Qu'est-ce que le Machine Learning ?
Définition du Machine Learning
Le Machine Learning (ML) est une branche de l'intelligence artificielle (IA) qui se concentre sur l'utilisation de données et d'algorithmes pour imiter le mode d'apprentissage des humains, en améliorant progressivement la précision au fil du temps. C'est Arthur Samuel, informaticien et pionner de l'IA, qui va le définir pour la première fois dans les années 1950 : "discipline qui donne aux ordinateurs la capacité d'apprendre sans être explicitement programmés".
Le Machine Learning consiste à alimenter des algorithmes informatiques avec de grandes quantités de données afin qu'ils puissent apprendre à identifier des schémas et des relations au sein de cet ensemble de données. Les algorithmes commencent alors à faire leurs propres prédictions ou à prendre leurs propres décisions en fonction de leurs analyses. Au fur et à mesure que les algorithmes reçoivent de nouvelles données, ils continuent d'affiner leurs choix et d'améliorer leurs performances de la même manière qu'une personne s'améliore avec de la pratique.
Quels sont les quatre types de Machine Learning ?
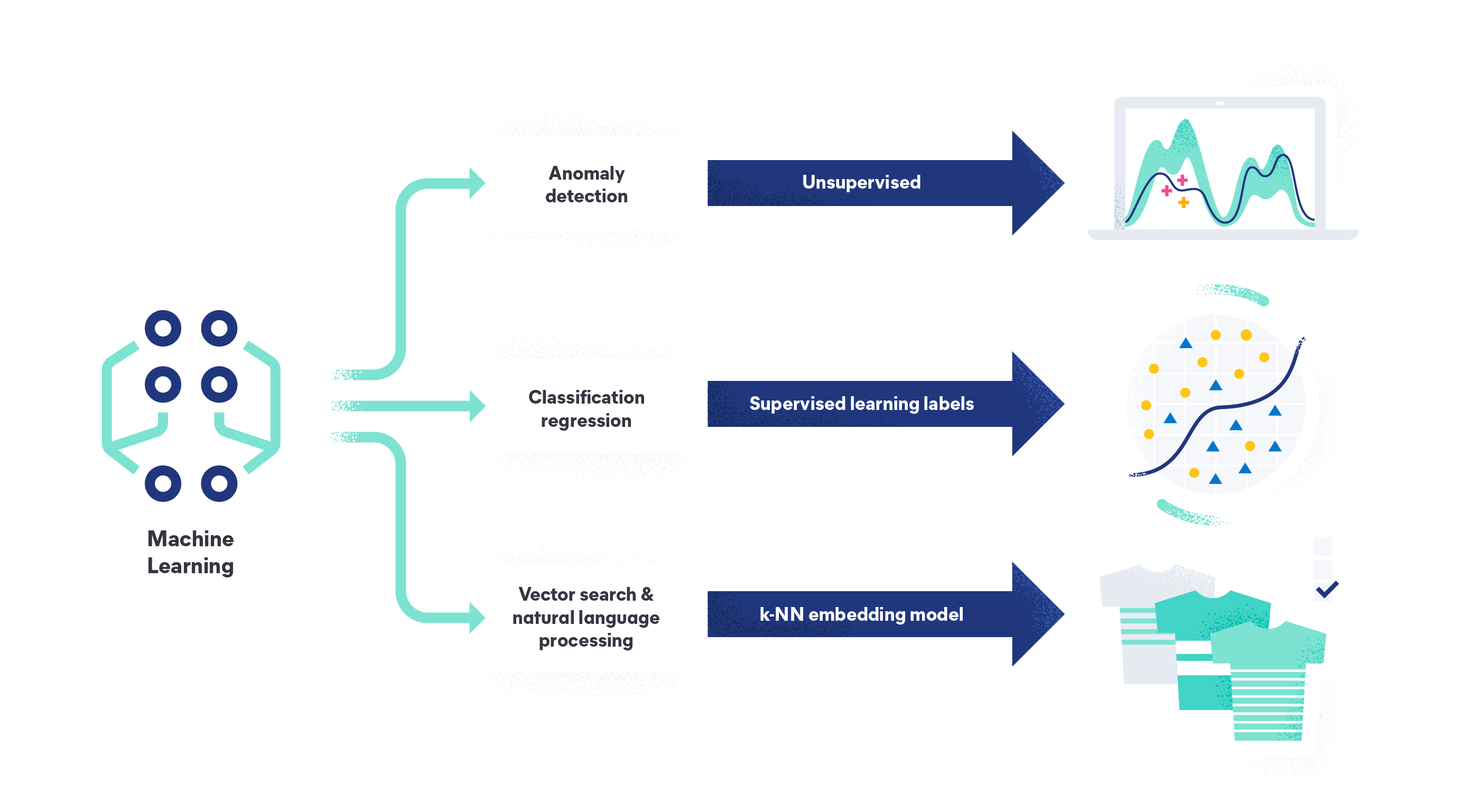
Les quatre types de Machine Learning sont le Machine Learning supervisé, le Machine Learning non supervisé, l'apprentissage semi-supervisé et l'apprentissage par renforcement.
