Elasticオブザーバビリティでインフラとマイクロサービスを監視する
ソフトウェアを開発、実行する方法は、インフラストラクチャーとソフトウェア分野を席捲する数々のトレンドによって大きく変わりました。この結果インフラストラクチャーはコードとして扱われるようになり、インフラ使用にかかるコストが下がったほか、各種プロダクトをより早く市場に送り出すことも可能になりました。このような新しいアーキテクチャーを使えば、本番環境を模したデプロイで高速にソフトウェアをテストでき、また一般に安定的で、再現性のあるデプロイを構築できます。一方、こうしたメリットと共に、環境が複雑化するというデメリットがあることも事実です。これは、新しいインフラストラクチャーを効果的に監視する上で特に顕著なデメリットです。
このブログ記事は、カスタムアプリケーションとサービス、それらを実行するインフラストラクチャーを含む、完全なアプリケーションスタックを監視するための“マストハブ”、要件について解説します。さらに、ElasticオブザーバビリティソリューションとElastic Stackを使ってこのニーズを解決する手法もご紹介します。この手法はオブザーバビリティを向上させ、ダウンタイムを短縮する究極の監視プラットフォームの構築を支援します。実際に試したいと感じた方は、Elastic Cloudの無料トライアルではじめることも、またはElasticのWebサイトで最新バージョンをダウンロードして使うこともできます。
進化するアーキテクチャー ― コンテナーとマイクロサービスが登場するまで
私たちが現在の状況に至るまでの道のりを振り返ってみましょう。インフラストラクチャーソフトウェアの分野は急速に進化しています。ハードウェアに関して言えば、物理マシンからさまざまな仮想化ツール(あるいはハイパーバイザー)への移行があり、その後パブリッククラウドインフラの登場を目撃しました。おかげでサーバーとネットワークの保守やプロビジョニング作業のアウトソースが可能になり、“Time to Value”(価値実現までの時間)が短縮されました。筆者は、プロジェクトに必要な新しいサーバーがプロビジョニングされるまで何週間も待たなければならなかった時代のことをまだ覚えています。現在でもどこかでそうしたことがあるかもしれませんが、基本的には解決済みの問題と言えるでしょう。今日の問題は、コンテナープラットフォームです。DockerやKubernetesなどのコンテナーオーケストレーターは、多くの組織で採用されるプラットフォームとなっています。言うまでもなく、そういった組織の多くでは同時にベアメタルホストの仮想化も使われています。
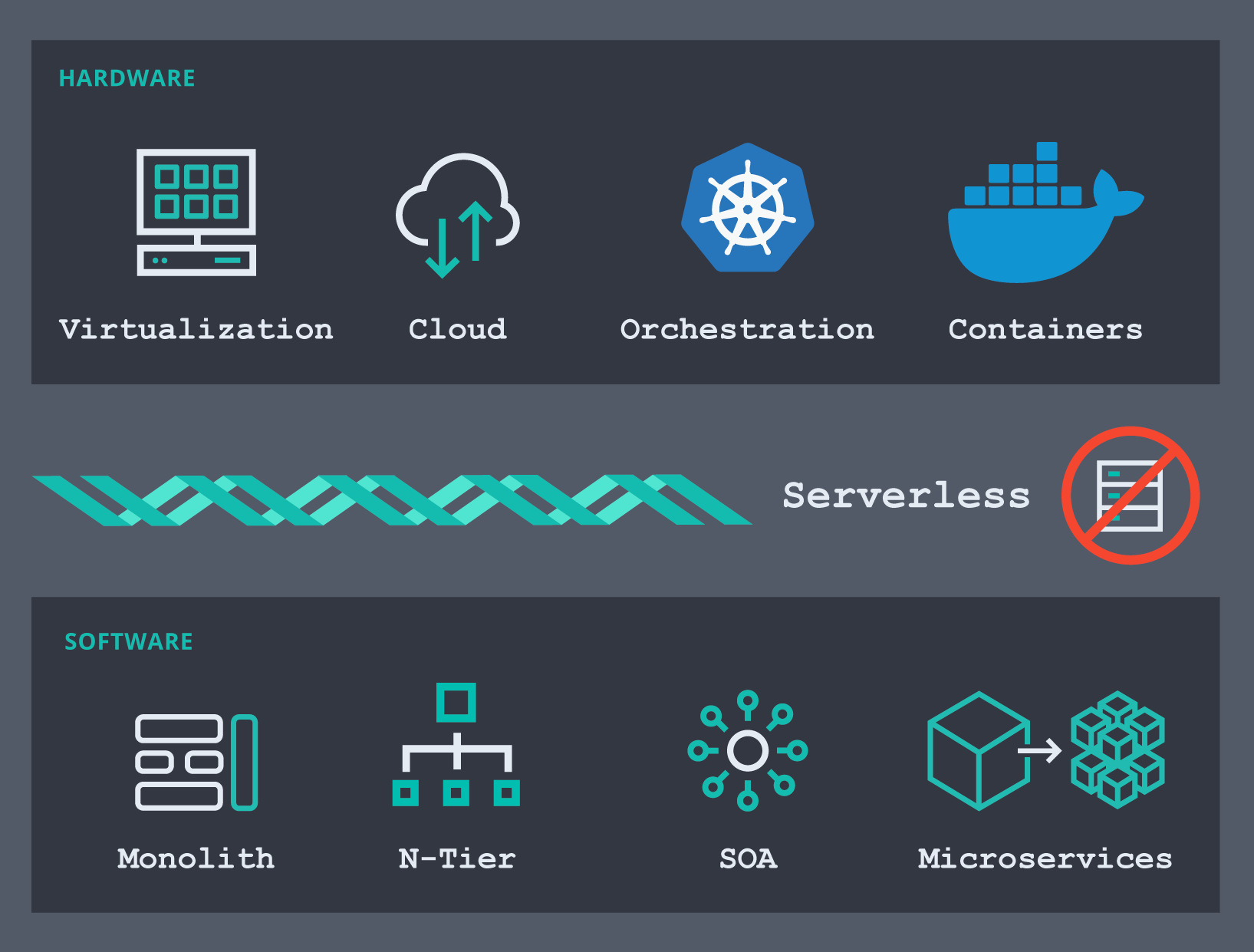
