Prestar más servicios sin servidor

 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Nos sorprenden constantemente las maneras en que las personas usan Elasticsearch® para resolver sus principales desafíos de datos. Esto se evidencia en las más de 4000 millones de descargas, 70 000 commits, 1800 colaboradores y los comentarios de nuestra comunidad global. El rol de Elastic® en una amplia variedad de casos de uso nos ha llevado a simplificar complejidades haciendo que sea más fácil aprovechar la búsqueda y todas nuestras soluciones. Por eso nos entusiasma ampliar las posibilidades de Elasticsearch con una nueva arquitectura sin servidor. Optimiza responsabilidades operativas, amplía el rendimiento a alta velocidad reconocido de Elasticsearch a almacenes de objetos escalables y optimiza los flujos de trabajo con experiencias de producto diseñadas específicamente para búsqueda, observabilidad y seguridad. Es una nueva forma de usar Elastic junto con nuestros despliegues en Elastic Cloud y en las instalaciones existentes.
Solo trae tus datos y las opciones sin servidor se encargarán del resto
Si pensamos en la próxima década, reconocemos la necesidad de una experiencia de usuario más simple que siga brindando un rendimiento ultrarrápido. Sabemos que muchos usuarios de Elastic quieren tener el control total para desplegar y escalar, pero otros desean mayor simpleza. Los analistas de SOC quieren proteger sus organizaciones, no escalar shards para una mejor detección de amenazas. Los desarrolladores desean crear aplicaciones de búsqueda, no ajustar la infraestructura para búsqueda más rápida. Los SRE quieren garantizar la confiabilidad en línea, no realizar configuraciones para ayudar a minimizar el tiempo de inactividad. Nos encanta gestionar clusters, pero tú no tienes que hacerlo. La arquitectura sin servidor de Elastic elimina la responsabilidad operativa, así que puedes despedirte de gestionar clusters, configurar shards, escalar y configurar ILM. Solo trae tus datos y búsquedas, y la plataforma se encarga de todo el escalado y la gestión.
¿Estás cansado de escuchar que no puedes tener escalabilidad más rápida con períodos de retención de datos más prolongados y balancear los costos además de disminuir la complejidad? Bueno, ahora puedes. En muchas cargas de trabajo, tanto la escala como la velocidad importan; ya sea para investigar amenazas como SolarWinds (que tienen un tiempo de permanencia prolongado), identificar la causa raíz de una interrupción de servicio en cientos de servicios o usar labúsqueda de vectores para impulsar cargas de AI generativa con generación aumentada de recuperación.
Por eso nuestra arquitectura sin servidor se basa en un Elasticsearch rediseñado y repensado, que desacopla por completo el procesamiento del almacenamiento y se basa en el almacenamiento de objetos. Los almacenes de objetos en el cloud ofrecen escalabilidad rentable, pero introducen latencia, lo que requiere nuevas técnicas para lograr velocidad. Afortunadamente, nuestra experiencia de años en optimizar las estructuras de datos de índice de Elasticsearch y Lucene para almacenamiento en caché eficiente, junto con la paralelización mejorada del tiempo de búsqueda, superan este desafío de latencia. Esto significa que puedes disfrutar tanto de velocidad como de escala con los controles integrados para balancear con facilidad la velocidad y el costo.
