Introducing Machine Learning for the Elastic Stack
Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
Today we’re proud to announce the first release of machine learning features for the Elastic Stack, available via X-Pack. Joining Elastic has been like jumping on a rocket ship, but after 7 crazy months we are excited that the Prelert machine learning technology is now fully integrated into the Elastic Stack, and we are really excited about getting feedback from users.
Note: Before you get too excited, keep in mind that this functionality is marked beta in version 5.4.0.
Machine Learning
Our goal is to empower users with tools to get value and insights from their Elasticsearch data, and we view machine learning as a natural extension to the search and analytics capabilities in Elasticsearch. For example, Elasticsearch allows you to search for transactions for user ‘steve’ in real time across huge volumes of data, or use aggregations and visualisations to show the top ten selling products or trends in transactions over time. Now, with machine learning you can go deeper and ask questions like “Have any of my services changed behaviour?” or “Are there any unusual processes running on my hosts?” These questions require behavioural models of hosts or services that can be automatically built from data using machine learning techniques.
However, machine learning is currently one of the most overloaded terms in the software industry, as fundamentally it is used to describe a broad range of algorithms and methods for data driven prediction, decision making, and modelling. It’s therefore important to cut through the noise and describe specifically what we are doing.
Time Series Anomaly Detection
Today, the machine learning features of X-Pack are focused on providing “Time Series Anomaly Detection” capabilities using unsupervised machine learning.
Over time we plan to add more machine learning capabilities, but for now we are focused on providing added value to users storing time series data such as log files, application and performance metrics, network flows, or financial/transaction data in Elasticsearch.
