Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In a recent blog post, we discussed how ChatGPT and Elasticsearch can work together to help manage proprietary data more effectively. By utilizing Elasticsearch's search capabilities and ChatGPT's contextual understanding, we demonstrated how the resulting outcomes can be improved.
In this post, we discuss how users’ experience can be further enhanced with the addition of facets, filtering, and additional context. By providing tools like ChatGPT additional context, you can increase the likelihood of obtaining more accurate results. See how Elasticsearch's faceting and filtering framework can allow users to refine their search and reduce the cost of engaging with ChatGPT.
Comparing ChatGPT and Elasticsearch results
To improve the user experience of our sample application, we've added a feature that displays the raw results alongside the ChatGPT-created response. This will help users better understand how ChatGPT works.
Since our source data set is only crawled, the structure in the documents makes it difficult to read for a human. To show this difference and therefore the value that ChatGPT can bring, we added the raw result next to the GPT created response.

Currently, this example application only returns a single result. And even though we have hybrid scoring with vector search and BM25, this result may not be perfect. If we take this not perfect result and pass it over to ChatGPT, there’s a good chance that the response we get won’t be great either, as the context was missing important information.
Ideally, we’d just pass more context into ChatGPT, but the current 3.5-turbo models are limited to 4,096 tokens (that’s including the response you expect to get, so the actual limit is much lower). Future models will likely have a much larger limit, but this also comes with a cost.
As of today, GPT-3.5-turbo costs $0.002 per 1K tokens, while the up-and-coming GPT-4 with 32K context costs $0.06 per 1K tokens — that’s a factor of 30 more. Even with more powerful models coming in the next few years, there’s a chance that it’s not economically viable to do so for all user cases.
We will therefore not use GPT-4 right now and instead work around the max token limitation of GPT-3.5 by sending multiple concurrent requests and giving the user more flexibility in filtering the results.
Leveraging aggregations, facets, and filtering in Elasticsearch to enhance ChatGPT
To address this limitation, one of the biggest advantages of Elasticsearch is its robust faceting and filtering framework. When a user is searching for something, they may have additional preferences or context they can provide to dramatically increase the likelihood of obtaining the correct result. By leveraging Elasticsearch's faceting and filtering framework, we can allow users to refine their search based on various parameters such as date, location, or other relevant criteria.
It’s also important to note that many users have gotten used to having facet filtering options available when searching for something. Let us look at an example.
Searching for “How can I parse a message with Grok?” results in a document for ingest pipelines to be returned as the top result. This is not wrong, as ingest pipelines also support Grok expressions, but what if the user was interested in parsing his data using Logstash?
Using a simple terms aggregation as part of the request to fetch the hits, we can get a list of the top 10 product categories and offer these as a filtering option for a user.

If the user now selects “Logstash” on the left side, all results will be filtered for Logstash. It’s important to note that this all works while still using the same hybrid query model that we’ve talked about in the previous blog. We’re still using a combination of BM25 and kNN search to match our documents.

