Crawl web content
editCrawl web content
editThe Elastic Enterprise Search web crawler is a beta feature. Beta features are subject to change and are not covered by the support SLA of general release (GA) features. Elastic plans to promote this feature to GA in a future release.
Complete the following steps to crawl your web content using the Enterprise Search web crawler.
1. Identify your web content and create engines:
2. For each engine, complete the first crawl cycle:
3. Re-crawl your web content and optionally schedule crawls:
Identify web content
editBefore crawling your web content, you must inventory your domains and decide which you’d like to crawl and where you’d like to store the crawled documents. Consider an organization managing the following web content:
| Content type | URL |
|---|---|
Website |
|
Blog |
|
Ecommerce application |
|
Ecommerce administrative dashboard |
|
This organization may decide to index their website and blog using the web crawler, while using the Documents API to index their ecommerce data.
Complete this exercise with your own content to determine which domains you’d like to crawl. If you haven’t already, read the Web crawler (beta) FAQ to evaluate the crawler’s capabilities and limitations.
After choosing domains to crawl, decide where you will store the resulting search documents. Consider another organization with the following web content.
| Content type | URL |
|---|---|
Website |
|
Blog |
|
Although their website and blog are separate domains, they may choose to index them into a single engine.
Again, complete this exercise with your own content. Choose one engine per search experience. Each engine has its own crawl configuration, and is limited to a single active crawl.
Create engine
editAfter reviewing Identify web content, create one or more new engines for your content. See Create an engine for an explanation of the process.
The following sections of this document describe a crawl cycle composed of the following steps: manage, monitor, troubleshoot. Repeat this cycle for each new engine.
Manage crawl
editA crawl is the process by which the web crawler discovers, extracts, and indexes web content into an engine. See Crawl in the web crawler reference for a detailed explanation of a crawl.
Primarily, you manage each crawl in the App Search dashboard. There, you manage domains, entry points, and crawl rules; and start and cancel the active crawl. However, you can also manage a crawl by embedding instructions within your content, such as canonical URL link tags, robots meta tags, and nofollow links. You can also start and cancel a crawl using the App Search API.
The following sections cover these topics.
Manage domains
editA domain is a website or property you’d like to crawl. You must associate one or more domains to a crawl. See Domain in the web crawler reference for a detailed explanation of a domain.
Manage the domains for a crawl through the web crawler dashboard. From the engine menu, choose Web Crawler.
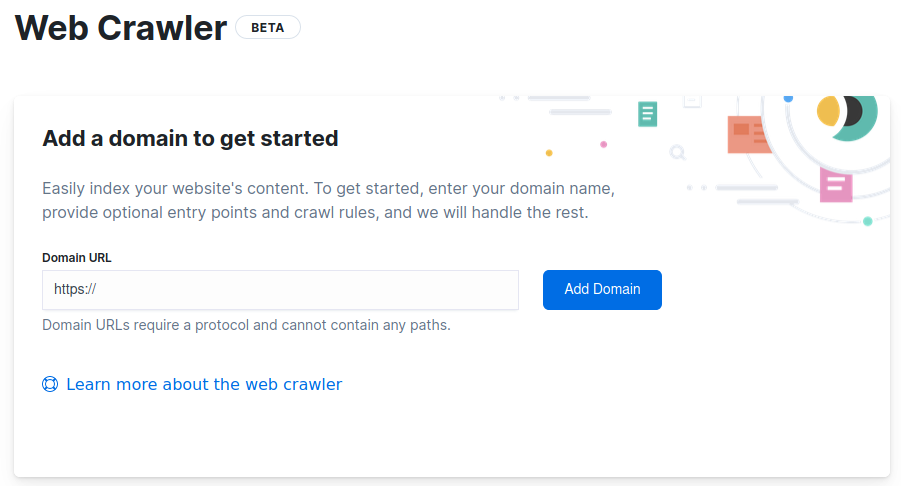
Add your first domain on the getting started screen.
