Using classification-based supervised learning in Elasticsearch to curate your movie queue
Classification has been added to machine learning in Elasticsearch 7.6. Unlike anomaly detection, classification is supervised machine learning to predict the class or category of a given data point in a dataset.
There are two types of classification: multi-class and binary classification. For example, multi-class classification predicts which category a movie belongs to, such as action, animation, or comedy. Binary classification predicts whether I like this movie or not. We released the binary classification feature in Elastic Stack 7.6.1 so this blog post will focus on building a model using that capability.
We'll make Elasticsearch learn the characteristics of the movies we liked and disliked, and then ask it to predict whether we’ll like or dislike a movie based on its characteristics.
Create deployment
To create a deployment, you can start a free 14-day free trial of Elasticsearch Service.
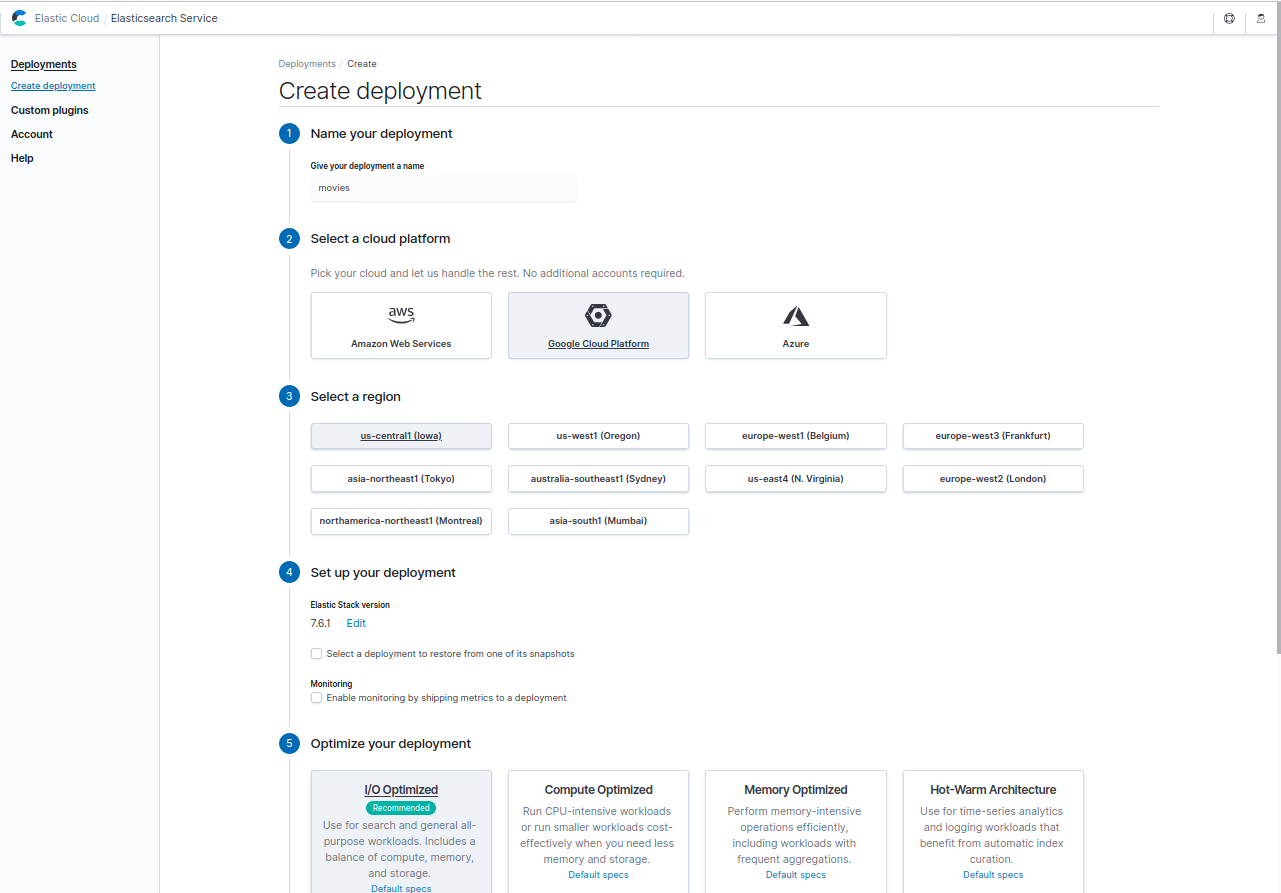
Once your trial is started, go to Elastic Cloud and start a new deployment. We can click the “Customize deployment” button at the bottom of the screen to activate the machine learning node as shown below, then click the “Create deployment” button to create the deployment. You can refer to the Elastic Cloud documentation for the deployment configuration.
