- Elasticsearch Guide: other versions:
- Elasticsearch basics
- Quick starts
- Set up Elasticsearch
- Run Elasticsearch locally
- Installing Elasticsearch
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Miscellaneous cluster settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- Health Diagnostic settings
- Index lifecycle management settings
- Data stream lifecycle settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Inference settings
- Monitoring settings
- Nodes
- Networking
- Node query cache settings
- Search settings
- Security settings
- Shard allocation, relocation, and recovery
- Shard request cache settings
- Snapshot and restore settings
- Transforms settings
- Thread pools
- Watcher settings
- Advanced configuration
- Important system configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Plugins
- Search your data
- Re-ranking
- Index modules
- Index templates
- Aliases
- Mapping
- Dynamic mapping
- Explicit mapping
- Runtime fields
- Field data types
- Aggregate metric
- Alias
- Arrays
- Binary
- Boolean
- Completion
- Date
- Date nanoseconds
- Dense vector
- Flattened
- Geopoint
- Geoshape
- Histogram
- IP
- Join
- Keyword
- Nested
- Numeric
- Object
- Pass-through object
- Percolator
- Point
- Range
- Rank feature
- Rank features
- Search-as-you-type
- Semantic text
- Shape
- Sparse vector
- Text
- Token count
- Unsigned long
- Version
- Metadata fields
- Mapping parameters
analyzercoercecopy_todoc_valuesdynamiceager_global_ordinalsenabledformatignore_aboveindex.mapping.ignore_aboveignore_malformedindexindex_optionsindex_phrasesindex_prefixesmetafieldsnormalizernormsnull_valueposition_increment_gappropertiessearch_analyzersimilaritystoresubobjectsterm_vector
- Mapping limit settings
- Removal of mapping types
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Ingest pipelines
- Example: Parse logs
- Enrich your data
- Processor reference
- Append
- Attachment
- Bytes
- Circle
- Community ID
- Convert
- CSV
- Date
- Date index name
- Dissect
- Dot expander
- Drop
- Enrich
- Fail
- Fingerprint
- Foreach
- Geo-grid
- GeoIP
- Grok
- Gsub
- HTML strip
- Inference
- IP Location
- Join
- JSON
- KV
- Lowercase
- Network direction
- Pipeline
- Redact
- Registered domain
- Remove
- Rename
- Reroute
- Script
- Set
- Set security user
- Sort
- Split
- Terminate
- Trim
- Uppercase
- URL decode
- URI parts
- User agent
- Ingest pipelines in Search
- Connectors
- Data streams
- Data management
- ILM: Manage the index lifecycle
- Tutorial: Customize built-in policies
- Tutorial: Automate rollover
- Index management in Kibana
- Overview
- Concepts
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Troubleshooting index lifecycle management errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Data tiers
- Roll up or transform your data
- Query DSL
- EQL
- ES|QL
- SQL
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Categorize text
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Frequent item sets
- Geo-distance
- Geohash grid
- Geohex grid
- Geotile grid
- Global
- Histogram
- IP prefix
- IP range
- Missing
- Multi Terms
- Nested
- Parent
- Random sampler
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Time series
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Average bucket
- Bucket script
- Bucket count K-S test
- Bucket correlation
- Bucket selector
- Bucket sort
- Change point
- Cumulative cardinality
- Cumulative sum
- Derivative
- Extended stats bucket
- Inference bucket
- Max bucket
- Min bucket
- Moving function
- Moving percentiles
- Normalize
- Percentiles bucket
- Serial differencing
- Stats bucket
- Sum bucket
- Bucket aggregations
- Geospatial analysis
- Watcher
- Monitor a cluster
- Secure the Elastic Stack
- Elasticsearch security principles
- Start the Elastic Stack with security enabled automatically
- Manually configure security
- Updating node security certificates
- User authentication
- Built-in users
- Service accounts
- Internal users
- Token-based authentication services
- User profiles
- Realms
- Realm chains
- Security domains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- JWT authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Looking up users without authentication
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Role restriction
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enable audit logging
- Restricting connections with IP filtering
- Securing clients and integrations
- Operator privileges
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Set up a cluster for high availability
- Optimizations
- Autoscaling
- Snapshot and restore
- REST APIs
- API conventions
- Common options
- REST API compatibility
- Autoscaling APIs
- Behavioral Analytics APIs