同時期、ソフトウェアの現場ではモノリスの開発からソフトウェアを複数レイヤー(プレゼンテーション、アプリケーション、データetc)へデカップリングする開発へと移行してきました。やがてサービスオリエンテットアーキテクチャー(SOA)が設計の主流なパターンとなり、それがさまざまな方向性で進化を遂げました。つまり、Webサービス、イベントドリブンアーキテクチャー、そして最新型のマイクロサービスの登場です。今日、新しいアプリケーションを開発するとなれば、クラウドのどこかで稼働する、Kubernetesのpodで実行されるマイクロサービスベースである可能性が高いでしょう。もちろん古いモノリスをマイクロサービスに分割し、オーケストレーターを使ってデプロイしようというイニシアチブを1つ以上進めている組織も存在するかもしれません。
この結果、スタックで監視すべきコンポーネントは以前より増えました。また、各種の監視ツールを使い、高頻度で出現しては消滅するコンテナーを備え、変化し続けるアプリケーションを追跡することが必要となっています。最新の環境を監視する取り組みにおいては、全面的に新しいアプローチが求められています。
インフラストラクチャーを監視する ― 複雑性を扱うための要件
今日のデプロイ環境について論じるとき、少なからぬ要素を考慮する必要があります。オンプレミスのデータセンターからパブリッククラウドのインフラ、ハイブリッドまで、まずデプロイを実行するインフラストラクチャーがあります。現在、典型的な環境にはオーケストレーションレイヤー(例:Kubernetes)があり、このレイヤーでアプリケーションのデプロイとスケーリングを自動化しています。それから、コンテナーやVM、ベアメタルなど、どこでアプリを実行するかです。またアプリケーションの開発にあたっては、外部サービスやデータベース、組織の他のチームが記述したコンポーネントなど、サードパーティのシステムとの依存関係を導入します。もちろん、アプリケーション自体も、内部コンポーネントと、エンドユーザーエクスペリエンスの双方について考慮しなくてはなりません。
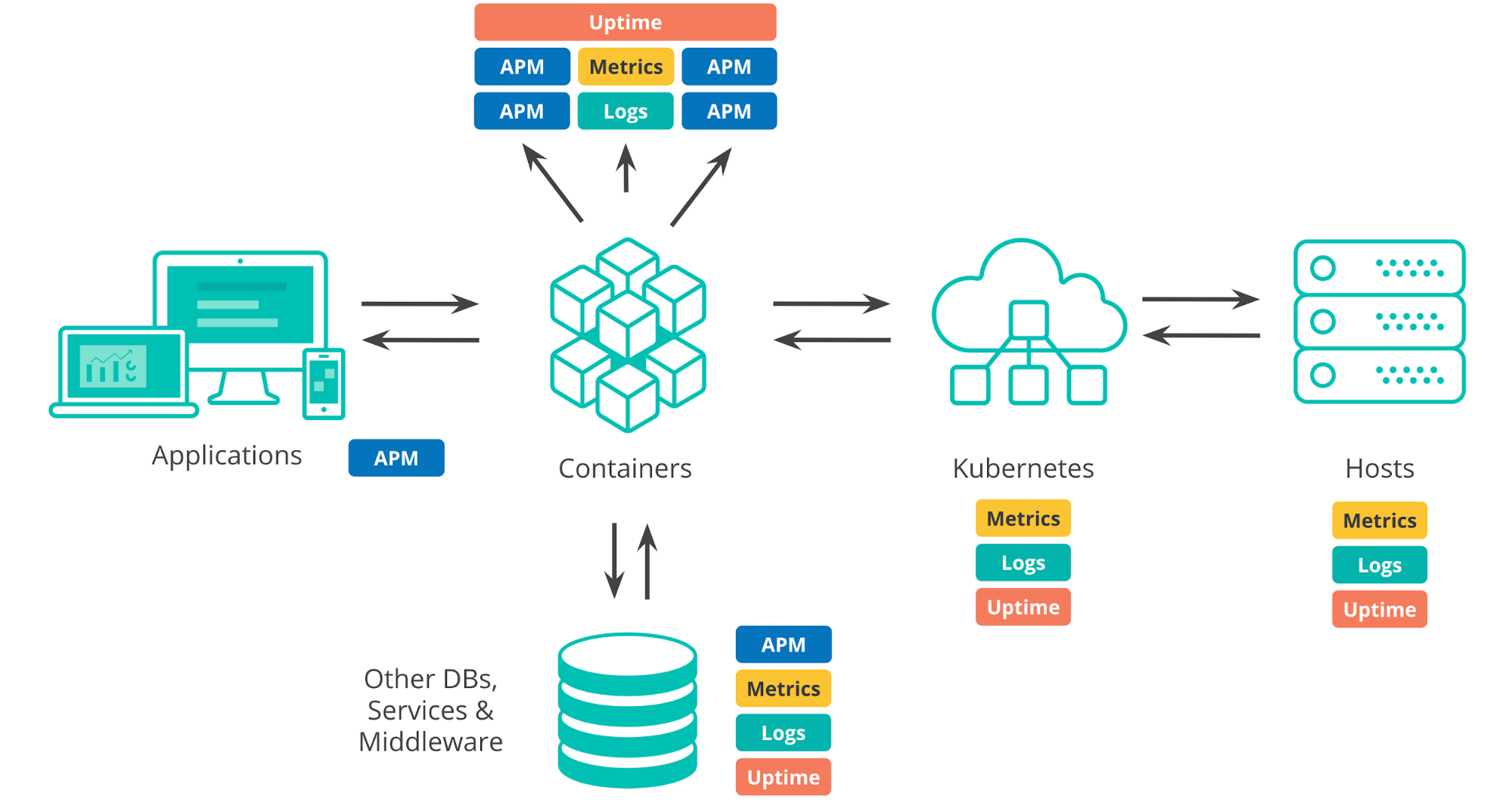
すべてのアプリケーションが正しく実行されていることを確認するには、このようなさまざまなコンポーネントをすべて監視する必要があります。さらに、これらすべてのコンポーネントは大量の監視データ、すなわちログとメトリックだけでなく、APMとアップタイムデータを生成しています。
このようなデプロイについて完全な可視性を確立する監視ソリューションの要件は、以下の通りです。
- ホストからアプリケーションまで、インフラストラクチャーとアプリケーションスタック全体をサポートする仕様である。
- VM、コンテナー、オーケストレーター、クラウドプラットフォーム、データベースなど多様なソースから簡単にデータをインジェストする仕様である(通常、監視ソリューションが提供する他のシステムとの統合機能により決まる)。
- インフラストラクチャーのコンテナー化に伴ってますます動的となるデプロイに対応しつつ、従来型の古いインフラストラクチャーにも対応する。
- 運用データを加工し、DevOpsからプロダクトチーム、経営陣まで組織の全員に最適な各種のビューを構築するためのパワフルな手段を搭載している。
