Ingest pipelines in Search
editIngest pipelines in Search
editYou can manage ingest pipelines through Elasticsearch APIs or Kibana UIs.
The Content UI under Search has a set of tools for creating and managing indices optimized for search use cases (non time series data). You can also manage your ingest pipelines in this UI.
Find pipelines in Content UI
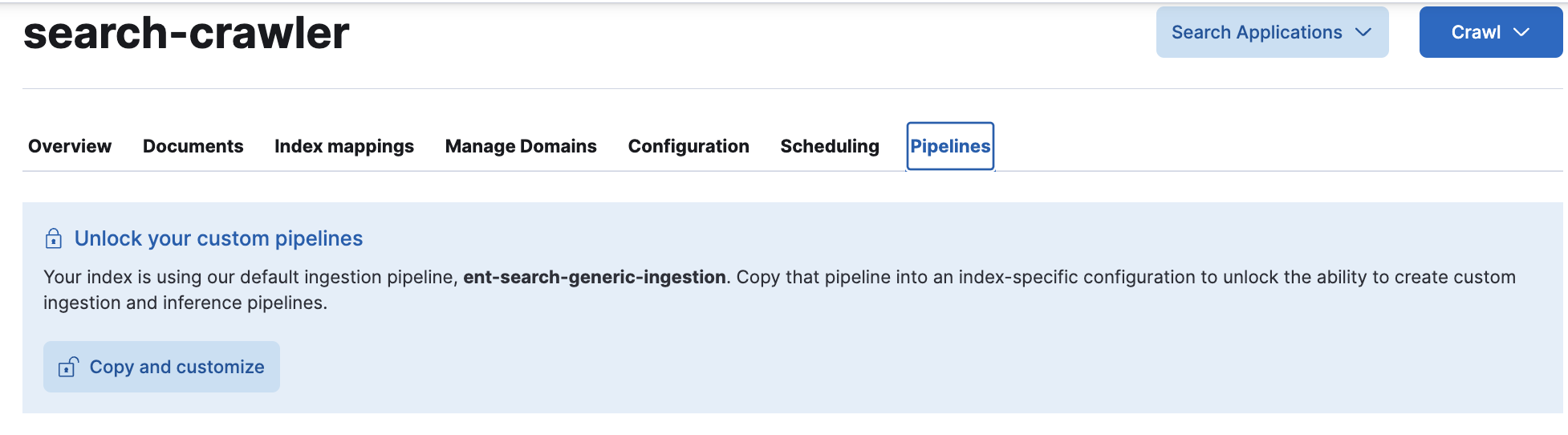
editTo work with ingest pipelines using these UI tools, you’ll be using the Pipelines tab on your search-optimized Elasticsearch index.
To find this tab in the Kibana UI:
- Go to Search > Content > Elasticsearch indices.
-
Select the index you want to work with. For example,
search-my-index. - On the index’s overview page, open the Pipelines tab.
- From here, you can follow the instructions to create custom pipelines, and set up ML inference pipelines.
The tab is highlighted in this screenshot:
Overview
editThese tools can be particularly helpful by providing a layer of customization and post-processing of documents. For example:
- providing consistent extraction of text from binary data types
- ensuring consistent formatting
- providing consistent sanitization steps (removing PII like phone numbers or SSN’s)
It can be a lot of work to set up and manage production-ready pipelines from scratch. Considerations such as error handling, conditional execution, sequencing, versioning, and modularization must all be taken into account.
To this end, when you create indices for search use cases, (including Elastic web crawler, Elastic connector, and API indices), each index already has a pipeline set up with several processors that optimize your content for search.
This pipeline is called ent-search-generic-ingestion.
While it is a "managed" pipeline (meaning it should not be tampered with), you can view its details via the Kibana UI or the Elasticsearch API.
You can also read more about its contents below.
You can control whether you run some of these processors. While all features are enabled by default, they are eligible for opt-out. For Elastic crawler and Elastic connectors, you can opt out (or back in) per index, and your choices are saved. For API indices, you can opt out (or back in) by including specific fields in your documents. See below for details.
At the deployment level, you can change the default settings for all new indices. This will not effect existing indices.
Each index also provides the capability to easily create index-specific ingest pipelines with customizable processing.
If you need that extra flexibility, you can create a custom pipeline by going to your pipeline settings and choosing to "copy and customize".
This will replace the index’s use of ent-search-generic-ingestion with 3 newly generated pipelines:
-
<index-name> -
<index-name>@custom -
<index-name>@ml-inference
Like ent-search-generic-ingestion, the first of these is "managed", but the other two can and should be modified to fit your needs.
