Universal Profiling (beta)
editUniversal Profiling (beta)
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
Elastic Universal Profiling is a continuous profiling tool running on top of the Elastic Stack. For a quick overview of Universal Profiling, see the Universal Profiling product page.
On this page, you’ll find information on:
- inspecting data through stacktraces, flamegraphs, and functions
- filtering your data
- comparing time ranges through differential views
Inspecting data in Kibana
editYou can find Universal Profiling in the Observability navigation menu. Clicking Stacktraces under Universal Profiling opens the stacktraces view.
Universal Profiling currently only supports CPU profiling through stack sampling.
From the Stacktraces view, you get an overview of all of your data. You can also use filtering queries in the search bar to slice your data into more detailed sections of your fleet. Time-based filters and property filters allow you to inspect portions of data and drill-down into how much CPU various parts of your infrastructure consume over time.
See Filtering for more on slicing data and Differential views for more on comparing two time ranges to detect performance improvements or regressions.
Debug symbols
editYour stacktrace can be:
- symbolized, showing the full source code’s filename and line number
- partially symbolized
- not symbolized
In the following screenshot, you can see that unsymbolized frames do not show a filename and line number, but a hexadecimal number such as 0x80d2f4
or <unsymbolized>.
Adding symbols for unsymbolized frames is currently a manual operation. See Add symbols for native frames.

Stacktraces
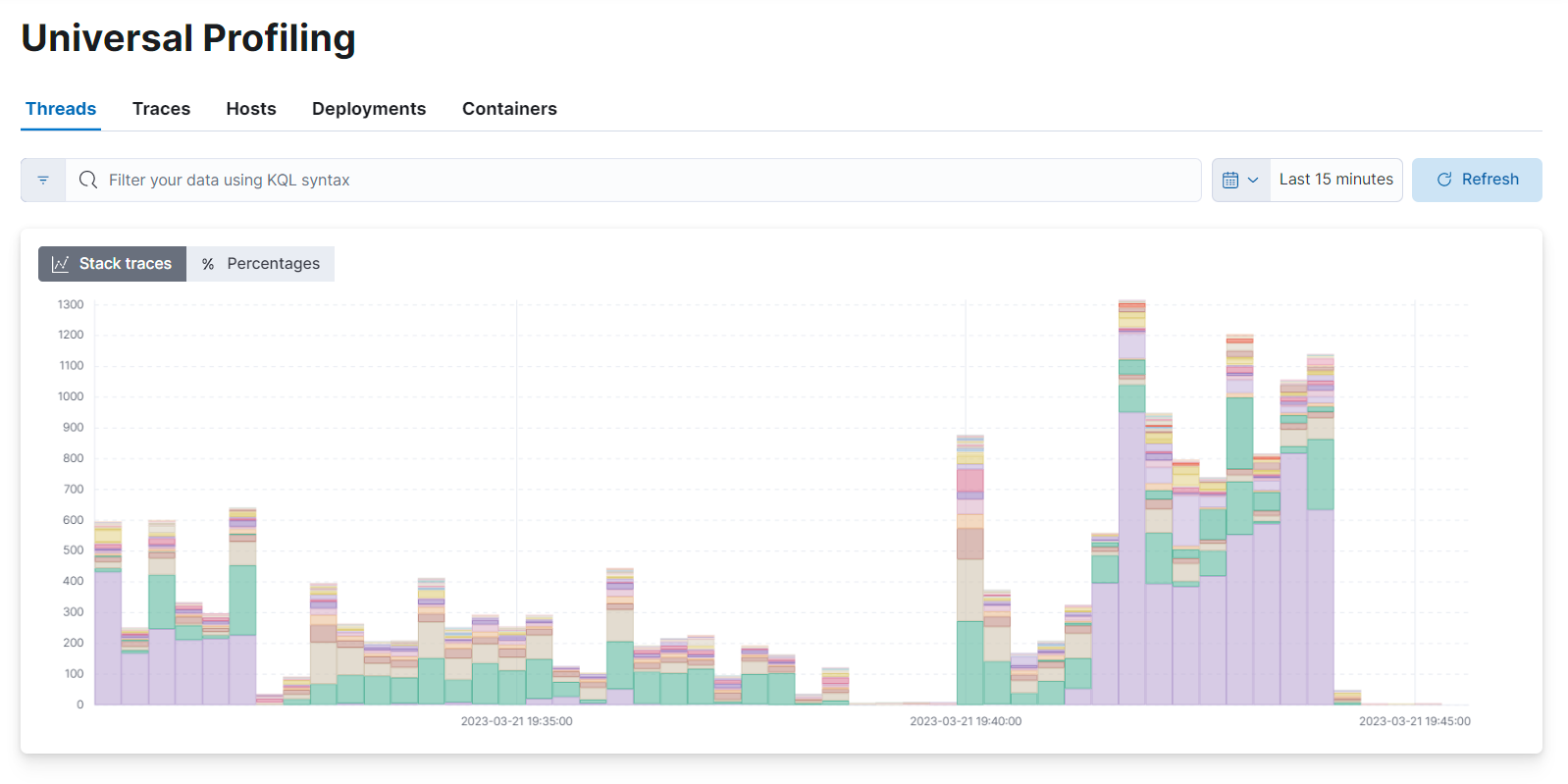
editThe stacktraces view shows graphs of stacktraces grouped by threads, traces, hosts, deployments, and containers:
Overview
editThe different views on the stacktraces page show:
- Threads: stacktraces grouped by the process' thread name
- Traces: un-grouped stacktraces
- Hosts: stacktraces grouped by machine’s hostname or IP address
-
Deployments: stacktraces grouped by deployment name set by the container orchestration (e.g. Kubernetes
ReplicaSet,DaemonSet, orStatefulSetname) - Containers: stacktraces grouped by container name discovered by the host-agent
The stacktraces view provides valuable information that you can use to:
- Discover which container, deployed across multiple machines, is using the most CPU.