- 問題が生じたとき、それを通知する機能がある。 アラートは、あらゆる監視ソリューションにおいて基本的な構成要素の1つであり、インフラ全体をカバーする必要があるため。
- ログおよびメトリック用に長期の安定したストレージがあり、履歴分析や各種の規制要件への準拠に対応する。さらにストレージソリューションは、粒度と保持レートを完全に制御するデータライフサイクル管理機能も備えている。
- インフラストラクチャーとアプリケーションに対する包括的なオブザーバビリティに適した仕様である。多くの典型的な監視ツールは1つのデータタイプに特化している(人気の時系列データベースの多くはメトリックにしか対応していない)のに対し、一般的なデプロイ環境はあらゆる種類のデータ(ログ、メトリック、APM、アベイラビリティデータ)を生成する。したがって、データストリームは環境のパフォーマンスについてさまざまな視点から情報を提供するものであり、データを別個に扱ったり、学習曲線や、ライセンスモデル、サポートモデルが異なる多様なツールを保守したりすることにはメリットがない。
- 1つの監視ソリューションで、上記のすべての要件を満たしている。
| 上のリストは、2つのコア要件に要約することができます。すなわち、インフラストラクチャー監視ソリューションはインフラストラクチャーのすべての部分から運用データを収集できるということ、および、実践的なデータに変換できるということです。 |
インフラストラクチャー監視にElastic Stack(ELK Stack)を活用する
進化と向上を続けるパワフルな監視を通じて最新のインフラストラクチャーを効果的にオブザーブするには、高速、スケーラブル、かつフレキシブルなソリューションが必要です。そこでElasticのテクノロジーがこの問題解決にどう役立つか、ご紹介します。
ログとメトリックのインジェスト
Elasticは数百種類のプラットフォームとサービスが生成するログ、およびメトリックデータのインジェストに対応する統合機能を提供しています。この統合機能を使えば新規のデータソースを簡単に追加できるだけでなく、ダッシュボードや複数の可視化、事前構築済みのパイプライン(たとえば、ログから特定のフィールドを抽出できる)など、設定不要で使える各種のアセットも含まれています。ElasticはElastic Stackにログとメトリックデータをシッピングするプロダクトとして、MetricbeatとFilebeatを提供しています。統合機能はすべてMetricbeatとFilebeatでサポートされており、Kibanaのインストラクションに従って簡単に使うことができます。
オブザーバビリティ(と、セキュリティ)の領域を広げるうちに、やがて多くのシッパーやエージェントを使いこなすことになります。特に大規模なエンタープライズ環境の場合、大量のエージェントを設定、管理する作業は複雑になりがちです。エージェントをデプロイして、configファイルを更新し、データを管理する…多くのチームが現在もこうした作業に従事していますが、これはなかなか大変です。Elasticはこのプロセスを改善したいと考え、7.8リリースで2つの新しいコンポーネント、“Elastic Agent”と“Fleet”を導入しました。この2つのコンポーネントは、Elastic Stackに運用データを送るプロセスを大きく進化させます。