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat component templates
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Prevalidate node removal
- Nodes reload secure settings
- Nodes stats
- Cluster Info
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Create or update desired nodes
- Get desired nodes
- Delete desired nodes
- Get desired balance
- Reset desired balance
- Cross-cluster replication APIs
- Connector APIs
- Create connector
- Delete connector
- Get connector
- List connectors
- Update connector API key id
- Update connector configuration
- Update connector index name
- Update connector features
- Update connector filtering
- Update connector name and description
- Update connector pipeline
- Update connector scheduling
- Update connector service type
- Create connector sync job
- Cancel connector sync job
- Delete connector sync job
- Get connector sync job
- List connector sync jobs
- Check in a connector
- Update connector error
- Update connector last sync stats
- Update connector status
- Check in connector sync job
- Claim connector sync job
- Set connector sync job error
- Set connector sync job stats
- Data stream APIs
- Document APIs
- Enrich APIs
- EQL APIs
- ES|QL APIs
- Features APIs
- Fleet APIs
- Graph explore API
- Index APIs
- Alias exists
- Aliases
- Analyze
- Analyze index disk usage
- Clear cache
- Clone index
- Close index
- Create index
- Create or update alias
- Create or update component template
- Create or update index template
- Create or update index template (legacy)
- Delete component template
- Delete dangling index
- Delete alias
- Delete index
- Delete index template
- Delete index template (legacy)
- Exists
- Field usage stats
- Flush
- Force merge
- Get alias
- Get component template
- Get field mapping
- Get index
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Import dangling index
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- List dangling indices
- Open index
- Refresh
- Resolve index
- Resolve cluster
- Rollover
- Shrink index
- Simulate index
- Simulate template
- Split index
- Unfreeze index
- Update index settings
- Update mapping
- Index lifecycle management APIs
- Create or update lifecycle policy
- Get policy
- Delete policy
- Move to step
- Remove policy
- Retry policy
- Get index lifecycle management status
- Explain lifecycle
- Start index lifecycle management
- Stop index lifecycle management
- Migrate indices, ILM policies, and legacy, composable and component templates to data tiers routing
- Inference APIs
- Delete inference API
- Get inference API
- Perform inference API
- Create inference API
- Stream inference API
- Update inference API
- AlibabaCloud AI Search inference service
- Amazon Bedrock inference service
- Anthropic inference service
- Azure AI studio inference service
- Azure OpenAI inference service
- Cohere inference service
- Elasticsearch inference service
- ELSER inference service
- Google AI Studio inference service
- Google Vertex AI inference service
- HuggingFace inference service
- Mistral inference service
- OpenAI inference service
- Watsonx inference service
- Info API
- Ingest APIs
- Licensing APIs
- Logstash APIs
- Machine learning APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get model snapshots
- Get model snapshot upgrade statistics
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Reset jobs
- Revert model snapshots
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Upgrade model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Delete data frame analytics jobs
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Preview data frame analytics
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Update data frame analytics jobs
- Machine learning trained model APIs
- Clear trained model deployment cache
- Create or update trained model aliases
- Create part of a trained model
- Create trained models
- Create trained model vocabulary
- Delete trained model aliases
- Delete trained models
- Get trained models
- Get trained models stats
- Infer trained model
- Start trained model deployment
- Stop trained model deployment
- Update trained model deployment
- Migration APIs
- Node lifecycle APIs
- Query rules APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Root API
- Script APIs
- Search APIs
- Search Application APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Clear service account token caches
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Bulk create or update roles API
- Bulk delete roles API
- Create or update users
- Create service account tokens
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete service account token
- Delete users
- Disable users
- Enable users
- Enroll Kibana
