機械学習とは?
機械学習とは
機械学習(ML)とは、人工知能(AI)の一分野であり、データとアルゴリズムを利用して人間の学習方法を模倣し、時間の経過とともに徐々に正解率を向上させることに焦点を当てた技術です。コンピューター科学者でありAIの革新者であるアーサー・サミュエル氏によって、1950年代に初めて「明示的にプログラムされることなく学習する能力をコンピューターに与える学問分野」と定義されました。
機械学習では、大量のデータをコンピューターのアルゴリズムに投入することで、そのデータセット内のパターンや関係を特定することを学習させます。そして、アルゴリズムは、独自の予測や、分析に基づく決定を始めます。アルゴリズムが新しいデータを受け取ると、人が練習を重ねることで活動が上達するのと同じように、選択能力が洗練され、パフォーマンスが向上し続けます。
4つの機械学習の種類とは何か?
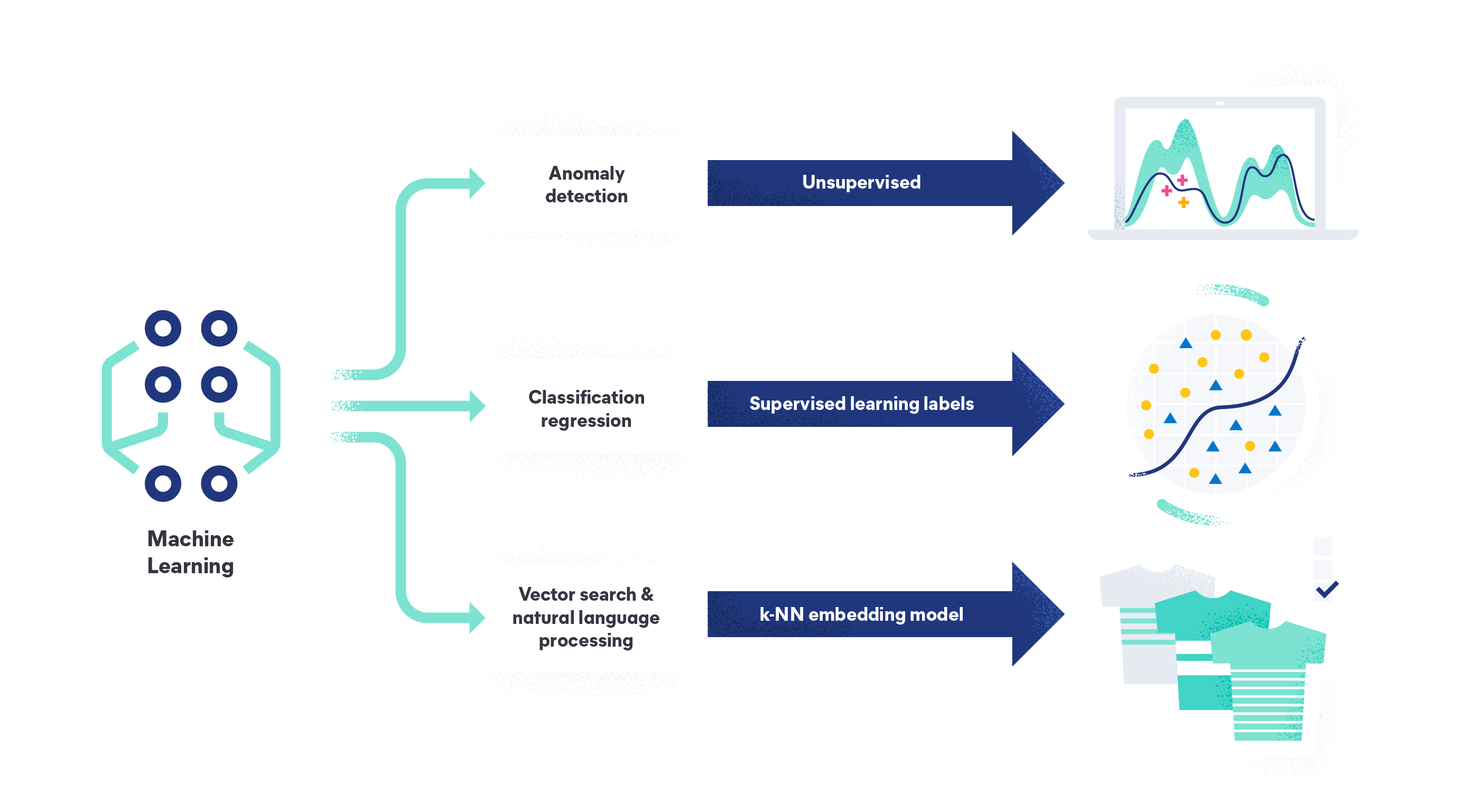
4つの機械学習の種類は、教師あり機械学習、教師なし機械学習、半教師あり学習、強化学習です。
教師あり機械学習は最も一般的な種類の機械学習です。教師あり学習モデルでは、アルゴリズムはラベル付きの学習データセットから学習し、時間とともに正解率を改善します。これは、以前に見たことのない新しいデータを受け取ったときに、目標変数を正しく予測できるモデルを構築するように設計されています。たとえば、人間がバラの花や他の花のイメージにラベルを貼って分類するようなものです。そして、アルゴリズムは、新しいラベルのないイメージを受け取ったときに、正しくバラと識別できるようになります。
教師なし機械学習では、アルゴリズムは、ラベル付けされていない、目標変数がないデータからパターンを検索します。ログ、トレース、メトリックの異常を検出してシステムの問題やセキュリティ脅威を特定するなど、人間がまだ特定できていない可能性のあるパターンや関係をデータから見つけ出すことが目的です。
半教師あり学習は、教師あり機械学習と教師なし機械学習のハイブリッドです。半教師あり学習では、アルゴリズムはラベル付けされたデータとラベル付けされていないデータの両方で学習します。まず、ラベル付けされた小さなデータセットから学習し、利用可能な情報に基づいて予測や決定を行います。そして、より大きなラベル付けされていないデータセットを使用して、データのパターンと関係を見つけることによって、予測や決定を改善します。
強化学習とは、アルゴリズムが試行錯誤を繰り返しながら、その行動に対する報酬や罰則という形でフィードバックを得て学習することです。たとえば、ビデオゲームをプレイするようにAIエージェントを学習させ、レベルが上がれば報酬を受け取り、失敗すれば罰則を受ける、サプライチェーンを最適化し、コストを最小化し、配送速度を最大化することで報酬を受け取る、あるいは、エージェントが商品やコンテンツを提案し、購入やクリックによって報酬を受け取る推薦システムなどがあります。
機械学習の仕組み
機械学習は複数の方法で動作できます。学習済み機械学習モデルを新しいデータに適用したり、新しいモデルを最初から学習させたりできます。
一般的に、学習済み機械学習モデルを新しいデータに適用した方が高速で、リソースの消費も少ないプロセスです。学習によりパラメーターを開発する代わりに、モデルのパラメーターを使用し、入力データに対する予測を行います(推論プロセス)。また、学習フェーズですでに評価されているため、パフォーマンスを評価する必要もありません。ただし、入力データを慎重に準備し、モデルの学習で使用したデータと同じ形式であることを保証する必要があります。