You can view these pipelines using the platform tools (Kibana UI, Elasticsearch API), and can also
read more about their content below.
Pipeline Settings
editAside from the pipeline itself, you have a few configuration options which control individual features of the pipelines.
- Extract Binary Content - This controls whether or not binary documents should be processed and any textual content should be extracted.
- Reduce Whitespace - This controls whether or not consecutive, leading, and trailing whitespaces should be removed. This can help to display more content in some search experiences.
-
Run ML Inference - Only available on index-specific pipelines.
This controls whether or not the optional
<index-name>@ml-inferencepipeline will be run. Enabled by default.
For Elastic web crawler and connectors, you can opt in or out per index.
These settings are stored in Elasticsearch in the .elastic-connectors index, in the document that corresponds to the specific index.
These settings can be changed there directly, or through the Kibana UI at Search > Content > Indices > <your index> > Pipelines > Settings.
You can also change the deployment wide defaults.
These settings are stored in the Elasticsearch mapping for .elastic-connectors in the _meta section.
These settings can be changed there directly, or from the Kibana UI at Search > Content > Settings tab.
Changing the deployment wide defaults will not impact any existing indices, but will only impact any newly created indices defaults.
Those defaults will still be able to be overriden by the index-specific settings.
Using the API
editThese settings are not persisted for indices that "Use the API". Instead, changing these settings will, in real time, change the example cURL request displayed. Notice that the example document in the cURL request contains three underscore-prefixed fields:
{
...
"_extract_binary_content": true,
"_reduce_whitespace": true,
"_run_ml_inference": true
}
Omitting one of these special fields is the same as specifying it with the value false.
You must also specify the pipeline in your indexing request. This is also shown in the example cURL request.
If the pipeline is not specified, the underscore-prefixed fields will actually be indexed, and will not impact any processing behaviors.
Details
editent-search-generic-ingestion Reference
editYou can access this pipeline with the Elasticsearch Ingest Pipelines API or via Kibana’s Stack Management > Ingest Pipelines UI.
This pipeline is a "managed" pipeline.
That means that it is not intended to be edited.
Editing/updating this pipeline manually could result in unintended behaviors, or difficulty in upgrading in the future.
If you want to make customizations, we recommend you utilize index-specific pipelines (see below), specifically the <index-name>@custom pipeline.
Processors
edit-
attachment- this uses the Attachment processor to convert any binary data stored in a document’s_attachmentfield to a nested object of plain text and metadata. -
set_body- this uses the Set processor to copy any plain text extracted from the previous step and persist it on the document in thebodyfield. -
remove_replacement_chars- this uses the Gsub processor to remove characters like "�" from thebodyfield. -
remove_extra_whitespace- this uses the Gsub processor to replace consecutive whitespace characters with single spaces in thebodyfield. While not perfect for every use case (see below for how to disable), this can ensure that search experiences display more content and highlighting and less empty space for your search results. -
trim- this uses the Trim processor to remove any remaining leading or trailing whitespace from thebodyfield. -
remove_meta_fields- this final step of the pipeline uses the Remove processor to remove special fields that may have been used elsewhere in the pipeline, whether as temporary storage or as control flow parameters.
Control flow parameters
editThe ent-search-generic-ingestion pipeline does not always run all processors.
It utilizes a feature of ingest pipelines to conditionally run processors based on the contents of each individual document.
-
_extract_binary_content- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theattachment,set_body, andremove_replacement_charsprocessors. Note that the document will also need an_attachmentfield populated with base64-encoded binary data in order for theattachmentprocessor to have any output. If the_extract_binary_contentfield is missing orfalseon a source document, these processors will be skipped. -
_reduce_whitespace- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theremove_extra_whitespaceandtrimprocessors. These processors only apply to thebodyfield. If the_reduce_whitespacefield is missing orfalseon a source document, these processors will be skipped.
Crawler, Native Connectors, and Connector Clients will automatically add these control flow parameters based on the settings in the index’s Pipeline tab. To control what settings any new indices will have upon creation, see the deployment wide content settings. See Pipeline Settings.
Index-specific ingest pipelines
editIn the Kibana UI for your index, by clicking on the Pipelines tab, then Settings > Copy and customize, you can quickly generate 3 pipelines which are specific to your index.
These 3 pipelines replace ent-search-generic-ingestion for the index.