- Elastic Agentはログ、メトリック、他のタイプのデータを収集する単一のエージェントです。手動で個々の統合機能を保守する作業に比べ、Elastic Agentのインストール・管理ははるかに簡単です。
- FleetはKibanaに登場した新しいアプリで、指定したプラットフォームとサービスの統合機能をすばやく有効化するプロセスと、Elastic Agentの集団全体を一元的に管理するプロセスの2つを手助けします。
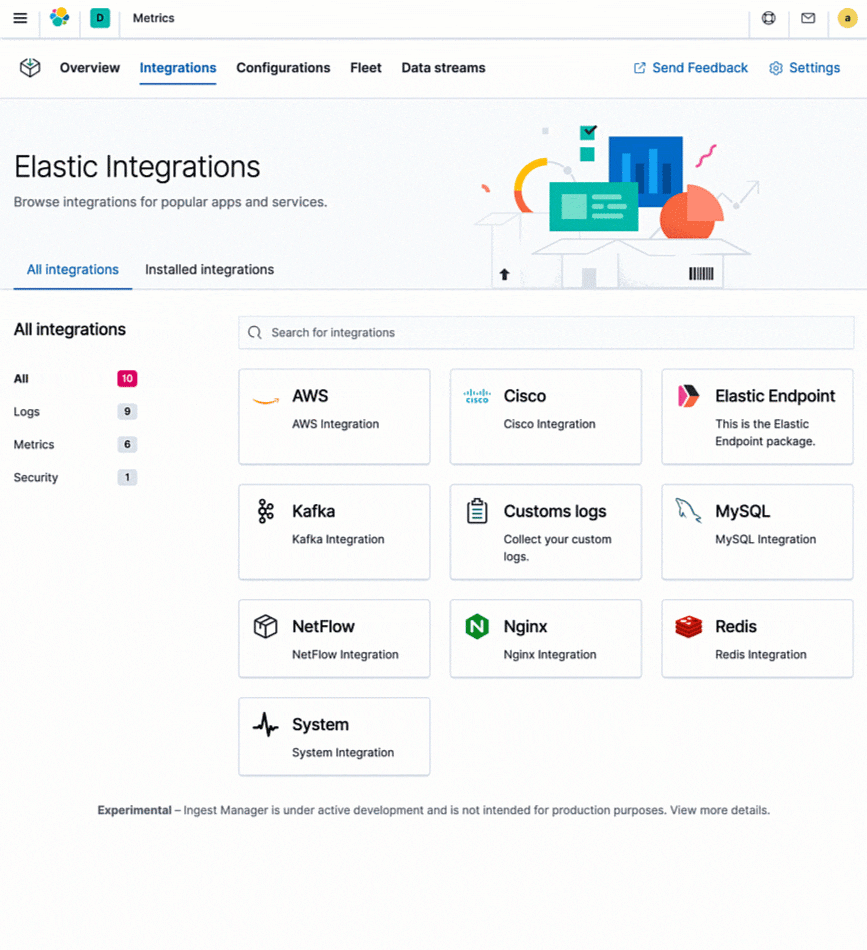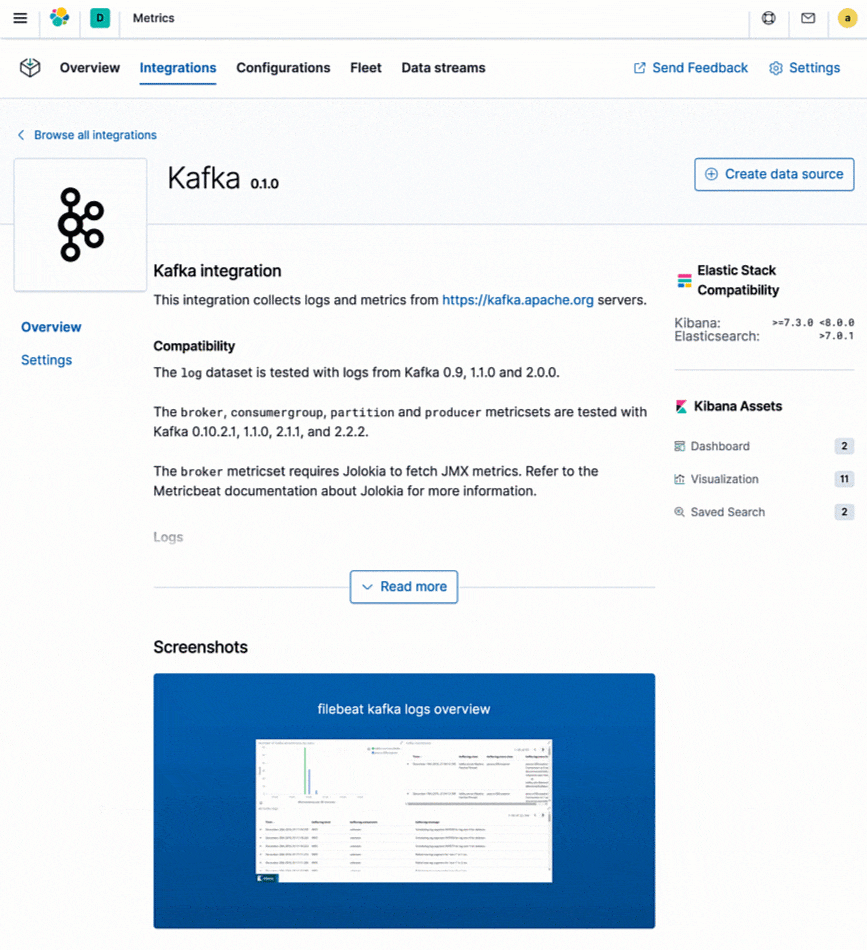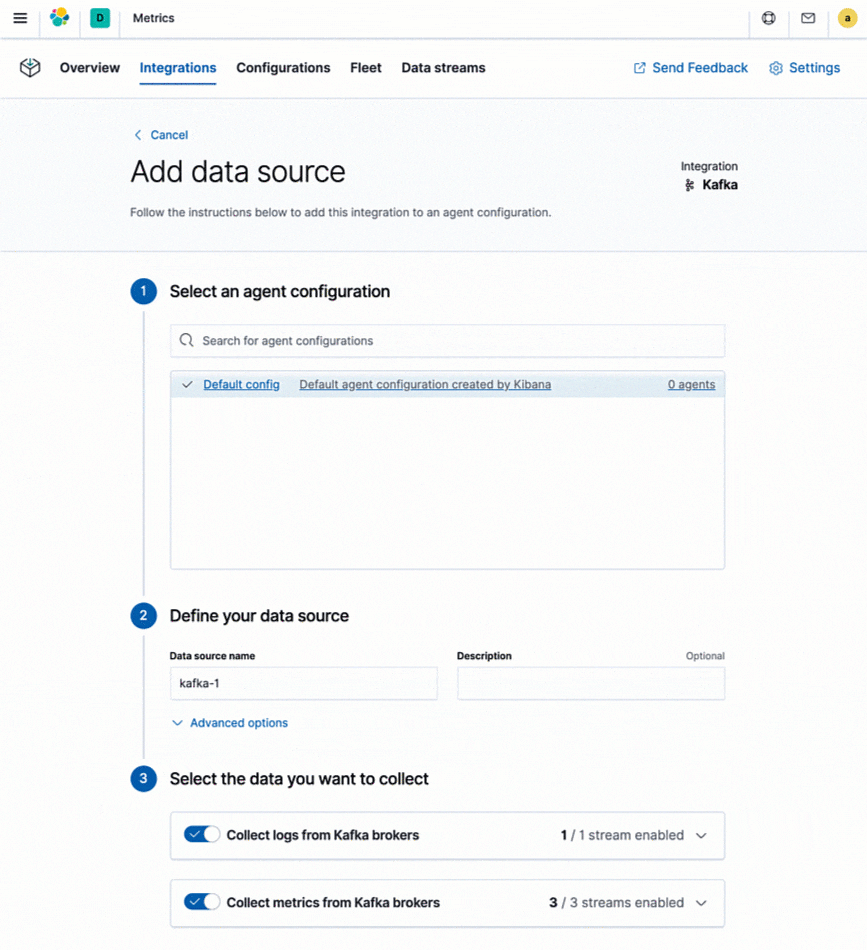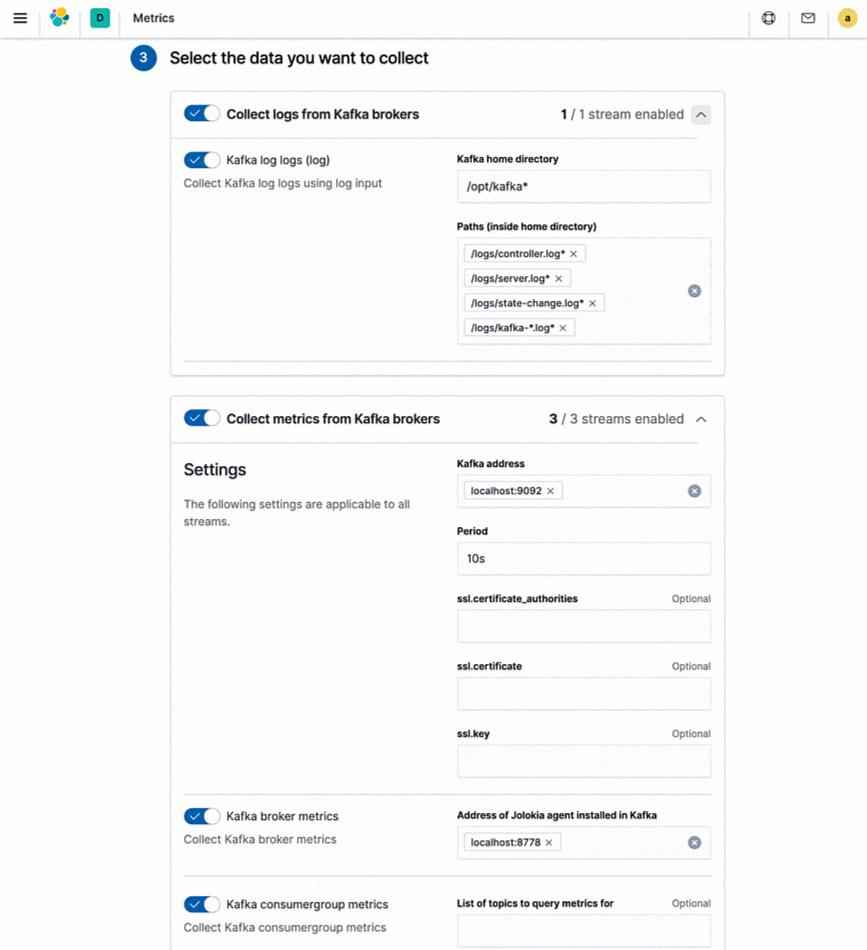
既に導入済みの監視ツールとの併用について検討してみましょう。現在、StackdriverやAzure Monitorなどのネイティブなクラウド監視サービス、またはPrometheusやstatsdといったツール類を導入済みで、収集したメトリックをログや他のデータと組み合わせて一元化したいというユーザーも、Elasticが提供する専用の統合機能を使うことができます。他の高次の監視ツール向け統合機能を使い、既存のインストルメンテーション(たとえば、prometheus exporterなど)は保持しながら、メトリックと他の運用データを格納してオブザーバビリティを向上させることが可能です。
本記事の冒頭で、コンテナー化したデプロイへの移行に伴い、システムの監視方法全般を見直す必要が生じることを説明しました。これは、物理ホストや仮想化マシン、静的なインフラストラクチャーを扱う想定で設計された従来型の監視ツールについて特に言えることです。コンテナー化した場合、従来型監視ツールが提唱するアプローチでは十分ではありません。つまりコンテナー化したデプロイでは、状況は常に変化し、コンテナーが増減し、より高頻度にサービスがデプロイされ、IPアドレスは不安定で信頼できません。そして多くの監視ツールは、こうした条件に対応できる設計ではありません。アプリケーションを実行するコンテナーは、監視システムにとって実質的に“移動する標的”のように見えます。そのため、環境内で新規にデプロイされたサービスや、スケールされたインスタンス、アップグレードなどの変化を自動検知する必要が生じます。悪いニュースばかりではありません。MetricbeatとFilebeatはいずれも自動検知能力を備えており、デプロイの追跡や、変化の検知のほか、新たに実行をはじめたサービスを監視するための設定の調整などを実施できます。