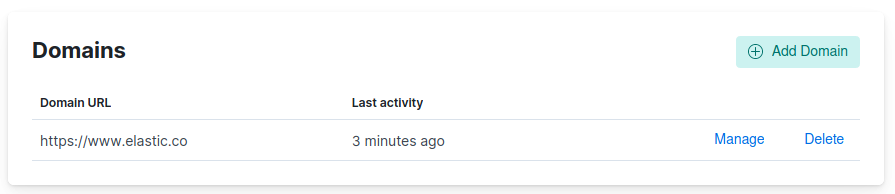
From there, you can view, add, manage, and delete domains using the web crawler dashboard.
Manage entry points
editEach domain must have one or more entry points. These are paths from which the crawler will start each crawl. See Entry point in the web crawler reference for a detailed explanation of an entry point.
Manage the entry points for a domain through the domain dashboard. From the engine menu, choose Web Crawler. Choose Manage next to the domain you’d like to manage. Then locate the Entry Points section of the dashboard.
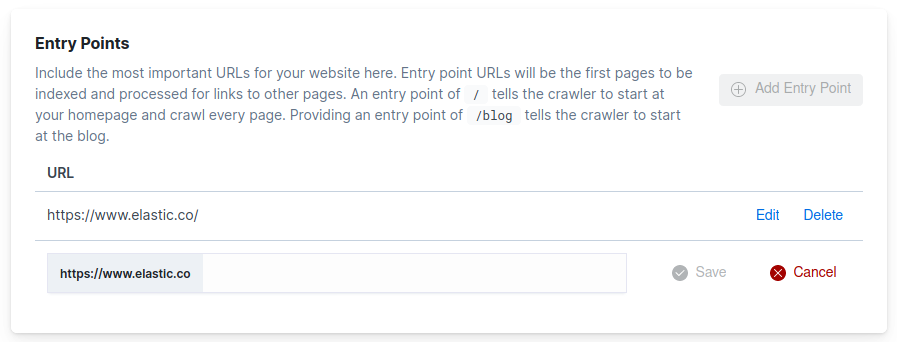
From here, you can view, add, edit, and delete entry points.
The dashboard adds a default entry point of / to each domain.
You can delete this entry point, but each domain must have at least one entry point.
Manage crawl rules
editEach domain must also have one or more crawl rules. These rules instruct the crawler which pages to crawl within the domain. See Crawl rule in the web crawler reference for a detailed explanation of a crawl rule.
Manage the crawl rules for a domain through the domain dashboard. From the engine menu, choose Web Crawler. Choose Manage next to the domain you’d like to manage. Then locate the Crawl Rules section of the dashboard.
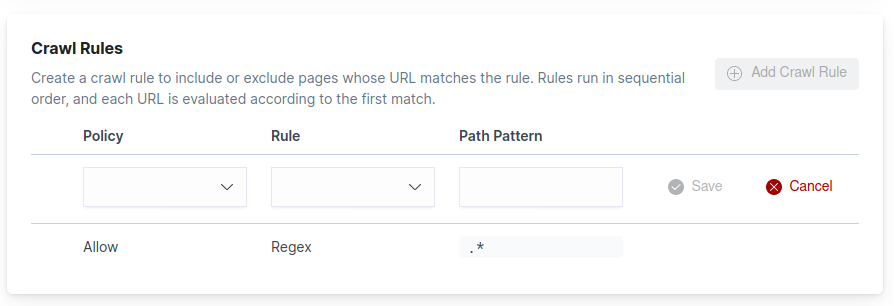
From here, you can view, add, edit, delete, and re-order crawl rules.
The dashboard adds a default crawl rule to allow all paths. You cannot delete this crawl rule, but you can insert more restrictive rules in front of this rule. See Crawl rule for explanations of crawl rule logic and the effects of crawl rule order.
Embed web crawler instructions within content
editYou can also embed instructions for the web crawler within your HTML content. These instructions are specific HTML tags, attributes, and values that affect the web crawler’s behavior.
The Enterprise Search web crawler recognizes the following embedded instructions, each of which is described further in the web crawler reference:
Start crawl
editStart a crawl from the web crawler or domain dashboard, or using the App Search API.
To use a dashboard, navigate to Web Crawler, then optionally choose a domain to manage. Choose the Start a Crawl button at the top of the dashboard.