Le Machine Learning supervisé est le type de Machine Learning le plus courant. Dans les modèles d'apprentissage supervisé, l'algorithme apprend à partir d'ensembles de données d'entraînement étiquetés et améliore sa précision au fil du temps. Il est conçu pour créer un modèle capable de prédire correctement la variable cible lorsqu'il reçoit de nouvelles données qu'il n'a jamais vues. Cela pourrait être, par exemple, des humains étiquetant et imputant des images de roses et d'autres fleurs. L'algorithme pourrait alors identifier correctement une rose lorsqu'il en reçoit une nouvelle image sans étiquette.
On parle de Machine Learning non supervisé, lorsque l'algorithme recherche des schémas dans des données qui n'ont pas été étiquetées et qui n'ont pas de variables cibles. L'objectif est de trouver des schémas et des relations dans les données que les humains n'ont peut-être pas encore identifiés, comme la détection d'anomalies dans les logs, les traces et les indicateurs pour repérer les problèmes système et les menaces de sécurité.
L'apprentissage semi-supervisé est un hybride du Machine Learning supervisé et du Machine Learning non supervisé. Dans l'apprentissage semi-supervisé, l'algorithme s'entraîne à la fois sur des données étiquetées et non étiquetées. Il apprend d'abord à partir d'un petit ensemble de données étiquetées pour faire des prédictions ou prendre des décisions en fonction des informations disponibles. Il utilise ensuite le plus grand ensemble de données non étiquetées pour affiner ses prédictions ou décisions en trouvant des schémas et des relations dans les données.
On parle d'apprentissage par renforcement lorsque l'algorithme apprend par des essais et des erreurs en obtenant un retour sous forme de récompenses ou de pénalités pour ses actions. Voici quelques exemples : former un agent IA à jouer à un jeu vidéo, où il reçoit une récompense positive s'il progresse dans les niveaux et une pénalité s'il échoue ; optimiser une chaîne d'approvisionnement, où l'agent est récompensé s'il réduit les coûts et optimise la vitesse de livraison ; ou des systèmes de recommandation, où l'agent suggère des produits ou du contenu et est récompensé par des achats et des clics.
Comment fonctionne le Machine Learning ?
Le Machine Learning peut fonctionner de différentes manières. Vous pouvez appliquer un modèle de Machine Learning entraîné à de nouvelles données ou vous pouvez entraîner un nouveau modèle à partir de zéro.
L'application d'un modèle de Machine Learning entraîné à de nouvelles données est en général plus rapide et moins gourmande en ressources. Au lieu de développer des paramètres via l'entraînement, vous utilisez les paramètres du modèle pour faire des prédictions sur les données d'entrée, un processus appelé inférence. Vous n'avez pas non plus besoin d'évaluer ses performances, car cela a déjà été effectué lors de la phase d'entraînement. Cependant, vous devez préparer soigneusement les données d'entrée pour vous assurer que leur format est identique à celles utilisées pour entraîner le modèle.
L'entraînement d'un nouveau modèle de Machine Learning implique les étapes suivantes :
Collecte de données
Commencez par choisir vos ensembles de données. Les données peuvent provenir de diverses sources telles que les logs, les indicateurs et les traces système. En plus des logs et des indicateurs, plusieurs autres types de données temporelles sont importants dans l'entraînement du Machine Learning, notamment :
- Données de marché financier, telles que les prix des actions, les taux d'intérêt et les taux de change. Ces données sont souvent utilisées pour créer des modèles prédictifs à des fins de trading et d'investissement.