- Enroll node
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Query Role
- Get service accounts
- Get service account credentials
- Get Security settings
- Get token
- Get user privileges
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- Query API key information
- Query User
- Update API key
- Update Security settings
- Bulk update API keys
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SAML complete logout
- SAML service provider metadata
- SSL certificate
- Activate user profile
- Disable user profile
- Enable user profile
- Get user profiles
- Suggest user profile
- Update user profile data
- Has privileges user profile
- Create Cross-Cluster API key
- Update Cross-Cluster API key
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- SQL APIs
- Synonyms APIs
- Text structure APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Command line tools
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- Troubleshooting
- Fix common cluster issues
- Diagnose unassigned shards
- Add a missing tier to the system
- Allow Elasticsearch to allocate the data in the system
- Allow Elasticsearch to allocate the index
- Indices mix index allocation filters with data tiers node roles to move through data tiers
- Not enough nodes to allocate all shard replicas
- Total number of shards for an index on a single node exceeded
- Total number of shards per node has been reached
- Troubleshooting corruption
- Fix data nodes out of disk
- Fix master nodes out of disk
- Fix other role nodes out of disk
- Start index lifecycle management
- Start Snapshot Lifecycle Management
- Restore from snapshot
- Troubleshooting broken repositories
- Addressing repeated snapshot policy failures
- Troubleshooting an unstable cluster
- Troubleshooting discovery
- Troubleshooting monitoring
- Troubleshooting transforms
- Troubleshooting Watcher
- Troubleshooting searches
- Troubleshooting shards capacity health issues
- Troubleshooting an unbalanced cluster
- Capture diagnostics
- Upgrade Elasticsearch
- Migration guide
- What’s new in 8.16
- Release notes
- Elasticsearch version 8.16.2
- Elasticsearch version 8.16.1
- Elasticsearch version 8.16.0
- Elasticsearch version 8.15.5
- Elasticsearch version 8.15.4
- Elasticsearch version 8.15.3
- Elasticsearch version 8.15.2
- Elasticsearch version 8.15.1
- Elasticsearch version 8.15.0
- Elasticsearch version 8.14.3
- Elasticsearch version 8.14.2
- Elasticsearch version 8.14.1
- Elasticsearch version 8.14.0
- Elasticsearch version 8.13.4
- Elasticsearch version 8.13.3
- Elasticsearch version 8.13.2
- Elasticsearch version 8.13.1
- Elasticsearch version 8.13.0
- Elasticsearch version 8.12.2
- Elasticsearch version 8.12.1
- Elasticsearch version 8.12.0
- Elasticsearch version 8.11.4
- Elasticsearch version 8.11.3
- Elasticsearch version 8.11.2
- Elasticsearch version 8.11.1
- Elasticsearch version 8.11.0
- Elasticsearch version 8.10.4
- Elasticsearch version 8.10.3
- Elasticsearch version 8.10.2
- Elasticsearch version 8.10.1
- Elasticsearch version 8.10.0
- Elasticsearch version 8.9.2
- Elasticsearch version 8.9.1
- Elasticsearch version 8.9.0
- Elasticsearch version 8.8.2
- Elasticsearch version 8.8.1
- Elasticsearch version 8.8.0
- Elasticsearch version 8.7.1
- Elasticsearch version 8.7.0
- Elasticsearch version 8.6.2
- Elasticsearch version 8.6.1
- Elasticsearch version 8.6.0
- Elasticsearch version 8.5.3
- Elasticsearch version 8.5.2
- Elasticsearch version 8.5.1
- Elasticsearch version 8.5.0
- Elasticsearch version 8.4.3
- Elasticsearch version 8.4.2
- Elasticsearch version 8.4.1
- Elasticsearch version 8.4.0
- Elasticsearch version 8.3.3
- Elasticsearch version 8.3.2
- Elasticsearch version 8.3.1
- Elasticsearch version 8.3.0
- Elasticsearch version 8.2.3
- Elasticsearch version 8.2.2
- Elasticsearch version 8.2.1
- Elasticsearch version 8.2.0
- Elasticsearch version 8.1.3
- Elasticsearch version 8.1.2
- Elasticsearch version 8.1.1
- Elasticsearch version 8.1.0
- Elasticsearch version 8.0.1
- Elasticsearch version 8.0.0
- Elasticsearch version 8.0.0-rc2
- Elasticsearch version 8.0.0-rc1
- Elasticsearch version 8.0.0-beta1
- Elasticsearch version 8.0.0-alpha2
- Elasticsearch version 8.0.0-alpha1
- Dependencies and versions
Ingest pipelines in Search
editIngest pipelines in Search
editYou can manage ingest pipelines through Elasticsearch APIs or Kibana UIs.
The Content UI under Search has a set of tools for creating and managing indices optimized for search use cases (non time series data). You can also manage your ingest pipelines in this UI.
Find pipelines in Content UI
editTo work with ingest pipelines using these UI tools, you’ll be using the Pipelines tab on your search-optimized Elasticsearch index.