Una nueva arquitectura de Elastic para lo que viene
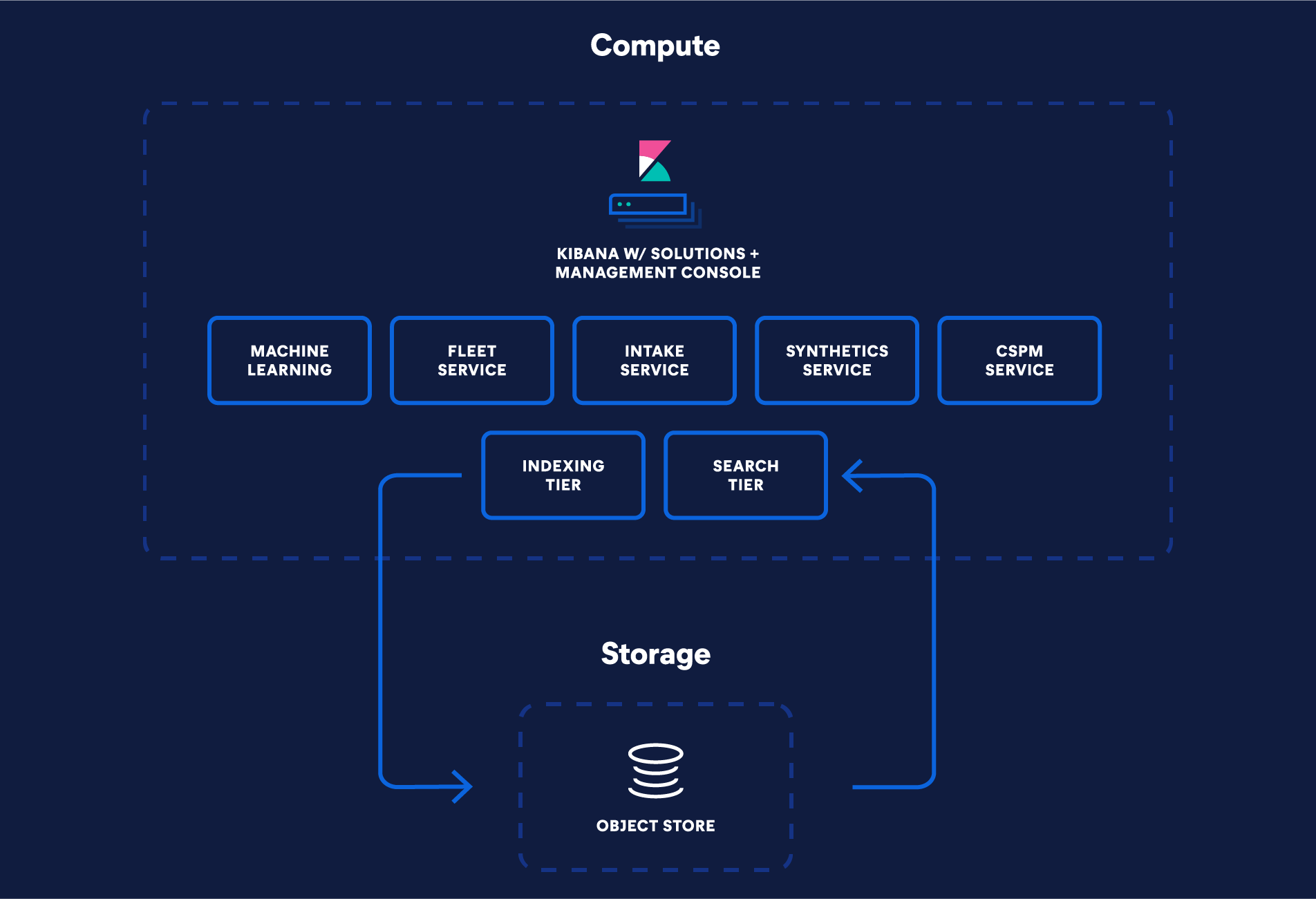
La nueva arquitectura sin servidor de Elastic marca un importante rediseño de Elasticsearch. Se creó para aprovechar los servicios más recientes nativos del cloud y brindar experiencias de producto optimizadas con administración sin inconvenientes. Brinda la capacidad de almacenamiento de un lago de datos, pero con el rendimiento de búsqueda rápido sinónimo de Elasticsearch y la simpleza operativa con escala y gestión de clusters sin intervención. La arquitectura se asienta sobre cuatro principios clave:
- Procesamiento y almacenamiento desacoplados
- Niveles separados de búsqueda e indexación
- Almacenamiento de objetos económico como sistema de registro
- Búsqueda de baja latencia
Almacenamiento y procesamiento completamente desacoplados
Para optimizar la topología de los clusters, el procesamiento y el almacenamiento ahora están completamente desacoplados. Elasticsearch ofrece en la actualidad varios niveles de datos (caliente, tibio, frío y congelado) para alinearse mejor con los requisitos de hardware. En la arquitectura sin servidor, desacoplar el almacenamiento y el procesamiento hace que la división de datos en niveles sea obsoleta, lo cual lleva a una operación más simple. Por ejemplo, la opción sin servidor combina los niveles caliente y congelado: los índices del nivel congelado pueden almacenar grandes volúmenes de datos en los que se busca con menos frecuencia, pero de modo similar al nivel caliente, estos datos pueden actualizarse y consultarse de manera rápida en todo momento.
