Getting Started with the Elastic Stack on Microsoft Azure
UPDATE: This article refers to our old getting started experience for Elastic on Microsoft Azure. You can now take advantage of a more streamlined way to get started with Elastic on Microsoft Azure. Check out our latest blog to learn more.
We've since published a more expansive blog post on the same topic here.
As cloud adoption grows, we're keeping pace at Elastic, developing integrations and making it easier to use our software wherever you are. These days, a number of our users are using Microsoft Azure for their deployments. For example, you can read about how Collector Bank is using Elastic to search and correlate logs.
Microsoft itself is an Elastic user in its own right. Elasticsearch is used behind the scenes to power the content backend of MSN.com - a Top 50 website, and social network Yammer is using the Elastic Stack to centralize its logs.
There are several ways to run the components of the Elastic Stack (Elasticsearch, Kibana, Logstash, and Beats) - and to ingest data from various applications and Azure components.
Installing Elastic from the Azure Marketplace
The easiest way to get started is to use the official Elastic offering in the Azure Marketplace. We've partnered with Microsoft to create a configurable, UI-driven deployment template that you can use to create an Elasticsearch cluster with a Kibana instance on top.
You can find more information on this in one of our blog posts. And you'll find the template itself in the Azure Marketplace. Let us know at azuremarketplace@elastic.co if you have any questions or feedback.
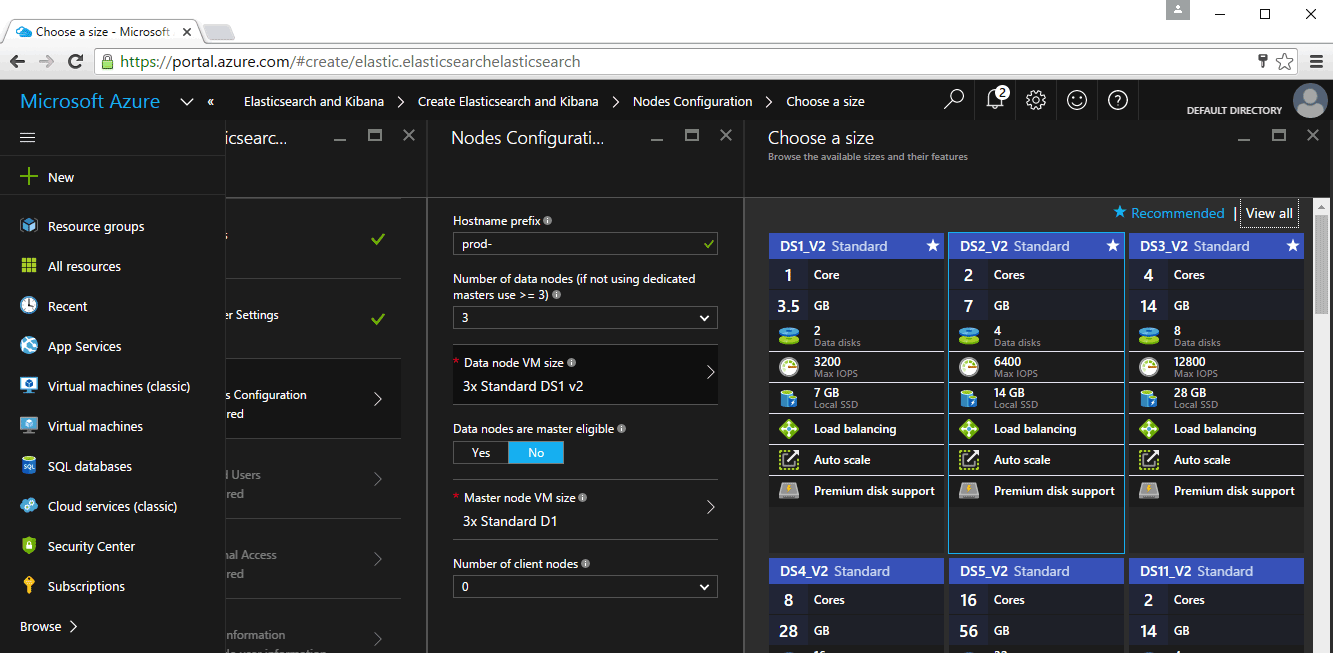
You can also modify the underlying deployment template, or install the Elastic Stack components without using a template at all.
