Cardinality aggregation
editCardinality aggregation
editA single-value metrics aggregation that calculates an approximate count of
distinct values.
Assume you are indexing store sales and would like to count the unique number of sold products that match a query:
response = client.search( index: 'sales', size: 0, body: { aggregations: { type_count: { cardinality: { field: 'type' } } } } ) puts response
POST /sales/_search?size=0 { "aggs": { "type_count": { "cardinality": { "field": "type" } } } }
Response:
{ ... "aggregations": { "type_count": { "value": 3 } } }
Precision control
editThis aggregation also supports the precision_threshold option:
response = client.search( index: 'sales', size: 0, body: { aggregations: { type_count: { cardinality: { field: 'type', precision_threshold: 100 } } } } ) puts response
POST /sales/_search?size=0 { "aggs": { "type_count": { "cardinality": { "field": "type", "precision_threshold": 100 } } } }
|
The |
Counts are approximate
editComputing exact counts requires loading values into a hash set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This cardinality aggregation is based on the
HyperLogLog++
algorithm, which counts based on the hashes of the values with some interesting
properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of c, the implementation that we are using requires
about c * 8 bytes.
The following chart shows how the error varies before and after the threshold:
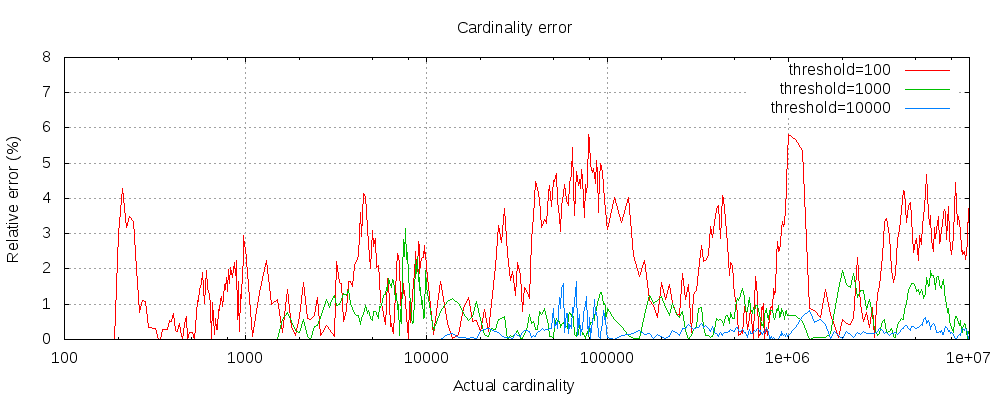
For all 3 thresholds, counts have been accurate up to the configured threshold. Although not guaranteed, this is likely to be the case. Accuracy in practice depends on the dataset in question. In general, most datasets show consistently good accuracy. Also note that even with a threshold as low as 100, the error remains very low (1-6% as seen in the above graph) even when counting millions of items.
The HyperLogLog++ algorithm depends on the leading zeros of hashed values, the exact distributions of hashes in a dataset can affect the accuracy of the cardinality.
Pre-computed hashes
editOn string fields that have a high cardinality, it might be faster to store the
hash of your field values in your index and then run the cardinality aggregation
on this field. This can either be done by providing hash values from client-side
or by letting Elasticsearch compute hash values for you by using the
mapper-murmur3 plugin.
Pre-computing hashes is usually only useful on very large and/or high-cardinality fields as it saves CPU and memory. However, on numeric fields, hashing is very fast and storing the original values requires as much or less memory than storing the hashes. This is also true on low-cardinality string fields, especially given that those have an optimization in order to make sure that hashes are computed at most once per unique value per segment.
Script
editIf you need the cardinality of the combination of two fields, create a runtime field combining them and aggregate it.
response = client.search( index: 'sales', size: 0, body: { runtime_mappings: { type_and_promoted: { type: 'keyword', script: "emit(doc['type'].value + ' ' + doc['promoted'].value)" } }, aggregations: { type_promoted_count: { cardinality: { field: 'type_and_promoted' } } } } ) puts response
POST /sales/_search?size=0 { "runtime_mappings": { "type_and_promoted": { "type": "keyword", "script": "emit(doc['type'].value + ' ' + doc['promoted'].value)" } }, "aggs": { "type_promoted_count": { "cardinality": { "field": "type_and_promoted" } } } }
Missing value
editThe missing parameter defines how documents that are missing a value should be treated.
By default they will be ignored but it is also possible to treat them as if they
had a value.
response = client.search( index: 'sales', size: 0, body: { aggregations: { tag_cardinality: { cardinality: { field: 'tag', missing: 'N/A' } } } } ) puts response
POST /sales/_search?size=0 { "aggs": { "tag_cardinality": { "cardinality": { "field": "tag", "missing": "N/A" } } } }
|
Documents without a value in the |
There are different mechanisms by which cardinality aggregations can be executed:
-
by using field values directly (
direct) -
by using global ordinals of the field and resolving those values after
finishing a shard (
global_ordinals) -
by using segment ordinal values and resolving those values after each
segment (
segment_ordinals)
Additionally, there are two "heuristic based" modes. These modes will cause
Elasticsearch to use some data about the state of the index to choose an
appropriate execution method. The two heuristics are:
- save_time_heuristic - this is the default in Elasticsearch 8.4 and later.
- save_memory_heuristic - this was the default in Elasticsearch 8.3 and
earlier
When not specified, Elasticsearch will apply a heuristic to chose the
appropriate mode. Also note that some data (i.e. non-ordinal fields), direct
is the only option, and the hint will be ignored in these cases. Generally
speaking, it should not be necessary to set this value.