To find this tab in the Kibana UI:
- Go to Search > Content > Elasticsearch indices.
-
Select the index you want to work with. For example,
search-my-index. - On the index’s overview page, open the Pipelines tab.
- From here, you can follow the instructions to create custom pipelines, and set up ML inference pipelines.
The tab is highlighted in this screenshot:
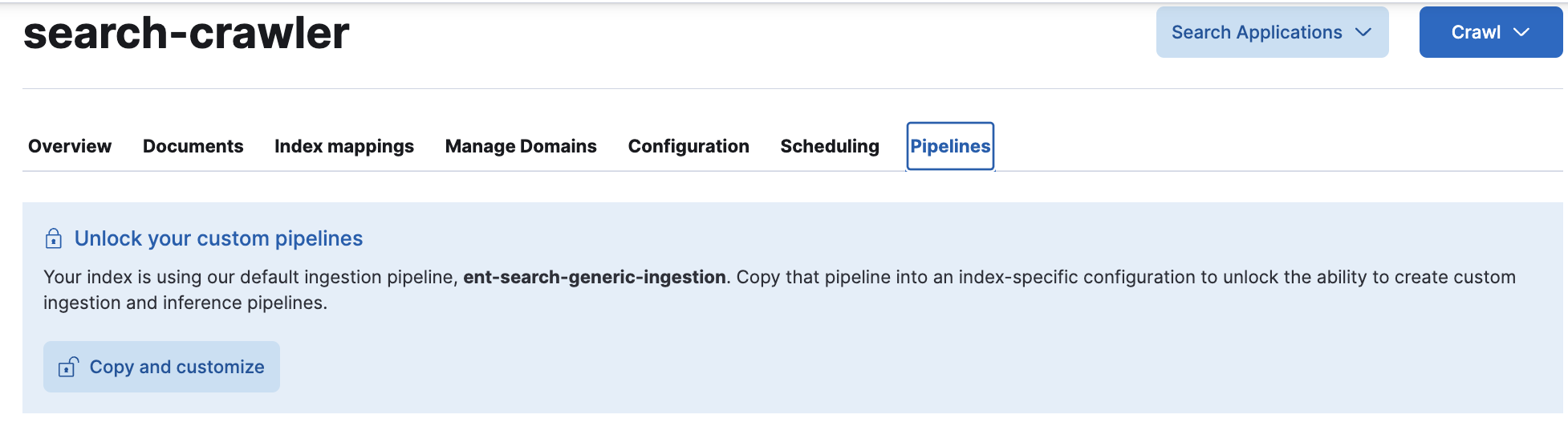
Overview
editThese tools can be particularly helpful by providing a layer of customization and post-processing of documents. For example:
- providing consistent extraction of text from binary data types
- ensuring consistent formatting
- providing consistent sanitization steps (removing PII like phone numbers or SSN’s)
It can be a lot of work to set up and manage production-ready pipelines from scratch. Considerations such as error handling, conditional execution, sequencing, versioning, and modularization must all be taken into account.
To this end, when you create indices for search use cases, (including Elastic web crawler, connectors. , and API indices), each index already has a pipeline set up with several processors that optimize your content for search.
This pipeline is called ent-search-generic-ingestion.
While it is a "managed" pipeline (meaning it should not be tampered with), you can view its details via the Kibana UI or the Elasticsearch API.
You can also read more about its contents below.
You can control whether you run some of these processors. While all features are enabled by default, they are eligible for opt-out. For Elastic crawler and connectors. , you can opt out (or back in) per index, and your choices are saved. For API indices, you can opt out (or back in) by including specific fields in your documents. See below for details.
At the deployment level, you can change the default settings for all new indices. This will not effect existing indices.
Each index also provides the capability to easily create index-specific ingest pipelines with customizable processing.
If you need that extra flexibility, you can create a custom pipeline by going to your pipeline settings and choosing to "copy and customize".
This will replace the index’s use of ent-search-generic-ingestion with 3 newly generated pipelines:
-
<index-name> -
<index-name>@custom -
<index-name>@ml-inference
Like ent-search-generic-ingestion, the first of these is "managed", but the other two can and should be modified to fit your needs.
You can view these pipelines using the platform tools (Kibana UI, Elasticsearch API), and can also
read more about their content below.
Pipeline Settings
editAside from the pipeline itself, you have a few configuration options which control individual features of the pipelines.