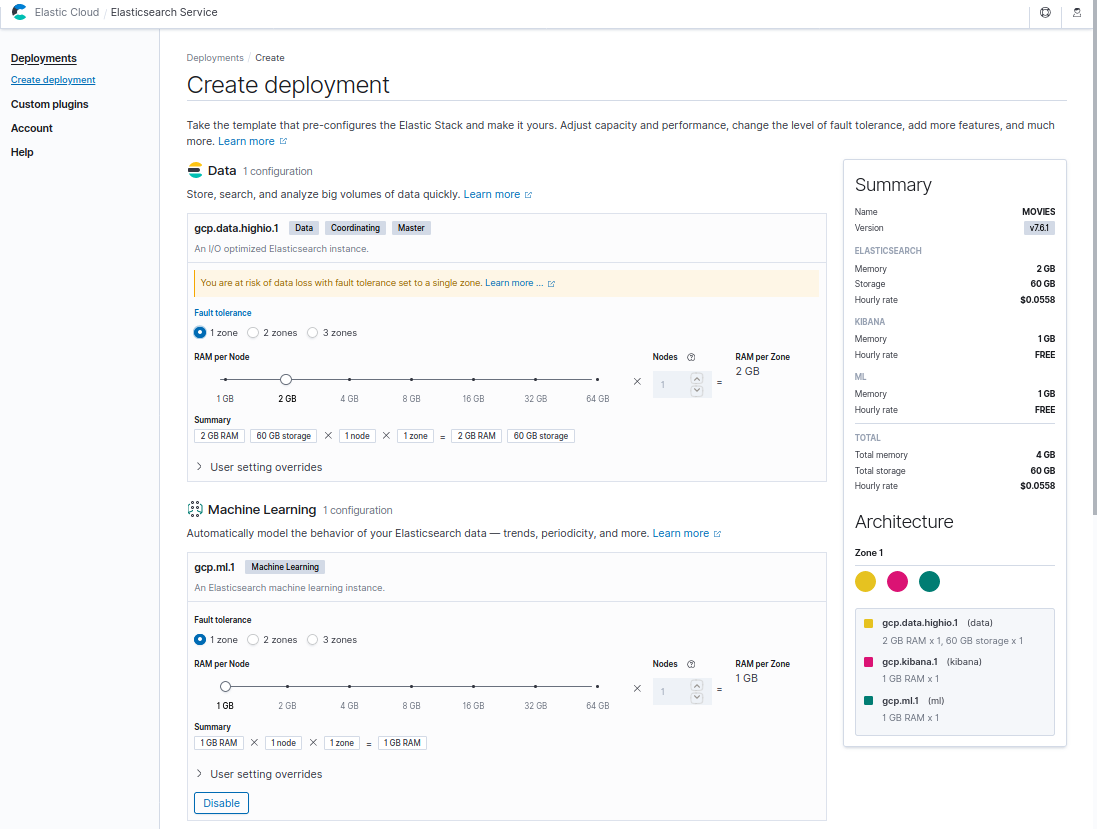
You can see the password while the deployment is being created.
