以极低的成本实现 AI 级可观测性
Elastic Observability 不仅能收集数据,还能了解系统、发现重要信息并采取行动。比其他方案更快更便宜。
获得《财富》500 强半数企业的信赖,助力创新前行
我们的可观测性了解您的系统
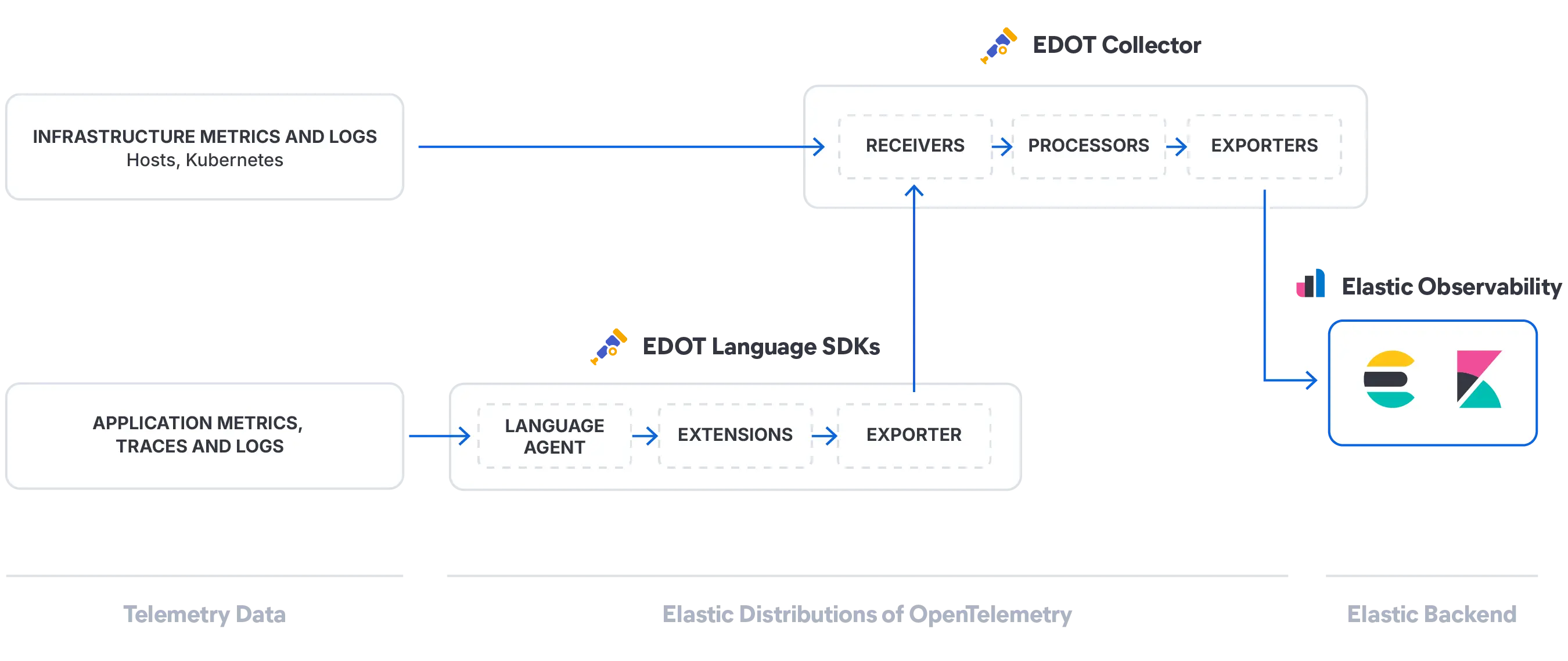
Elastic 将您的日志、指标和跟踪信息转换为 AI 可以实时推理的动态系统模型。可通过您选择的任何 AI 接口按需提供。
一个平台,满足一切需求
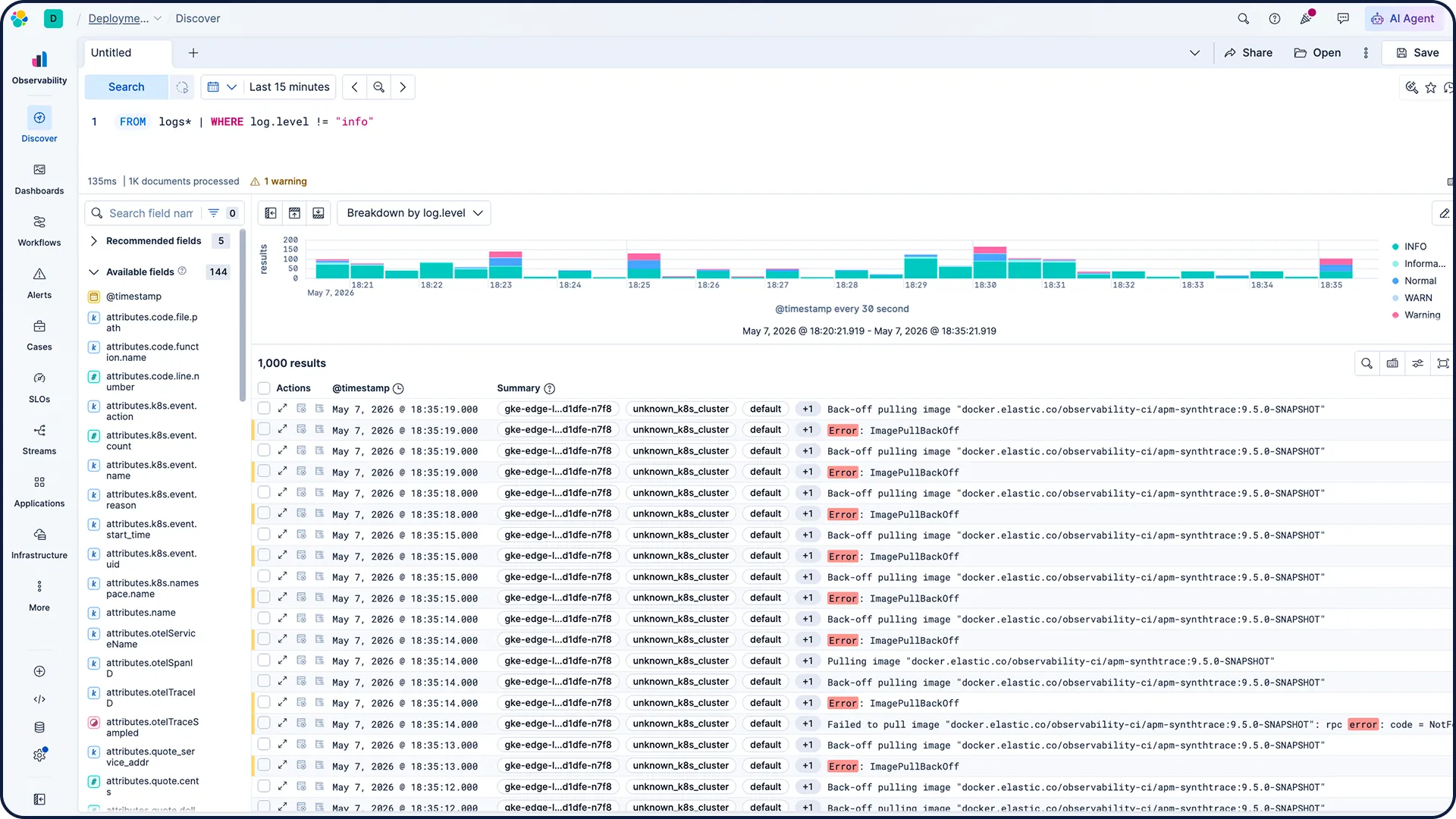
以日志为调查核心,所有信号来自单一可信来源。
提供 450+ 一键集成,覆盖云平台、CI/CD、数据库以及更多系统。
指标成果背后的创新
同类最佳效率
AI 的优势取决于为其支持的数据平台。从存储架构到查询性能,Elasticsearch 的每个部分都是有目的地构建的。
专为日志数据构建的索引模式。按 host.name 和 @timestamp 进行智能排序,将相似记录相邻放置,从而显著提升压缩率。Synthetic _source 可按需重建字段。阅读深度剖析 →
长期日志保留 最高可达 50%
智能索引排序 最高可达30%
自 2026 年 1 月以来,四项针对性的查询引擎优化在 9.x 版本中叠加,延迟降低了 40%。
预计于今年晚些时候发布的 doc-values-only 模式将完全跳过倒排索引和 BKD 树,改用压缩的二进制 doc-values,以实现近列式存储的密度。
您准备好切换了吗?