- Extract Binary Content - This controls whether or not binary documents should be processed and any textual content should be extracted.
- Reduce Whitespace - This controls whether or not consecutive, leading, and trailing whitespaces should be removed. This can help to display more content in some search experiences.
-
Run ML Inference - Only available on index-specific pipelines.
This controls whether or not the optional
<index-name>@ml-inferencepipeline will be run. Enabled by default.
For Elastic web crawler and connectors, you can opt in or out per index.
These settings are stored in Elasticsearch in the .elastic-connectors index, in the document that corresponds to the specific index.
These settings can be changed there directly, or through the Kibana UI at Search > Content > Indices > <your index> > Pipelines > Settings.
You can also change the deployment wide defaults.
These settings are stored in the Elasticsearch mapping for .elastic-connectors in the _meta section.
These settings can be changed there directly, or from the Kibana UI at Search > Content > Settings tab.
Changing the deployment wide defaults will not impact any existing indices, but will only impact any newly created indices defaults.
Those defaults will still be able to be overriden by the index-specific settings.
Using the API
editThese settings are not persisted for indices that "Use the API". Instead, changing these settings will, in real time, change the example cURL request displayed. Notice that the example document in the cURL request contains three underscore-prefixed fields:
{ ... "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true }
Omitting one of these special fields is the same as specifying it with the value false.
You must also specify the pipeline in your indexing request. This is also shown in the example cURL request.
If the pipeline is not specified, the underscore-prefixed fields will actually be indexed, and will not impact any processing behaviors.
Details
editent-search-generic-ingestion Reference
editYou can access this pipeline with the Elasticsearch Ingest Pipelines API or via Kibana’s Stack Management > Ingest Pipelines UI.
This pipeline is a "managed" pipeline.
That means that it is not intended to be edited.
Editing/updating this pipeline manually could result in unintended behaviors, or difficulty in upgrading in the future.
If you want to make customizations, we recommend you utilize index-specific pipelines (see below), specifically the <index-name>@custom pipeline.
Processors
edit-
attachment- this uses the Attachment processor to convert any binary data stored in a document’s_attachmentfield to a nested object of plain text and metadata. -
set_body- this uses the Set processor to copy any plain text extracted from the previous step and persist it on the document in thebodyfield. -
remove_replacement_chars- this uses the Gsub processor to remove characters like "�" from thebodyfield. -
remove_extra_whitespace- this uses the Gsub processor to replace consecutive whitespace characters with single spaces in thebodyfield. While not perfect for every use case (see below for how to disable), this can ensure that search experiences display more content and highlighting and less empty space for your search results. -
trim- this uses the Trim processor to remove any remaining leading or trailing whitespace from thebodyfield. -
remove_meta_fields- this final step of the pipeline uses the Remove processor to remove special fields that may have been used elsewhere in the pipeline, whether as temporary storage or as control flow parameters.
Control flow parameters
editThe ent-search-generic-ingestion pipeline does not always run all processors.
It utilizes a feature of ingest pipelines to conditionally run processors based on the contents of each individual document.
-
_extract_binary_content- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theattachment,set_body, andremove_replacement_charsprocessors. Note that the document will also need an_attachmentfield populated with base64-encoded binary data in order for theattachmentprocessor to have any output. If the_extract_binary_contentfield is missing orfalseon a source document, these processors will be skipped. -
_reduce_whitespace- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theremove_extra_whitespaceandtrimprocessors. These processors only apply to thebodyfield. If the_reduce_whitespacefield is missing orfalseon a source document, these processors will be skipped.
Crawler, Native Connectors, and Connector Clients will automatically add these control flow parameters based on the settings in the index’s Pipeline tab. To control what settings any new indices will have upon creation, see the deployment wide content settings. See Pipeline Settings.
Index-specific ingest pipelines
editIn the Kibana UI for your index, by clicking on the Pipelines tab, then Settings > Copy and customize, you can quickly generate 3 pipelines which are specific to your index.
These 3 pipelines replace ent-search-generic-ingestion for the index.
There is nothing lost in this action, as the <index-name> pipeline is a superset of functionality over the ent-search-generic-ingestion pipeline.
The "copy and customize" button is not available at all Elastic subscription levels. Refer to the Elastic subscriptions pages for Elastic Cloud and self-managed deployments.
<index-name> Reference
editThis pipeline looks and behaves a lot like the ent-search-generic-ingestion pipeline, but with two additional processors.