There is nothing lost in this action, as the <index-name> pipeline is a superset of functionality over the ent-search-generic-ingestion pipeline.
The "copy and customize" button is not available at all Elastic subscription levels. Refer to the Elastic subscriptions pages for Elastic Cloud and self-managed deployments.
<index-name> Reference
editThis pipeline looks and behaves a lot like the ent-search-generic-ingestion pipeline, but with two additional processors.
You should not rename this pipeline.
This pipeline is a "managed" pipeline.
That means that it is not intended to be edited.
Editing/updating this pipeline manually could result in unintended behaviors, or difficulty in upgrading in the future.
If you want to make customizations, we recommend you utilize the <index-name>@custom pipeline.
Processors
editIn addition to the processors inherited from the ent-search-generic-ingestion pipeline, the index-specific pipeline also defines:
-
index_ml_inference_pipeline- this uses the Pipeline processor to run the<index-name>@ml-inferencepipeline. This processor will only be run if the source document includes a_run_ml_inferencefield with the valuetrue. -
index_custom_pipeline- this uses the Pipeline processor to run the<index-name>@custompipeline.
Control flow parameters
editLike the ent-search-generic-ingestion pipeline, the <index-name> pipeline does not always run all processors.
In addition to the _extract_binary_content and _reduce_whitespace control flow parameters, the <index-name> pipeline also supports:
-
_run_ml_inference- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theindex_ml_inference_pipelineprocessor. If the_run_ml_inferencefield is missing orfalseon a source document, this processor will be skipped.
Crawler, Native Connectors, and Connector Clients will automatically add these control flow parameters based on the settings in the index’s Pipeline tab. To control what settings any new indices will have upon creation, see the deployment wide content settings. See Pipeline Settings.
<index-name>@ml-inference Reference
editThis pipeline is empty to start (no processors), but can be added to via the Kibana UI either through the Pipelines tab of your index, or from the Stack Management > Ingest Pipelines page.
Unlike the ent-search-generic-ingestion pipeline and the <index-name> pipeline, this pipeline is NOT "managed".
It’s possible to add one or more ML inference pipelines to an index in the Content UI.
This pipeline will serve as a container for all of the ML inference pipelines configured for the index.
Each ML inference pipeline added to the index is referenced within <index-name>@ml-inference using a pipeline processor.
You should not rename this pipeline.
The monitor_ml Elasticsearch cluster permission is required in order to manage ML models and ML inference pipelines which use those models.
<index-name>@custom Reference
editThis pipeline is empty to start (no processors), but can be added to via the Kibana UI either through the Pipelines
tab of your index, or from the Stack Management > Ingest Pipelines page.
Unlike the ent-search-generic-ingestion pipeline and the <index-name> pipeline, this pipeline is NOT "managed".
You are encouraged to make additions and edits to this pipeline, provided its name remains the same. This provides a convenient hook from which to add custom processing and transformations for your data. Be sure to read the docs for ingest pipelines to see what options are available.
You should not rename this pipeline.
Upgrading notes
editExpand to see upgrading notes
-
app_search_crawler- Since 8.3, App Search web crawler has utilized this pipeline to power its binary content extraction. You can read more about this pipeline and its usage in the App Search Guide. When upgrading from 8.3 to 8.5+, be sure to note any changes that you made to theapp_search_crawlerpipeline. These changes should be re-applied to each index’s<index-name>@custompipeline in order to ensure a consistent data processing experience. In 8.5+, the index setting to enable binary content is required in addition to the configurations mentioned in the App Search Guide. -
ent_search_crawler- Since 8.4, the Elastic web crawler has utilized this pipeline to power its binary content extraction. You can read more about this pipeline and its usage in the Elastic web crawler Guide. When upgrading from 8.4 to 8.5+, be sure to note any changes that you made to theent_search_crawlerpipeline. These changes should be re-applied to each index’s<index-name>@custompipeline in order to ensure a consistent data processing experience. In 8.5+, the index setting to enable binary content is required in addition to the configurations mentioned in the Elastic web crawler Guide. -
ent-search-generic-ingestion- Since 8.5, Native Connectors, Connector Clients, and new (>8.4) Elastic web crawler indices will all make use of this pipeline by default. You can read more about this pipeline above. As this pipeline is "managed", any modifications that were made toapp_search_crawlerand/orent_search_crawlershould NOT be made toent-search-generic-ingestion. Instead, if such customizations are desired, you should utilize Index-specific ingest pipelines, placing all modifications in the<index-name>@custompipeline(s).