Connector sync rules
editConnector sync rules
editUse connector sync rules to help control which documents are synced between the third-party data source and Elasticsearch.
Define sync rules in the Kibana UI for each connector index, under the Sync rules tab for the index.
Sync rules apply to managed connectors and self-managed connectors.
Availability and prerequisites
editIn Elastic versions 8.8.0 and later all connectors have support for basic sync rules.
Some connectors support advanced sync rules. Learn more in the individual connector’s reference documentation.
Types of sync rule
editThere are two types of sync rule:
- Basic sync rules - these rules are represented in a table-like view. Basic sync rules are identical for all connectors.
- Advanced sync rules - these rules cover complex query-and-filter scenarios that cannot be expressed with basic sync rules. Advanced sync rules are defined through a source-specific DSL JSON snippet.
General data filtering concepts
editBefore discussing sync rules, it’s important to establish a basic understanding of data filtering concepts. The following diagram shows that data filtering can occur in several different processes/locations.
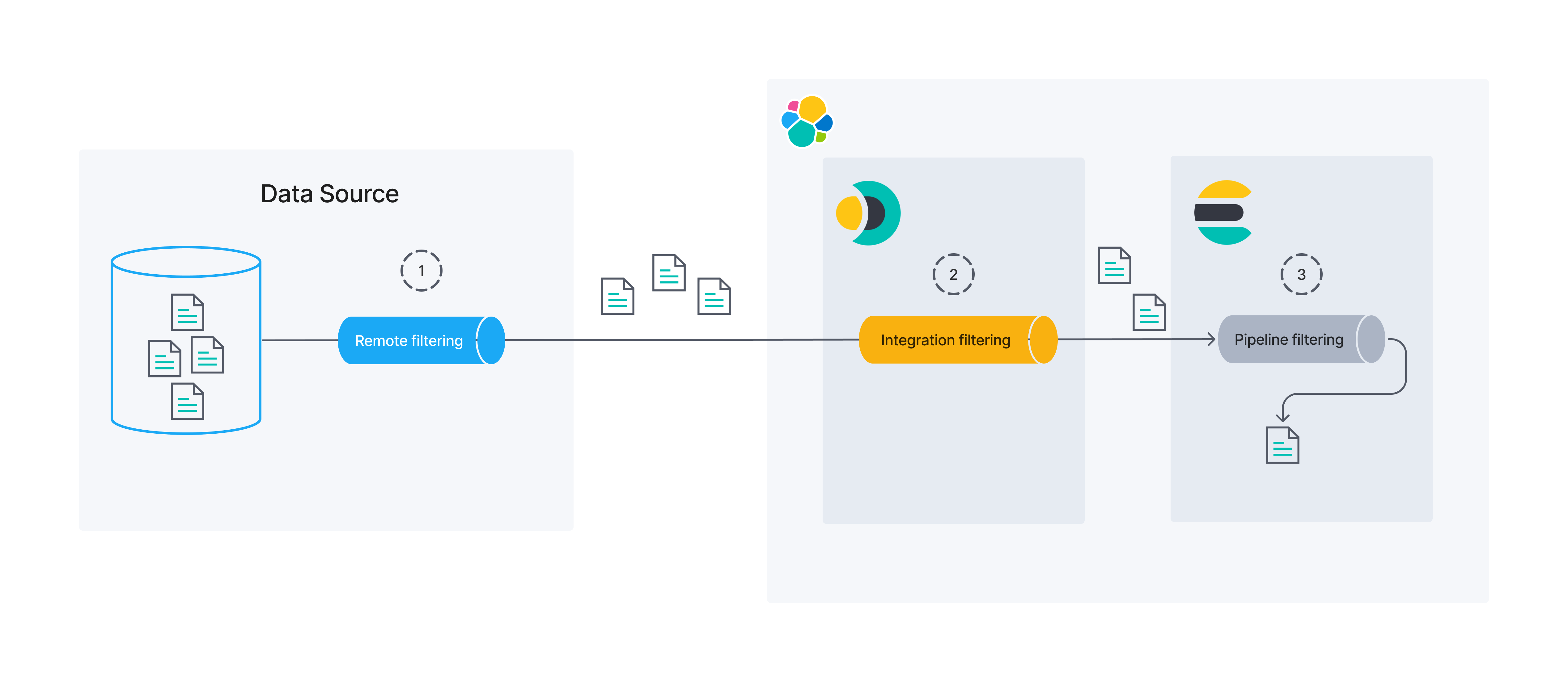
In this documentation we will focus on remote and integration filtering. Sync rules can be used to modify both of these.
Remote filtering
editData might be filtered at its source. We call this remote filtering, as the filtering process is external to Elastic.
Integration filtering
editIntegration filtering acts as a bridge between the original data source and Elasticsearch. Filtering that takes place in connectors is an example of integration filtering.
