Wie funktioniert eine Ursachenanalyse bei der Softwareentwicklung?
Definition: Ursachenanalyse
Ursachenanalysen (Root Cause Analysis, RCA) sind eine bewährte Fehlerbehebungsmethode, mit der Softwareentwicklungsteams Probleme identifizieren und deren Ursachen auf den Grund gehen können, anstatt nur Symptome zu behandeln. Die Ursachenanalyse ist ein strukturierter, schrittweise ausgeführter Prozess mit dem Ziel, zugrunde liegende Ursachen zu ermitteln, indem relevante Daten erfasst und analysiert und Lösungen zur Behebung der Ursachen getestet werden.
Warum ist die Ursachenanalyse so wichtig?
Die Ursachenanalyse ist wichtig für die Softwareentwicklung, weil Teams mit diesem systematischen Ansatz Probleme effizienter beheben und langfristige Lösungen entwickeln können, um zu verhindern, dass Probleme erneut auftreten. Durch die Behebung von Ursachen für Fehler und Defekte können Entwickler sicherstellen, dass ihre Systeme stabil, zuverlässig und effizient funktionieren, um kostspielige Ausfälle zu vermeiden und den Entwicklungsprozess zu beschleunigen. Mit der Ursachenanalyse können Entwickler außerdem Probleme anhand ihrer Auswirkungen priorisieren und die wichtigsten Probleme zuerst angehen.
Durchführen einer Ursachenanalyse
Die Ursachenanalyse wird branchen- und fachrichtungsübergreifend – von Wissenschaft und Technik bis hin zu Fertigung und Gesundheitswesen – als Methode zur Problemlösung eingesetzt, bei der Faktoren, die zu Mängeln oder Defekten in einem System führen, mit einer bestimmten Abfolge von Schritten isoliert und genau analysiert werden. Die genauen Schritte einer Ursachenanalyse im Bereich der Softwareentwicklung folgen denselben grundsätzlichen Prinzipien:
- Schritt 1: Problem definieren und Warnungen einrichten (falls möglich)
Der erste Schritt einer Ursachenanalyse besteht darin, das Problem zu definieren und möglichst genau zu verstehen. Dazu können Sie beispielsweise Warnungen für potenzielle Probleme wie ungewöhnliche Verhaltensweisen von Anwendungen, Systemleistungsbeeinträchtigungen oder Sicherheitsvorfälle einrichten. - Schritt 2: Sammeln und Analysieren der Daten, um potenzielle Ursachen zu ermitteln
Nachdem das Problem definiert wurde, besteht der nächste Schritt darin, Daten zu sammeln und zu analysieren. Dabei überprüfen Sie beispielsweise System-Logs, Leistungsmetriken von Anwendungen, Nutzer-Feedback und andere relevante Datenquellen. Aus der Datenauswertung ergibt sich eine Liste potenzieller Ursachen, die zu dem definierten Problem beitragen könnten. - Schritt 3: Ursachen ermitteln
Nach Abschluss der Datenanalyse in Schritt 2 können Sie eine der Methoden für Ursachenanalysen anwenden, um die Daten und die ermittelten Ursachen zu analysieren und tatsächliche Ursachen für das Problem zu ermitteln. Aus der Ursachenanalyse sollten Empfehlungen für Korrekturmaßnahmen abgeleitet werden. - Schritt 4: Lösungen implementieren und Aktionen dokumentieren
Nachdem die Ursache identifiziert wurde, besteht der letzte Schritt darin, Lösungen zur Behebung des Problems zu implementieren. Dazu gehören Maßnahmen wie Änderungen am Code oder an Konfigurationseinstellungen sowie verschiedene Systemanpassungen. Dabei ist es wichtig, alle zur Behebung des Problems ergriffenen Maßnahmen zu dokumentieren, um sicherzustellen, dass sie wirksam sind und bei Bedarf wiederholt werden können.