从 Datadog 迁移,节省 50% 的指标费用。
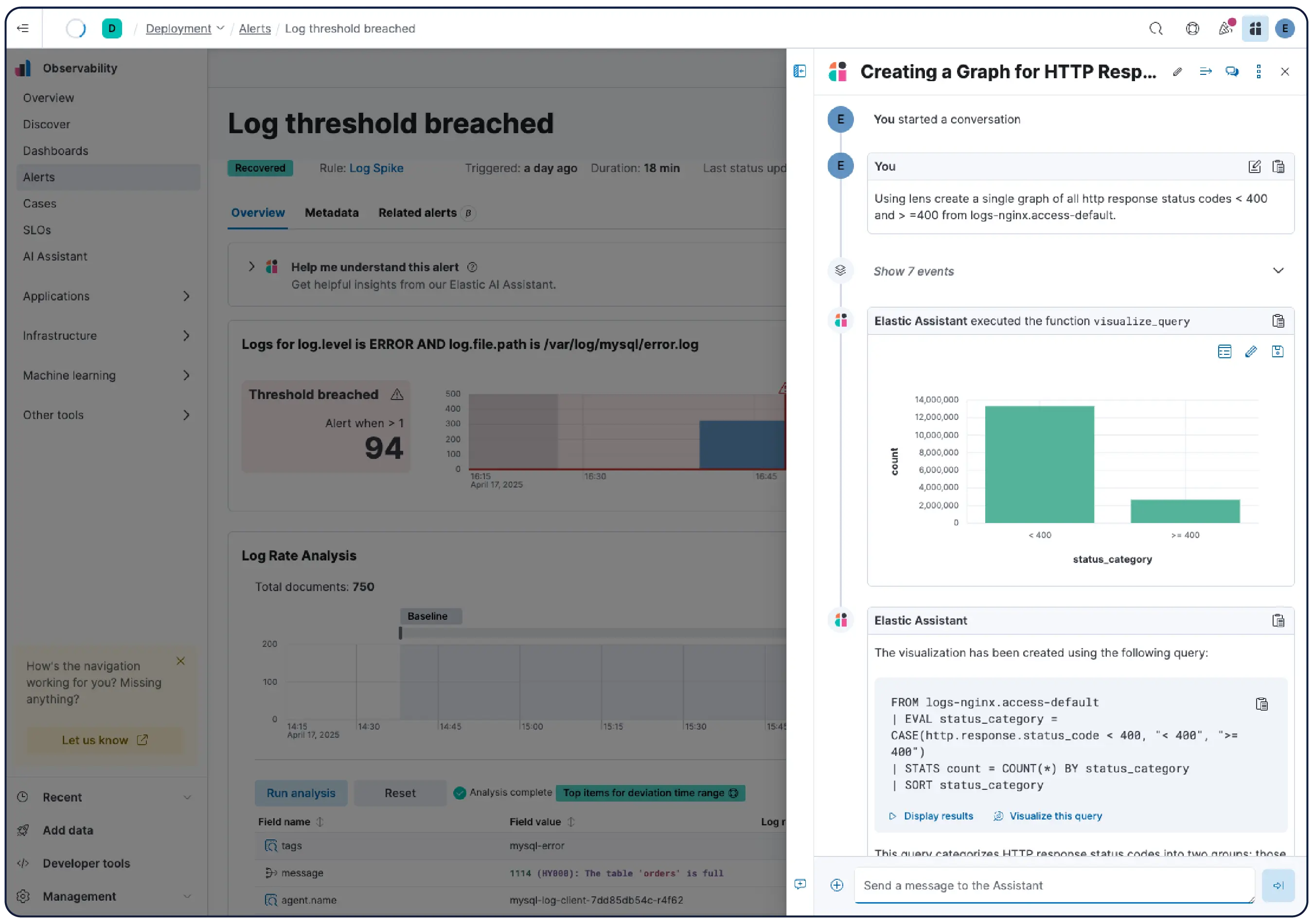
您的AI所需的调查背景
Elastic 自动从您的遥测数据中提取知识指标 (KI),包括实体、依赖关系、实时状态和上下文,从而构建整个系统的持续更新模型。无需配置或标记。
了解详情 →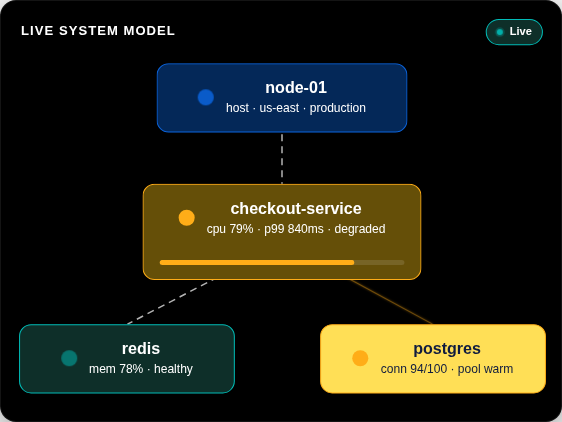
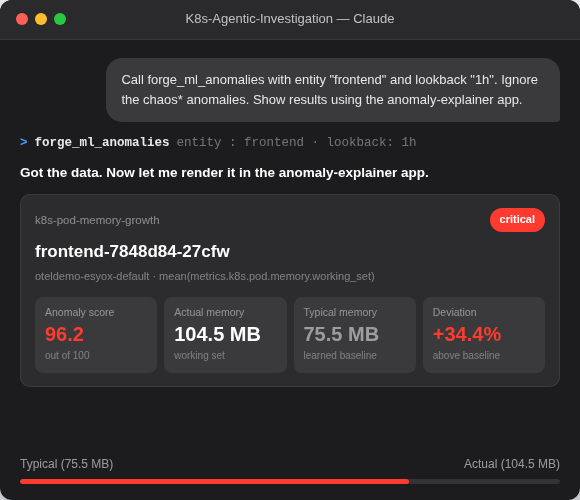
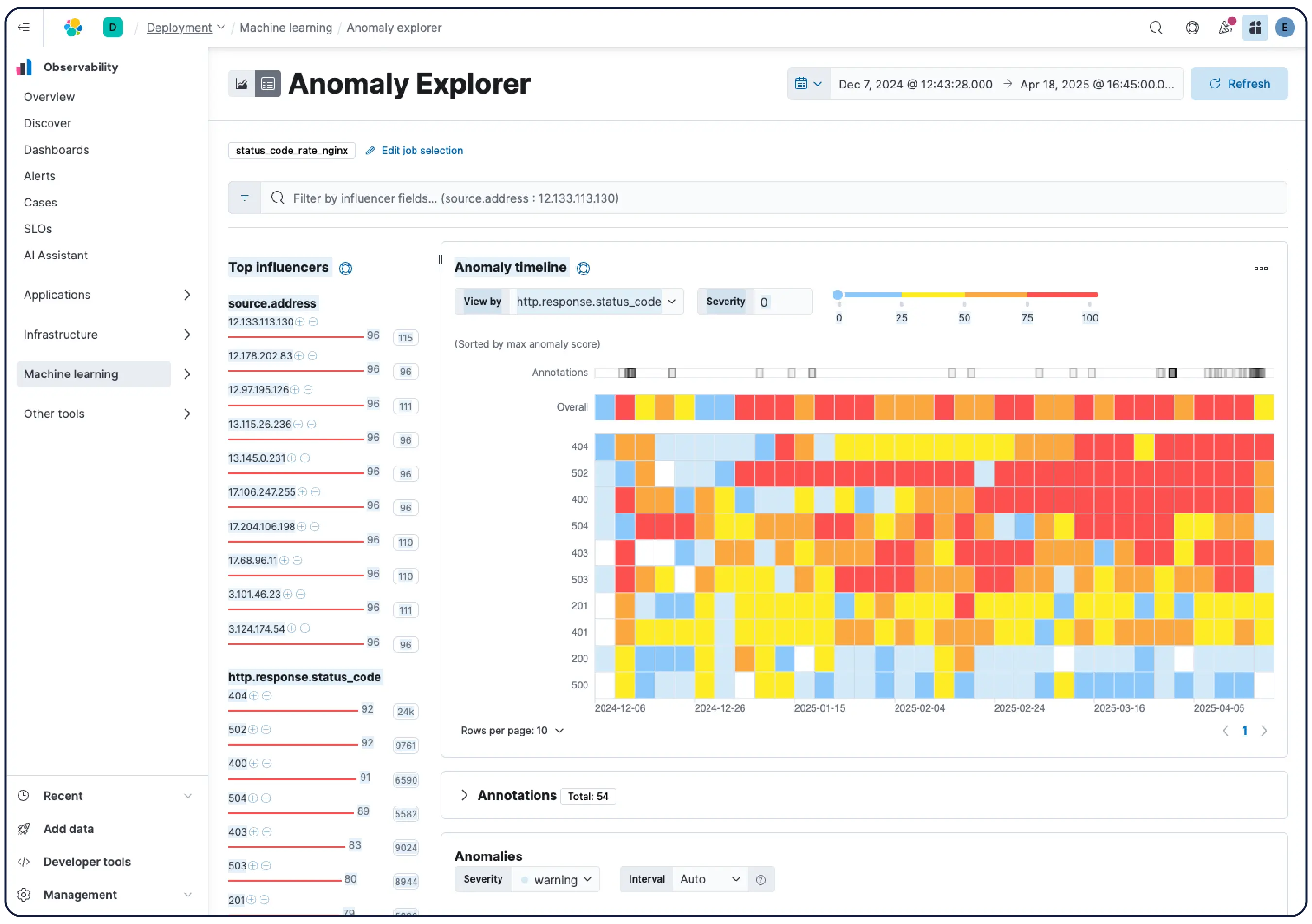
全场景原生观测
完全相同的智能底座——包含核心指标、重大事件与流程自愈补丁——皆可自适应渲染在任意工作视窗上。Kibana 适用于您的 SRE 团队。Claude 适用于您的值班工程师。CLI 适用于您的自动化管道。