Loading multiple results in parallel
We briefly mentioned the max token limit earlier. In short, the prompt that you send to the API and its response can’t be longer than 4,096 tokens. When searching your proprietary data, you would like to provide as much specific context as possible so the model can give you the best answer. However, the 4,096 tokens aren’t that much, especially when you include things like code snippets.
A very simple first step toward mitigating the limit is to just ask multiple times in parallel, giving a different context each time. Using our approach with Elasticsearch, instead of only fetching the top 1 result and sending that to OpenAI, we can change the application to load the top 10 hits instead and then ask the question with the respective context.
This gives us 10 unique answers to our question and greatly increases our chances of presenting a relevant answer to the end user. While we are increasing the burden of the user to look at the results, it still gives them more flexibility.
Think of it like this: if you try to debug a problem and search for an exception on Google, you quickly scan the list of the top four or five results that Google displays and click on the one that seems most fitting to your question. Showing the user multiple answers to their question is similar to this.
While having a single correct answer would be ideal, having more than one to choose from initially is a great starting point. And as mentioned before, it can be cheaper compared to using a more expensive model (such as GPT-4).
We can also get more creative with our prompt and ask ChatGPT to send us a specific response if it can’t answer the question using the provided context. This will allow us to remove the results from the UI later.
One prompt that worked well in our use case is:
Working around the max token limit of ChatGPT: Answering a question from a set of answers
Since we have more than a single answer to our question now, we can attempt to summarize them into a single response. For this, we will mostly follow the same approach as before, but instead of searching Elasticsearch for the context, we will just concatenate the individual answers we’ve received so far, excluding any where the model responded that it can’t answer it based on the provided context.
Note that the prompt for this run is a little different from the earlier prompt, so the model treats our context slightly differently. The provided prompt here is by no means perfect, and depending on the data, it should be adjusted and optimized further.
With this additional “reduce phase” in place, our app will now:
- Search Elasticsearch for the top 10 hits
- 10x in parallel ask OpenAI to answer the question, providing a different context each time
- Concatenate responses from OpenAI and ask OpenAI once again to answer the question
With this setup, we can use close to 40,000 tokens of context, while only paying for the considerably cheaper GPT-3.5 model. In another blog post, we will explore the cost in more detail and use Elastic APM for tracking our spend, alongside other metrics.
It should be noted that GPT-4 may still perform much better than the approach above, so use whatever works best for you and the amount of traffic you expect.