さらに、Elasticの統合機能が収集するすべてのデータはElastic Common Schema(ECS)に準拠しているため、Elasticオブザーバビリティとセキュリティソリューションの全般にわたりデータを参照できます。ECSと他の一般的なデータモデルの違いについて触れておきましょう。ECSは設計上、Elasticsearchに最適化されています。ECSはオープンソースであり、Elasticのグローバルなコミュニティのコントリビューションによって開発されました。インフラストラクチャーメトリックやログ、APM、セキュリティなど、開発時から幅広いユースケースを想定しています。たとえるなら、ECSはElasticの全ソリューションをつなぐ関節部です。ECSを使うことで、多様なデータストリームを統一的な方法で相関付け、可視化、分析できます。
ECSはElasticのテクノロジーの外部でも活用されており、各種ユースケースにおいて、領域固有のスキーマを用いたエンリッチのために導入する組織が増えています。また、チームを横断するプロジェクトで、ECSを共通のデータモデルとして使用する組織もあります。Elasticのソリューションが組織のサイロを破壊し、チームの結集に貢献している事例があることは、私たちにとっても大きな喜びです。
ログとメトリックを格納する
データの格納と言えば、Elasticsearchはおそらく一般的に“ログ向けのストレージシステム”として認知されています。それは当然のことかもしれません。従来、Elasticsearchの最初のユースケースはほとんどがロギングでした。その後、ログと共に時系列データを格納するユーザーが増えました。これも自然なことです。インフラストラクチャーとアプリケーションのログを格納するのであれば、ログを調査するタイミングの把握に必要なメトリックも格納する方が理に適っています。
初期にはこうしたユースケースに対応するべく、Elasticsearchに列志向ストアを導入することで、時系列データのストアとして使うための開発が行われました。次に、アグリゲーションフレームワークが追加され、次元の異なるメトリックのグループ化や絞り込みを実行することが可能になりました。さらに、数的データと地理データの処理能力を向上させるBKDツリーが導入されたほか、履歴データの粒度を上げる(例:ダウンサンプリング)データロールアップや、Hot、Warm、Cold、Deleteという異なるフェーズでデータの保持期間を制御するインデックスライフサイクル管理など、時系列データを効率的に管理するための多数の機能も追加されました。
監視データを実践的データに変換する
可視化
さて、インジェストが正常に動作し、Elastic Stackにログとメトリックがストリーミングされているとしましょう。まずは、このデータを有意義な形で見てみたいと思うはずです。監視ツールの中には、データ可視化の作成や検索プロセスを完全にユーザーに委ねるものもあります。しかし、Elasticは可視化のビューを“不可欠なもの”と位置づけ、サポートするすべての統合機能について事前構築済みの可視化とダッシュボードを提供しています。つまり、ログとメトリックの収集を開始すると同時にダッシュボードをチェックして、システムやサービスで起きていることをリアルタイムに把握できます。