获取 MCP 服务器 →-
 原生 MansCheP 服务器
原生 MansCheP 服务器
-
技能自动加载
-
表面感知渲染
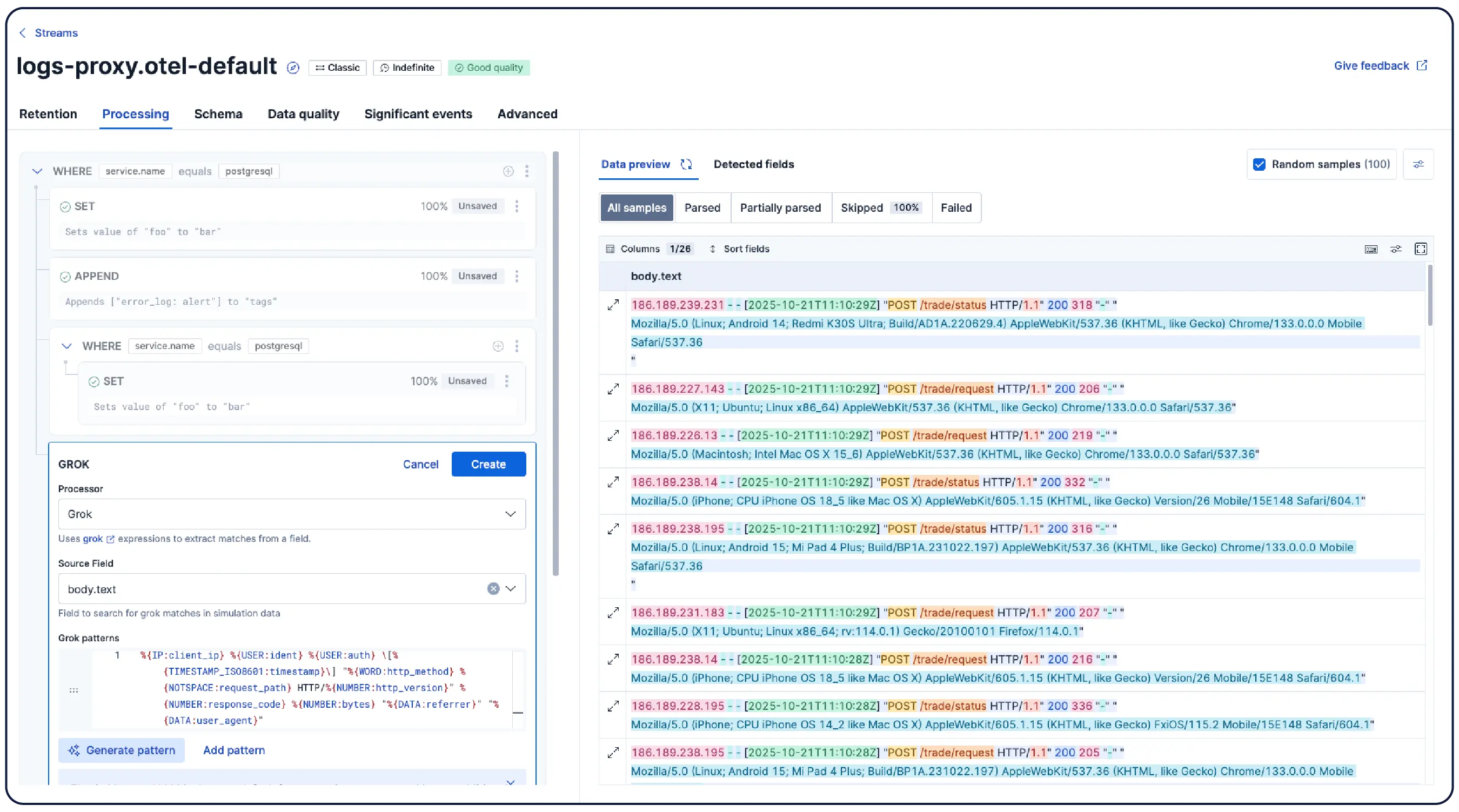
从数据到答案。无需挖掘。
从日志探索到智能体调查,围绕值班 SRE 的实际思考和工作方式构建。
加入聊天
加入 Elastic 的全球社区,参与公开对话和协作。
常见问题
全栈可观测性是指可观测性解决方案能够监测整个应用程序堆栈(从最终用户到应用程序代码和基础架构)的能力。全栈可观测性解决方案通常包含多种功能,包括日志监测和分析、云和基础设施监测、应用程序性能监测、数字体验监测、持续性能分析和 AIOps。欢迎进行我们的自我评估,了解您在实现统一全栈可观测性平台的成熟度方面的进展情况,以便您能够全面分析遥测数据,并缩短平均故障解决时间。