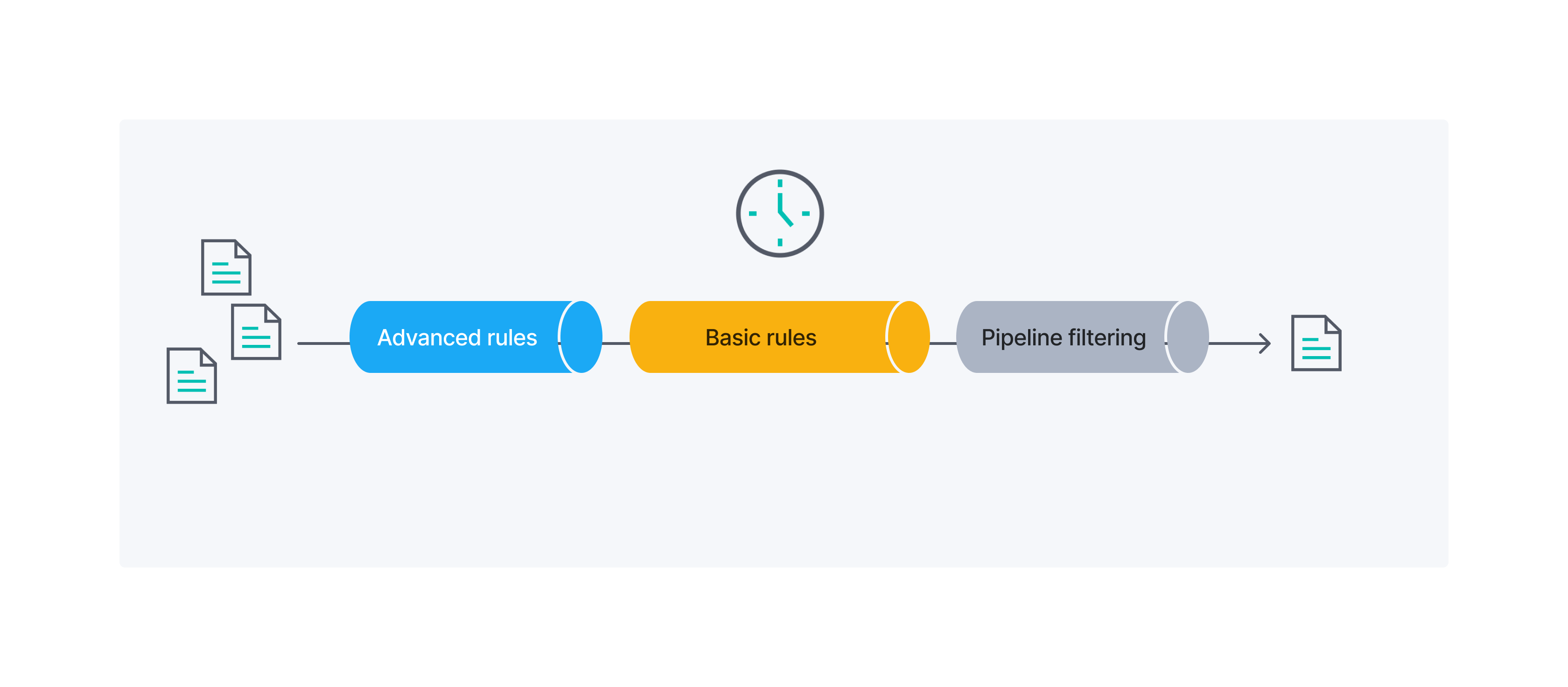
Pipeline filtering
editFinally, Elasticsearch can filter data right before persistence using ingest pipelines. We will not focus on ingest pipeline filtering in this guide.
Currently, basic sync rules are the only way to control integration filtering for connectors. Remember that remote filtering extends far beyond the scope of connectors alone. For best results, collaborate with the owners and maintainers of your data source. Ensure the source data is well-organized and optimized for the query types made by the connectors.
Sync rules overview
editIn most cases, your data lake will contain far more data than you want to expose to end users. For example, you may want to search a product catalog, but not include vendor contact information, even if the two are co-located for business purposes.
The optimal time to filter data is early in the data pipeline. There are two main reasons:
- Performance: It’s more efficient to send a query to the backing data source than to obtain all the data and then filter it in the connector. It’s faster to send a smaller dataset over a network and to process it on the connector side.
- Security: Query-time filtering is applied on the data source side, so the data is not sent over the network and into the connector, which limits the exposure of your data.
In a perfect world, all filtering would be done as remote filtering.
In practice, however, this is not always possible. Some sources do not allow robust remote filtering. Others do, but require special setup (building indexes on specific fields, tweaking settings, etc.) that may require attention from other stakeholders in your organization.
With this in mind, sync rules were designed to modify both remote filtering and integration filtering. Your goal should be to do as much remote filtering as possible, but integration is a perfectly viable fall-back. By definition, remote filtering is applied before the data is obtained from a third-party source. Integration filtering is applied after the data is obtained from a third-party source, but before it is ingested into the Elasticsearch index.
All sync rules are applied to a given document before any ingest pipelines are run on that document. Therefore, you can use ingest pipelines for any processing that must occur after integration filtering has occurred.
If a sync rule is added, edited or removed, it will only take effect after the next full sync.
Basic sync rules
editEach basic sync rules can be one of two "policies": include and exclude.
Include rules are used to include the documents that "match" the specified condition.
Exclude rules are used to exclude the documents that "match" the specified condition.
A "match" is determined based on a condition defined by a combination of "field", "rule", and "value".
The Field column should be used to define which field on a given document should be considered.
The following rules are available in the Rule column:
-
equals- The field value is equal to the specified value. -
starts_with- The field value starts with the specified (string) value. -
ends_with- The field value ends with the specified (string) value. -
contains- The field value includes the specified (string) value. -
regex- The field value matches the specified regular expression. -
>- The field value is greater than the specified value. -
<- The field value is less than the specified value.