You should not rename this pipeline.
This pipeline is a "managed" pipeline.
That means that it is not intended to be edited.
Editing/updating this pipeline manually could result in unintended behaviors, or difficulty in upgrading in the future.
If you want to make customizations, we recommend you utilize the <index-name>@custom pipeline.
Processors
editIn addition to the processors inherited from the ent-search-generic-ingestion pipeline, the index-specific pipeline also defines:
-
index_ml_inference_pipeline- this uses the Pipeline processor to run the<index-name>@ml-inferencepipeline. This processor will only be run if the source document includes a_run_ml_inferencefield with the valuetrue. -
index_custom_pipeline- this uses the Pipeline processor to run the<index-name>@custompipeline.
Control flow parameters
editLike the ent-search-generic-ingestion pipeline, the <index-name> pipeline does not always run all processors.
In addition to the _extract_binary_content and _reduce_whitespace control flow parameters, the <index-name> pipeline also supports:
-
_run_ml_inference- if this field is present and has a value oftrueon a source document, the pipeline will attempt to run theindex_ml_inference_pipelineprocessor. If the_run_ml_inferencefield is missing orfalseon a source document, this processor will be skipped.
Crawler, Native Connectors, and Connector Clients will automatically add these control flow parameters based on the settings in the index’s Pipeline tab. To control what settings any new indices will have upon creation, see the deployment wide content settings. See Pipeline Settings.
<index-name>@ml-inference Reference
editThis pipeline is empty to start (no processors), but can be added to via the Kibana UI either through the Pipelines tab of your index, or from the Stack Management > Ingest Pipelines page.
Unlike the ent-search-generic-ingestion pipeline and the <index-name> pipeline, this pipeline is NOT "managed".
It’s possible to add one or more ML inference pipelines to an index in the Content UI.
This pipeline will serve as a container for all of the ML inference pipelines configured for the index.
Each ML inference pipeline added to the index is referenced within <index-name>@ml-inference using a pipeline processor.
You should not rename this pipeline.
The monitor_ml Elasticsearch cluster permission is required in order to manage ML models and ML inference pipelines which use those models.
<index-name>@custom Reference
editThis pipeline is empty to start (no processors), but can be added to via the Kibana UI either through the Pipelines
tab of your index, or from the Stack Management > Ingest Pipelines page.
Unlike the ent-search-generic-ingestion pipeline and the <index-name> pipeline, this pipeline is NOT "managed".
You are encouraged to make additions and edits to this pipeline, provided its name remains the same. This provides a convenient hook from which to add custom processing and transformations for your data. Be sure to read the docs for ingest pipelines to see what options are available.
You should not rename this pipeline.
Upgrading notes
editExpand to see upgrading notes
-
app_search_crawler- Since 8.3, App Search web crawler has utilized this pipeline to power its binary content extraction. You can read more about this pipeline and its usage in the App Search Guide. When upgrading from 8.3 to 8.5+, be sure to note any changes that you made to theapp_search_crawlerpipeline. These changes should be re-applied to each index’s<index-name>@custompipeline in order to ensure a consistent data processing experience. In 8.5+, the index setting to enable binary content is required in addition to the configurations mentioned in the App Search Guide. -
ent_search_crawler- Since 8.4, the Elastic web crawler has utilized this pipeline to power its binary content extraction. You can read more about this pipeline and its usage in the Elastic web crawler Guide. When upgrading from 8.4 to 8.5+, be sure to note any changes that you made to theent_search_crawlerpipeline. These changes should be re-applied to each index’s<index-name>@custompipeline in order to ensure a consistent data processing experience. In 8.5+, the index setting to enable binary content is required in addition to the configurations mentioned in the Elastic web crawler Guide. -
ent-search-generic-ingestion- Since 8.5, Native Connectors, Connector Clients, and new (>8.4) Elastic web crawler indices will all make use of this pipeline by default. You can read more about this pipeline above. As this pipeline is "managed", any modifications that were made toapp_search_crawlerand/orent_search_crawlershould NOT be made toent-search-generic-ingestion. Instead, if such customizations are desired, you should utilize Index-specific ingest pipelines, placing all modifications in the<index-name>@custompipeline(s).
On this page
ElasticON events are back!
Learn about the Elastic Search AI Platform from the experts at our live events.
Register now