AI 驱动的可观测性可帮助组织实现卓越的业务和运营。通过实现由智能体 AI 驱动的全栈可观测性,SRE 团队可以主动通过上下文根本原因分析、交叉信号关联以及跨孤立团队的有效协作,更快地检测和解决问题。企业可以履行服务水平协议 (SLA),并缩短产品上市时间、提高运营效率和客户满意度。了解有关 AI 驱动的可观测性的优势的更多信息。
各地企业都面临着一个充满挑战的环境:成本压力增加,同时还承受着复杂的分布式云原生环境产生的大量数据。在这样的情况下,团队需要能够随时随地对其所有数据进行更智能的分析、访问和保留,从而解决问题,做出决策并确保弹性。许多已采用 Splunk Enterprise 的公司需要做出选择,因为 Splunk 提供的 Splunk Enterprise、Splunk Cloud 和 Splunk Observability 具有不同的定价模式,很难提供一体化的可观测性。相比之下,Elastic 提供的解决方案快速而简单,让公司能够为未来做好准备。
最常见原因:成本。随着基础设施规模的扩大,Datadog 按主机和指标计费的成本迅速上升,许多团队不得不在保留哪些数据和舍弃哪些数据之间做出痛苦的权衡。Elastic 的模式让团队能够更好地控制存储的内容、存储时间以及付费方式,通常可节省高达 4 倍的成本。
可观测性可以看作是对现代应用程序监测的演变。从根本上说,它是应用程序和基础架构通过可操作的日志、发布的指标和分布式跟踪来显示其内部状态的能力。作为一种方法,与传统形式的监测相比,可观测性收集、转换、关联、分析和可视化这些信号,更适合管理云原生环境的复杂性和规模。可观测性会随着新趋势和新技术的出现不断发展。
引领可观测的未来
了解 Elastic 为何在 2025 年度《Gartner® 可观测性平台魔力象限™》中获评“领导者”。