Finally, the Value column is dependent on:
- the data type in the specified "field"
- which "rule" was selected.
For example, if a value of [A-Z]{2} might make sense for a regex rule, but much less so for a > rule.
Similarly, you probably wouldn’t have a value of espresso when operating on an ip_address field, but perhaps you would for a beverage field.
Basic sync rules examples
editExample 1
editExclude all documents that have an ID field with the value greater than 1000.

Example 2
editExclude all documents that have a state field that matches a specified regex.

Performance implications
edit- If you’re relying solely on basic sync rules in the integration filtering phase the connector will fetch all the data from the data source
- For data sources without automatic pagination, or similar optimizations, fetching all the data can lead to memory issues. For example, loading datasets which are too big to fit in memory at once.
The native MongoDB connector provided by Elastic uses pagination and therefore has optimized performance. Keep in mind that custom community-built self-managed connectors may not have these performance optimizations.
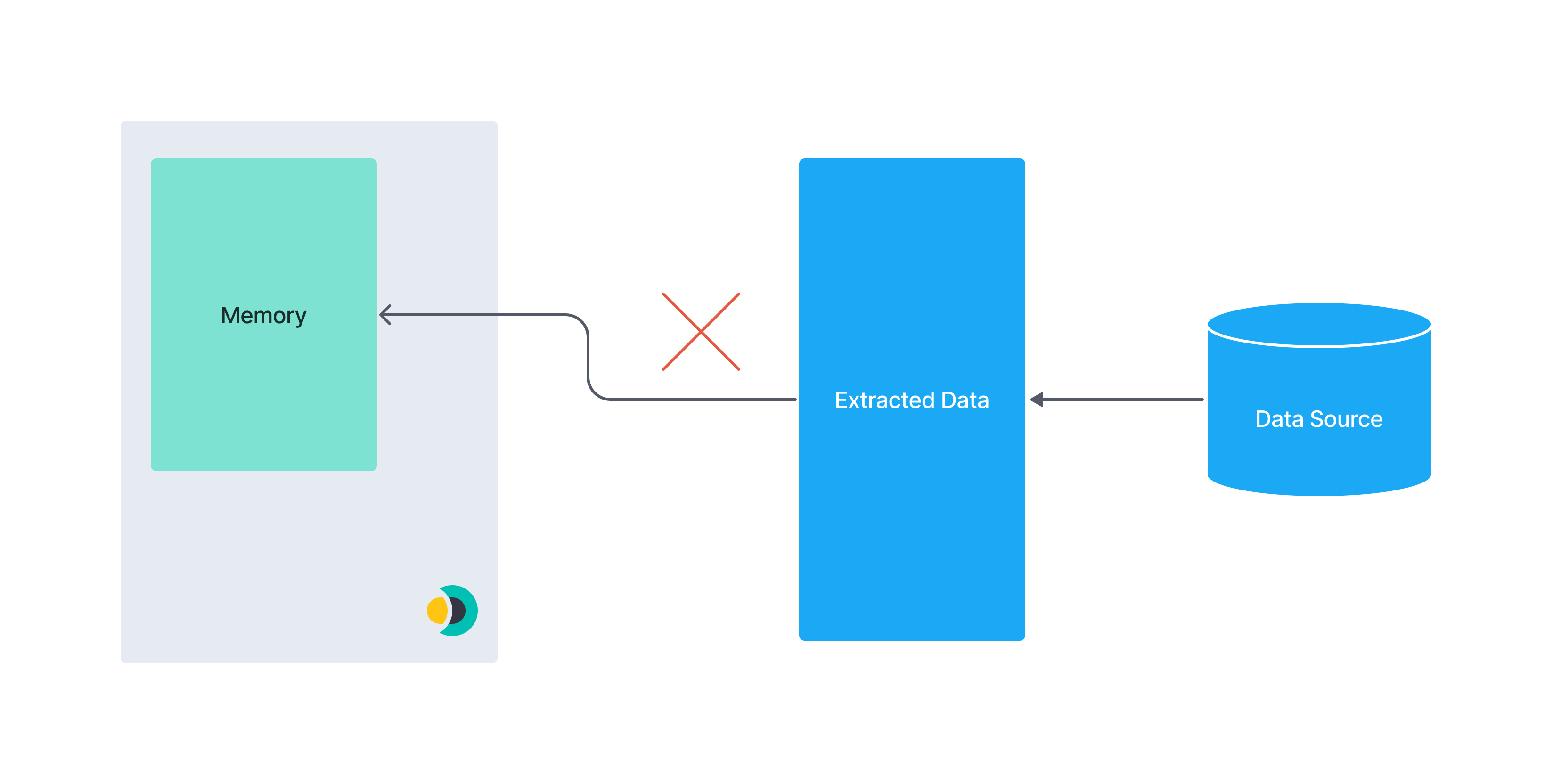
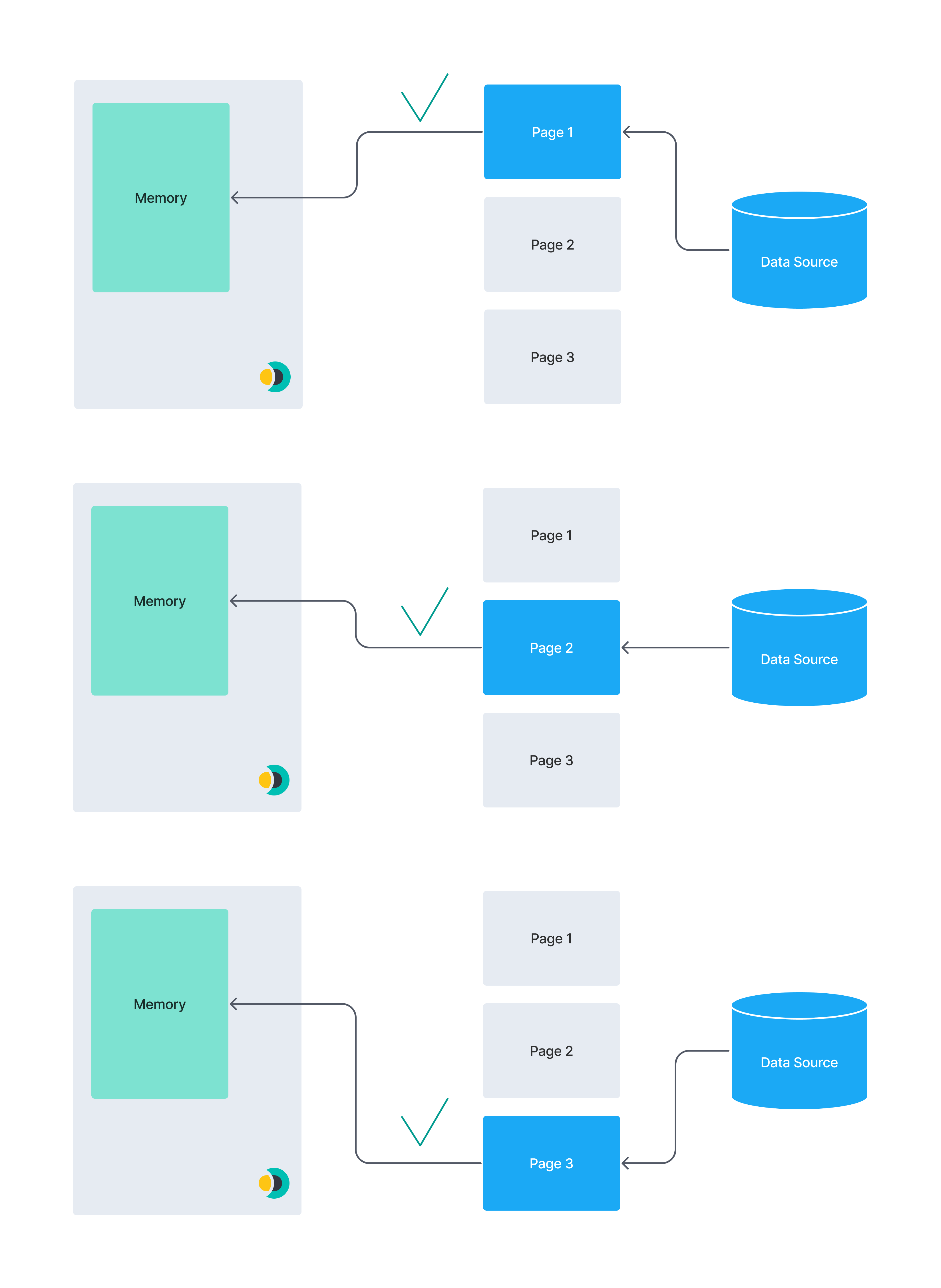
The following diagrams illustrate the concept of pagination. A huge data set may not fit into a connector instance’s memory. Splitting data into smaller chunks reduces the risk of out-of-memory errors.
This diagram illustrates an entire dataset being extracted at once:
By comparison, this diagram illustrates a paginated dataset:
Advanced sync rules
editAdvanced sync rules overwrite any remote filtering query that could have been inferred from the basic sync rules. If an advanced sync rule is defined, any defined basic sync rules will be used exclusively for integration filtering.