Example 1 - Automatically Alert on Unusual Changes in a Key Performance Indicator Value
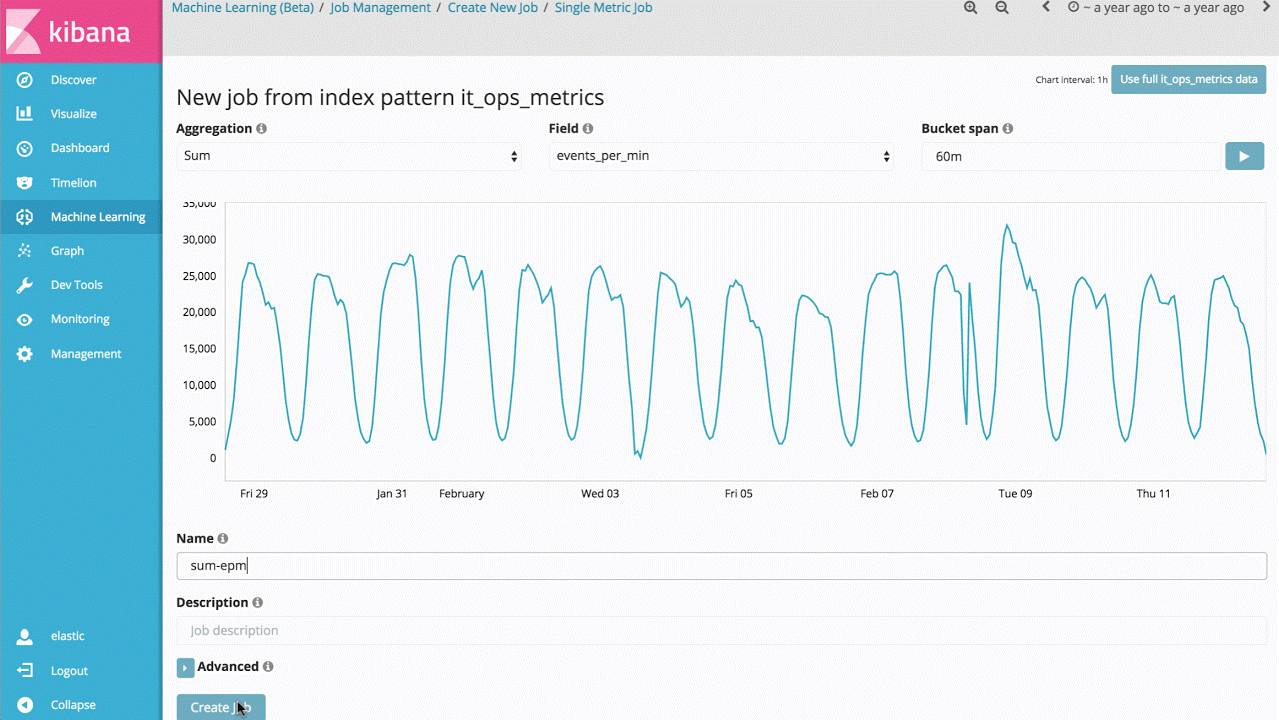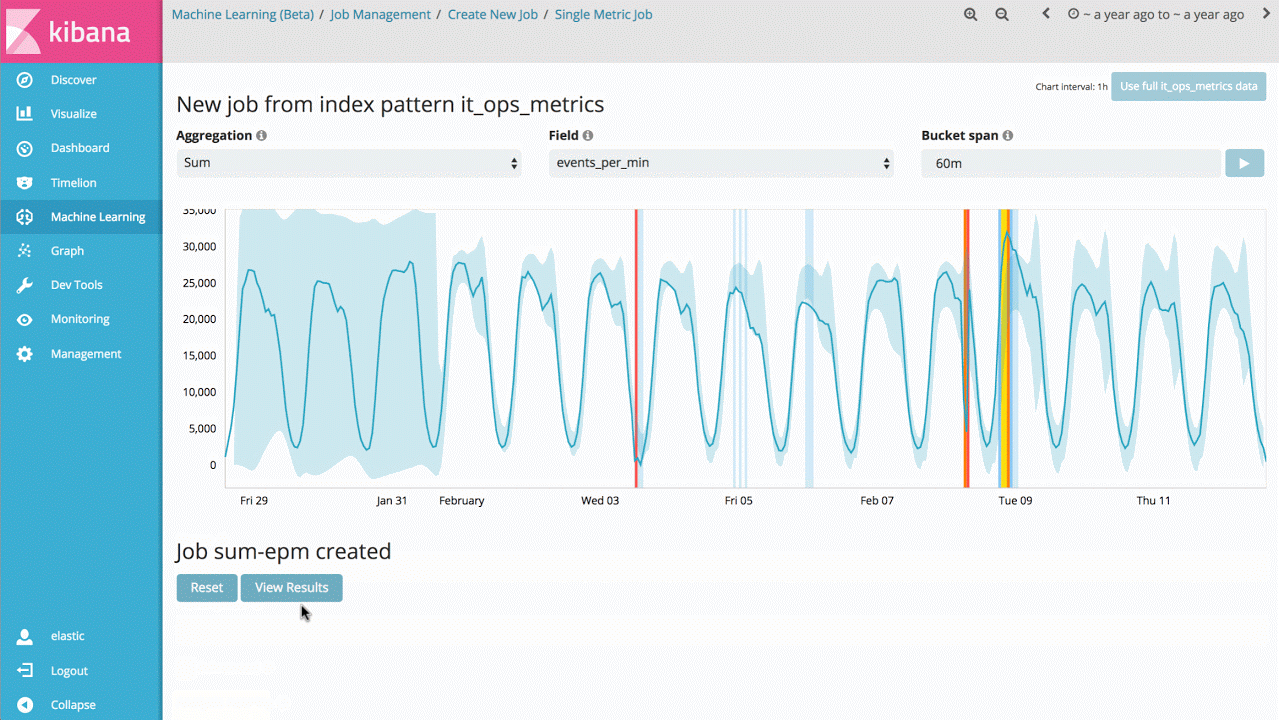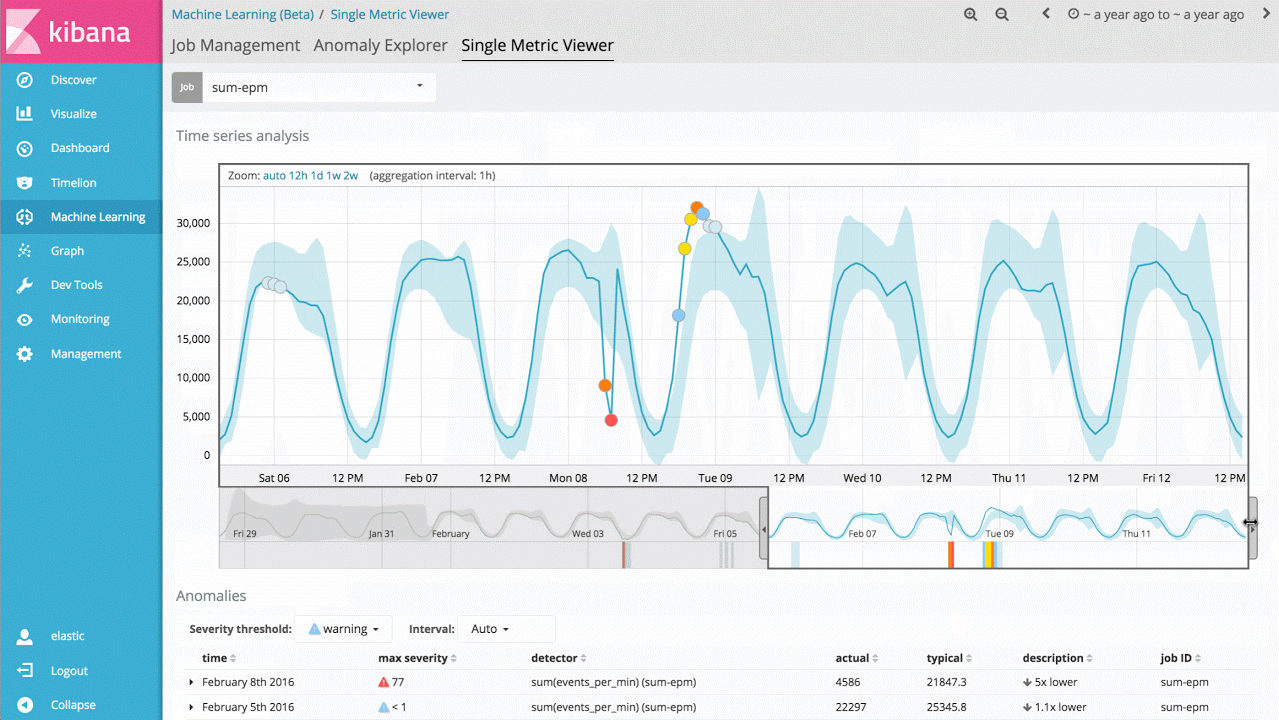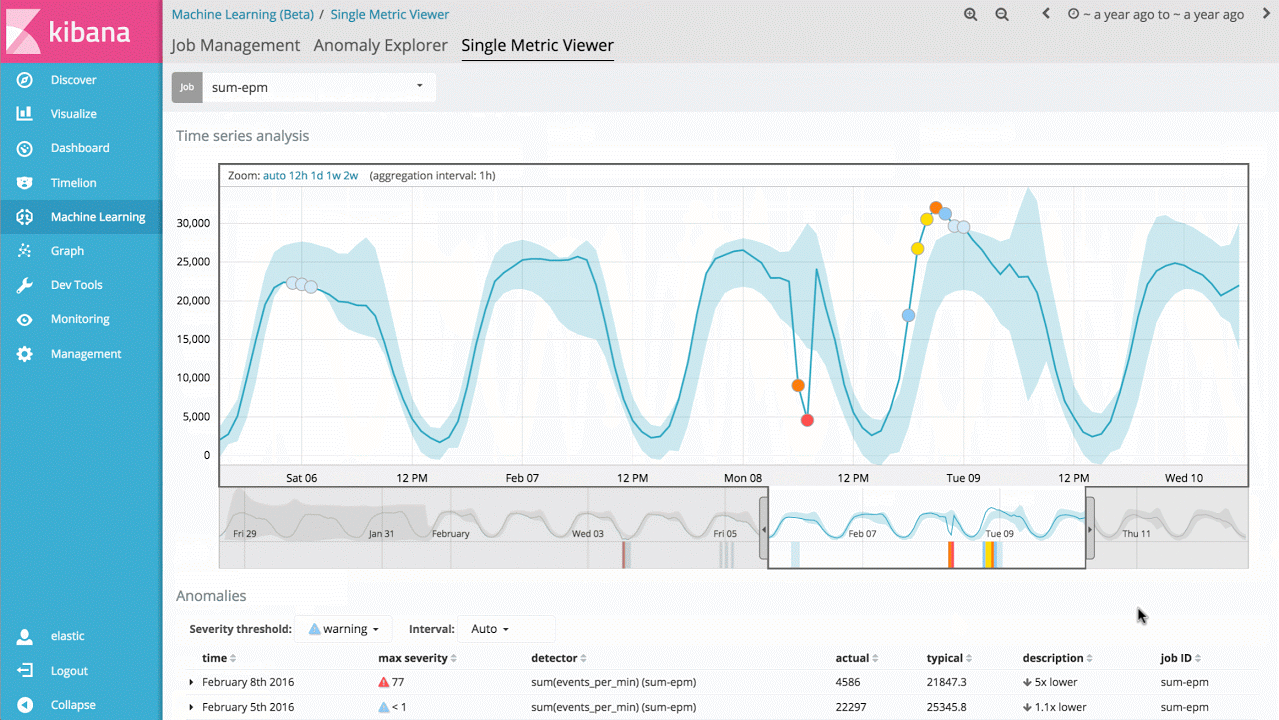
The most straightforward use case of this technology is to identify when a metric value or event rate deviates from its normal behaviour. For example, has the response time of my service increased significantly, or are the expected number of website visitors significantly different from normal at this time of day? Traditionally, rules, thresholds or simple statistical methods are used for this type of analysis. Unfortunately, these simple methods are rarely effective on real-world data, as they often rely on invalid statistical assumptions (e.g. Gaussian distributions), don’t allow for trends (long term or periodic) or are brittle to changes in signal.
Therefore, the first entry point into the machine learning features is a Single Metric job that allows you to investigate how the product learns what's normal and identifies anomalies on univariate time series data. If the anomalies you find are useful, you can run this analysis continually in real time and alert when an anomaly occurs.
Whilst this seems like a relatively simple use case, the backend of the product contains a large of amount of complex unsupervised machine learning algorithms and statistical modelling so we are robust and accurate to arbitrary signals.
The implementation is also optimised to run natively in an Elasticsearch cluster, so millions of events can be analysed in seconds.
Example 2 -Automatically track 1000s of metrics
The machine learning product can scale to 100,000s of metrics and log files, and so the next step is to analyse multiple metrics together. These could be multiple related metrics on a host, performance metrics from a database or application, or multiple log files from multiple hosts. In this case we can simply partition the analysis and aggregate the results into one pane of glass showing overall system anomalousness.
For example, if I have response times from a large set of application services, I can simply analyse the response times for each service over time, and identify individual services behaving abnormally, as well as provide a view of overall system anomalousness:
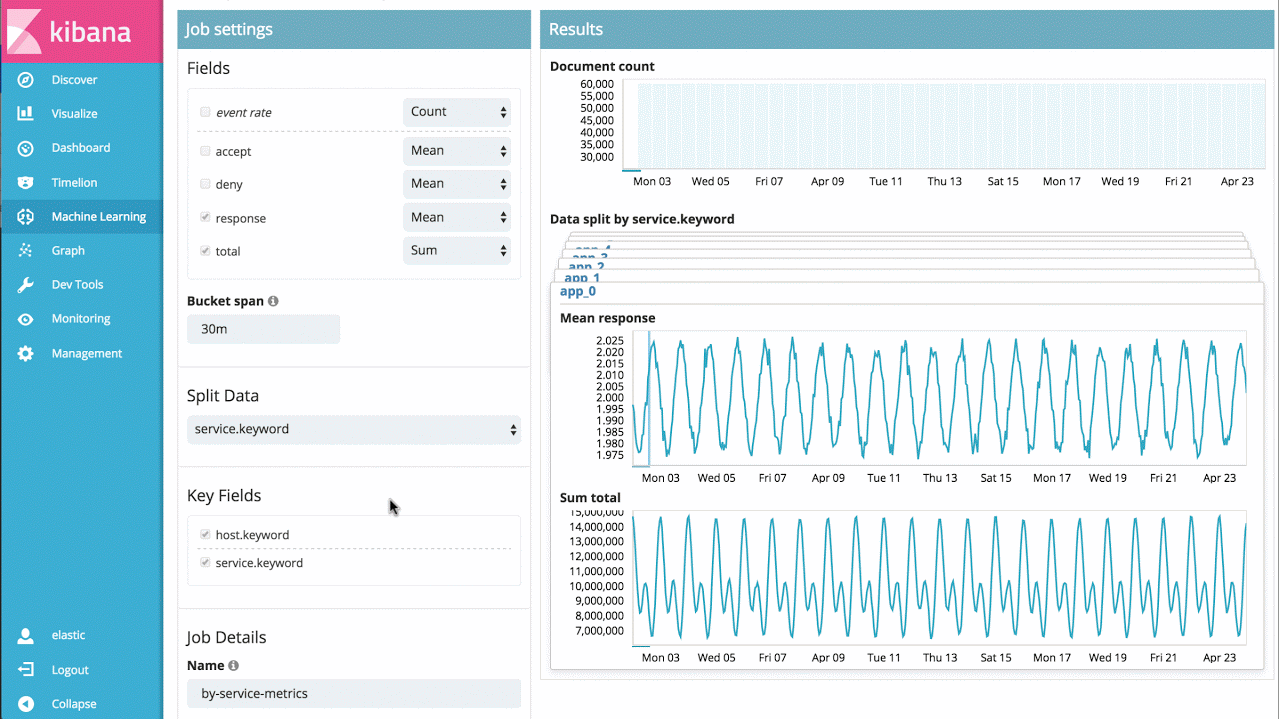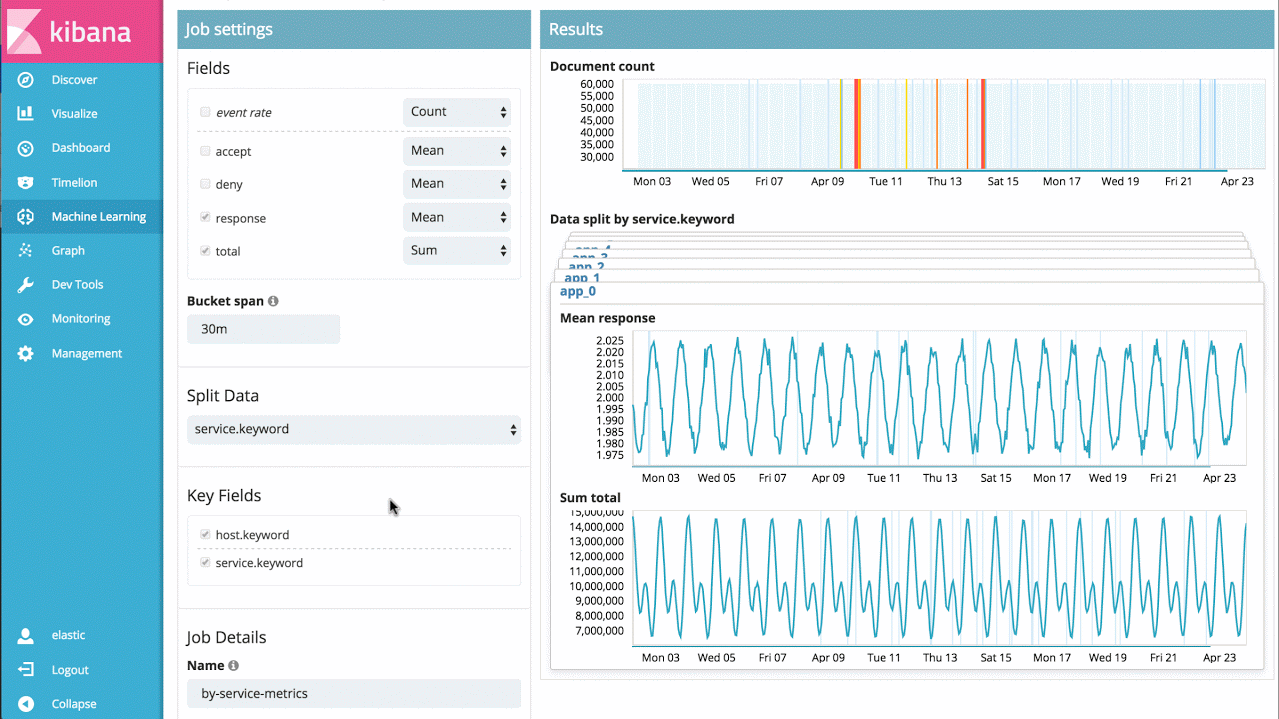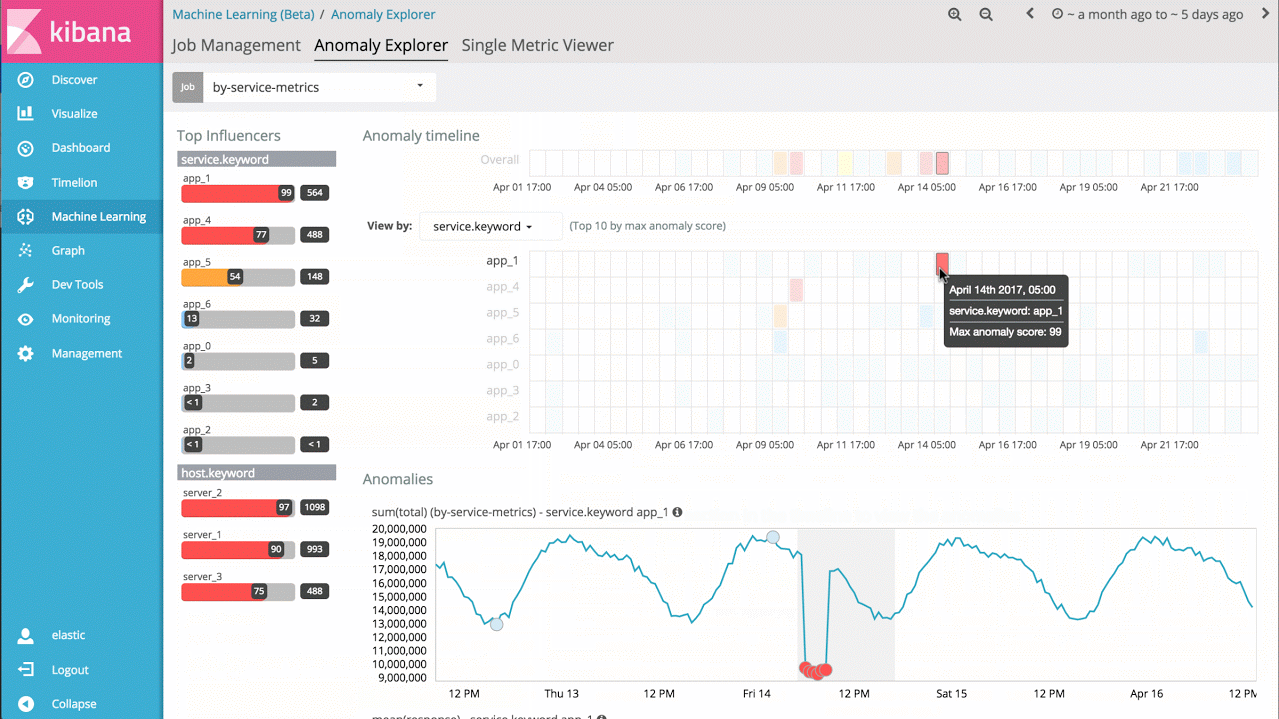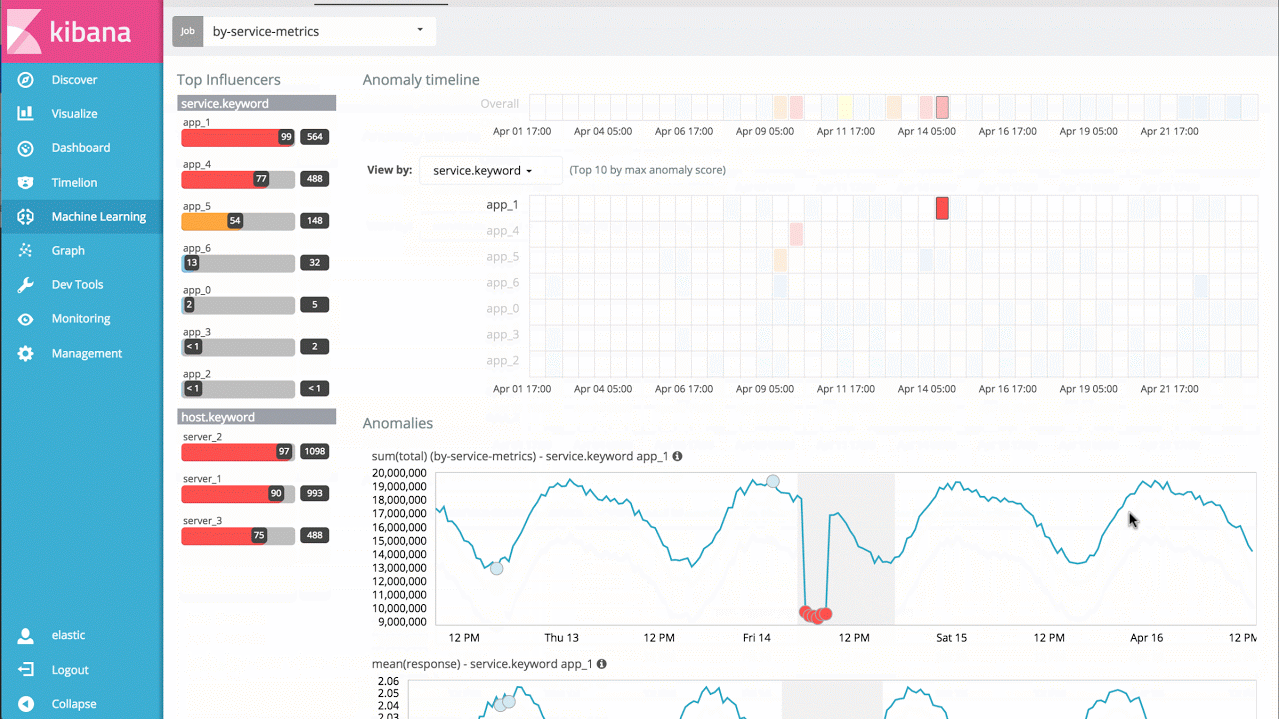
Example 3 - Advanced Jobs
Finally, there are a large number of more advanced ways to use the product. For example, if you want to find users behaving unusually compared to a population, unusual DNS traffic or congestion on London roads, advanced jobs provide a flexible way to analyse any time series data stored in Elasticsearch.
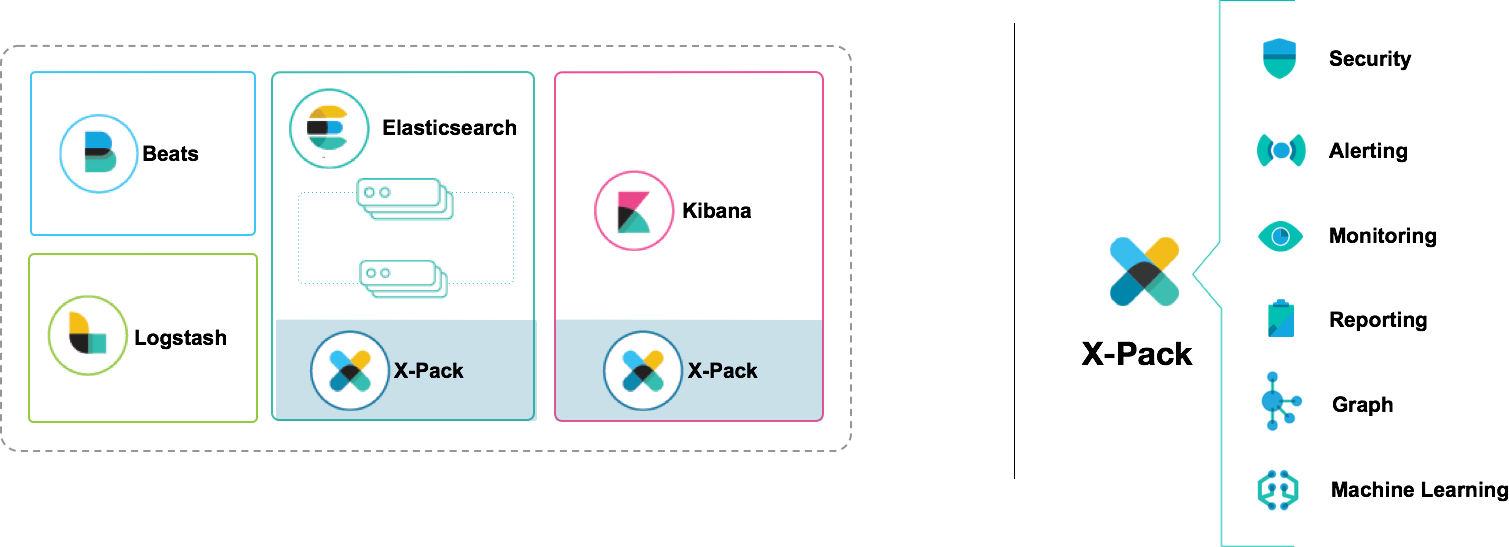
Elastic Stack Integration
Machine learning is available as a feature of X-Pack. This means that when X-Pack is installed, machine learning features can be used to analyse time series data in Elasticsearch in real time. Machine learning jobs are automatically distributed and managed across the Elasticsearch cluster in much the same way that indexes and shards are. This also means that machine learning jobs are resilient to node failure. From a performance perspective, the tight integration means that data never needs to leave the cluster and we can rely on Elasticsearch aggregations to dramatically improve performance for some job types. Yet another benefit of the tight coupling is that you can create anomaly detection jobs and view results right from Kibana.
Since the data is analyzed in-situ and never leaves the cluster, this approach provides a significant performance and operational advantage over integrating Elasticsearch data with external data science tools. As we develop more technologies in this space, the advantages of this architecture will become even more pronounced.
Try it today and let us know what you think
These machine learning features are in beta in X-Pack 5.4, which is available now. We’re eager to hear about your experience, so please download the 5.4 release, install X-Pack, and reach out to us directly, or via our Discuss forum.