Methoden und Techniken für Ursachenanalysen in anderen Fachbereichen als der Softwareentwicklung
Es gibt zahlreiche Tools, die Sie bei einer effektiven Ursachenanalyse unterstützen. Beim Brainstorming und der Analyse potenzieller Ursachen können Sie Ihre Informationen mit diesen Methoden visualisieren und in einem hilfreichen Framework für die Problembehandlung organisieren. Bei Ursachenanalysen werden unter anderem diese Techniken eingesetzt:
- 5 Gründe warum
„5 Gründe warum“ ist eine Problemlösungsstrategie für die Suche nach Ursachen, bei der Sie iterativ immer wieder nach dem „Warum“ fragen, bis Sie die direkten Ursachen eines Problems identifiziert haben. Wenn Teams mehrmals „Warum“ fragen und sich von einer Frage zur nächsten leiten lassen, fördert dies das kritische Denkvermögen, liefert tiefgründige Antworten und vermeidet oberflächliche Lösungen. - Pareto-Diagramm
Ein Pareto-Diagramm ist eine Kombination aus Balken- und Liniendiagramm und bildet die Häufigkeit der gängigsten Problemursachen ab, beginnend mit der wahrscheinlichsten Ursache. Das Pareto-Prinzip besagt, dass 80 % der Auswirkungen durch 20 % der Ursachen entstehen. Darum listet das Diagramm die Ursachen in der Reihenfolge der Bedeutung und zeigt die jeweiligen kumulativen Auswirkungen, damit sich die Teams auf die Ursachen mit den stärksten Auswirkungen auf das Problem konzentrieren können. - Punktdiagramm
Ein Punktdiagramm verwendet Punkte, um Teams dabei zu unterstützen, Muster in Daten zu erkennen, die möglicherweise zu einem Problem beitragen. Durch die Abbildung zweier numerischer Variablen in einem Diagramm lassen sich Korrelationen zwischen den Variablen leichter erkennen. Mit dieser Technik können Sie mühelos signifikante Beziehungen zwischen Variablen sowie Ausreißer identifizieren, bei denen es sich um die gesuchten Ursachen handeln könnte. - Fischgrätdiagramm
Dieses Diagramm ähnelt einem Fischskelett und bildet die Faktoren ab, die möglicherweise zu einem Problem beitragen. Der Kopf stellt dabei das Problem dar, und die Gräten die Kategorien potenzieller Ursachen. Diese Darstellung ist besonders förderlich für die Zusammenarbeit zwischen Teams und hilft, das Problem umfassender zu verstehen. - Fehler-Möglichkeits- und Einflussanalyse (FMEA)
FMEA ist eine strukturierte, empirische Herangehensweise, um potenzielle Probleme und deren Auswirkungen zu identifizieren. Bei dieser Methode werden potenzielle Fehlermodi systematisch identifiziert, ihr Schweregrad bewertet und die Wahrscheinlichkeit von Auftreten und Erkennung ermittelt, um ihnen anschließend eine Risikobewertung zuzuweisen. Diese Methode hilft den Teams, sich zuerst auf die wichtigsten Probleme zu konzentrieren und Probleme zu vermeiden, bevor sie auftreten.
Ursachenanalyse-Tools für Softwareentwickler
Im Softwarebereich können Ursachenanalysen Probleme aufdecken, die tief im Code verborgen liegen. Durch die zunehmende Nutzung von cloudnativen Technologien und die Komplexität moderner Anwendungen wird es jedoch immer schwieriger, Problemursachen zu ermitteln. Teams können Observability- und Sicherheitstools einsetzen, um hervorragende Ursachenanalysen durchzuführen, wie etwa:
Observability
Observability liefert Echtzeiteinblicke in die Leistung und das Verhalten von Softwareprogrammen durch Datenerfassung und -Analyse. Sie können Probleme identifizieren und Einblicke in Ursachen erhalten, indem Sie Metriken, Logs und Traces mit AIOps- und Observability-Tools überwachen, wie zum Beispiel:
- Machine Learning und AIOps
Nutzen Sie Suche, Visualisierung und Machine Learning, um Anomalien zu identifizieren und Problemursachen zutage zu fördern. Auf diese Weise können Sie fundierte Entscheidungen treffen und schnell Korrekturmaßnahmen ergreifen. - Verteiltes Tracing
Mit Nachverfolgungs- und Analysefunktionen für den Ablauf von Anfragen in komplexen verteilten Systemen liefert das verteilte Tracing Einblicke in die Interaktionen zwischen Komponenten und Diensten, um Engpässe und andere potenzielle Problemursachen zu identifizieren. - Logmusteranalyse
Mit der Analyse von Mustern und Trends in Logs, die von Anwendungen und Infrastrukturelementen generiert wurden, können Sie Problemursachen identifizieren und Anomalien, Fehler und andere Probleme aufdecken, die sich negativ auf die Softwareleistung auswirken können. - Kartografierung von Dienstabhängigkeiten
Durch das Identifizieren der Beziehungen und Abhängigkeiten zwischen verschiedenen Systemkomponenten können Sie automatisch Dienstabhängigkeiten kartografieren, die möglicherweise Probleme verursachen und die Auswirkungen von Änderungen an einer Komponente auf das restliche System besser abschätzen. - Korrelation von Latenz und Fehlern
Indem Sie Daten im Zusammenhang mit Latenz und Fehlerraten analysieren und Korrelationen identifizieren können Sie Muster und Beziehungen zwischen Fehlern und Leistungsproblemen aufdecken und Problemursachen exakt orten.