Advanced sync rules are only used in remote filtering. You can think of advanced sync rules as a language-agnostic way to represent queries to the data source. Therefore, these rules are highly source-specific.
The following connectors support advanced sync rules:
Each connector supporting advanced sync rules provides its own DSL to specify rules. Refer to the documentation for each connector for details.
Combining basic and advanced sync rules
editYou can also use basic sync rules and advanced sync rules together to filter a data set.
The following diagram provides an overview of the order in which advanced sync rules, basic sync rules, and pipeline filtering, are applied to your documents:
Example
editIn the following example we want to filter a data set containing apartments to only contain apartments with specific properties. We’ll use basic and advanced sync rules throughout the example.
A sample apartment looks like this in the .json format:
{
"id": 1234,
"bedrooms": 3,
"price": 1500,
"address": {
"street": "Street 123",
"government_area": "Area",
"country_information": {
"country_code": "PT",
"country": "Portugal"
}
}
}
The target data set should fulfill the following conditions:
- Every apartment should have at least 3 bedrooms
- The apartments should not be more expensive than 1500 per month
- The apartment with id 1234 should get included without considering the first two conditions
- Each apartment should be located in either Portugal or Spain
The first 3 conditions can be handled by basic sync rules, but we’ll need to use advanced sync rules for number 4.