新しい機械学習モデルの学習には、次のステップがあります。
データ収集
まず、データセットを選択します。データは、システムログ、メトリック、トレースなどのさまざまなソースから取り込まれます。機械学習のトレーニングでは、ログやメトリックのほかに、次のような他の複数種の時系列データが重要です。
- 株価、利率、外国為替相場などの金融市場データ。多くの場合、このようなデータは、取引や投資目的の予測モデルを構築するために使用されます。
- 交通量、速度、移動時間などの交通時系列データ。このようなデータは、経路を最適化し、交通渋滞を軽減するために使用できます。
- Webサイトトラフィックやソーシャルメディアエンゲージメントなどの製品使用状況データ。これにより、企業は顧客の行動を把握し、改善領域を特定できます。
どのようなデータを使うとしても、解決しようとしている問題に関連し、予測や決定を行う母集団を代表するデータを使用してください。
データ処理
データを収集した後は、機械学習アルゴリズムによって使用可能にするための処理を行う必要があります。これには、データのラベル付け、データセットの各データポイントへの特定のカテゴリや値の割り当てなどがあります。これにより、機械学習モデルはパターンを学習し、予測ができるようになります。
さらに、欠損値を取り除いたり、集約を適用して時系列データをよりコンパクトな形式に変換したり、すべての特徴量が同じような範囲になるようにデータを調整したりすることも含まれます。大規模言語モデル(LLM)などのディープニュートラルネットワークでは、大量のラベル付き学習データがあることが要件です。従来の教師ありモデルでは、それほど処理の必要がありません。
特徴量選択
一部のアプローチでは、モデルで使用される特徴量を選択する必要があります。基本的には、解決しようとしている問題に最も関連している変数や属性を特定する必要があります。相関は特徴量を特定するための基本的な方法です。さらに最適化するために、自動特徴量選択方法が提供され、多くのMLフレームワークでサポートされています。
モデル選択
特徴量を選択した後は、解決しようとしている問題に最適な機械学習モデルを選択する必要があります。回帰モデル、決定木、ニュートラルネットワークなどのオプションがあります。(以下の機械学習の手法とアルゴリズムを参照してください
トレーニングコース
モデルを選択した後は、収集および処理したデータを使用してモデルを学習する必要があります。学習では、アルゴリズムがデータにあるパターンと関係を特定するように学習し、それらをモデルパラメーターにエンコードします。最適なパフォーマンスを実現するために、学習は繰り返し行われます。これには、モデルハイパーパラメーターの調整や、データ処理および特徴量選択の改善などがあります。
テスト
モデルが学習された後は、以前に見たことがない新しいデータでモデルをテストし、そのパフォーマンスを他のモデルと比較する必要があります。最もパフォーマンスが高いモデルを選択し、別のテストデータでパフォーマンスを評価します。過去に使用されたことのないデータのみが、モデルがデプロイされた後に、どのようなパフォーマンスを発揮するのかを正しく推定できます。
モデルのデプロイ