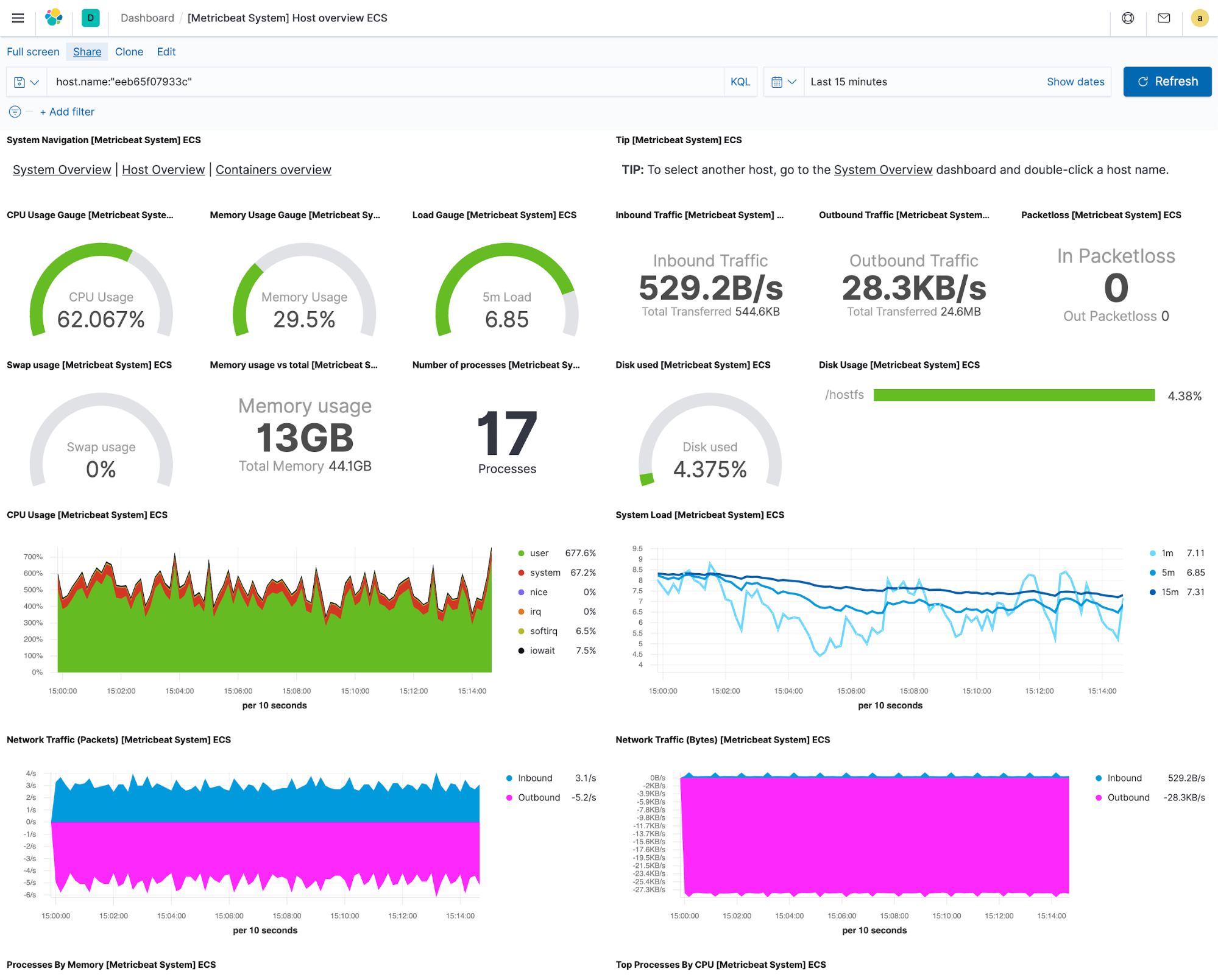
事前定義済みダッシュボードを構築する可視化要素はすべて再利用できます。つまり、特に有用な可視化要素を選んで特定のニーズ向けのカスタムダッシュボードを作成したり、異なる統合機能からくるデータを組み合わせてあなたが抱く疑問の答えを入手したりできます。さらに、絞り込みやドリルダウンのためのカスタムドロップダウンも作成できます。カスタムドロップダウンを使うと、ダッシュボードからダッシュボードへ、コンテクストを見失うことなく移動でき、トラブルシューティングのワークフローの合理化に貢献するので大変便利です。
Elasticは各種のダッシュボードと可視化に加え、ログ、メトリック、アベイラビリティデータ向けの精選されたアプリも提供しています。各種アプリはいずれも、お使いのインフラストラクチャーの可視性を向上させる目的で設計されています。
Metricsアプリを使うと、一つの画面でインフラストラクチャー全体を確認できます。地理的に分散させたデータセンターを設置しているかどうか、あるいは複数のクラウドで実行中のKubernetesや、すべてを一緒くたに投げ込んでいるセットアップがあるか否かにかかわらず、インフラをもれなく確認できます。Metricsアプリはすべてのリソースを単体の透明なパネルに表示します。ユーザーはインフラのプロバイダーや地理空間ゾーン、ステージングと運用の環境を区別するカスタムタグのあらゆるフィールドに基づいてリソースをグループ化できます。このビューを通じて、すべてのリソースに関する詳細なメトリックや、ログ、アプリケーションパフォーマンス、アップタイム情報も確認できます。一連のメリットは、このように捉えることもできます。全運用データを入れる単体のデータストアとしてElastic Stackを使うことにより、精選されたビューの構築と、そのビューを相互にリンクさせたシンプルなナビゲーションが実現します。その結果、インフラストラクチャーの監視エクスペリエンス自体がよりスムーズなものになる、ということです。
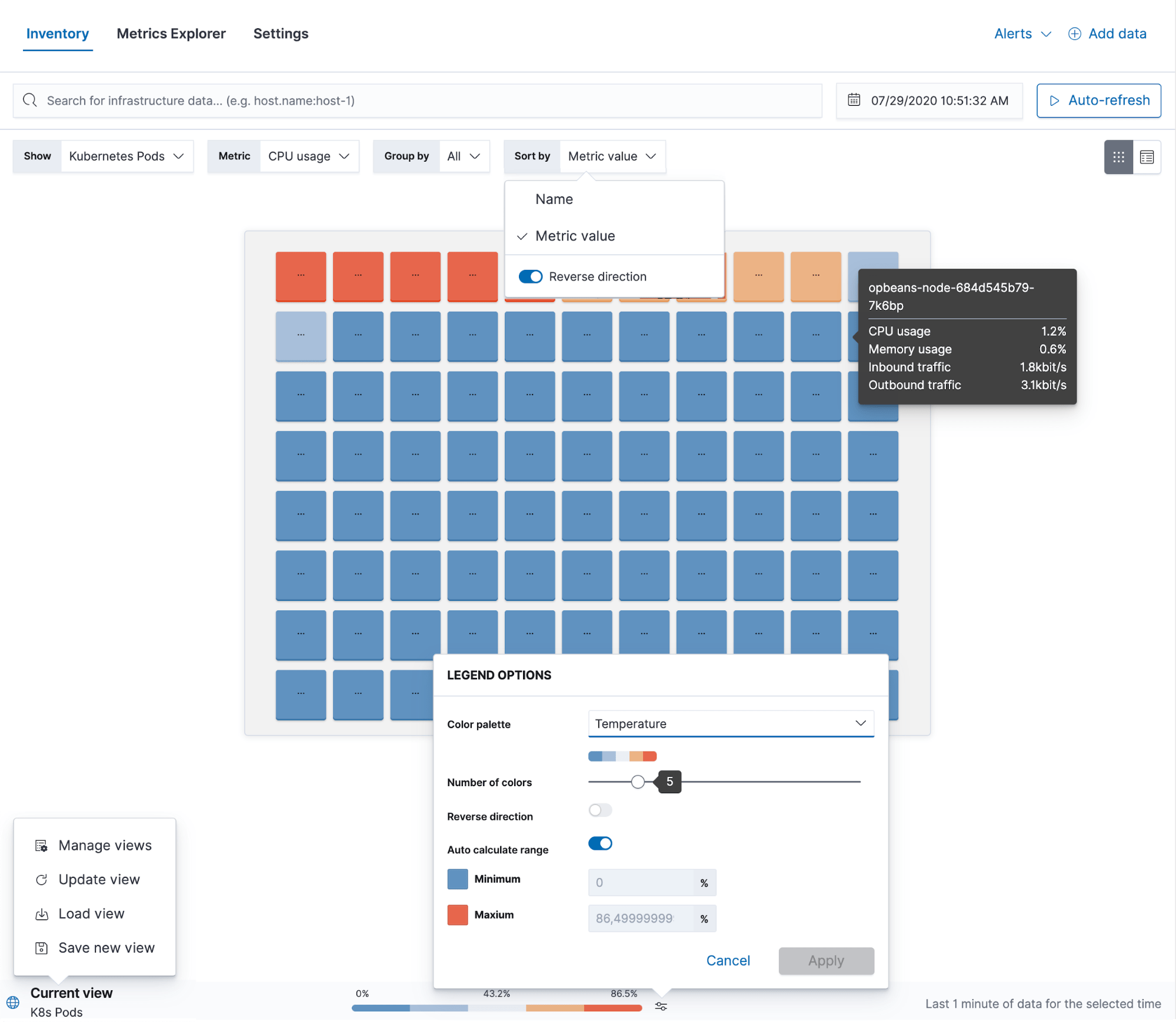
Metricsアプリは“Metrics Explorer”も搭載しています。異なるメトリックを重ね合わせて、相関関係があるかを判断できるMetrics Explorerは、トラブルシューティングに便利です。またMetricsアプリから、新規の可視化やアラートの閾値を作成することもできます。