Basic sync rules examples
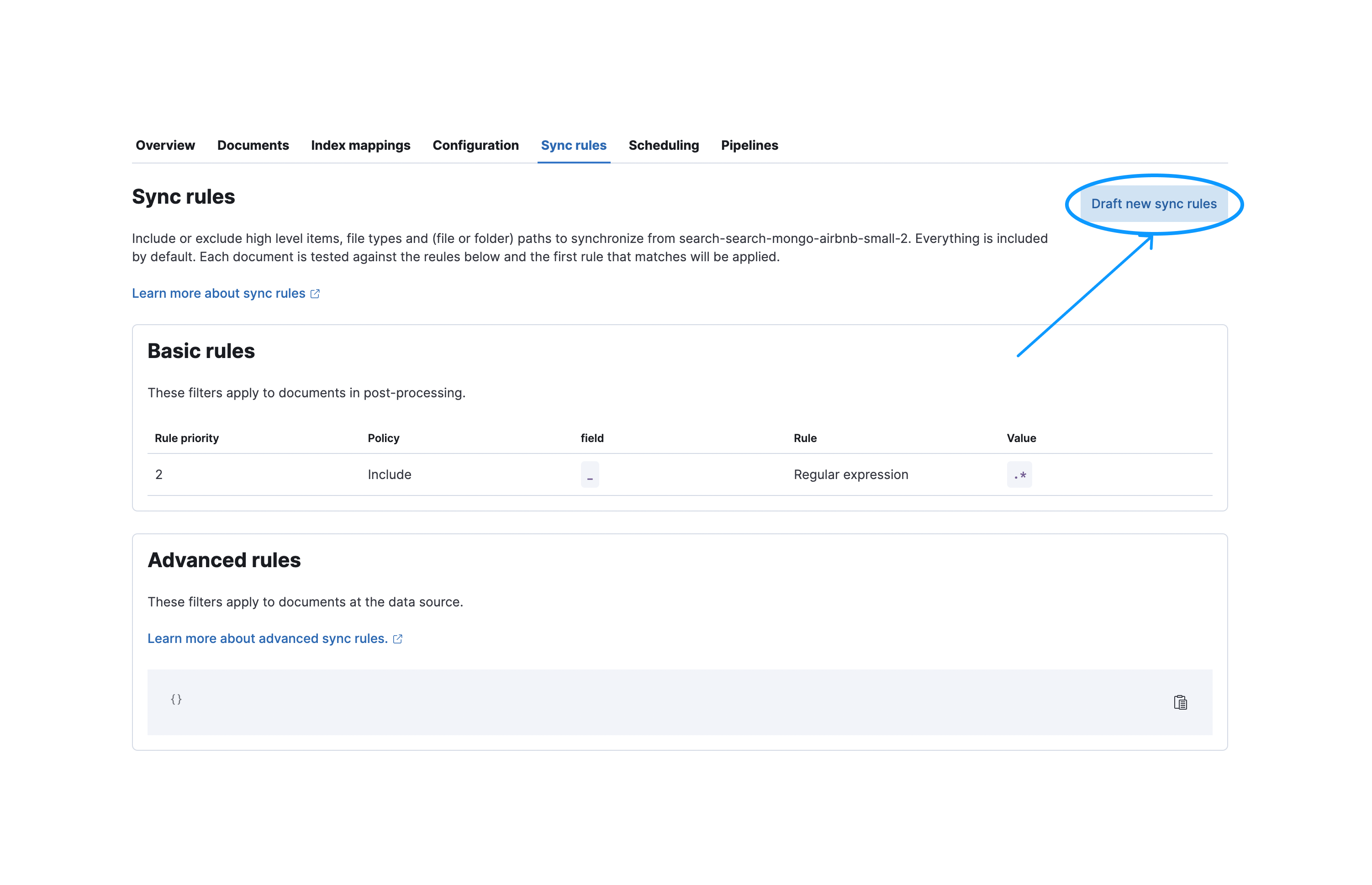
editTo create a new basic sync rule, navigate to the Sync Rules tab and select Draft new sync rules:
Afterwards you need to press the Save and validate draft button to validate these rules. Note that when saved the rules will be in draft state. They won’t be executed in the next sync unless they are applied.