Además, existen controles simples para balancear el rendimiento de la búsqueda y los costos de almacenamiento de manera eficiente. Esto proporciona soporte para escalar independientemente cualquier carga de trabajo de forma rápida y confiable sin comprometer el rendimiento.
Separar niveles de indexación y búsqueda
En lugar de depender de instancias primarias y réplicas para gestionar varias cargas de trabajo, la arquitectura sin servidor de Elastic brinda soporte a distintos niveles de indexación y búsqueda. Esta separación significa que las cargas de trabajo pueden escalarse de manera independiente y que el hardware se puede seleccionar y optimizar para cada caso de uso.
Además, este enfoque aborda efectivamente el problema persistente de cargas de trabajo de búsqueda e indexación que interfieren entre sí. Esto hace que sea más sencillo optimizar tanto el rendimiento como el gasto para cualquier carga de trabajo o caso de uso de búsqueda. Esta propiedad es importante para los usuarios de seguridad y logging de alto volumen que desean evitar que las búsquedas intensivas interrumpan las operaciones de indexación y para los usuarios de búsqueda que desean usar características de tiempo de indexación intensivas para un mejor rendimiento de búsqueda y relevancia sin afectar su rendimiento de búsqueda.
Almacenamiento de objetos a un costo accesible
La arquitectura sin servidor depende de un almacenamiento de objetos económico para alcanzar una mayor escala y reducir los costos de almacenamiento. Gracias a que aprovecha el almacenamiento de objetos para la persistencia, Elasticsearch ya no necesita replicar las operaciones de indexación en una o más réplicas para la durabilidad, y de este modo reduce los costos de indexación y la duplicación de datos. En cambio, los segmentos persisten y se replican a través del almacenamiento de objetos. Esto genera eficiencia en varios requisitos. Por ejemplo, reduce los gastos de almacenamiento correspondientes al nivel de indexación minimizando los datos almacenados en discos locales. La arquitectura sin servidor indexa directamente en el almacén de objetos, por lo que solo una fracción se retiene como datos locales. En los casos que involucran operaciones de solo anexado, solo es necesario preservar metadatos específicos para indexación, lo que lleva a una importante reducción del almacenamiento local necesario para fines de indexación.
Búsquedas de baja latencia a escala
Los almacenes de objetos pueden brindar soporte a enormes cantidades de datos, pero no son conocidos por la velocidad ni la baja latencia. Entonces, ¿cómo Elastic usa almacenamiento de objetos y mantiene un excelente rendimiento de búsqueda? Bueno, introdujimos varias capacidades nuevas para brindar rendimiento rápido. La paralelización de búsqueda a nivel del segmento reduce la latencia al recuperar datos del almacén de objetos. Esto permite que más solicitudes se envíen rápidamente a los almacenes de objetos como S3 cuando los datos no están en la memoria caché local. El almacenamiento en caché también es "más inteligente" gracias a la capacidad para volver a usarla y al aprovechamiento de los formatos de índice óptimos de Lucene para cada tipo de datos. Estas son solo algunas de las capacidades nuevas que dan como resultado mejoras importantes de rendimiento tanto en el almacén de objetos como en las capas de caché.