モデルのパフォーマンスに問題がない場合は、モデルを本番環境にデプロイし、リアルタイムで予測や意思決定を行うことができます。これには、モデルを他のシステムやソフトウェアアプリケーションと統合することも含まれます。一般的なクラウドコンピューティングプロバイダーと統合されたMLフレームワークは、クラウドへのモデルのデプロイが非常に簡単です。
監視と更新
モデルがデプロイされた後は、そのパフォーマンスを監視し、新しいデータが利用可能になったり、解決しようとしている問題が時間とともに進化したりするため、定期的に更新する必要があります。つまり、新しいデータでモデルを再学習したり、パラメーターを調整したり、まったく別のMLアルゴリズムを選択したりする可能性があります。
機械学習が重要である理由
機械学習が重要なのは、特別なアルゴリズムをプログラミングすることなく、例を使って複雑なタスクを実行するように学習するからです。従来のアルゴリズムによるアプローチと比較して、機械学習では、自動化の拡大、顧客エクスペリエンスの改善、以前は実現不可能だった革新的なアプリケーションの開発が可能です。また、機械学習モデルは、使用しながら、モデルを繰り返し改善できます。例:
- ビジネスの決定を改善するためのトレンドの予測
- 収益と顧客満足度を向上させる推奨のパーソナライズ
- 複雑なアプリケーションとITインフラストラクチャーの自動化と監視
- 迷惑メールの識別とセキュリティ違反の特定
機械学習の手法とアルゴリズム
多数の機械学習の手法とアルゴリズムがあります。選択する手法やアルゴリズムは、解決しようとしている問題やデータの特性によって異なります。次に、一部の一般的な手法やアルゴリズムの概要を示します。線形回帰は、目的が連続変数の予測であるときに使用されます。
線形回帰は、入力変数と目標変数の間に線形の関係があると想定します。たとえば、住宅価格を、面積、立地、寝室数、その他の特徴の線形結合として予測することです。
ロジスティック回帰は、目的がyes/noの結果である二項分類問題で使用されます。ロジスティック回帰は、入力変数の線形モデルに基づいて、目標変数の確率を推計します。たとえば、申込者のクレジットスコアやその他の金融データに基づいて、ローン申請が承認されるかどうかを予測することです。
決定木は、決定を可能な結果にマッピングするための木の形状のモデルに従います。各決定(ルール)は1つの入力変数のテストを表し、木の形状のモデルに従って複数のルールを連続して適用することができます。データをサブセットに分割し、木の各ノードで最も有意な特徴量を使用します。たとえば、決定木は、人口層や興味に基づいて、マーケティングキャンペーンの潜在顧客を特定するために使用できます。
ランダムフォレストは複数の決定木を組み合わせて、予測の正解率を改善します。各決定木は、学習データのランダムなサブセットと入力変数のサブセットで学習されます。ランダムフォレストは、個々の決定木よりも精度が高く、複雑なデータセットや欠損データを扱うのに適していますが、推論で使用するとかなり大きくなり、必要なメモリが多くなる可能性があります。
ブースティング決定木は、各決定木が前の決定木に基づいて改善されることで、一連の決定木を学習します。ブースティング手順は、決定木の前の反復によって誤分類されたデータポイントを取り、これらの以前に誤分類されたポイントの分類を改善するために、新しい決定木を再学習します。有名なXGBoost Pythonパッケージにはこのアルゴリズムが実装されています。