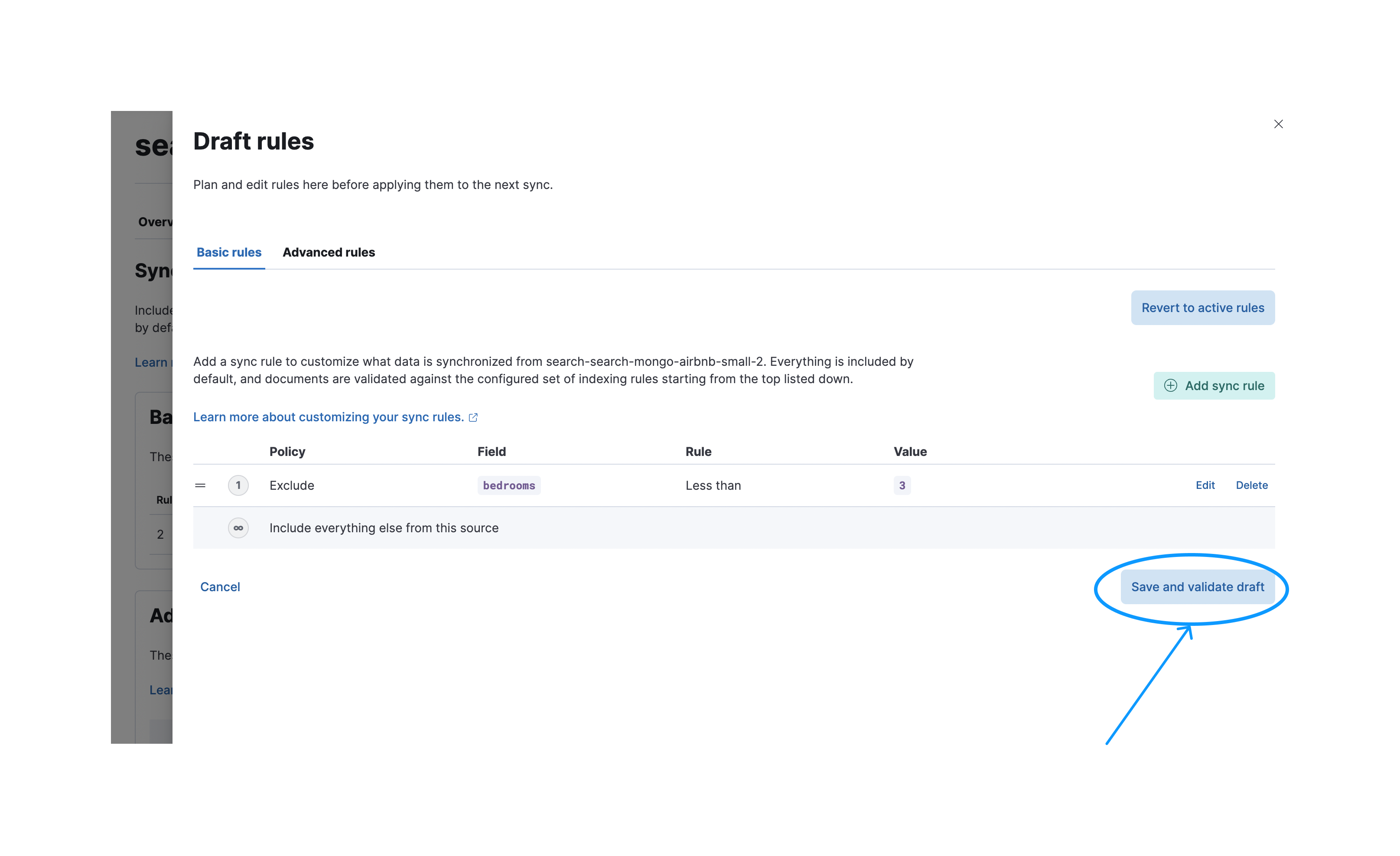
After a successful validation you can apply your rules so they’ll be executed in the next sync.
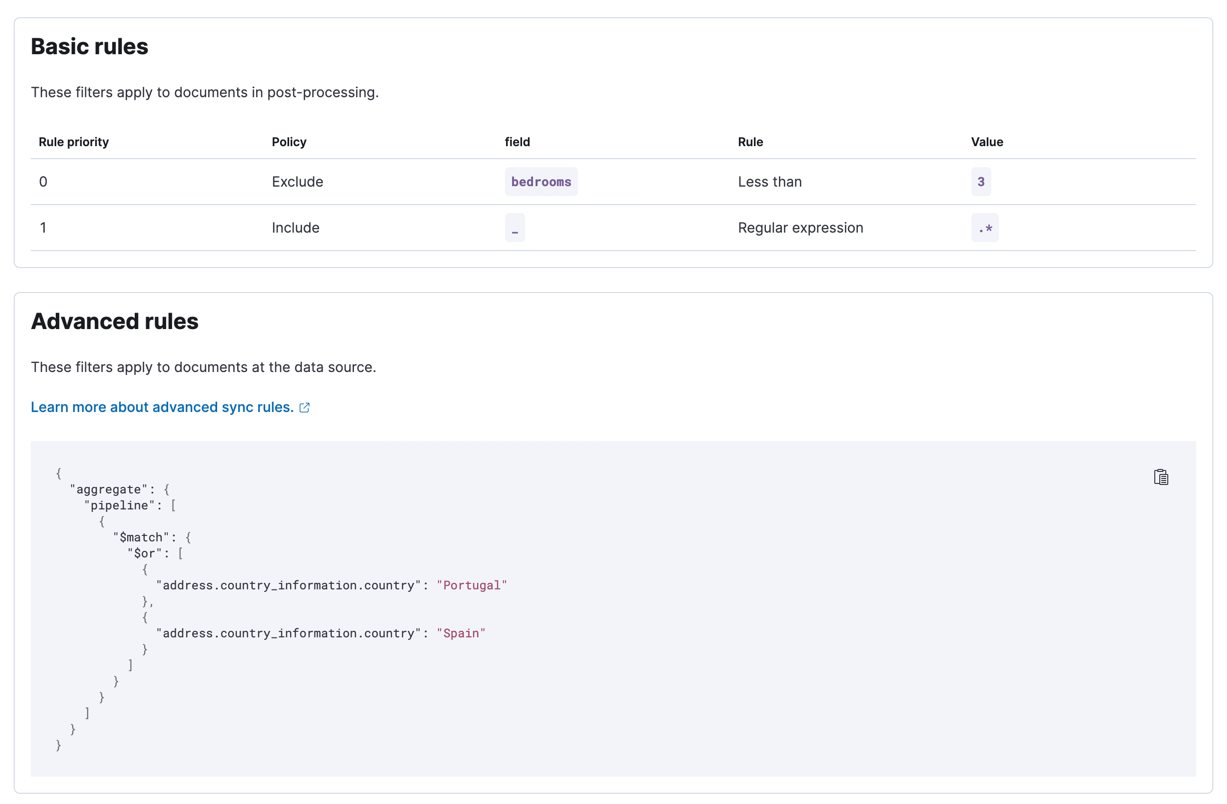
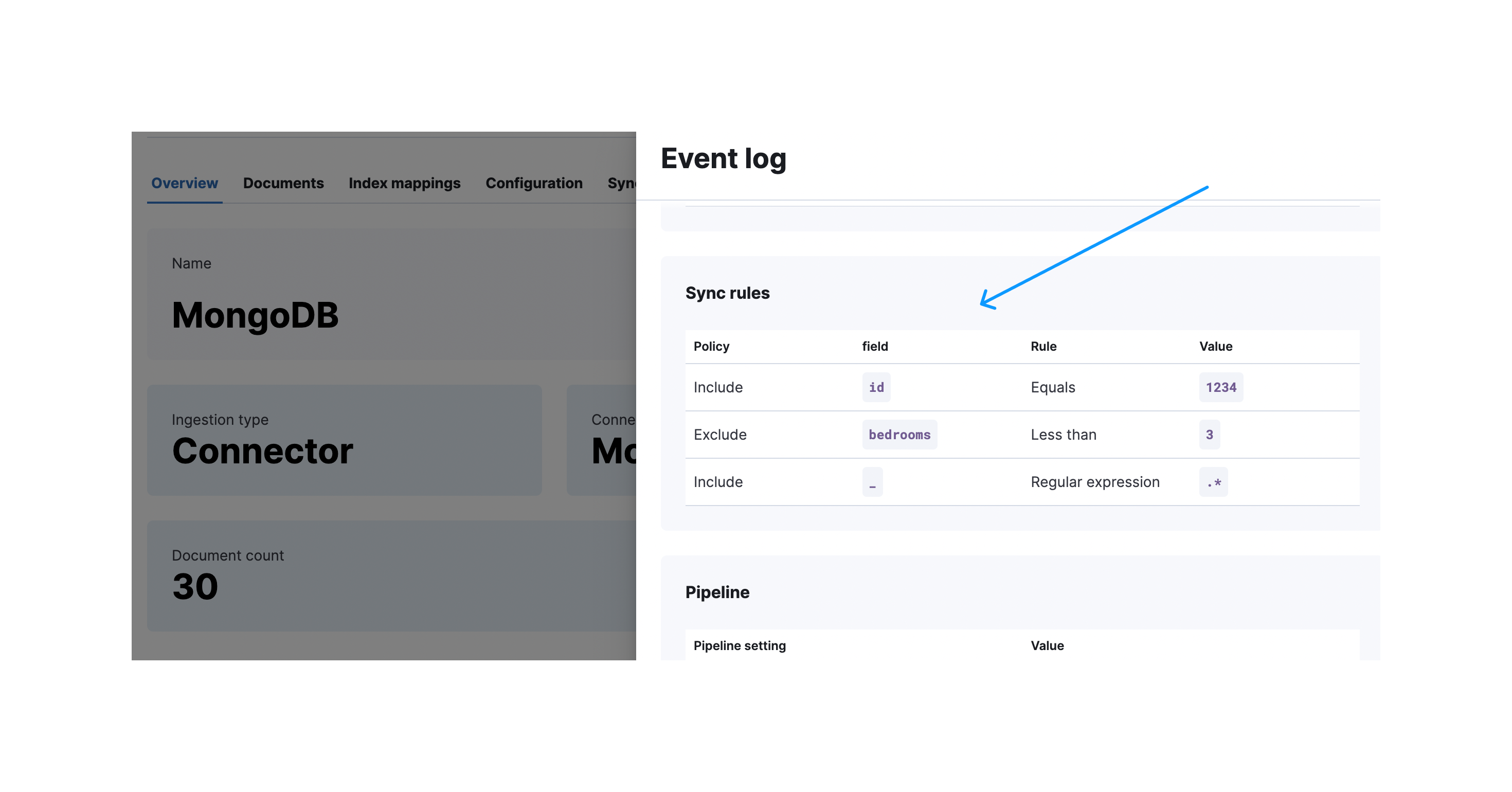
These following conditions can be covered by basic sync rules:
- The apartment with id 1234 should get included without considering the first two conditions
- Every apartment should have at least three bedrooms
- The apartments should not be more expensive than 1000/month
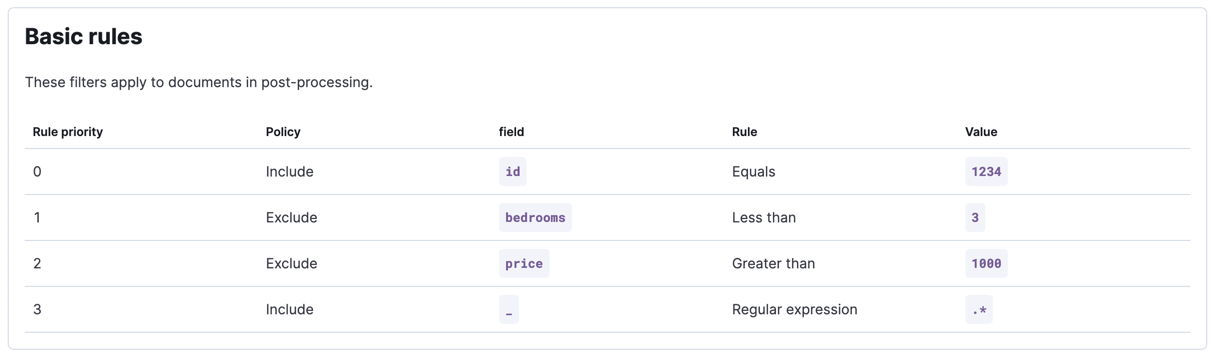
Remember that order matters for basic sync rules. You may get different results for a different ordering.