Logsアプリでは基本的に、インフラ全体のtail -fを実行できます。Logsアプリはすべてのログストリームを統合し、1つのビューにリアルタイムのログと履歴ログの双方を表示します。バックグラウンドではログとメトリックが相関付けされており、そのため問題の調査に際して痕跡を辿る作業がより簡単になります。Logsアプリを使うと、すべてのログの詳細情報を表示できるほか、ログ行が生成された前後のタイミングで起きていたことを確認できます。Kibanaのほかのオブザーバビリティアプリもそうですが、Logsアプリは単なるread-onlyのビューではありません。アラートや機械学習機能を活用し、疑わしい挙動の分析と対応を実行できます。
アラート
アラートは、インフラストラクチャー全体にわたって問題の検知と対応を支援する機能であり、監視のあらゆるユースケースに欠かせない要素の1つです。Elasticが最近導入した新しいアラートフレームワークを使うと、異なるデータストリームに最適化させた複数の種類のアラートを設定できます。
- メトリックアラートは、物理環境かコンテナー化環境かを問わず、あらゆるタイプのデプロイ向けに簡単に設定できます。つまり、メトリックアラートは新規に作成されたリソースを自動的にカバーすることが可能です。また、フィルターを使って、アラートがカバーするインフラ内の領域を制御することもできます。さらに、一度設定したアラートを、指定のフィールドごとに自動で分けることも可能です。たとえば、すべてのホストについてアラートを発する、あるいはすべてのホストの全ディスクについてアラートを発する、といったことです。
- ログアラート機能はログデータ向けに最適化されており、ユーザーはフェーズにマッチするフィールドに基づいて、または特定のフィールドのロギング頻度に基づいてアラートを作成することができます。
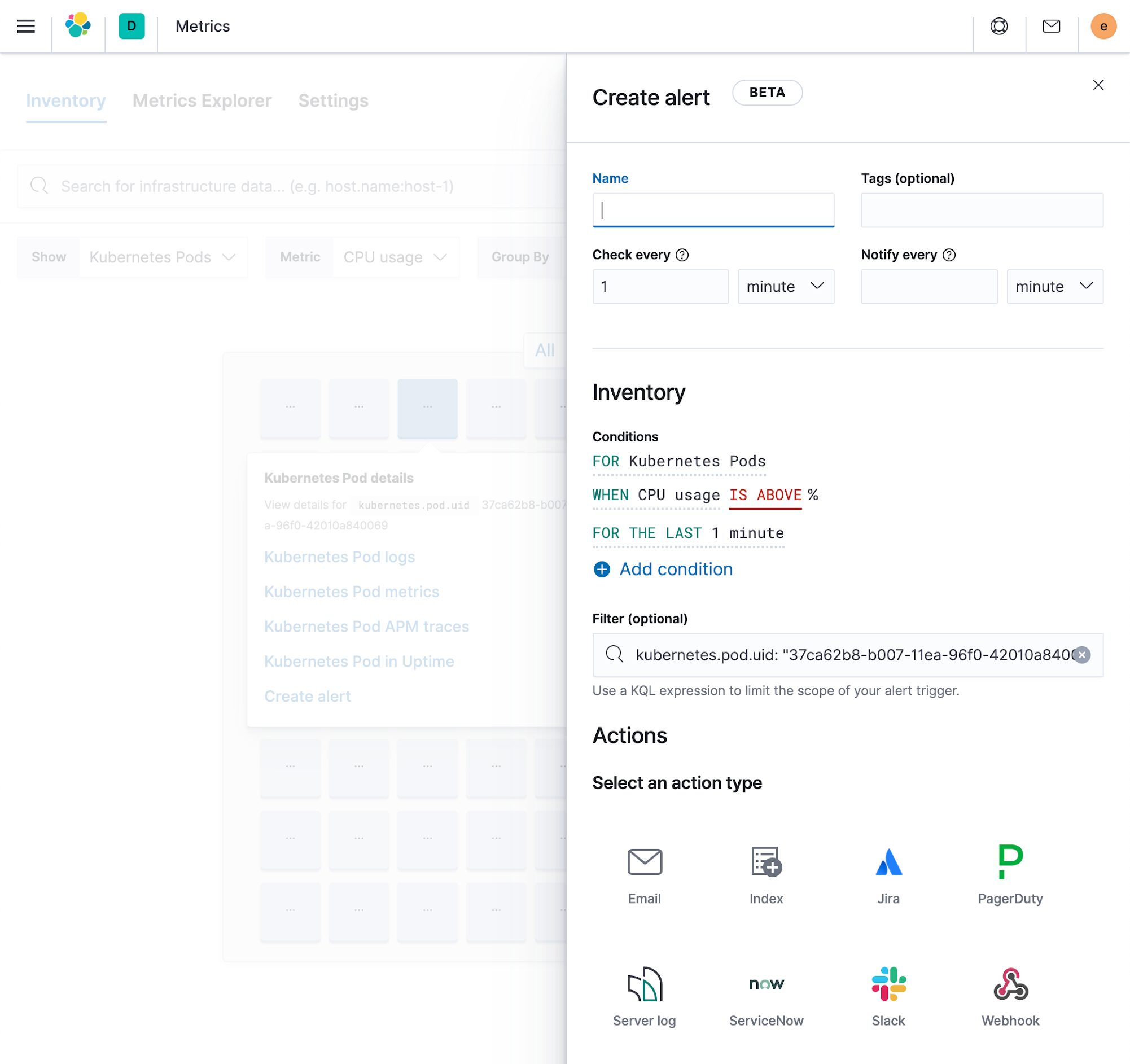
すべてのアラートは、Kibana内の一元的な画面から作成、管理できます。さらに、個々のアプリにもアラートの作成と管理メニューが埋め込まれており、日常的な作業を簡単に行うことができます。
機械学習と異常検知
今日のインフラストラクチャーは大量の運用データを生成し、そのデータは増え続けます。つまり、異なるデータストリームのデータを手動で分析することは実質的に不可能です。これは実際、問題の検知を自動化する方法を検討している組織にとって大きな悩みの種です。裏を返せば、現代の監視ソリューションで最重視すべきなのは、問題が生じる前にデプロイ環境内の異常な挙動を自動で検知する能力です。
嬉しいことに、Elasticのソリューションなら、Elasticsearchに運用データを入れるだけでデータ分析の準備が完了します。異常検知向けの事前構築済み機械学習ジョブはあらかじめログとメトリック向けに最適化されており、必要なKibanaのアプリとも深く統合されています。たとえば、インフラストラクチャーのログ生成レートに基づいて、またはパターンを発見し、ログをカテゴリーにグループ化することで、異常が生じた場合に自動で検知することができます。
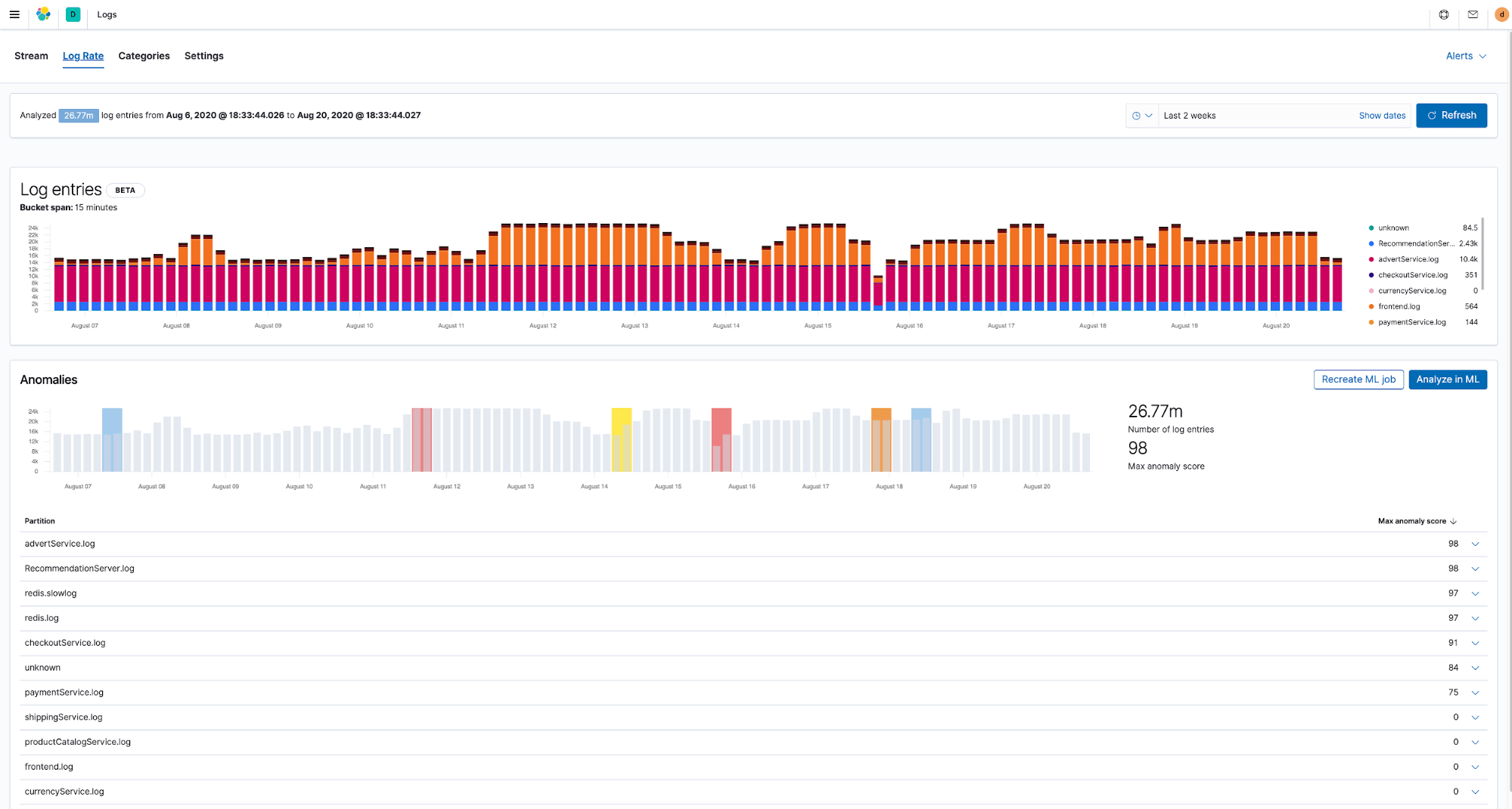