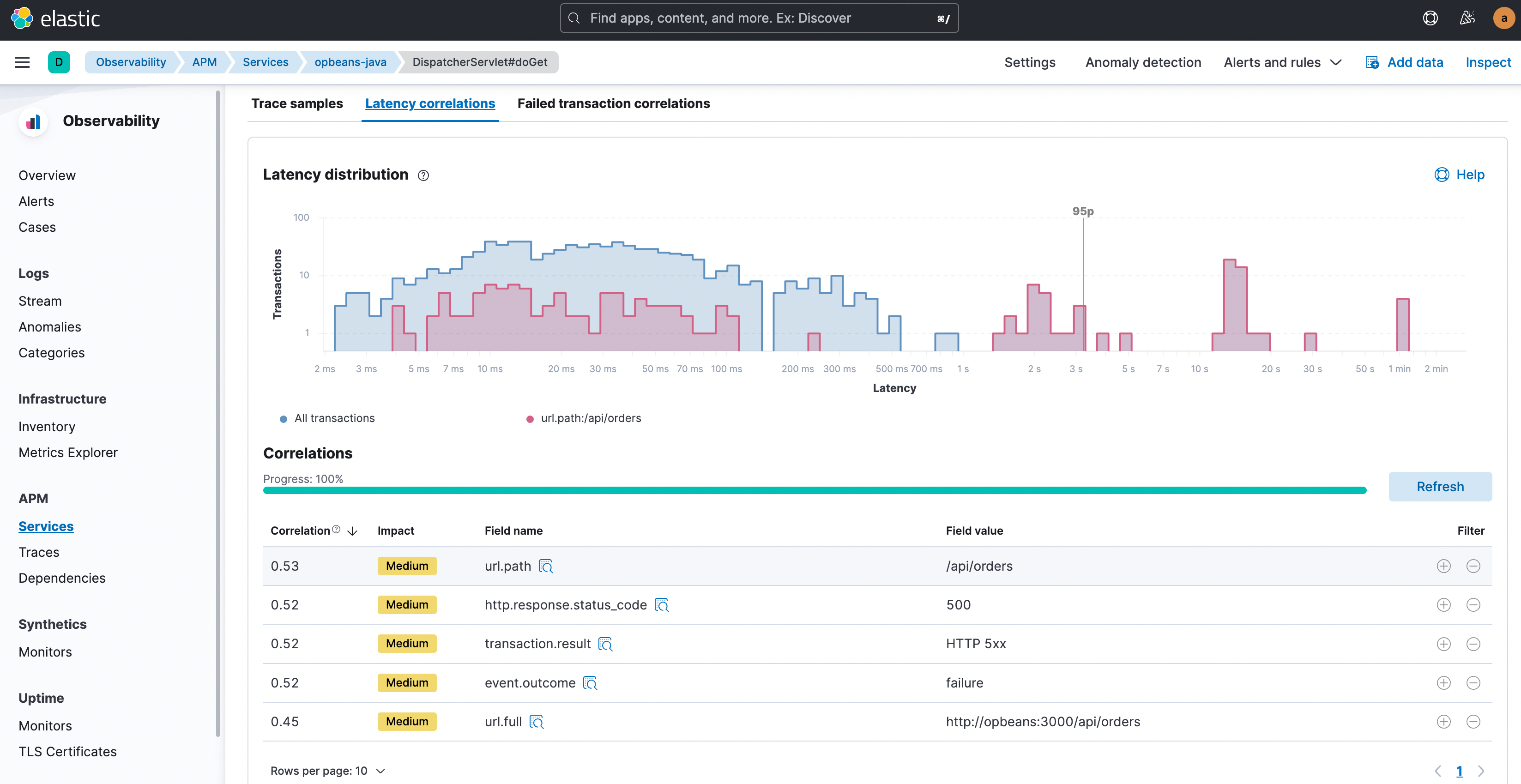
Sicherheit
Die Analyse von sicherheitsrelevanten Daten zum Identifizieren von Sicherheitslücken und Schwachstellen im System ist ein wichtiger Aspekt der Ursachenanalyse. Mit dieser Analyse können Sie Sicherheitsverletzungen und andere Probleme vermeiden, die die Softwareleistung beeinträchtigen könnten.