Advanced sync rules example
editYou want to only include apartments which are located in Portugal or Spain. We need to use advanced sync rules here, because we’re dealing with deeply nested objects.
Let’s assume that the apartment data is stored inside a MongoDB instance. For MongoDB we support aggregation pipelines in our advanced sync rules among other things. An aggregation pipeline to only select properties located in Portugal or Spain looks like this:
[
{
"$match": {
"$or": [
{
"address.country_information.country": "Portugal"
},
{
"address.country_information.country": "Spain"
}
]
}
}
]
To create these advanced sync rules navigate to the sync rules creation dialog and select the Advanced rules tab.
You can now paste your aggregation pipeline into the input field under aggregate.pipeline:
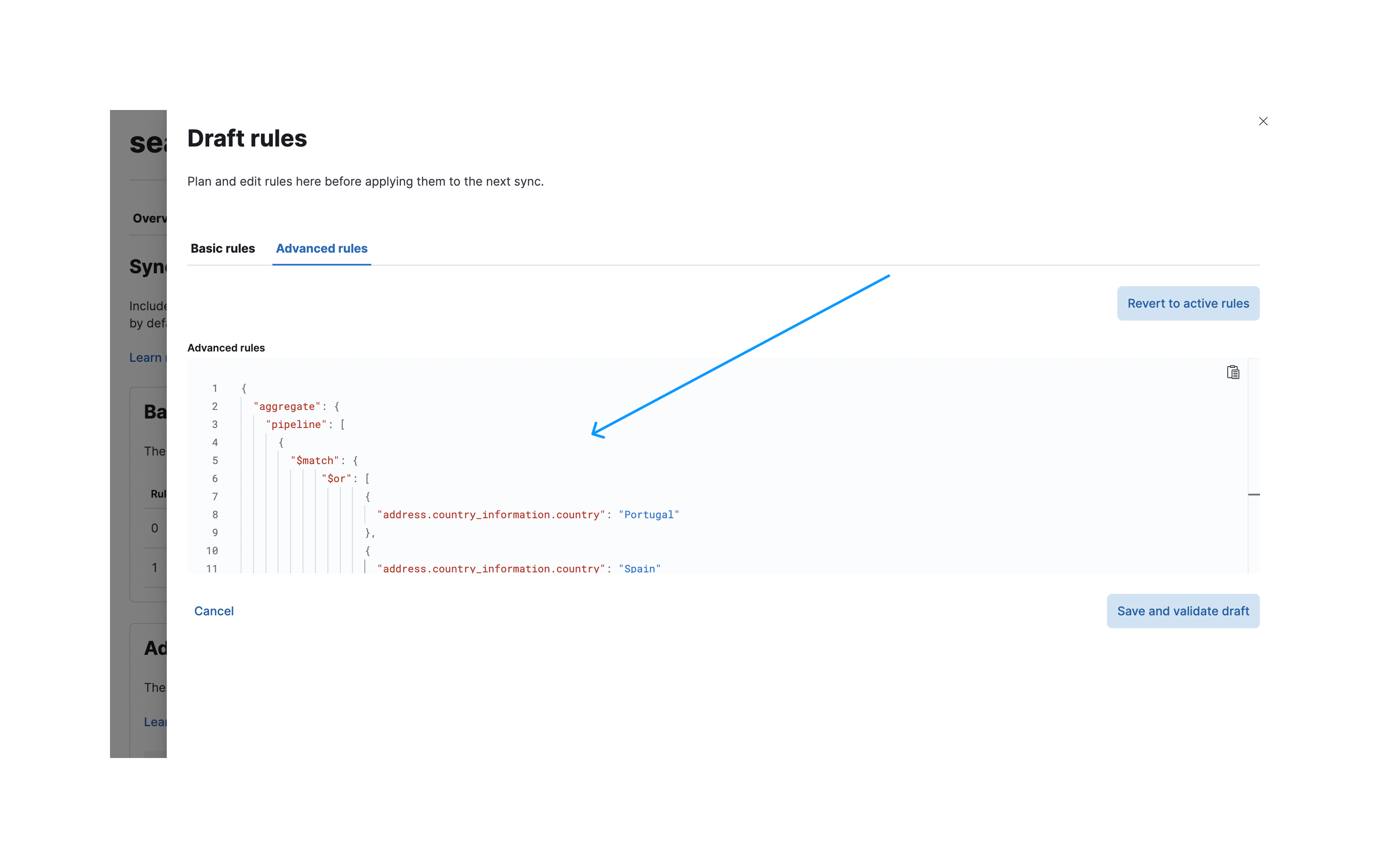
Once validated, apply these rules. The following screenshot shows the applied sync rules, which will be executed in the next sync:
After a successful sync you can expand the sync details to see which rules were applied:
Active sync rules can become invalid when changed outside of the UI. Sync jobs with invalid rules will fail. One workaround is to revalidate the draft rules and override the invalid active rules.