Elasticが提供する機械学習機能を使うと、異常検知以外にもさまざまなことを実行できます。分類や外れ値検知など他のアルゴリズムを使用でき、またインフラストラクチャーデータを含む幅広いユースケースにわたって活用できます。
Elastic Stackで増幅するバリュー
Elasticのテクノロジーは、どんなものも“単なる新しいインデックス”として扱います。したがって収集した監視データに対し、Elasticのあらゆる機能を使うことができます。さまざまな可視化機能を備えるKibanaを使えば、組織のあらゆる人に有意義なビューを構築できます。たとえばLensとTSVB(Time Series Visual Builder、時系列視覚ビルダーのこと。注釈可能なメトリックとヒストグラムの可視化を構築するパワフルなツール)を使ってエンジニアリングチームに役立つフレキシブルで内容の濃いダッシュボードを作成したり、Canvasを使った経営陣向けのライブインフォグラフィックを作成し、複雑なデータから傾向を明らかにすることもできます。
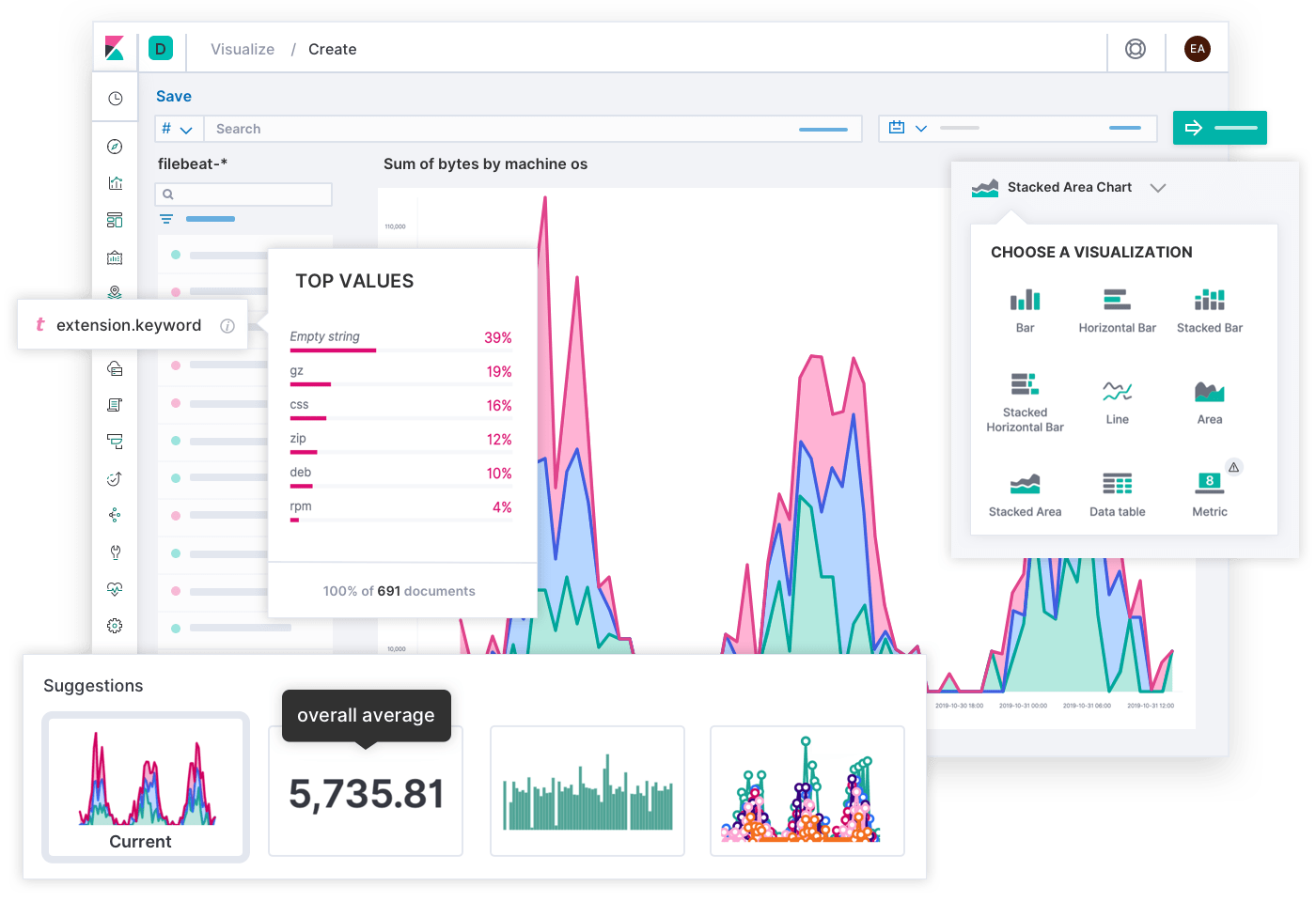
Elastic Stackに格納したデータに対して、UIからアクセスすることも、SQLやPromQLなどのおなじみのクエリ言語を使ってAPIからアクセスすることも可能です。PromQLは最近人気が出ている言語です。Elasticが提供するPrometheus統合機能を使うと、Elastic StackにPromQLクエリの結果を書き込むことができます。これは、生のメトリックを格納する予定がなく、処理済みのデータにしか興味がない場合に特に便利です。
また、インフラストラクチャー監視とセキュリティを組み合わせることも可能です。近年、オブザーバビリティとセキュリティの境界線はなくなりつつあります。本質的に、インフラストラクチャーの監視に使用するデータは、インフラストラクチャーの安全を保つ上でも重要な存在であるためです。Elasticオブザーバビリティと同様、ElasticセキュリティもElastic Stackをベースに開発されており、インフラストラクチャーのセキュリティ脅威検知と防御を手軽に実施できるソリューションです。
まとめ
このブログ記事では、最新の監視ソリューションに対するニーズを列挙し、またElasticのテクノロジーがどのようにそのニーズに応えているかを説明しました。ElasticオブザーバビリティソリューションとElastic Stackを使えば、究極の監視プラットフォームを構築できます。それはつまり、組織の複数のチームがあらゆる運用データを安全にインジェストし、問題なく操作できるプラットフォームです。
「そんなうまい話があるだろうか…?」とお感じの方は、実際に試していただくことをお勧めいたします。 Elastic Cloudの無料トライアルでクラスターを立ち上げることも、ElasticのWebサイトで最新のバージョンをダウンロードしてお使いいただくこともできます。ご質問やフィードバックがおありの場合は、ぜひフォーラムに投稿をお寄せください。