- Unbeaufsichtigte Anomalieerkennung als zusätzliche Verteidigungslinie
Für eine umfassende Sicherheitsstrategie brauchen Sie einen mehrschichtigen Bedrohungsschutz. Unbeaufsichtigte Machine-Learning-Funktionen erkennen Abweichungen von den normalen Aktivitäten in Ihren Daten, ohne dass Sie die abnormalen Daten selbst definieren müssen, und können Angriffe aufdecken, die mit herkömmlichen Threat-Hunting-Ansätzen oft unentdeckt bleiben. - Bedrohungen untersuchen und Korrelationen aufdecken
Durch die Analyse sicherheitsrelevanter Daten zu erkannten Ereignissen können Sie ermitteln, ob es sich tatsächlich um Bedrohungen handelt oder ob sie ignoriert werden können. Sicherheitsanalysten erkennen bösartige Aktivitäten anhand von Mustern in Sitzungen, Ereignisabläufen und Diagnosedaten von Hosts.
Gängige Fehler und Fallstricke bei der Ursachenanalyse
Eine richtig durchgeführte Ursachenanalyse ist extrem hilfreich beim Identifizieren und Beheben von Problemen, wobei jedoch einige typische Fehler vermieden werden sollten:
- Mangelnde Datenvalidierung: Wenn die in Ihrer Analyse verwendeten Daten nicht angemessen validiert wurden, können sie zu fehlerhaften Schlussfolgerungen und wirkungslosen Lösungen führen.
- Auswahl von Lösungen als Ursachen: Dinge wie ein Mangel an Schulungen und Support oder Budgeteinschränkungen sind nur selten die tatsächliche Ursache eines Problems. Sie sind oft vielmehr Lösung als Ursache. Es ist wichtig, tiefer zu graben, um ein Problem zu seinem Ursprung zurückzuverfolgen.
- Suche nach einer zentralen Ursache: Probleme werden oft durch viele verschiedene Faktoren verursacht, die allesamt identifiziert werden müssen, anstatt nur eine „bequeme“ Schlussfolgerung zu ziehen.
- Nicht die richtigen Leute einbeziehen: Für eine sinnvolle und effektive Ursachenanalyse müssen alle relevanten Beteiligten einbezogen werden, inklusive Softwareentwickler, Tester und Business Analysts.
Vorteile der Ursachenanalyse
Im Bereich der Softwareentwicklung können Sie mit der Ursachenanalyse Probleme besser beheben, Kosten senken und Ihre Effizienz steigern, was wiederum zu einem besseren Produkt und zufriedeneren Kunden führt. Die Ursachenanalyse ist entscheidend bei der Softwareentwicklung und hilft Teams, den Ursprung fundamentaler Fehler sowie Ansätze zu deren Behebung zu finden. Mit der Ursachenanalyse lässt sich außerdem verhindern, dass die Probleme erneut auftreten.
- Verhindert, dass Probleme erneut auftreten: Mit der Ursachenanalyse können die Teams Lösungen implementieren, die Ursachen anstelle von Symptomen beheben. Wenn ein erneutes Auftreten des Problems verhindert wurde, können die Teams Zeit und Kosten sparen und hochwertigere Software ausliefern. Stellen Sie sich beispielsweise vor, ein Softwareteam bemerkt, dass ein Feature einer Anwendung häufig abstürzt. Bei der Ursachenanalyse finden sie heraus, dass das Problem durch bestimmte, nicht korrekt verarbeitete Nutzereingaben verursacht wird. Mit dieser Information kann das Team eine Lösung implementieren, die das Problem ein für alle Mal behebt.
- Effizientere Prozesse: Durch das Identifizieren der Ursachen können die Teams ihre Prozesse optimieren und ähnliche Probleme in Zukunft vermeiden. Dies führt zu mehr Effizienz, weniger Ausfallzeiten und einem schnelleren Entwicklungsprozess. Wenn ein Entwicklungsteam feststellt, dass die Continuous-Integration-Pipeline regelmäßig aufgrund von Problemen in der Testsammlung fehlschlägt, können sie mit einer Ursachenanalyse herausfinden, ob beispielsweis zu lange laufende Tests eine Zeitüberschreitung in der Pipeline verursachen. Anschließend können sie ihre Testsammlung optimieren, um diese Art von Problemen in Zukunft zu vermeiden.