Each engine may have only one active crawl. The start button changes state to reflect a crawl is in progress.

To start a crawl programatically, refer to the following API reference:
Cancel crawl
editCancel an active crawl from the web crawler or domain dashboard, or using the App Search API.
To use a dashboard, navigate to Web Crawler, then optionally choose a domain to manage. Expand the Crawling… button at the top of the dashboard. Choose Cancel Crawl.
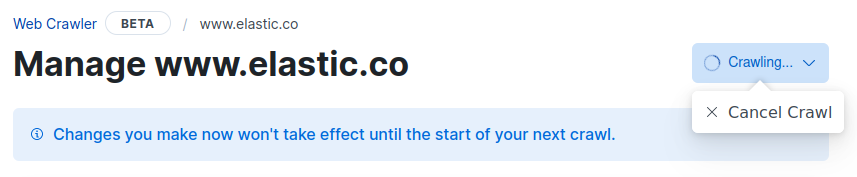
To cancel a crawl programatically, refer to the following API reference:
Due to a known issue in Enterprise Search 7.11.0, you cannot cancel a crawl while the crawl is running its Content deletion phase.
Monitor crawl
editYou can monitor a crawl while it is running or audit the crawl after it has completed.
Monitoring includes viewing the crawl status, crawl request ID, web crawler event logs (optionally filtered by the crawl ID and a specific URL), web crawler system logs, and documents indexed by the crawl.
The following sections cover these topics.
View crawl status
editEach crawl has a status, which quickly communicates its state. See Crawl status in the web crawler reference for a description of each crawl status.
View the status of a crawl within the web crawler dashboard or using the App Search API.
To use the dashboard, navigate to Web Crawler and locate the Recent crawl requests section.
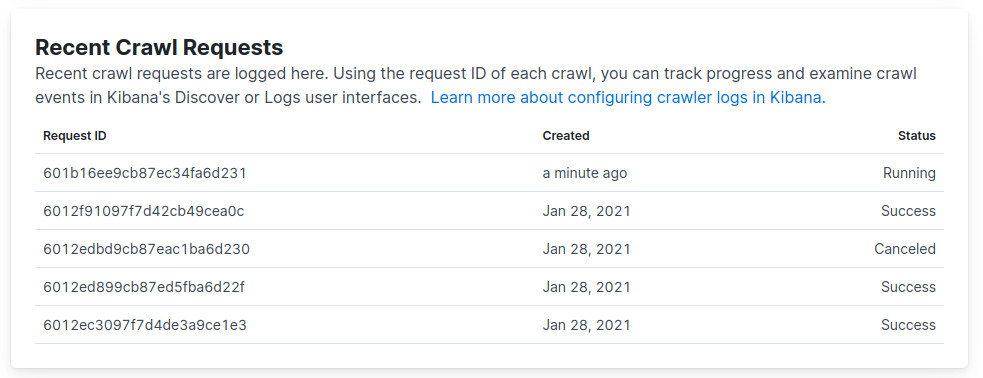
Refer to the Status column for the status of each recent crawl.
To get a crawl status programatically, refer to the following API references:
View crawl request ID
editEach crawl has an associated crawl request, which is identified by a unique ID in the following format: 60106315beae67d49a8e787d.
Use a crawl request ID to filter the web crawler events logs to a specific crawl.
View the request ID of a crawl within the web crawler dashboard or using the App Search API.
To use the dashboard, navigate to Web Crawler and locate the Recent crawl requests section.
Refer to the Request ID column for the request ID of each recent crawl.
To get a crawl request ID programatically, refer to the following API references:
View web crawler events logs
editThe Enterprise Search web crawler records detailed structured events logs for each crawl. The crawler indexes these logs into Elasticsearch, and you can view the logs using Kibana.
See View web crawler events logs for a step by step process to view the web crawler events logs in Kibana.
View web crawler events by crawl ID and URL
editTo monitor a specific crawl or a specific domain, you must filter the web crawler events logs within Kibana.
To view the events for a specific crawl, first get the crawl’s request ID.
Then filter within Kibana on the crawler.crawl.id field.