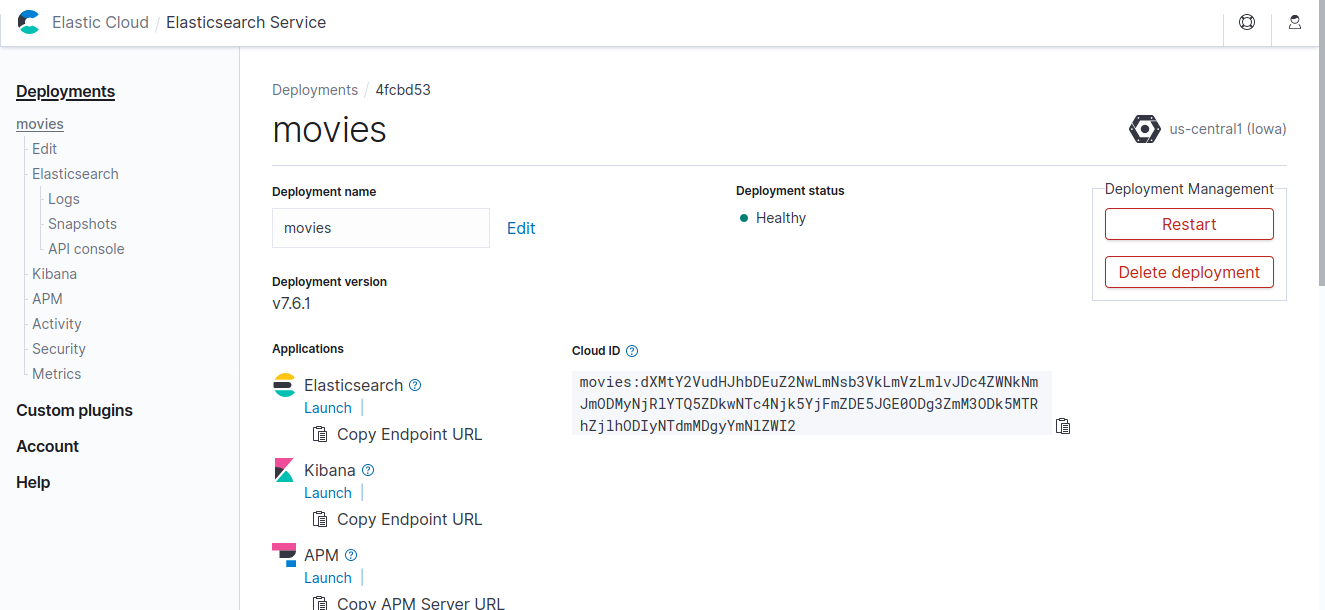
You can see the Cloud ID when the deployment creation completes.
Prepare data
We can download information such as the film title, year of production, country, and genre as an Excel file from the Korean Film Council website (in Korean). We can add the “like” field to show whether we liked it or not (1 if you like, 0 if not), and save it as a csv file (movies.csv). Elasticsearch can learn this data and create a model, and then create a system that predicts whether we will like or not based on the title, year of production, country of production, director, and company of a new movie.
title,year,country,genre,like,director,company Memento,2000,USA,thriller,0,Christopher Nolan, Harry Potter And The Prisoner Of Azkaban,2004,USA,drama,1,Alfonso Cuarón,Warner Bros. …
If we put the field name in the first line, we can ingest into Elasticsearch using the following logstash.conf file. We can set the “cloud_id” field to the Cloud ID from Fig. 4 to, and the “cloud_auth” field to the password from Fig. 3 in the format of “elastic:<Password>”.
We should add "pipeline.workers: 1" in config/logstash.yml because we have "autodetect_column_names => true" in the csv filter.
input {
file {
path => "/home/kiju/github/7/logstash-7.6.1/movies.csv"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
csv {
autodetect_column_names => true
}
}
output {
elasticsearch {
cloud_id => "movies:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDc4ZWNkNmJmODMyNjRlYTQ5ZDkwNTc4Njk5YjFmZDE5JGE0ODg3ZmM3ODk5MTRhZjlhODIyNTdmMDgyYmNlZWI2"
cloud_auth => "elastic:<Password>"
index => "movie2"
}
}
From Kibana Dev Tools, we can define the mapping in Elasticsearch as below:
PUT movie2
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"year": {
"type": "integer"
},
"country": {
"type": "keyword"
},
"genre": {
"type": "keyword"
},
"like": {
"type": "integer"
},
"director": {
"type": "keyword"
},
"company": {
"type": "keyword"
}
}
}
}
And then run Logstash as below:
$ bin/logstash -f logstash.conf
We can see if the data is correctly ingested in Elasticsearch.
GET movie2/_search
=>
{
...
"hits" : {
"total" : {
"value" : 211,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie2",
"_type" : "_doc",
"_id" : "BCqX2HABaohLi7nef_QH",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2020-03-14T10:29:31.761Z",
"genre" : "thriller",
"title" : "Memento",
...
}
},
…
Classification
Now we can run classification from Kibana to generate a model to predict whether we’ll like a movie or not.
We can select “Data Frame Analysis” from the “Machine Learning” menu and click the “Create analytics job” button as shown below. Select “classification” as the job type, and select “like” as the predicted target for the dependent variable. In the excluded fields, we can list fields that are not related to the characteristics of the movies, then click the “Create” button and then the “Start” button to run supervised learning.