Citations for your ChatGPT results
One downside of large language models (LLMs) is their overconfidence and tendency to hallucinate. You ask a question, you get an answer. Whether the answer is actually correct is for you to decide. The model rarely admits that it does not know something. Providing the context and telling it to respond with a specific answer as we did above helps mitigates this to some extent.
But the provided context alongside getting the model to admit that it can’t answer a question also allows us to provide more accurate citations for the responses.
In the last section, we summarized our set of 10 answers into one global answer. In addition to just providing this global answer, we can also provide a list of all source documentation pages that we used to compile the result — basically any page where the model did not respond "The provided page does not answer the question."
In this screenshot, you can see the summary answer on a set of 10 results from Elasticsearch. Even though we inspected 10 results, we are only displaying the three links to the documentation that are actually relevant to answer the question. In this case, the other seven documents returned by Elasticsearch had something to do with documents or indices, but they didn’t specifically talk about how to index something.
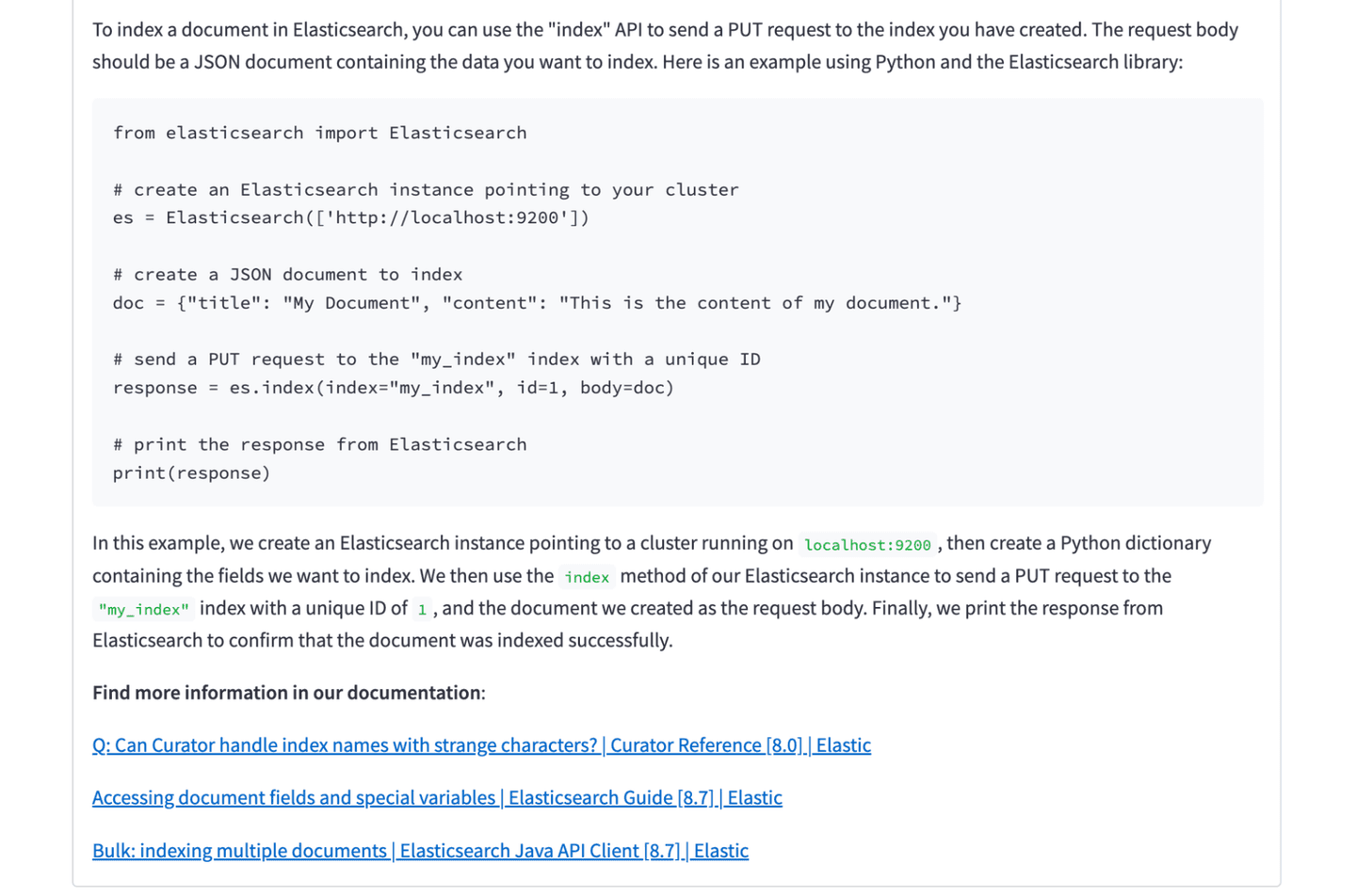
Searching proprietary data
We’ve mentioned in an earlier blog post that it’s great to use Elasticsearch and OpenAI to search proprietary data. However, we did use a web-crawler to crawl public documentation. That may seem a bit counterintuitive, and you’re right to think about it! OpenAI trains GPT models on web data, so we will assume it knows our documentation already. So why do we need Elasticsearch in addition to that data? Does this setup actually work on data that’s not public? It does — let’s prove it.
Using the existing setup, we will push a single super secret document about an internal project into our index.
Next we’ll then head over to our app and search for “What are the steps for the internal project?”
In summary, we used faceting and filtering to, for certain use cases, reduce the number tokens of context required to engage with ChatGPT. By providing additional context at query time, we showed it is also possible to improve the accuracy of search results.
Learn more about the possibilities with Elasticsearch and AI .
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Costs referred to herein are based on the current OpenAI API pricing and how often we call it when loading our sample app.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Frequently Asked Questions
How can ChatGPT and Elasticsearch work together?
ChatGPT and Elasticsearch can work together by leveraging Elasticsearch's search capabilities and ChatGPT's contextual understanding. This can help manage proprietary data more effectively.
What are the advantages of using Elasticsearch's faceting and filtering framework with ChatGPT?
Elasticsearch's faceting and filtering framework allow users to refine their search and reduce the cost of engaging with ChatGPT.
Related Content

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.

January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.