You can filter further to narrow your results to a specific URL. Use the following fields:
-
The full URL:
url.full -
Required components of the URL:
url.scheme,url.domain,url.port,url.path -
Optional components of the URL:
url.query,url.fragment,url.username,url.password
View web crawler system logs
editIf you are managing your own Enterprise Search deployment, you can also view the web crawler system logs.
View these logs on disk in the crawler.log file.
The events in these logs are less verbose then the web crawler events logs, but they can help solve web crawler issues. Each event has a crawl request ID, which allows you to analyze the logs for a specific crawl.
View indexed documents
editThe web crawler extracts the content from each web page, transforming it into a search document. It indexes these documents within the engine associated with the crawl. See Content extraction and indexing for more details on this process, and see Web crawler schema for more details on the structure of each search document.
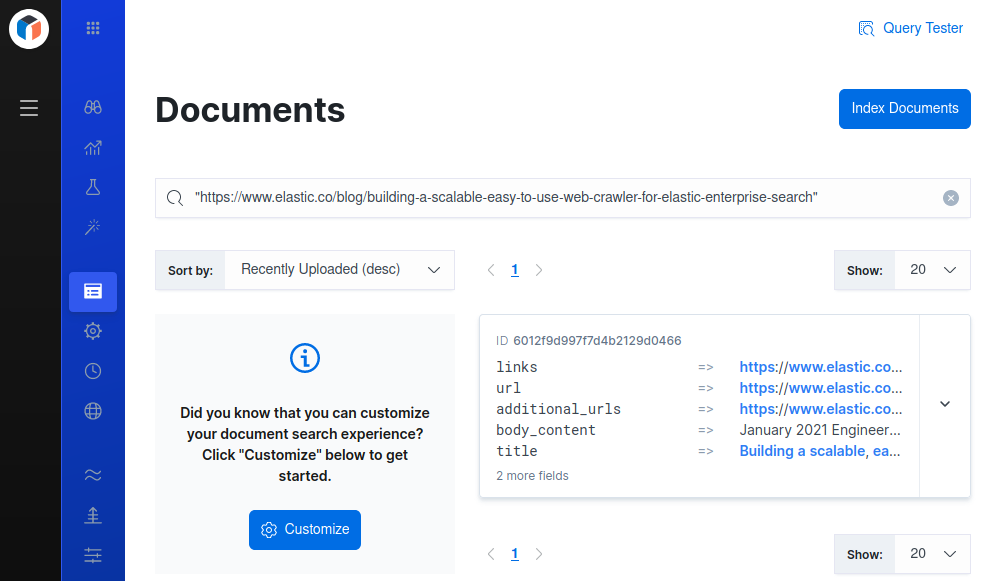
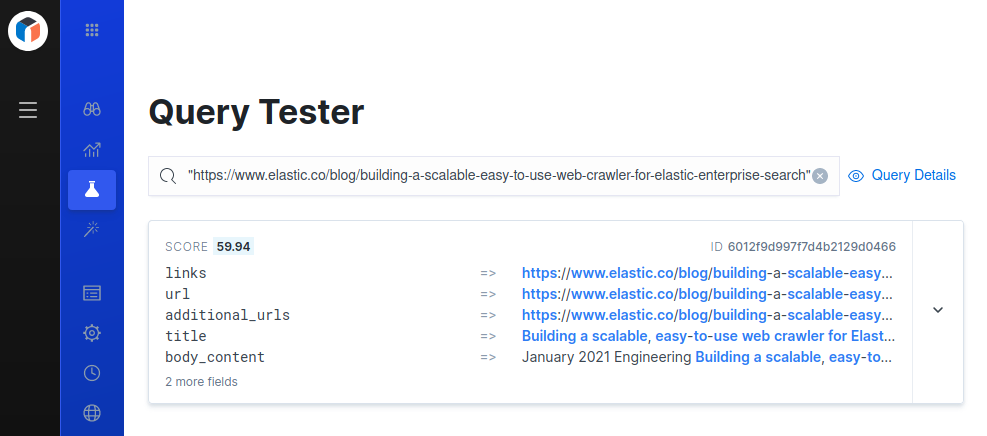
View the indexed documents using the Documents or Query Tester views within the App Search dashboard, or use the search API.