- Zufriedenere Kunden: Mit der Ursachenanalyse können Teams Probleme beheben, die die Kundenzufriedenheit beeinträchtigen könnten. Wenn ein Team beispielsweise Beschwerden über die Ladedauer eines Features erhält, können die Teammitglieder mit der Ursachenanalyse herausfinden, ob das Problem durch eine mangelhaft optimierte Datenbankabfrage verursacht wird. Anschließend können sie beispielsweise die Leistung der Abfrage optimieren, um zu verhindern, dass das Problem erneut auftritt, und so ein besseres Nutzererlebnis bereitstellen. Wenn eine Software die Kundenerwartungen fortlaufend erfüllt, wirkt sich dies hervorragend auf Vertrauen und Kundentreue aus, was wiederum die Erträge und das langfristige Wachstum steigert.
Tipps für die Durchführung einer Ursachenanalyse
- Informationen aus verschiedenen Quellen einbeziehen und die Daten gut kennen
Qualität, Transparenz und Verständnis der Daten sind für eine effiziente Ursachenanalyse unverzichtbar. Von Elastic erhalten Sie eine Lösung, mit der Sie sämtliche Daten in einem System konsolidieren können. Mit der Datenvisualisierung in Kibana und den interaktiven Tools können Sie Observability-Probleme und Sicherheits-Incidents umfassend untersuchen. - Im Team arbeiten, damit sich mehrere Personen die Daten und das Problem ansehen
Elastic bietet umfassende Unterstützung für eine personalisierte Zusammenarbeit in Kibana und O11y, damit Sie Workflows optimieren und Eskalationen mit Ihrem Team vereinfachen können. - Notizen machen
Elastic bietet optimierte Warnungen und Fallverwaltungsfunktionen, damit Sie schnell und kontextbezogen Einblicke in Ihre Daten und Visualisierungen erhalten und Anmerkungen sogar dynamisch aus Elasticsearch-Abfragen in Kibana generieren können. Für Ihre abfragebasierten Anmerkungen können Sie die Kibana Lens-Visualisierung manuell mit Notizen versehen.
Ursachenanalyse mit Elastic