Trabajar de forma más inteligente con productos diseñados específicamente en la opción sin servidor
También aprovechamos esta oportunidad a fin de crear productos personalizados para la arquitectura sin servidor para búsqueda, observabilidad y seguridad. El objetivo es optimizar conforme a las necesidades únicas de cada flujo de trabajo con una experiencia de usuario optimizada. Esto incluye la incorporación continua y más rápida, una mejor integración de las capacidades y la optimización de interfaces personalizadas para el trabajo de cada caso de uso. Algunos aspectos destacados de cada producto que vale la pena mencionar incluyen los siguientes:
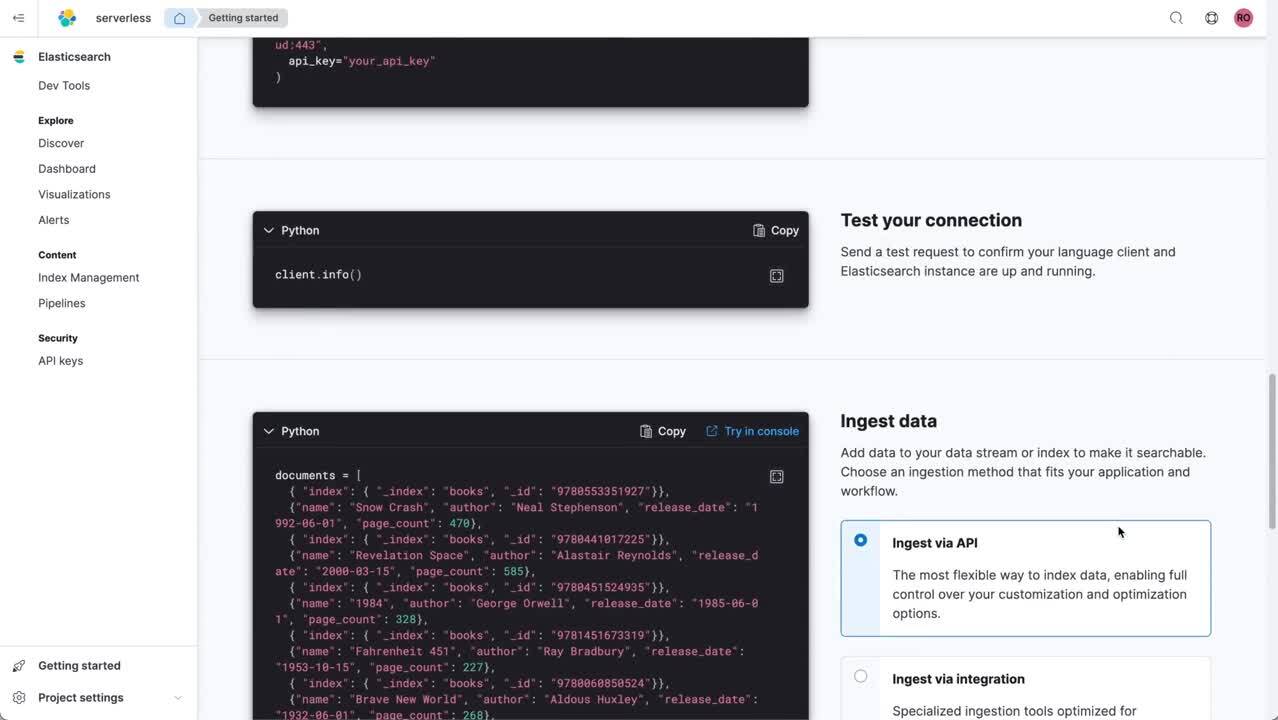
- Búsqueda: la experiencia de búsqueda sin servidor se enfoca en asegurarse de que los desarrolladores puedan crear experiencias de búsqueda excepcionales de fábrica, rápido y fácil. Las API son protagonistas, junto con las formas sencillas de ingestar e ingresar datos en Elastic. Estos pipelines se simplificaron para permitir que la transformación y otras tareas se completen rápido. Los nuevos clientes de lenguaje, como Java, .NET, Python y otros, se crearon para reducir la curva de aprendizaje inicial y los pasos necesarios para completar tareas, junto con la documentación integrada; lo que colectivamente crea una experiencia de desarrollador optimizada que ayuda a los desarrolladores a obtener valor más rápido.