Ingesting Data using Beats and Logstash
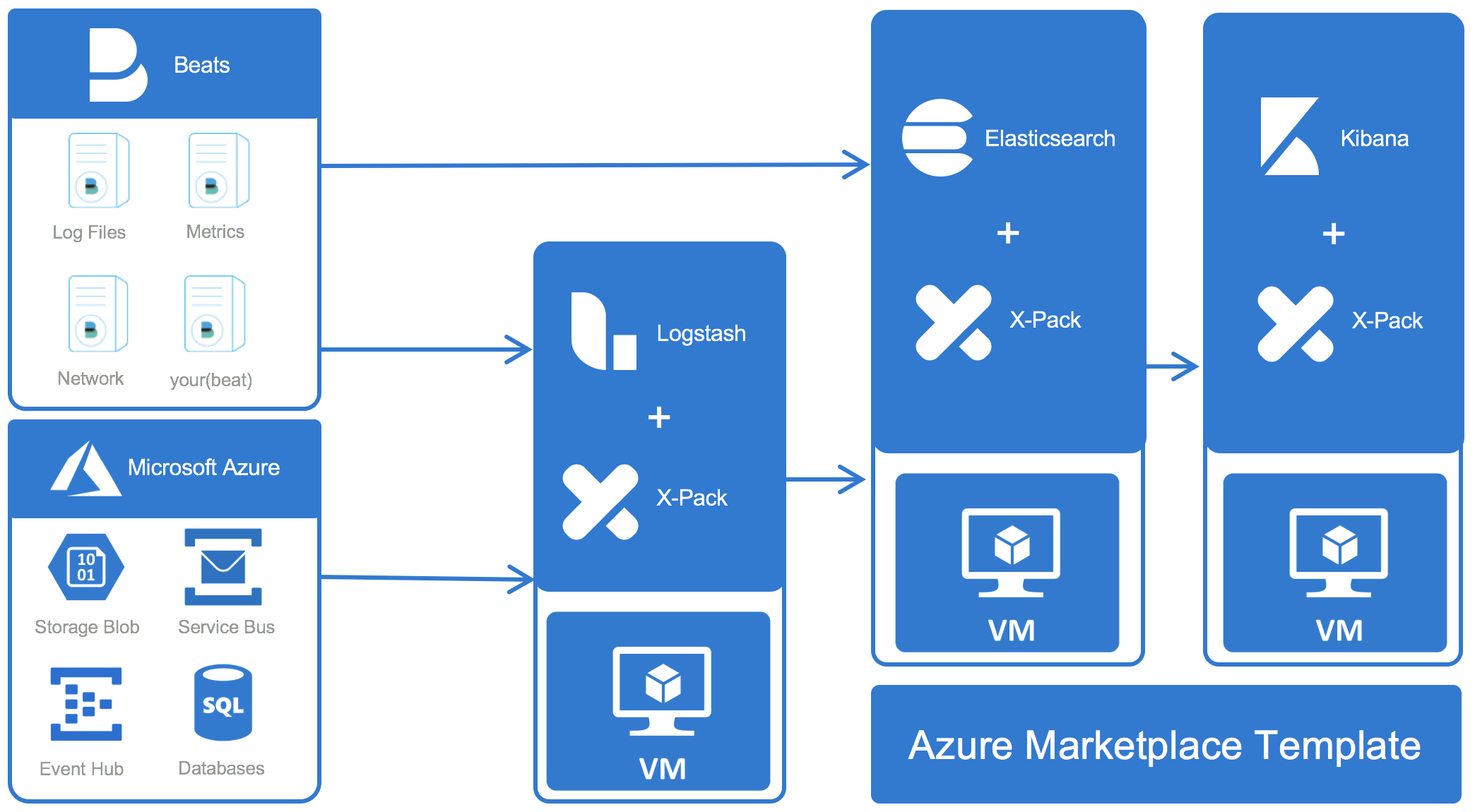
As the primary ingest technologies for the Elastic Stack, you can use both these components to get your data into Elasticsearch on Azure.
Beats is a data collection framework with implementations for many common data types: Log files, system and application metrics, network data, audit logs, or Windows Event data. You can view a list of official Beats here, and a curated list of community-developed Beats here.
All Beats are supported on Linux as well as Windows and come with pre-built configurations including dashboards for common data sources. See the support matrix for details on versions.
Logstash In contrast to the Beats which collect data from the source, Logstash is commonly used to receive data from the Beats for further processing - or to pull data from intermediary systems. Logstash supports a number of data sources, e.g. Syslog, various message queues like Kafka or Redis, and a number of Azure-specific data sources. And, of course, it can receive data from any Beat for further processing and enrichment. See here for a list of input plugins and here for a list of data transformations that are supported out of the box.
Oct 25: Join Us Virtually at Azure OpenDev!
Join us online for the next edition of Azure OpenDev where we will dive deeper into this. This is a live community-focused series of technical demonstrations centered around building open source solutions on Azure.
On October 25, 2017 at 9:00 AM Pacific Time, we will be presenting together with HashiCorp, GitHub, CloudBees, and Chef on how to build a DevOps pipeline and bring an enterprise app to the Azure cloud.