Die Elasticsearch-Plattform und die integrierten Lösungen – Elastic Enterprise Search, Elastic Observability und Elastic Security – bilden gemeinsam einen Turboantrieb für Ihre Ursachenanalyse. Elastic Observability ist die weltweit meist genutzte Lösung zum Transformieren von Metriken, Logdaten und Traces in verwertbare IT-Erkenntnisse und die ideale Lösung für die Zentralisierung der Observability in Ihrem gesamten digitalen Ökosystem. Außerdem wird Elastic Security von Analysten weithin als Marktführer für Security-Analytics und SIEM anerkannt.
Insbesondere die folgenden Funktionen sind hilfreich für die verschiedenen Phasen von Ursachenanalysen:
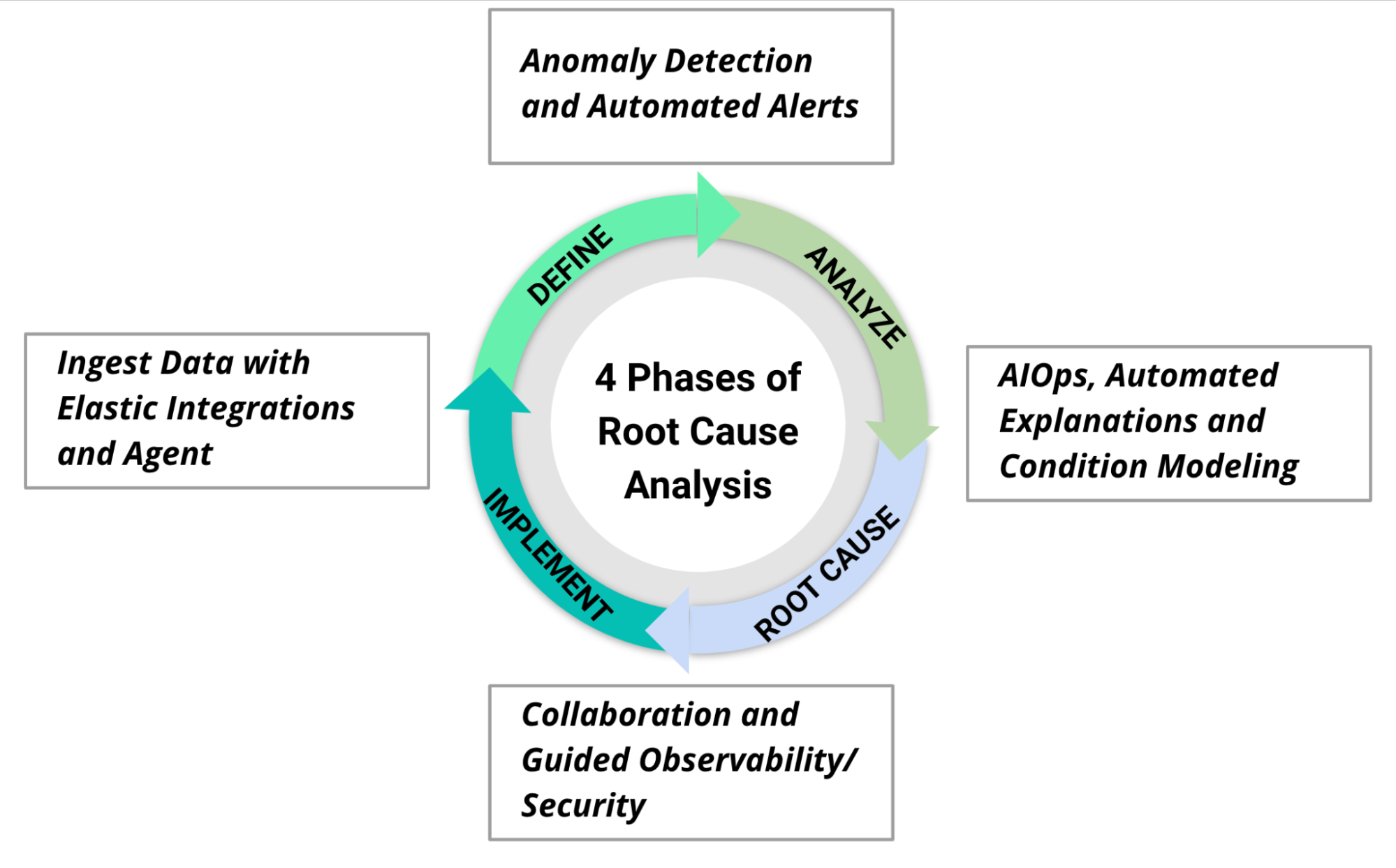
- Ingestieren von Daten mit dem Elastic Agent und Hunderten von Integrationen.
- Nutzen Sie den „Autopilot“ für Ihr Monitoring und lassen Sie sich mit vorkonfigurierten Warnungen und der Anomalieerkennung automatisch über potenzielle Probleme benachrichtigen.
- Wenden Sie Machine Learning und AIOps an, um umfangreiche Datensätze im großen Stil zu verarbeiten, zusammen mit interaktiven und maßgeschneiderten RCA-Observability-Funktionen, inklusive APM-Korrelationen und Erläuterung von Spitzen bei Logging-Raten. Unterstützen Sie Sicherheitsuntersuchungen mit Features wie der Sitzungsansicht und der Ereigniszeitleiste und fordern Sie Diagnosedaten mit Osquery von Ihren Hosts an.
- Ermitteln Sie auslösende Faktoren mit angeleiteten Journeys und erarbeiten sie gemeinsam Ursachen und passende Lösungen für aufgetretene Probleme mit der Elastic-Fallverwaltung.
Starten Sie eine kostenlose Testversion, um Ihr Team bei wirkungsvollen Ursachenanalysen zu unterstützen und herauszufinden, was Elastic für Sie tun kann.
Ressourcen für Ursachenanalysen (teils nur auf Englisch verfügbar)
- Ursachenanalyse für Logs
- AIOps für die Automatisierung der Problemlösung und die Optimierung der operativen Abläufe
- Elastic Security für SIEM und Security-Analytics
- Elastic Security für automatisierten Schutz vor Bedrohungen
- Schnellere Sicherheitsuntersuchungen mit Machine Learning und interaktiven Ursachenanalysen in Elastic
- Ursachenanalysen im Fertigungsbereich mit Elastic
- Prädiktive Wartung in industriellen IoT-Systemen