Add a service name to logs
editAdd a service name to logs
editAdding the service.name field to your logs associates them with the services that generate them.
You can use this field to view and manage logs for distributed services located on multiple hosts.
To add a service name to your logs, either:
-
Use the
add_fieldsprocessor through an integration, Elastic Agent configuration, or Filebeat configuration. -
Map an existing field from your data stream to the
service.namefield.
Use the add fields processor to add a service name
editFor log data without a service name, use the add_fields processor to add the service.name field.
You can add the processor in an integration’s settings or in the Elastic Agent or Filebeat configuration.
For example, adding the add_fields processor to the inputs section of a standalone Elastic Agent or Filebeat configuration would add your_service_name as the service.name field:
processors:
- add_fields:
target: service
fields:
name: your_service_name
Adding the add_fields processor to an integration’s settings would add your_service_name as the service.name field:
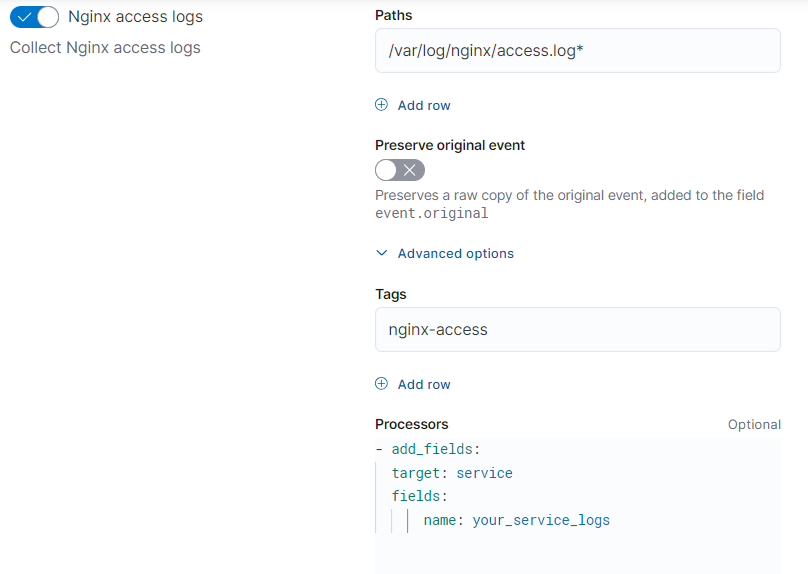
For more on defining processors, refer to define processors.
Map an existing field to the service name field
editFor logs that with an existing field being used to represent the service name, map that field to the service.name field using the alias field type.
Follow these steps to update your mapping:
- From the main Kibana menu, go to Stack Management → Index Management → Index Templates.
- Search for the index template you want to update.
- From the Actions menu for that template, select Edit.
- Go to Mappings, and select Add field.
-
Under Field type, select Alias and add
service.nameto the Field name. - Under Field path, select the existing field you want to map to the service name.
- Select Add field.
For more ways to add a field to your mapping, refer to add a field to an existing mapping.
Additional ways to process data
editThe Elastic Stack provides additional ways to process your data:
- Ingest pipelines: convert data to ECS, normalize field data, or enrich incoming data.
- Logstash: enrich your data using input, output, and filter plugins.