- Données temporelles de transport, telles que le volume de trafic, la vitesse et le temps de trajet. Ces données peuvent être utilisées pour optimiser les itinéraires et réduire les embouteillages.
- Données d'utilisation des produits, telles que le trafic sur le site web et l'engagement sur les réseaux sociaux. Ces données peuvent aider les entreprises à comprendre le comportement des clients et à identifier les domaines à améliorer.
Quelles que soient les données que vous utilisez, elles doivent être pertinentes par rapport au problème que vous essayez de résoudre et elles doivent être représentatives de la population pour laquelle vous souhaitez faire des prédictions ou prendre des décisions.
Prétraitement des données
Une fois que vous avez collecté les données, vous devez les prétraiter pour qu'elles soient utilisables par un algorithme de Machine Learning. Cela implique parfois d'étiqueter les données ou d'attribuer une catégorie ou une valeur spécifique à chaque point de données dans un ensemble de données, ce qui permet à un modèle de Machine Learning d'apprendre des schémas et de faire des prédictions.
De plus, cela peut impliquer la suppression des valeurs manquantes, la transformation des données temporelles en un format plus compact en appliquant des agrégations et le scaling des données pour garantir que toutes les caractéristiques ont des plages similaires. Pour les réseaux de neurones profonds, tels que les grands modèles de langage, il est impératif d'avoir une grande quantité de données d'entraînement étiquetées. Pour les modèles supervisés classiques, il n'est pas utile d'en traiter autant.
Sélection des caractéristiques
Certaines approches exigent que vous sélectionniez les caractéristiques qui seront utilisées par le modèle. Vous devez simplement identifier les variables ou les attributs les plus pertinents pour le problème que vous essayez de résoudre. Les corrélations sont un moyen de base pour identifier les caractéristiques. Pour améliorer davantage l'optimisation, de nombreux frameworks de ML proposent des méthodes automatisées de sélection des caractéristiques.
Sélection du modèle
Maintenant que vous avez sélectionné les caractéristiques, vous devez choisir un modèle de Machine Learning adapté au problème que vous essayez de résoudre. Parmi les options, on peut citer les modèles de régression, les arbres de décision et les réseaux de neurones. (Voir "Techniques et algorithmes de Machine Learning" ci-dessous.)
Entraînement
Après avoir choisi un modèle, vous devez l'entraîner à l'aide des données que vous avez collectées et prétraitées. L'entraînement est la phase pendant laquelle l'algorithme apprend à identifier les schémas et les relations dans les données et les encode dans les paramètres du modèle. Pour atteindre des performances optimales, l'entraînement est un processus itératif. Cela peut inclure le réglage des hyperparamètres du modèle, et l'amélioration du traitement des données et de la sélection des caractéristiques.
Tests
Maintenant que le modèle a été entraîné, vous devez le tester sur de nouvelles données qu'il n'a jamais vues et comparer ses performances à d'autres modèles. Vous sélectionnez le modèle le plus performant et évaluez ses performances sur des données de test distinctes. Seules les données non utilisées précédemment vous donnent une bonne estimation des performances de votre modèle après son déploiement.
Déploiement du modèle
Lorsque vous êtes satisfait des performances du modèle, vous pouvez le déployer dans un environnement de production où il peut faire des prédictions ou prendre des décisions en temps réel. Cela peut impliquer d'intégrer le modèle dans d'autres systèmes ou applications logicielles. Les frameworks ML intégrés aux fournisseurs de calcul dans le cloud les plus courants facilitent le déploiement de modèles dans le cloud.
Monitoring et mise à jour
Une fois le modèle déployé, vous devez monitorer ses performances et le mettre à jour périodiquement au fur et à mesure de la disponibilité de nouvelles données ou de l'évolution du problème que vous essayez de résoudre. Cela peut impliquer de réentraîner le modèle avec de nouvelles données, d'ajuster ses paramètres ou de choisir un algorithme de ML différent.
Pourquoi le Machine Learning est-il important ?