To find a specific document, wrap the document’s URL in quotes, and use that as your search query.
For example: "https://example.com/some/page.html".
If the document is present in the engine, it should be a top result (or only result).
To access the documents dashboard, choose Documents from the engine menu.
To access the query tester, choose Query Tester from the engine menu.
To use the search API, refer to the following API reference:
Troubleshoot crawl
editA crawl may not behave as expected or discover and index the documents you expected. The web crawler faces many challenges while it crawls, including:
- Network issues: lost packets, timeouts, DNS issues
- Resource contention: memory usage, CPU cycles
- Parsing problems: broken HTML
- HTTP protocol issues: broken HTTP servers, incorrect HTTP status codes
For a detailed look at crawl issues, see Sprinting to a crawl: Building an effective web crawler.
However, these issues generally fall into three categories: crawl stability, content discovery, and content extraction and indexing. Use the following sections to guide your troubleshooting:
See Troubleshoot crawl stability if:
- You’re not sure where to start (resolve stability issues first)
- No documents in the engine
- Many documents missing or outdated
- Crawl fails
- Crawl runs for the maximum duration (defaults to 24 hours)
See Troubleshoot content discovery if:
- Specific documents missing or outdated
See Troubleshoot content extraction and indexing if:
- Specific documents missing or outdated
- Incorrect content within documents
- Content missing from documents
Troubleshoot crawl stability
editCrawl stability issues prevent the crawler from discovering, extracting, and indexing your content. It is therefore critical you address these issues first.
Use the following techniques to troubleshoot crawl stability issues.
Analyze web crawler events logs for the most recent crawl:
First:
- Find the crawl request ID for the most recent crawl.
- Filter the web crawler events logs by that ID.
Then:
- Order the events by timestamp, oldest first.
-
Locate the
crawl-endevent and preceding events. These events communicate what happened before the crawl failed.
Analyze web crawler system logs:
These logs may contain additional information about your crawl.
See View web crawler system logs.
Modify the web crawler configuration:
As a last resort, operators can modify the web crawler configuration, including resource limits.
See Web crawler configuration settings in the web crawler reference.
Troubleshoot content discovery
editAfter your crawls are stable, you may find the crawler is not discovering your content as expected. It’s helpful to understand how the web crawler discovers content. See Content discovery in the web crawler reference.
Use the following techniques to troubleshoot content discovery issues.
Confirm the most recent crawl completed successfully:
View the status of the most recent crawl to confirm it completed successfully. See View crawl status.
If the crawl failed, look for signs of crawl stability issues. See Troubleshoot crawl stability.
View indexed documents to confirm missing pages:
Identify which pages are missing from your engine, or focus on specific pages. See View indexed documents for instructions to view all documents and specific documents.
Analyze web crawler events logs for the most recent crawl:
First:
- Find the crawl request ID for the most recent crawl.
- Filter the web crawler events logsby that ID.
- Find the URL of a specific document missing from the engine.
- Filter the web crawler events logs by that URL.
Then:
-
Locate
url-discoverevents to confirm the crawler has seen links to your page. Theoutcomeandmessagefields may explain why the web crawler did not crawl the page. -
If
url-discoverevents indicate discovery was successful, locateurl-fetchevents to analyze the fetching phase of the crawl.
Analyze web crawler system logs:
These may contain additional information about specific pages.
See View web crawler system logs.
Address specific content discovery problems:
| Problem | Description | Solution |
|---|---|---|
External domain |
The web crawler does not follow links that go outside the domains configured for each crawl. |
Manage domains for your crawl to add any missing domains. |
Disallowed path |
The web crawler does not follow links whose paths are disallowed by the crawl rules for each domain. |
Manage crawl rules for each domain to ensure paths are allowed. |
No incoming links |
The web crawler cannot find pages that have no incoming links, unless you provide the path as an entry point. See Content discovery for an explanation of how the web crawler discovers content. |
Add links to the content from other content that the web crawler has already discovered, or explicitly add the path as an entry point. |
Nofollow links |
The web crawler does not follow nofollow links. |
Remove the nofollow link to allow content discovery. |
|
If a page contains a |
Remove the meta tag from your page. |
Redirect loop |
The web crawler cannot discover and index content if redirects result in an infinite loop. |
Ensure all HTTP redirects eventually lead to a |
HTTP errors |
The web crawler cannot discover and index content if it cannot fetch HTML pages from a domain.