サポートベクターマシンは、あるクラスのデータポイントと別のクラスのデータポイントを最も適切に分離する超平面を探そうとします。そのために、クラスの間の「マージン」を最小化します。サポートベクターは、3つのポイントで定義される分離超平面の位置を識別する少数のオブザベーションを指します。標準SVMアルゴリズムは二項分類にのみ適用されます。多クラス分類の問題は、一連の二項分類の問題に分類されます。
ニュートラルネットワークは、人間の脳の構造と機能から発想を得ています。これは、相互に接続されたノードの層で構成され、ノード間の接続の強さを調整することで、データのパターンを認識するように学習できます。
クラスタリングアルゴリズムは、データポイントをその類似性に基づいてクラスターにグループ化するために使用されます。顧客セグメンテーションや異常検知などのタスクに使用できます。特に画像のセグメンテーションや処理に役立ちます。
機械学習の利点とは何か?
機械学習には多数の利点があります。次のカテゴリでパフォーマンスを一段階高めるための能力を得ることができます。
- 自動化:反復性や客観的な難しさなど、人間にとって困難な認知タスクを、機械学習によって自動化できます。たとえば、複雑なネットワークシステムの監視、複雑なシステムにおける不審な活動の特定、機器のメンテナンス時期の予測などです。
- 顧客エクスペリエンス:機械学習モデルから得られるインテリジェンスは、ユーザーエクスペリエンスを引き上げることができます。検索に基づく用途では、意図や好みを把握することで、より関連性の高いパーソナライズされた結果を提供できます。ユーザーは、自分が意味する内容を検索して、見つけることができます。
- イノベーション ―機械学習は、目的に合わせて構築されたアルゴリズムでは不可能であった複雑な問題を解決します。たとえば、画像や音声を含む非構造化データの検索、交通パターンの最適化と公共交通システムの改善、健康状態の診断などです。
機械学習のユースケース
以下は、機械学習のサブカテゴリとそのユースケースです。
センチメント分析とは、自然言語処理を用いてテキストデータを分析し、その全体的なセンチメントが肯定的、否定的、中立的のいずれであるかを判断するプロセスです。さまざまなデータソース(Twitterのツイート、Facebookのコメント、製品レビューなど)を分析し、顧客の意見や満足度を測ることができるため、顧客フィードバックを求めている企業にとって有用です。
異常検知とは、アルゴリズムを用いて、問題を示す可能性のあるデータの異常なパターンや異常値を特定するプロセスです。異常検知は、ITインフラストラクチャー、オンラインアプリケーション、ネットワークを監視し、潜在的なセキュリティ侵害のシグナルとなる活動や、後にネットワーク停止につながる可能性のある活動を特定するために使用されます。異常検知は不正な銀行取引を検出する目的でも使用されます。AIOpsの詳細をご覧ください。
画像認識は、画像を分析し、画像内の物体、顔、その他の特徴を識別します。Google画像検索のような一般的なツール以外にも、さまざまな用途があります。たとえば、農作物の健康状態を監視し、害虫や病気を特定するために農業で使用できます。自動運転車、医療用画像処理、監視システム、拡張現実ゲームなどはすべて画像認識を利用しています。
予測分析は、過去のデータを分析し、将来の事象や傾向を予測するために使用できるパターンを特定します。これは、企業が業務を最適化し、需要を予測し、潜在的なリスクや機会を特定するのに役立ちます。たとえば、製品の需要予測、交通渋滞の遅延、製造装置の安全な稼働時間などです。
機械学習の欠点とは何か?