Le Machine Learning est important car il apprend à exécuter des tâches complexes à l'aide d'exemples, sans programmation d'algorithmes spécialisés. Par rapport aux approches algorithmiques traditionnelles, le Machine Learning vous permet d'automatiser davantage, d'améliorer l'expérience des clients et de créer des applications innovantes qui n'étaient pas réalisables auparavant. En outre, les modèles de Machine Learning peuvent s'améliorer de manière itérative pendant l'utilisation. Quelques exemples :
- Prédiction de tendances pour améliorer les décisions commerciales
- Personnalisation de recommandations qui améliorent les revenus et la satisfaction des clients
- Automatisation du monitoring des applications complexes et de l'infrastructure informatique
- Identification des indésirables et détection des failles de sécurité
Techniques et algorithmes de Machine Learning
De nombreux algorithmes et techniques de Machine Learning sont disponibles. Celui que vous choisissez dépend du problème que vous essayez de résoudre et des caractéristiques des données. Voici un aperçu rapide de certains des plus courants : La régression linéaire est utilisée lorsque l'objectif est de prédire une variable continue.
La régression linéaire suppose une relation linéaire entre les variables d'entrée et la variable cible. Il peut s'agir, par exemple, de prédire le prix de maisons comme une combinaison linéaire de la surface, de l'emplacement, du nombre de chambres et d'autres caractéristiques.
La régression logistique est utilisée pour les problèmes de classification binaire où l'objectif est de prédire un résultat oui/non. La régression logistique estime la probabilité de la variable cible en fonction d'un modèle linéaire de variables d'entrée. Il peut s'agir, par exemple, de prédire si une demande de prêt sera approuvée ou non en fonction de la note de solvabilité du demandeur et d'autres données financières.
Les arbres de décision suivent un modèle en forme d'arbre pour relier des décisions à des conséquences possibles. Chaque décision (règle) représente un test d'une variable d'entrée, et plusieurs règles peuvent être appliquées successivement selon un modèle en forme d'arbre. Il divise les données en sous-ensembles, en utilisant la caractéristique la plus importante à chaque nœud de l'arbre. Par exemple, il est possible d'utiliser des arbres de décision pour identifier les clients potentiels d'une campagne marketing en fonction de leurs données démographiques et de leurs intérêts.
Les forêts aléatoires combinent plusieurs arbres de décision pour améliorer la précision des prédictions. Chaque arbre de décision est entraîné sur un sous-ensemble aléatoire des données d'entraînement et un sous-ensemble des variables d'entrée. Les forêts aléatoires sont plus précises que les arbres de décision individuels. De plus, elles gèrent mieux les ensembles de données complexes ou les données manquantes, mais elles peuvent devenir assez volumineuses et nécessiter plus de mémoire lorsqu'elles sont utilisées dans l'inférence.
Les arbres de décision optimisés entraînent une succession d'arbres de décision, chaque arbre de décision s'améliorant par rapport au précédent. La procédure d'optimisation prend les points de données qui ont été mal classés par l'itération précédente de l'arbre de décision et réentraîne un nouvel arbre de décision pour améliorer la classification sur ces points précédemment mal classés. Le package populaire XGBoost Python implémente cet algorithme.
Les machines à vecteurs de support fonctionnent pour trouver un hyperplan qui sépare au mieux les points de données d'une classe de ceux d'une autre classe. Pour cela, il réduit la "marge" entre les classes. Les vecteurs de support font référence aux quelques observations qui identifient l'emplacement de l'hyperplan de séparation, qui est défini par trois points. L'algorithme SVM standard s'applique uniquement à la classification binaire. Les problèmes multiclasses sont réduits à une série de problèmes binaires.
Les réseaux de neurones s'inspirent de la structure et du fonctionnement du cerveau humain. Ils se composent de couches interconnectées de nœuds qui peuvent apprendre à reconnaître les schémas dans les données en ajustant les forces des connexions entre eux.
Les algorithmes de clustering sont utilisés pour regrouper les points de données en clusters en fonction de leur similarité. Ils peuvent être utilisés pour des tâches telles que la segmentation des clients et la détection des anomalies. Ils sont particulièrement utiles pour la segmentation et le traitement des images.
Quels sont les avantages du Machine Learning ?