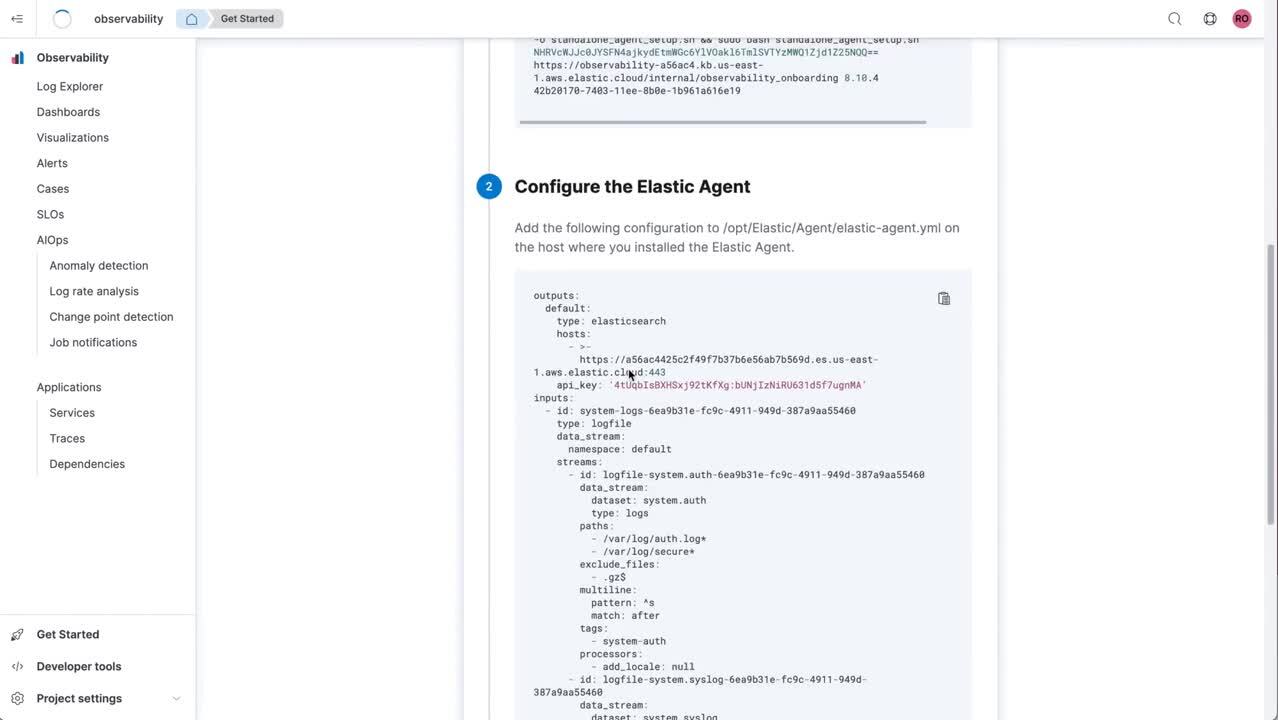
- Observabilidad: la observabilidad en la opción sin servidor permite a los ingenieros de confiabilidad del sitio enfocarse en lo que es importante para ellos, que es garantizar la confiabilidad de sus sistemas y aplicaciones. El tiempo de creación de valor es un principio clave, dados los logs optimizados que incorporan experiencias y simplifican el proceso de ingesta de datos, y el machine learning/las AIOps que ayudan a los SRE a identificar rápidamente comportamiento anómalo y llegar pronto a la causa raíz. Un componente clave es el nuevo servicio de ingesta gestionado, que hace que sea sencillo aceptar, procesar e indexar datos de OpenTelemetry y Elastic APM. Los servicios están creados a partir de una arquitectura de usuarios múltiples que escala automáticamente a fin de cumplir con las necesidades de la observabilidad moderna nativa del cloud y gestionada en su totalidad para garantizar siempre la confiabilidad y resiliencia.
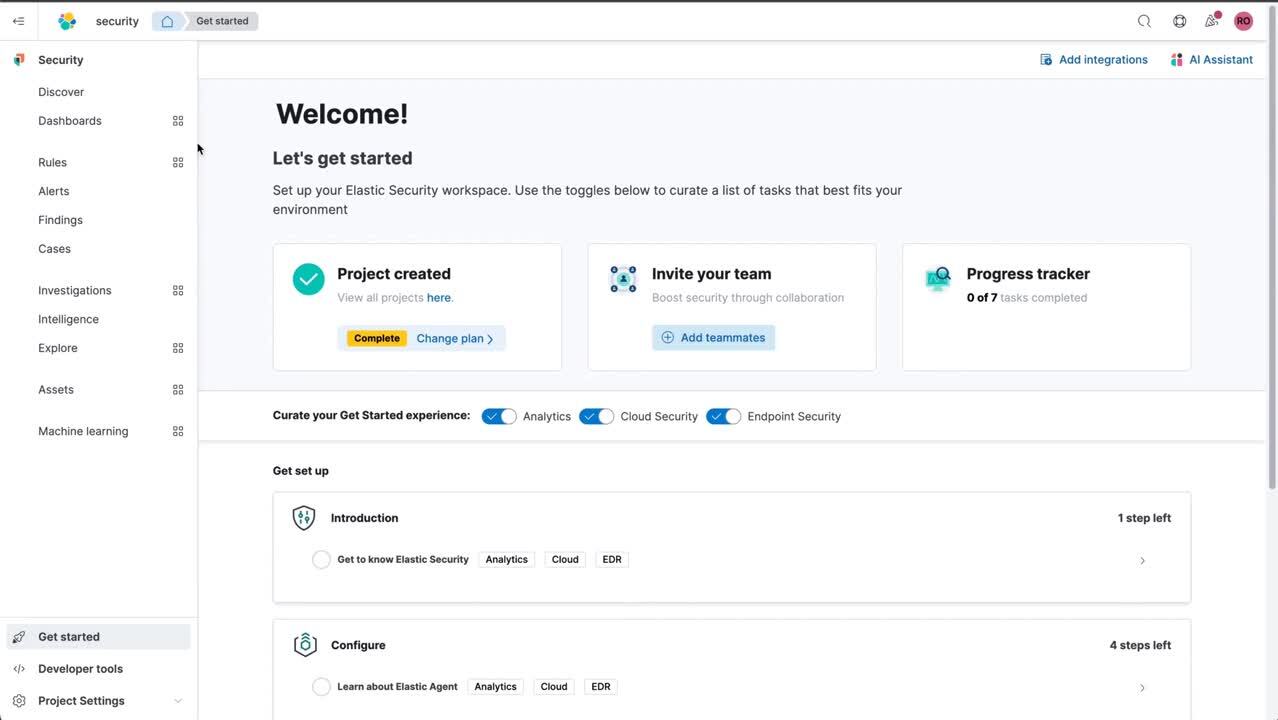
- Seguridad: la seguridad en la opción sin servidor gira en torno a una nueva incorporación continua que guía a los usuarios en la ingesta de logs de seguridad, la visualización de dashboards, la habilitación de reglas de detección y la investigación de alertas. Un "rastreador de progreso" integrado se personaliza para optimizar los casos de uso específicos, incluida la analítica de seguridad/SIEM, la seguridad de endpoint y la seguridad en el cloud. Una navegación enfocada en la seguridad mantiene todas las funciones relacionadas con la seguridad al alcance de la mano. Las capacidades de machine learning de Elastic Security se habilitan en cada proyecto de seguridad. Por ejemplo, la detección de anomalías basada en ML está disponible para su uso en las reglas de detección automáticas o para la búsqueda de amenazas basada en hipótesis. La investigación y exploración tanto ad-hoc como curada se proporciona para todos los datos ingestados.