The web crawler will not index pages that respond with a |
Fix HTTP server errors. Ensure correct HTTP response codes. |
HTML errors |
The web crawler cannot parse extremely broken HTML pages. In that case, the web crawler cannot index the page, and cannot discover links coming from that page. |
Use the W3C markup validation service to identify and resolve HTML errors in your content. |
Security |
The web crawler cannot access content requiring authentication or authorization. |
Remove the security to allow access to the web crawler. |
Non-HTML content |
The web crawler does not extract and index non-HTML content (e.g. JavaScript, PDF). |
Publish your content in HTML format. |
Non-HTTP protocol |
The web crawler recognizes only the HTTP and HTTPS protocols. |
Publish your content at URLs using HTTP or HTTPS protocols. |
Invalid SSL certificate |
The web crawler will not crawl HTTPS pages with invalid certificates. |
Replace invalid certificates with valid certificates. |
Troubleshoot content extraction and indexing
editThe web crawler may be discovering your content but not extracting and indexing it as expected. It’s helpful to understand how the web crawler extracts and indexes content. See Content extraction and indexing in the web crawler reference.
Use the following techniques to troubleshoot content discovery issues.
Confirm the most recent crawl completed successfully:
View the status of the most recent crawl to confirm it completed successfully. See View crawl status.
If the crawl failed, look for signs of crawl stability issues. See Troubleshoot crawl stability.
View indexed documents to confirm missing pages:
Identify which pages are missing from your engine, or focus on specific pages. See View indexed documents for instructions to view all documents and specific documents.
If documents are missing from the engine, look for signs of content discovery issues. See Troubleshoot content discovery.
Analyze web crawler events logs for the most recent crawl:
First:
- Find the crawl request ID for the most recent crawl.
- Filter the web crawler events logsby that ID.
- Find the URL of a specific document missing from the engine.
- Filter the web crawler events logs by that URL.
Then:
-
Locate
url-extractedevents to confirm the crawler was able to extract content from your page. Theoutcomeandmessagefields may explain why the web crawler could not extract and index the content. -
If
url-extractedevents indicate extraction was successful, locateurl-outputevents to confirm the web crawler attempted ingestion of the page’s content.
Analyze web crawler system logs:
These may contain additional information about specific pages.
See View web crawler system logs.
Address specific content extraction and indexing problems:
| Problem | Description | Solution |
|---|---|---|
Duplicate content |
If your website contains pages with duplicate content, those pages are stored as a single document within your engine.
The document’s |
Use a canonical URL link tag within any document containing duplicate content. |
Non-HTML content |
The web crawler does not extract and index non-HTML content (e.g. JavaScript, PDF). |
Publish your content in HTML format. |
|
The web crawler will not index pages that include a |
Remove the meta tag from your page. |
Page too large |
The web crawler cannot parse extremely large HTML pages. |
Reduce the size of your page. |
Broken HTML |
The web crawler cannot parse extremely broken HTML pages. |
Use the W3C markup validation service to identify and resolve HTML errors in your content. |
Provide feedback
editAfter troubleshooting your crawl, we’d love to know what worked, what didn’t, and what we can improve.
Please send us your feedback.
Re-crawl web content
editFor each engine, repeat the manage-monitor-troubleshoot cycle until the web crawler is discovering and indexing your documents as expected.
From there, you move into the next cycle: update your web content, re-crawl your web content, (repeat).
At this point, you may want to move beyond manual crawls and schedule crawls instead.
Schedule crawls
editYou may want to trigger crawls programatically. Use this technique to crawl in response to an event, such as pushing updated web content. Or, crawl according to a schedule.
To trigger crawls programatically, refer to the following API reference:
Schedule your API calls using a job scheduler, like cron. Or write your own application code to manage crawls.