Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In a previous blog post, we discussed common approaches to information retrieval and introduced the concepts of models and training stages. Here, we will examine benchmark solutions to compare various methods in a fair manner. Note that the task of benchmarking is not straightforward and can lead to misperceptions about how models perform in real-world scenarios.
Historically, comparisons between BM25 and learned retrieval models have been based on limited data sets, or even only on the training data set of these dense models: MSMARCO, which may not provide an accurate representation of the models' performance on your data. Despite this approach being useful for demonstrating how well a dense model performs against BM25 in a specific domain, it does not capture one of BM25's key strengths: its ability to perform well in many domains without the need for supervised fine-tuning. Therefore, it may be considered unfair to compare these two methods using such a specific data set.
The BEIR paper ("BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models," by Takhur et al. 2021) offers to address the issue of evaluating information retrieval methods in a generic setting. The paper proposes a framework using 18 publicly available data sets from a diverse range of topics to benchmark state-of-the-art retrieval systems.
In this post, we use a subcollection of those data sets to benchmark BM25 against two dense models that have been specifically trained for retrieval. Then we will illustrate the potential gain achievable using fine-tuning strategies with one of those dense models. We plan to return to this benchmark in our next blog post, since it forms the basis of the testing we have done to enhance Elasticsearch relevance using language models in a zero-shot setting.
BEIR data sets
Performance can vary greatly between retrieval methods, depending on the type of query, document size, or topic. In order to assess the diversity of data sets and to identify potential blind spots in our benchmarks, a classification algorithm trained to recognize natural questions was used to understand queries typology. The results are summarized in Table 1.

In our benchmarks, we choose not to include MSMARCO to solely emphasize performance in unfamiliar settings. Evaluating a model in a setting that is different from its training data is valuable when the nature of your use case data is unknown or resource constraints prevent adapting the model specifically.
Search relevance metrics
Selecting the appropriate metric is crucial in evaluating a model's ranking ability accurately. Of the various metrics available, three are commonly utilized for search relevance:
- Mean Reciprocal Rank (MRR) is the most straightforward metric. While it is easy to calculate, it only considers the first relevant item in the results list and ignores the possibility that a single query could have multiple relevant documents. In some instances, MRR may suffice, but it is often not precise enough.
- Mean Average Precision (MAP) excels in ranking lists and works well for binary relevance ratings (a document is either relevant or non-relevant). However, in data sets with fine-grained ratings, MAP is not able to distinguish between a highly relevant document and a moderately relevant document. Also, it is only appropriate if the list is reordered since it is not sensitive to order; a search engineer will prefer that the relevant documents appear first.
- Normalized Discounted Cumulative Gain (NDCG) is the most complete metric as it can handle multiple relevant documents and fine-grained document ratings. This is the metric we will examine in this blog and future ones.
All of these metrics are applied to a fixed-sized list of retrieved documents. The list size can vary depending on the task at hand. For example, a preliminary retrieval before a reranking task might consider the top 1000 retrieved documents, while a single-stage retrieval might use a smaller list size to mimic a user's search engine behavior. We have chosen to fix the list size to the top 10 documents, which aligns with our use case.
BM25 and dense models out-of-domain
In our previous blog post, we noted that dense models, due to their training design, are optimized for specific data sets. While they have been shown to perform well on this particular data set, in this section we explore if they maintain their performance when used out-of-domain. To do this, we compare the performance of two state-of-the-art dense retrievers (msmarco-distilbert-base-tas-b and msmarco-roberta-base-ance-fristp) with BM25 in Elasticsearch using the default settings and English analyzer.
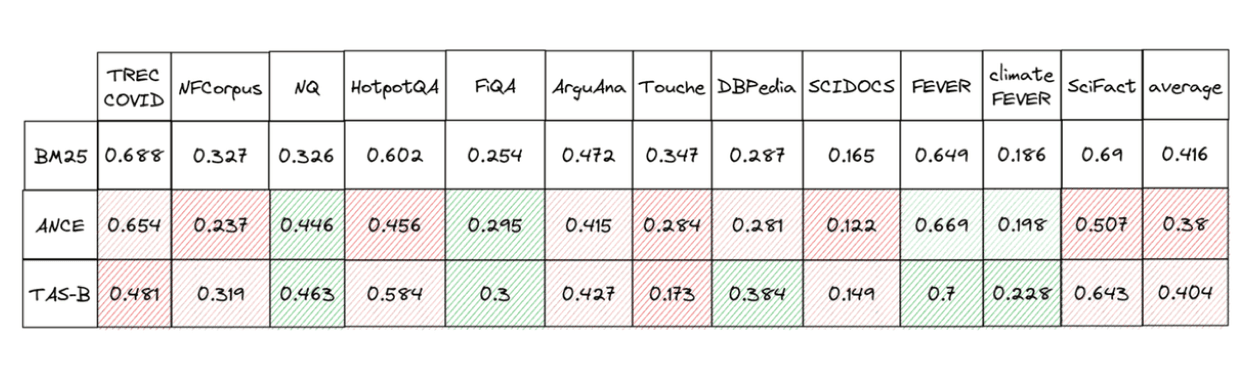
Those two dense models both outperform BM25 on MSMARCO (as seen in the BEIR paper), as they are trained specifically on this data set. However, they are usually worse out-of-domain. In other words, if a model is not well adapted to your specific data, it’s very likely that using kNN and dense models would degrade your retrieval performance in comparison to BM25.
Fine-tuning dense models
The portrayal of dense models in the previous description isn't the full picture. Their performance can be improved by fine-tuning them for a specific use case with some labeled data that represents that use case. If you have a fine-tuned embedding model, the Elastic Stack is a great platform to both run the inference for you and retrieve similar documents using ANN search.
There are various methods for fine-tuning a dense model, some of which are highly sophisticated. However, this blog post won't delve into those methods as it's not the focus. Instead, two methods were tested to gauge the potential improvement that can be achieved with not a lot of domain specific training data. The first method (FineTuned A) involved using labeled positive documents and randomly selecting documents from the corpus as negatives. The second method (FineTuned B) involved using labeled positive documents and using BM25 to identify documents that are similar to the query from BM25's perspective, but aren't labeled as positive. These are referred to as "hard negatives."

Labeling data is probably the most challenging aspect in fine-tuning. Depending on the subject and field, manually tagging positive documents can be expensive and complex. Incomplete labeling can also create problems for hard negatives mining, causing adverse effects on fine-tuning. Finally, changes to the topic or semantic structure in a database over time will reduce retrieval accuracy for fine-tuned models.
Conclusion
We have established a foundation for information retrieval using 13 data sets. The BM25 model performs well in a zero-shot setting and even the most advanced dense models struggle to compete on every data set. These initial benchmarks indicate that current SOTA dense retrieval cannot be used effectively without proper in-domain training. The process of adapting the model requires labeling work, which may not be feasible for users with limited resources.
In our next blog, we will discuss alternative approaches for efficient retrieval systems that do not require the creation of a labeled data set. These solutions will be based on hybrid retrieval methods.
Related Content

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.

January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.

January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.

December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.