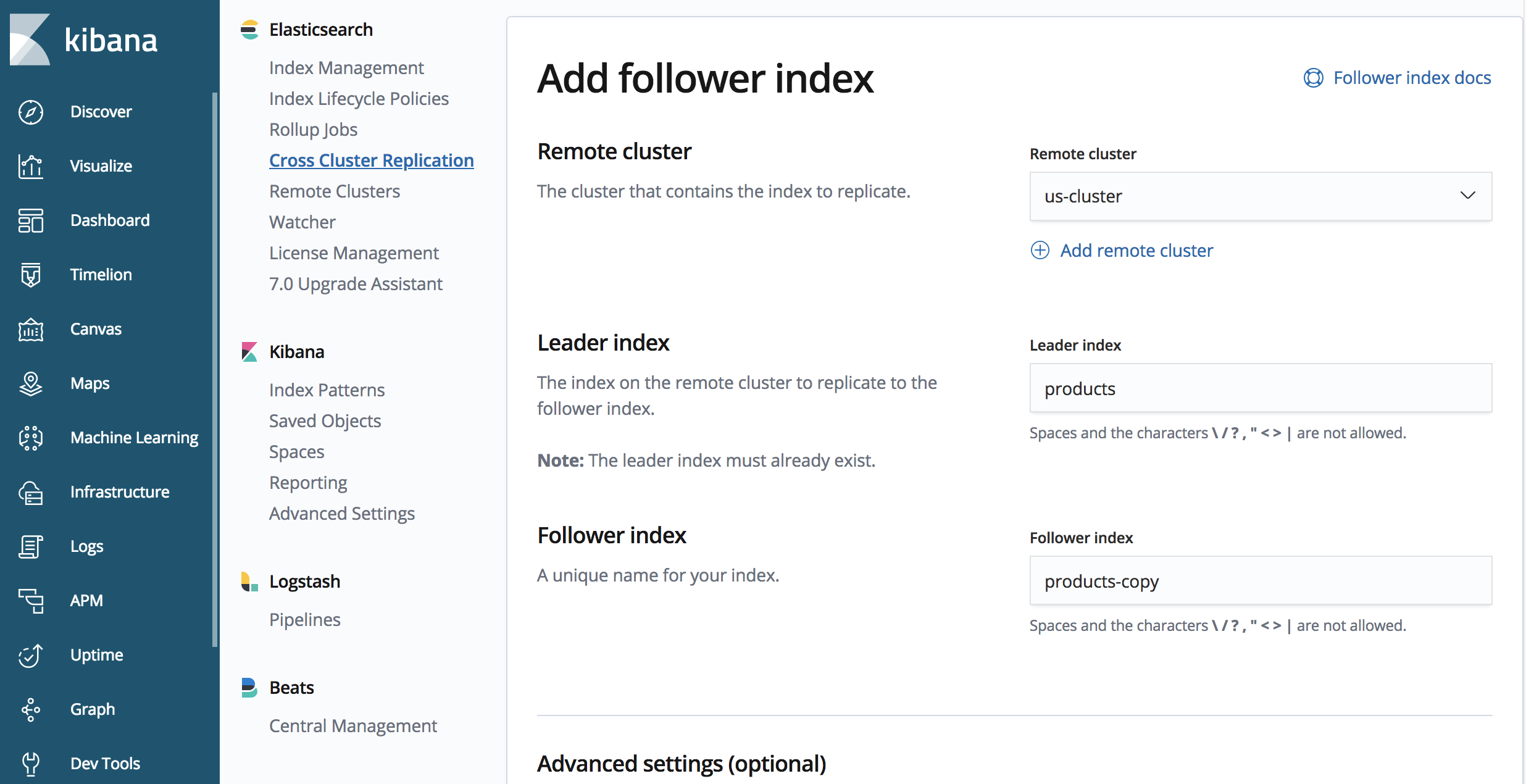
インデックス・パターンのレプリケーションの開始
お気づきかもしれませんが、上記の例は時間ベースの使用法には十分なものではなく、日次インデックス、または大量データに関しては正しく動作しません。また、CCR API には、複製するパターンを自動で指定するパターン、つまり、レプリケートする必要があるインデックスものを定義するメソッドも含まれています。
CCR API を使用して、自動フォローパターンを定義できます
PUT /_ccr/auto_follow/beats
{
"remote_cluster" : "us-cluster",
"leader_index_patterns" :
[
"metricbeat-*",
"packetbeat-*"
],
"follow_index_pattern" : "{{leader_index}}-copy"
}
上記のサンプル API 呼び出しは、'metricbeat' または 'packetbeat' で始まるインデックスを複製します。
また、Kibana で CCR UI を使用して、自動フォローパターンを定義することもできます。
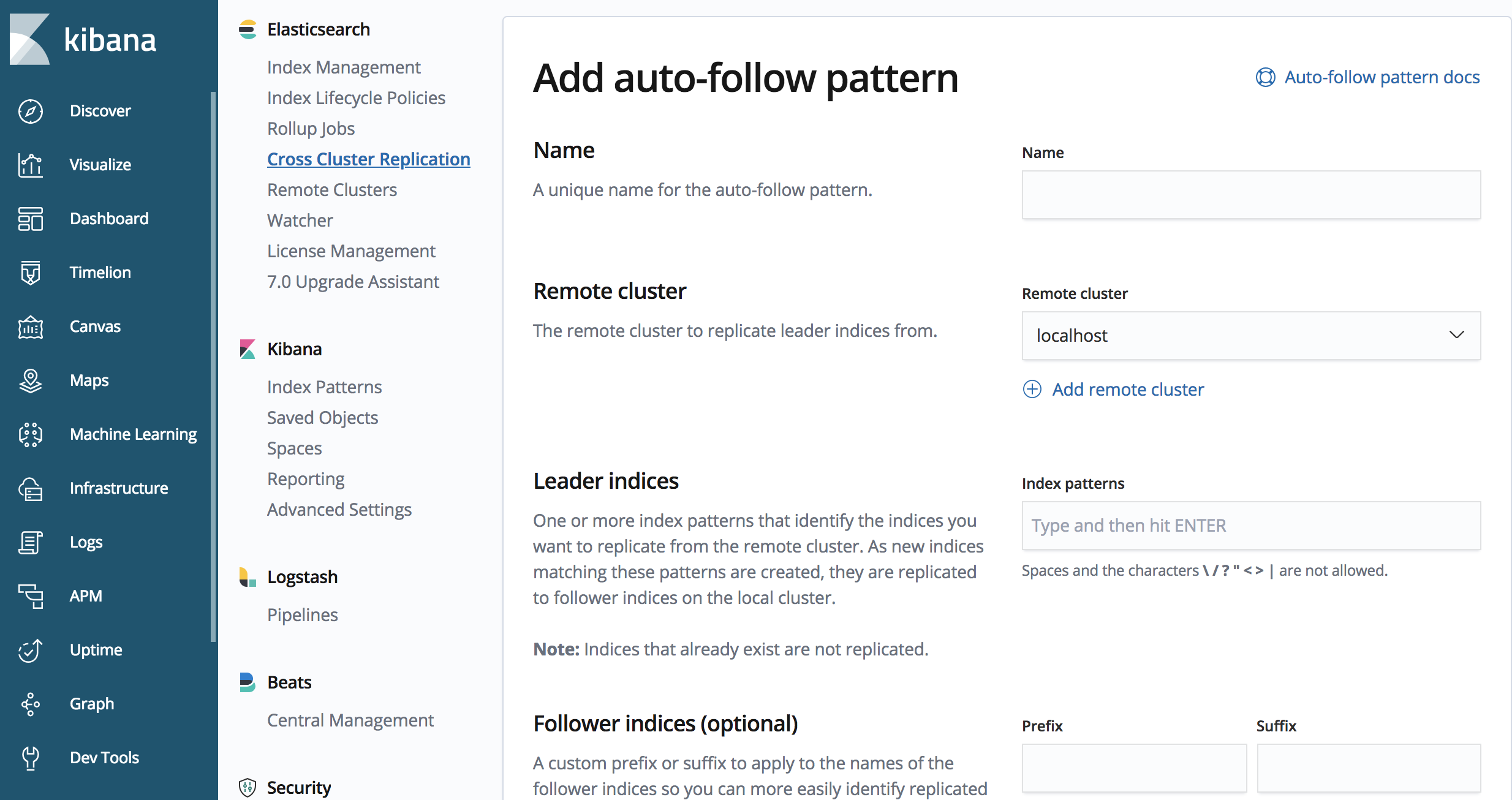
5. レプリケーションのセットアップのテスト
「us-cluster」から「japan-cluster」に製品を複製したので、今度はテスト用の文書を挿入し、それが複製されたことを確認してみましょう。
"us-cluster" クラスター上:
POST /products/_doc
{
"name" : "My cool new product"
}
次に、「日本のクラスター」クエリして、ドキュメントが確実に複製されているか確認しましょう:
GET /products-copy/_search
1つのドキュメントが存在し、「us-cluster」に書き込まれて、「japan-cluster」に複製されるはずです。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "products-copy",
"_type" : "_doc",
"_id" : "qfkl6WkBbYfxqoLJq-ss",
"_score" : 1.0,
"_source" : {
"name" : "My cool new product"
}
}
]
}
}
データセンター間管理に関する注意事項
CCR の管理上の API、チューニング可能な設定、およびレプリケートされたインデックスを通常のインデックスに変換する方法の概要について見てみましょう。
レプリケーションの管理 API群
CCR では、Elasticsearch に、便利な管理用 API がいくつかあります。これらは、レプリケーションのデバッグ、レプリケーション設定の変更、詳細診断の収集などに役立つ場合があります。
