June 16, 2026
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.
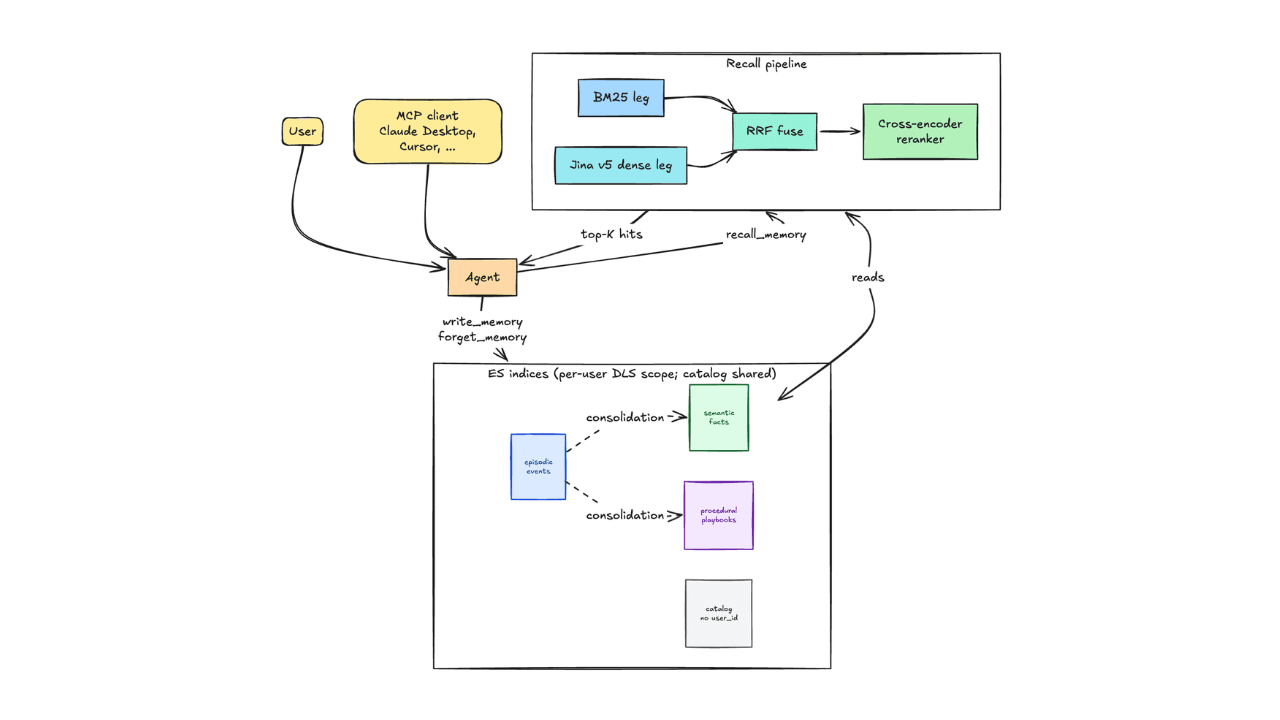
June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.

June 12, 2026
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.

June 12, 2026
Systematic research with LangChain's Deep Agents framework and Elasticsearch
Building a systematic research pipeline using LangChain's Deep Agents framework and Elasticsearch:

June 11, 2026
How Elasticsearch cut metrics storage by 41% by dropping sequence numbers after replication
Find out how Elasticsearch trims sequence numbers at merge time to cut TSDS storage by 41%, what you give up, and why it's safe for metrics workloads.
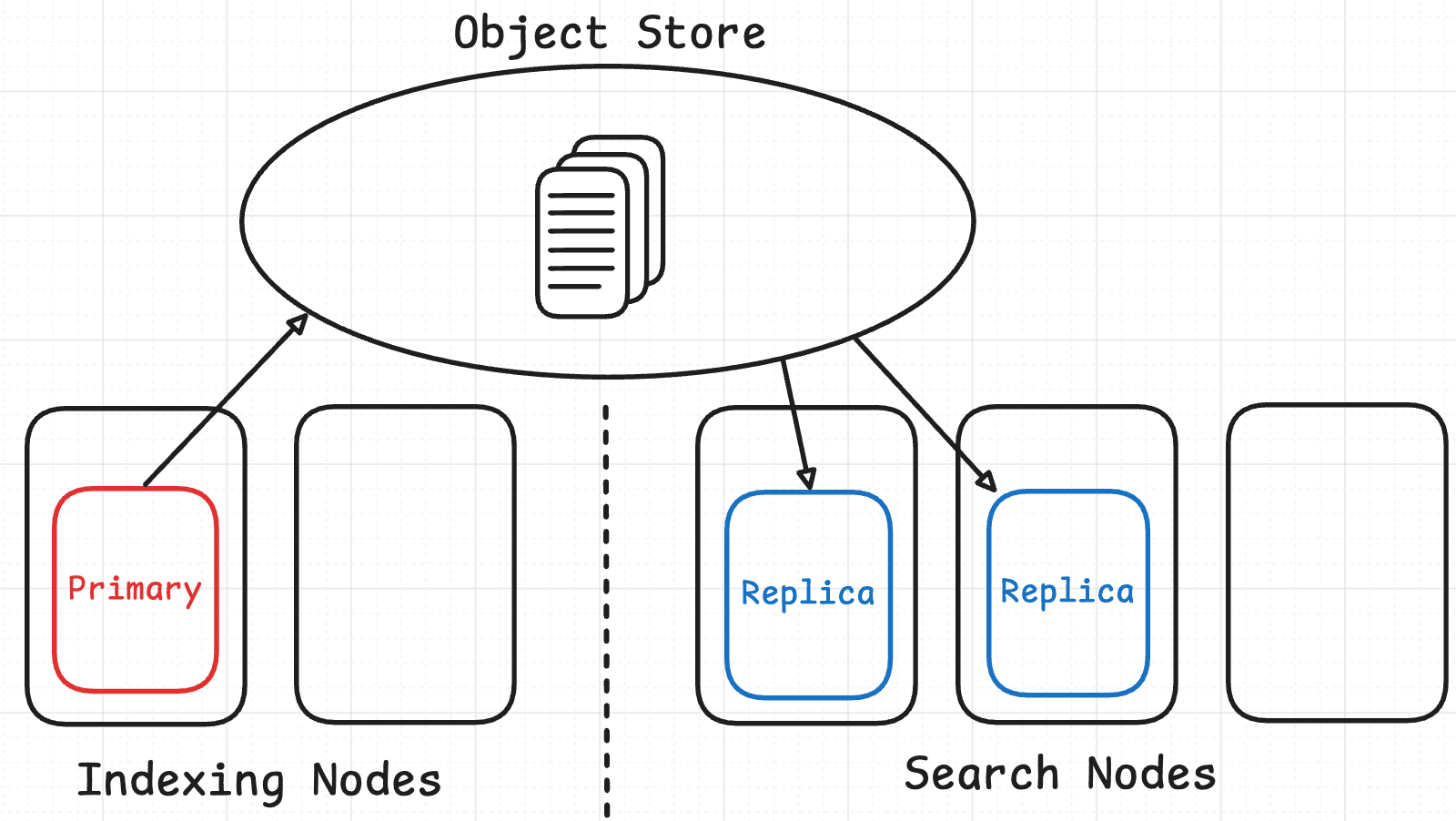
June 11, 2026
Replica management: Inside the system that keeps Elasticsearch Serverless searches fast at scale
A technical walkthrough of how two replica systems (one for failover, one for load balancing) combine every five minutes into a single cache-aware recommendation per index in Elasticsearch Serverless.
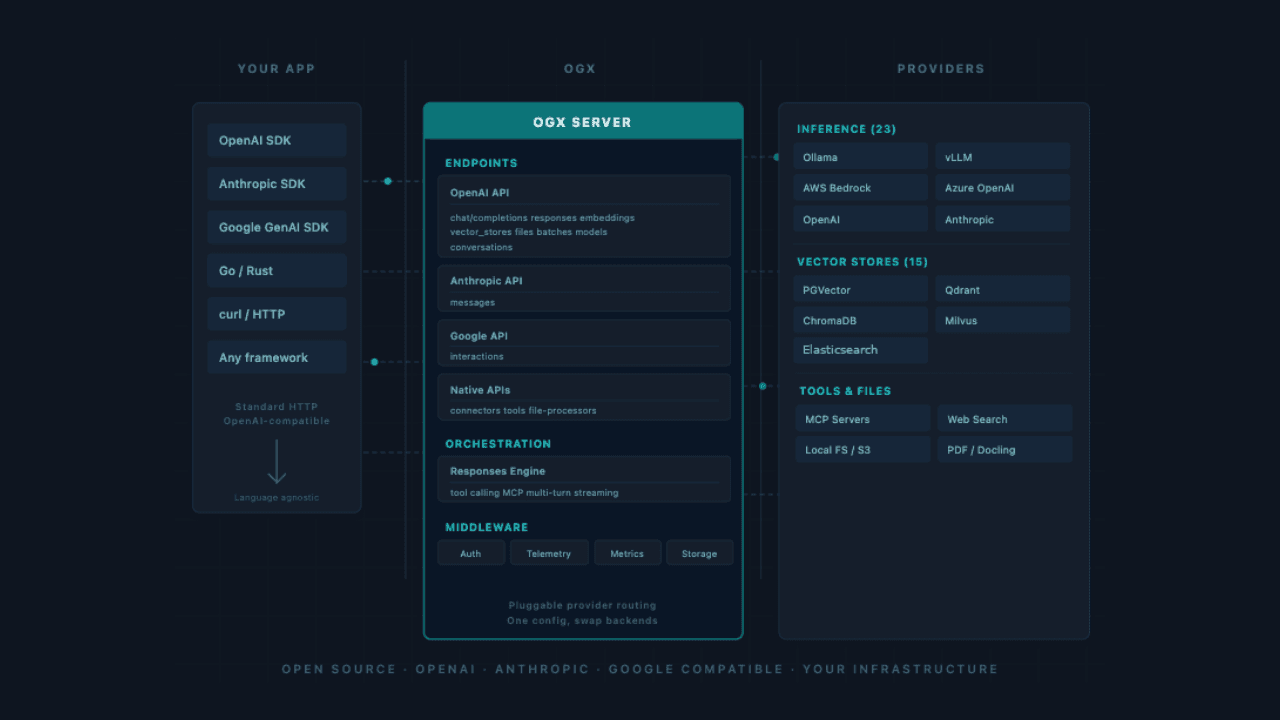
June 10, 2026
Your AI agent reads the fine print: building a RAG pipeline over EU regulations with Elasticsearch and OGX
Learn how to configure Elasticsearch as an OGX vector store, ingest EU regulation PDFs and build a Python RAG agent that runs hybrid BM25 and vector search with source-level citations.

June 9, 2026
Best practices for building a modern app with vector search
Exploring six vector search tips for building modern AI search applications entirely on Elasticsearch, with an opinionated rationale at each architectural decision.