機械学習には次のような欠点があります。
- 高品質の学習データへの依存:データに偏りがあったり、不完全であったりすると、モデルも偏ったり、不正確になったりする可能性があります。
- コスト:モデルの学習やデータの前処理には高いコストがかかることがあります。とはいえ、同じタスクを達成するために特化したアルゴリズムをプログラミングするコストに比べればまだ低く、おそらく、それほど正確ではないでしょう。
- 説明能力の欠如:ディープニューラルネットワークのような機械学習モデルのほとんどは、その動作に透明性がありません。一般に「ブラックボックス」モデルと呼ばれるこのモデルでは、モデルがどのように意思決定に至るかを理解することが困難です。
- 専門知識:さまざまなタイプのモデルから選択できます。専任のデータサイエンスチームがなければ、最適なパフォーマンスを達成するためのハイパーパラメーターのチューニングに苦労する可能性があります。特に、変換器、埋め込み、大規模な言語モデルの場合、学習の複雑さも採用の障壁となる可能性があります。
機械学習のベストプラクティス
機械学習のベストプラクティスの一部は次のとおりです。
- データがクリーンで、整理され、完全であることを確認します。
- 現在の問題とデータに適合した正しいアプローチを選択します。
- 過学習を防止する手法を使用します。過学習では、モデルは学習データでは適切に機能しますが、新しいデータでは適切に機能しません。
- 完全に新しいデータでテストすることで、モデルのパフォーマンスを評価します。モデルを開発し、最適化する際に測定したパフォーマンスで、本番でのパフォーマンスを予測できるとはかぎりません。
- モデルの設定を調整し、最高のパフォーマンスを見つけます(ハイパーパラメーター調整)。
- 標準的なモデルの正解率に加えて、実際の用途とビジネス問題のコンテキストでモデルのパフォーマンスを評価するメトリックを選択します。
- 他の人が作業を理解し、再現できることを保証するために、詳細な記録を残します。
- モデルを常に最新の状態に保ち、新しいデータに対しても優れたパフォーマンスを発揮できるようにします。
Elasticの機械学習の基本
Elastic機械学習は、スケーラブルなElasticsearchプラットフォームの利点を継承しています。デプロイと運用までに必要な学習が少ないモデルを使用するオブザーバビリティ、セキュリティ、検索ソリューションへの統合により、すぐに価値を実現できます。Elasticでは、信頼できる方法で、大規模に、新しいインサイトを収集し、革新的なエクスペリエンスを社内ユーザーや顧客に提供することができます。
次の方法をご覧ください。
何百ものソースからデータをインジェストし、組み込みの統合を使用して、データが存在する場所で機械学習と自然言語処理を適用します。
自分に最適な方法で機械学習を適用します。ユースケースに応じて、自動監視や脅威ハンティングのための構成済みモデル、センチメント分析や質問応答インタラクションのようなNLPタスクを実装するための学習済みモデルと変換器、ワンクリックでセマンティック検索を実装するためのElastic Learned Sparse Encoder™などの構成済みのモデルからすぐに価値を実現できます。あるいは、最適化されたカスタムモデルが必要な場合は、データを使って教師ありモデルを学習します。Elasticでは、ユースケースに適し、専門レベルに合ったアプローチを柔軟に適用することができます。
機械学習の用語集
- 人工知能とは、学習、推論、問題解決、意思決定など、通常は人間の知能を必要とするタスクを実行する機械の能力のことです。
- ニューラルネットワークは、機械学習アルゴリズムの一種であり、情報を処理し、伝達するノードの相互接続された層で構成されています。人間の脳の構造と機能から発想を得ています。
- ディープラーニングは、ニューラルネットワークの下位分野であり、多数の層があるため、他の機械学習アルゴリズムよりも大幅に複雑な関係を学習できます。
- 自然言語処理(NLP)は、機械が人間の言語を理解、解釈、生成できるようにすることに焦点を当てたAIの下位分野です。
- ベクトル検索は、ベクトル埋め込みとk最近傍探索を使用して、大規模なデータセットから関連情報を取得する検索アルゴリズムの一種です。