Le Machine Learning présente de nombreux avantages. Il peut donner à vos équipes les moyens de passer au niveau supérieur de performance dans les catégories suivantes :
- Automatisation : les tâches cognitives difficiles pour les humains, en raison de leur répétitivité ou de leur difficulté objective, peuvent être automatisées grâce au Machine Learning. Il peut s'agir, par exemple, du monitoring de systèmes en réseau complexes, de l'identification d'activités suspectes dans des systèmes complexes et de la prédiction du moment où l'équipement a besoin d'être entretenu.
- Expérience client : l'intelligence fournie par les modèles de Machine Learning peut améliorer l'expérience utilisateur. Pour les applications optimisées pour la recherche, la capture de l'intention et des préférences vous permet de fournir des résultats plus pertinents et personnalisés. Les utilisateurs peuvent rechercher et trouver ce qu'ils ont en tête.
- Innovation : le Machine Learning résout des problèmes complexes qui étaient impossibles avec des algorithmes spécialement conçus. Par exemple, la recherche de données non structurées incluant des images ou du son, l'optimisation des tendances de trafic, l'amélioration des systèmes de transport en commun et le diagnostic des problèmes de santé.
Découvrez comment le Machine Learning propulse la recherche au niveau supérieur
Cas d'utilisation du Machine Learning
Voici quelques sous-catégories du Machine Learning et leurs cas d'utilisation :
L'analyse des sentiments est le processus d'utilisation du traitement du langage naturel pour analyser les données textuelles et déterminer si leur sentiment global est positif, négatif ou neutre. Elle est utile pour les entreprises qui recherchent un retour client, car elle peut analyser diverses sources de données (par exemple, les tweets sur Twitter, les commentaires sur Facebook et les avis sur les produits) pour évaluer les opinions et les niveaux de satisfaction des clients.
La détection des anomalies est le processus d'utilisation des algorithmes pour identifier les schémas ou les aberrations inhabituels dans les données qui pourraient indiquer un problème. La détection des anomalies est utilisée pour monitorer l'infrastructure informatique, les applications en ligne et les réseaux, ainsi que pour identifier les activités qui signalent une faille de sécurité potentielle ou qui pourraient entraîner une panne réseau ultérieurement. La détection des anomalies est également utilisée pour détecter les transactions bancaires frauduleuses. En savoir plus sur AIOps.
La reconnaissance d'images analyse les images et identifie les objets, les visages ou d'autres caractéristiques dans les images. Elle a un grand nombre d'applications au-delà des outils couramment utilisés tels que la recherche d'images Google. Par exemple, elle peut être utilisée en agriculture pour surveiller la santé des cultures et identifier les nuisibles ou les maladies. La reconnaissance d'images est utilisée dans les voitures autonomes, l'imagerie médicale, les systèmes de surveillance et les jeux de réalité augmentée.
L'analyse prédictive analyse les données historiques et identifie les schémas pouvant être utilisés pour faire des prédictions sur les événements ou les tendances futurs. Cela peut aider les entreprises à optimiser leurs opérations, à prévoir la demande ou à identifier des risques ou des opportunités potentiels. Citons par exemple les prédictions de la demande de produits, les retards de trafic et la durée pendant laquelle les équipements de fabrication peuvent fonctionner en toute sécurité.
En savoir plus sur la maintenance prédictive
Quels sont les inconvénients du Machine Learning ?
Voici les inconvénients du Machine Learning :
- Dépendance à des données d'entraînement de haute qualité : si les données sont biaisées ou incomplètes, le modèle peut également être biaisé ou inexact.
- Coûts : l'entraînement des modèles et le prétraitement des données peuvent avoir un coût très élevé. Cela dit, il reste toujours inférieur au coût plus élevé de la programmation d'un algorithme spécialisé pour réaliser la même tâche, et ne serait probablement pas aussi précis.
- Manque d'explicabilité : la plupart des modèles de Machine Learning, tels que les réseaux de neurones profonds, manquent de transparence dans leur fonctionnement. Souvent appelés modèles de type "boîte noire", il est difficile de comprendre comment les modèles arrivent à leurs décisions.
- Expertise : plusieurs types de modèles sont disponibles. Sans une équipe de spécialistes en Data Science désignée, les entreprises peuvent avoir du mal à régler les hyperparamètres pour atteindre des performances optimales. La complexité de l'entraînement, en particulier pour les transformateurs, de l'intégration et des grands modèles de langage, peut également représenter un obstacle à l'adoption.