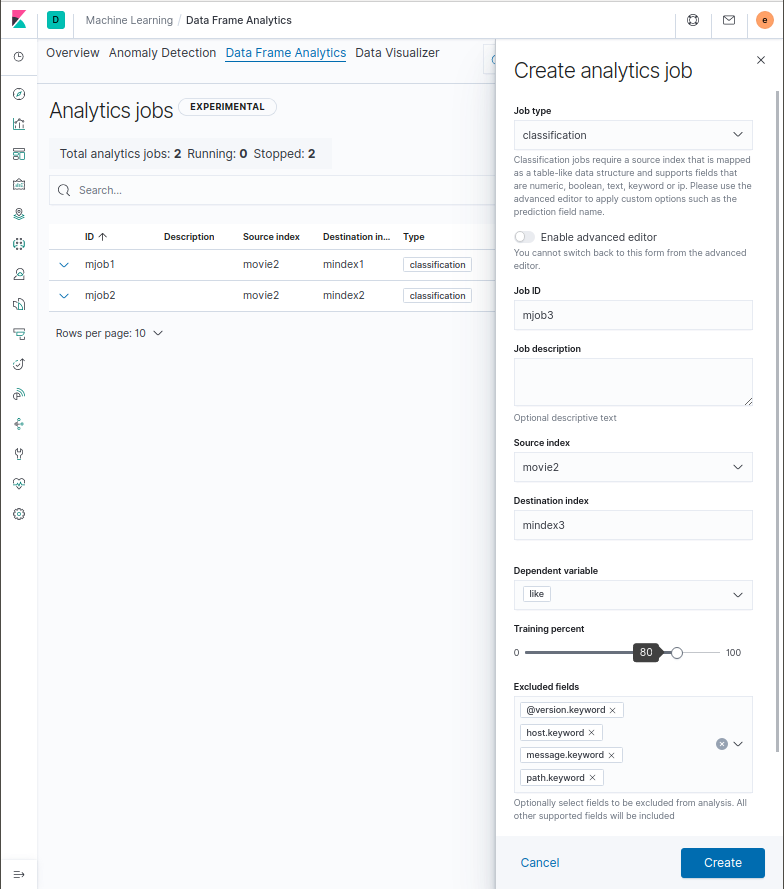
We can click the “Close” button to close the sub-window and use inference to predict whether we’ll like or dislike a movie once the job progress reaches 100%.
Inference
First, we can find the ID of the model created as a result of mjob3 execution using the “GET _ml/inference/_all” command. model_id consists of the job name and the timestamp.
GET _ml/inference/_all
=>
{
...
{
"model_id" : "mjob3-1584187672850",
"created_by" : "_xpack",
"version" : "7.6.1",
"description" : "",
"create_time" : 1584187672850,
"tags" : [
"mjob1"
],
…
Next, we can run the inference processor in an ingest pipeline. If you provide information about the movie in question as a document to the simulate pipeline API, you can see the predicted_value. If it is 1, you are likely to like it.
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "mjob3-1584187672850",
"inference_config": {
"classification": {}
},
"field_mappings": {}
}
}
]
},
"docs": [
{
"_source": {
"title": "Cloud Bread - The Day The Laundry Flew Off In The Wind",
"year": 2010,
"country": "South Korea",
"genre": "animation",
"director": "Jay woon Jang"
}
},
{
"_source": {
"country": "South Korea",
"year": "'2008",
"director": "Han-min Kim",
"title": "Handphone",
"genre": "thriller"
}
}
]
}
=>
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"country" : "South Korea",
"year" : 2010,
"director" : "Jay woon Jang",
"genre" : "animation",
"title" : "Cloud Bread - The Day The Laundry Flew Off In The Wind",
"ml" : {
"inference" : {
"predicted_value" : "1",
"model_id" : "mjob3-1584187672850"
}
...
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"country" : "South Korea",
"year" : "'2008",
"director" : "Han-min Kim",
"genre" : "thriller",
"title" : "Handphone",
"ml" : {
"inference" : {
"predicted_value" : "0",
"model_id" : "mjob3-1584187672850"
}
...
]
}
Outcome
After doing all this, the model says that I am likely to enjoy “Cloud Bread - The Day The Laundry Flew Off In The Wind” and not likely to enjoy "Handphone". Since schools are closed due to COVID-19, I watched “Cloud Bread - The Day The Laundry Flew Off In The Wind” with my kids and really enjoyed it.
Trying it for yourself
So that's how you can predict whether you’ll like a movie you haven't seen with the help of classification. This method can also be used to predict loan risk, detect defects in a car part, or detect cancer in a DNA sequence. I encourage to to try using classification in your own data sets, either locally or in Elastic Cloud.
For reference, the data file (in Korean) and the configuration files I used for testing are available in my GitHub repo.