Haznos saber si deseas probarla
Además de nuestras opciones de despliegue existentes, los productos y la arquitectura sin servidor de Elastic crean una base para un futuro de cargas de trabajo de procesamiento y datos complejas que brindan búsqueda ultrarrápidas incluso en grandes cantidades de datos históricos; todo esto al tiempo que ofrece la forma más sencilla de disfrutar todas las innovaciones de Elasticsearch para la búsqueda, observabilidad y seguridad. Cumple con la visión de simpleza, rendimiento y escala que brinda lo siguiente:
- Experiencias de producto diseñadas específicamente: trabaja más rápido con productos creados a medida optimizados para la búsqueda, seguridad y observabilidad.
- Operaciones sin inconvenientes: libérate de la responsabilidad operativa; no es necesario gestionar una infraestructura de backend, planificar la capacidad, actualizar ni escalar datos.
- Arquitectura desacoplada escalable: escala cargas de trabajo de forma automática, confiable e independiente. Responde en tiempo real a los cambios en la demanda, minimiza la latencia y asegura la respuesta más rápida.
- Desarrolla y entrega, rápido: da los primeros pasos al instante y crece con un almacenamiento de objetos rápido y a un costo accesible para buscar en los datos a largo plazo. Escala con facilidad gracias a los controles para gestionar el rendimiento y el gasto.
Conviértete en parte de nuestra visión sin servidores y pruébala antes que todos; presenta tu solicitud ahora para obtener acceso temprano.
El lanzamiento y el plazo de cualquier característica o funcionalidad descrita en este blog quedan a la entera discreción de Elastic. Cualquier característica o funcionalidad que no esté disponible actualmente puede no entregarse a tiempo o no entregarse en absoluto.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime