Smarter Machine Learning Job Placement in Elasticsearch
Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
Ever since we introduced machine learning into the Elastic Stack, ML jobs have been automatically distributed and managed across the Elasticsearch cluster.
To recap, you specify which nodes you’re happy for ML jobs to run on by configuring the node.ml and xpack.ml.enabled settings to true on these nodes. Then, when you open a job the cluster runs the job’s associated analytics process on one of those nodes, and the job will continue to run there until it’s closed or the node is stopped. Prior to version 6.1 this node allocation was done in a very simple way: a newly opened job was always allocated to the node running the fewest jobs subject to a couple of ML settings:
xpack.ml.max_open_jobs- A static per-node limit on the number of open/opening ML jobs on the node (default: 10 prior to 6.1)xpack.ml.node_concurrent_job_allocations- A dynamic cluster-wide limit on the number of opening ML jobs on each node (default: 2)
Different ML job configurations and data characteristics can require different resources. For example, a single metric job generally uses very little resource, whilst a multi-metric job analysing 10,000 metrics will require more memory and CPU. But no account was taken of the expected or actual resource usage of each job when allocating jobs to nodes, which could lead to:
- Node resources being exceeded
- Artificially low limits being imposed to prevent nodes running out of resources
- Failure to open jobs when ample resources are available (due to having many small jobs)
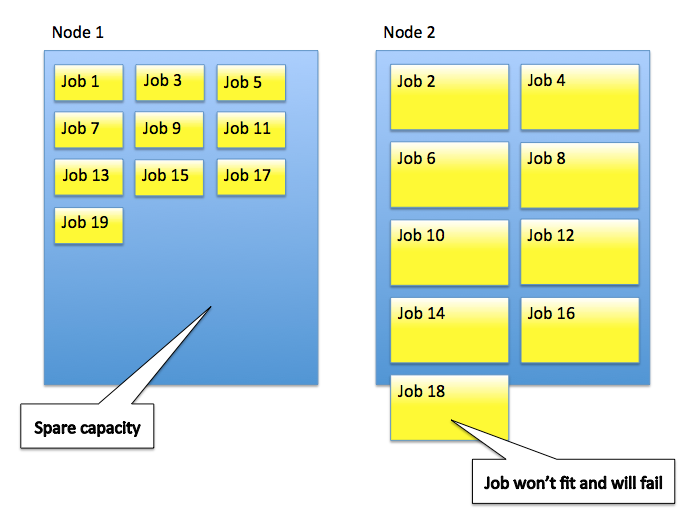
To mitigate these problems, starting in version 6.1 ML will allocate jobs based on estimated resource usage.
Each ML job runs in a separate process, outside of the Elasticsearch JVM. In 6.1 we have added a new setting, xpack.ml.max_machine_memory_percent, to control the percentage of memory on a machine running Elasticsearch that may be used by these processes associated with ML jobs. This is a dynamic cluster setting, so the same number will apply to all nodes in the cluster, and it can be changed without restarting nodes. By default the native processes associated with ML jobs are allowed to use 30% of memory on the machine.
ML will never allocate a job to a node where it would cause any of these constraints to be violated:
- Percentage of machine memory used
- Limit on number of open jobs
- Limit on number of concurrently opening jobs
For nodes where none of the hard constraints would be violated, we will continue to allocate jobs to the least loaded ML nodes. However, instead of number of jobs being the definition of load it is now estimated job memory. Job memory is estimated in one of two ways:
- The
model_bytesreported in the most recentmodel_size_statsplus 100MB for process overhead - The
model_memory_limitin the job’sanalysis_limitsplus 100MB for process overhead
The first method is preferred, but cannot be used very early in the lifecycle of a job. The estimate of job memory use is based on actual model size when the following conditions are met:
- A least one
model_size_statsdocument exists for the job - The job has produced results for at least 20 buckets
- Either there are no new
model_size_statsdocuments for the most recent 20 buckets for which results exist (implying very stable model memory usage), or else the model memory coefficient of variation (standard deviation divided by mean) over the most recent 20 buckets is less than 0.1
Once jobs are “established” according to these criteria, we should be able to make pretty good decisions about whether opening a new job is viable. However, if many jobs are created and opened around the same time then we will tend to be restricted by the model_memory_limit configured in the analysis_limits. Before version 6.1 our default maximum model_memory_limit was 4GB, and this was excessive in many cases. Therefore, in version 6.1 we have cut the default model_memory_limit to 1GB.
If you are creating advanced jobs that you expect to have high memory requirements we’d encourage you to explicitly set this limit to a higher value when creating the job. And there should be less scope to hog resources if you accidentally create a job that would use a lot of memory if it were allowed to run unconstrained.
Similarly, if you’re creating jobs that you expect to have very low memory requirements, we’d encourage you to set model_memory_limit in the analysis_limits to a much lower value than the default. We’ve done this in the job creation wizards in Kibana: single metric jobs created using the wizard now have their model_memory_limit set to 10MB, and multi-metric job created by the UI wizard have it set to 10MB plus 32KB per distinct value of the split field.
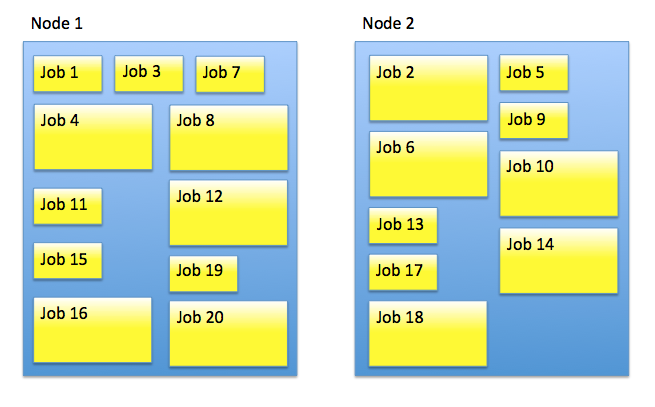
Because of the smarter limiting of ML jobs based on memory requirements, in version 6.1 we’ve increased the default value for xpack.ml.max_open_jobs from 10 to 20. Of course, if you have large jobs or little RAM then the memory limit will kick in and you won’t be able to open 20 jobs per node. But if you have many small jobs then you’ll no longer be artificially restricted. If you’ve previously customized the value of xpack.ml.max_open_jobs then you may wish to revisit your setting taking account of the new functionality.
During rolling upgrades to version 6.1 ML jobs might be running in mixed version clusters where some nodes are running version 6.1 and others pre-6.1. In such clusters some nodes will know enough to apply the new allocation logic and some won’t. Additionally, it is theoretically possible for the node stats API to fail to determine the amount of RAM a machine has. Rather than try to do anything clever in these scenarios, the following simple rule will apply: if any ML node in the cluster is unable to participate properly in the memory-based node allocation process then the pre-6.1 count based allocation will be applied to all ML node allocation decisions. For people running clusters on supported operating systems where all nodes have been upgraded to version 6.1 this should not be a problem.