# Return all statistics related to CCR
GET /_ccr/stats
# Pause replication for a given index
POST //_ccr/pause_follow
# Resume replication, in most cases after it has been paused
POST //_ccr/resume_follow
{
}
# Unfollow an index (stopping replication for the destination index), which first requires replication to be paused
POST //_ccr/unfollow
# Statistics for a following index
GET //_ccr/stats
# Remove an auto-follow pattern
DELETE /_ccr/auto_follow/
# View all auto-follow patterns, or get an auto-follow pattern by name
GET /_ccr/auto_follow/
GET /_ccr/auto_follow/
CCR 管理 APIs の詳細については、Elasticsearch のリファレンスドキュメントを参照してください。
フォロワーインデックスを通常のインデックスに変換する
上記の管理 API群 の一部を使用して、フォロワーインデックスを Elasticsearch の通常のインデックスに変換し、書き込みを受け入れることができます。
# Pause replication
POST //_ccr/pause_follow
# Close the index
POST /my_index/_close
# Unfollow
POST //_ccr/unfollow
# Open the index
POST /my_index/_open
Elasticsearch の CCR (クロスクラスターレプリケーション) を引き続き探索する
このガイドは Elasticsearch での CCR の使用を開始するお手伝いをするために作成されたものですが、CCR を十分に理解していただき、CCR のさまざまな APIs (Kibana で使用できる UI を含む) について学習し、この機能を試していただければうれしいです。その他のリソースとしては、「クロスクラスターレプリケーションの概要」および「クロスクラスターレプリケーション API ガイド」を参照してください。
ディスカッションフォーラムにご意見やご感想をお寄せください。すべての質問については、できるだけ早く回答するように心がけています。