Bonnes pratiques du Machine Learning
Voici quelques bonnes pratiques du Machine Learning :
- Assurez-vous que vos données sont propres, organisées et complètes.
- Sélectionnez la bonne approche qui correspond à votre problème et à vos données actuels.
- Utilisez des techniques pour éviter le surapprentissage, où le modèle fonctionne bien sur les données d'entraînement mais mal sur les nouvelles données.
- Évaluez les performances de votre modèle en le testant sur des données totalement inédites. Les performances que vous avez mesurées lors du développement et de l'optimisation de votre modèle ne sont pas un bon indicateur de ses performances en production.
- Ajustez les paramètres de votre modèle pour trouver les meilleures performances, ce que l'on appelle le réglage des hyperparamètres.
- Choisissez des indicateurs en plus de la précision standard du modèle, qui évaluent les performances de votre modèle dans le contexte de votre application réelle et de votre problème métier.
- Tenez des registres détaillés pour vous assurer que les autres peuvent comprendre et reproduire votre travail.
- Tenez votre modèle à jour pour vous assurer qu'il continue de bien fonctionner sur les nouvelles données.
Lancez-vous avec le Machine Learning Elastic
Le Machine Learning Elastic hérite des avantages de notre plateforme Elasticsearch scalable. Vous obtenez de la valeur dès le départ avec des intégrations dans des solutions d'observabilité, de sécurité et de recherche qui utilisent des modèles nécessitant moins de formation pour être opérationnels. Avec Elastic, vous pouvez rassembler de nouvelles informations pour offrir des expériences révolutionnaires à vos utilisateurs internes et à vos clients, le tout avec une fiabilité à grande échelle.
Découvrez comment vous pouvez :
Ingérer des données provenant de centaines de sources, et appliquer le Machine Learning et le traitement du langage naturel là où vos données résident avec des intégrations embarquées.
Appliquer le Machine Learning de la manière qui vous convient le mieux. Obtenez de la valeur dès le départ des modèles préconfigurés, en fonction de votre cas d'utilisation : modèles préconfigurés pour le monitoring automatisé et la recherche des menaces, modèles et transformateurs préentraînés pour implémenter des tâches de NLP comme l'analyse des sentiments ou l'interaction de réponse aux questions, et Elastic Learned Sparse Encoder™ pour implémenter la recherche sémantique en un clic. Ou, si votre cas d'utilisation exige des modèles optimisés et personnalisés, entraînez des modèles supervisés à l'aide de vos données. Avec Elastic, appliquez l'approche qui convient à vos cas d'utilisation et qui correspond à votre niveau d'expertise !
Ressources du Machine Learning
- Machine Learning pour Elasticsearch
- Machine Learning dans la Suite Elastic
- Accéder à des modèles et transformateurs de ML tiers dans Elastic
- Propulsez la recherche au niveau supérieur grâce au Machine Learning
- Appliquer le Machine Learning à l'observabilité avec AIOps
- Augmenter la profondeur de la défense en matière de sécurité avec le Machine Learning
Glossaire du Machine Learning
- L'intelligence artificielle est la capacité des machines à exécuter des tâches qui nécessitent généralement l'intelligence humaine, telles que l'apprentissage, le raisonnement, la résolution de problèmes et la prise de décision.
- Les réseaux de neurones sont un type d'algorithme de Machine Learning qui se compose de couches interconnectées de nœuds qui traitent et transmettent des informations. Ils s'inspirent de la structure et du fonctionnement du cerveau humain.
- Le Deep Learning est un sous-domaine des réseaux de neurones qui comporte de nombreuses couches, ce qui lui permet d'apprendre des relations beaucoup plus complexes que d'autres algorithmes de Machine Learning.
- Le traitement du langage naturel (NLP) est un sous-domaine de l'IA dont l'objectif est de permettre aux machines de comprendre, d'interpréter et de générer du langage humain.
- La recherche vectorielle est un type d'algorithme de recherche qui utilise des plongements vectoriels et la recherche des k plus proches voisins pour récupérer des informations pertinentes à partir de grands ensembles de données.