- Discover how much relative overhead comes from third-party software running on your machines.
- Detect unexpected CPU spikes across threads, and drill-down into a smaller time range to investigate further with a flamegraph.
Stacktraces are grouped based on the origin of collected stacktraces. You may find an empty view in containers and deployments if your host-agent deployment is profiling systems that do not run any containers or container orchestrators. In a deployment where Universal Profiling is correctly receiving data from host-agents you should always see a graph in the threads, hosts, and traces view.
Navigating the stacktraces view
editHover and click each of the stacked bar chart sections to show details. You can arrange the graph to display absolute values, or relative percentage values.
Below the top graph, there are individual graphs that show the individual trend-line for each of the items:
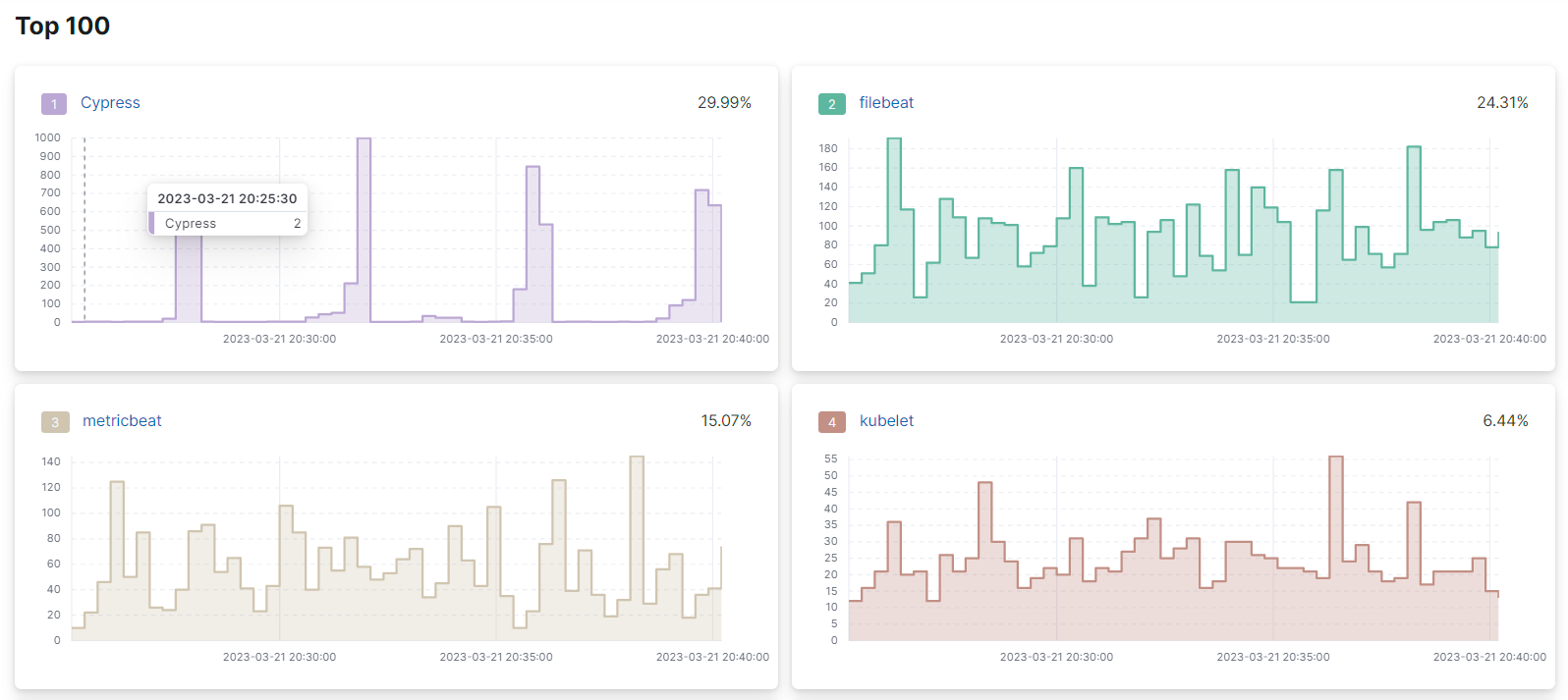
The percentage displayed in the top-right corner of every individual graph is the relative number of occurrences of every time over the total of samples in the group.
The displayed percentage is different from the percentage of CPU usage. Universal Profiling is not meant to show absolute monitoring data. Instead, it allows for relative comparisons between software running in your infrastructure (e.g. which is the most expensive?)
The individual graphs are ordered in decreasing order, from top to bottom, left to right.
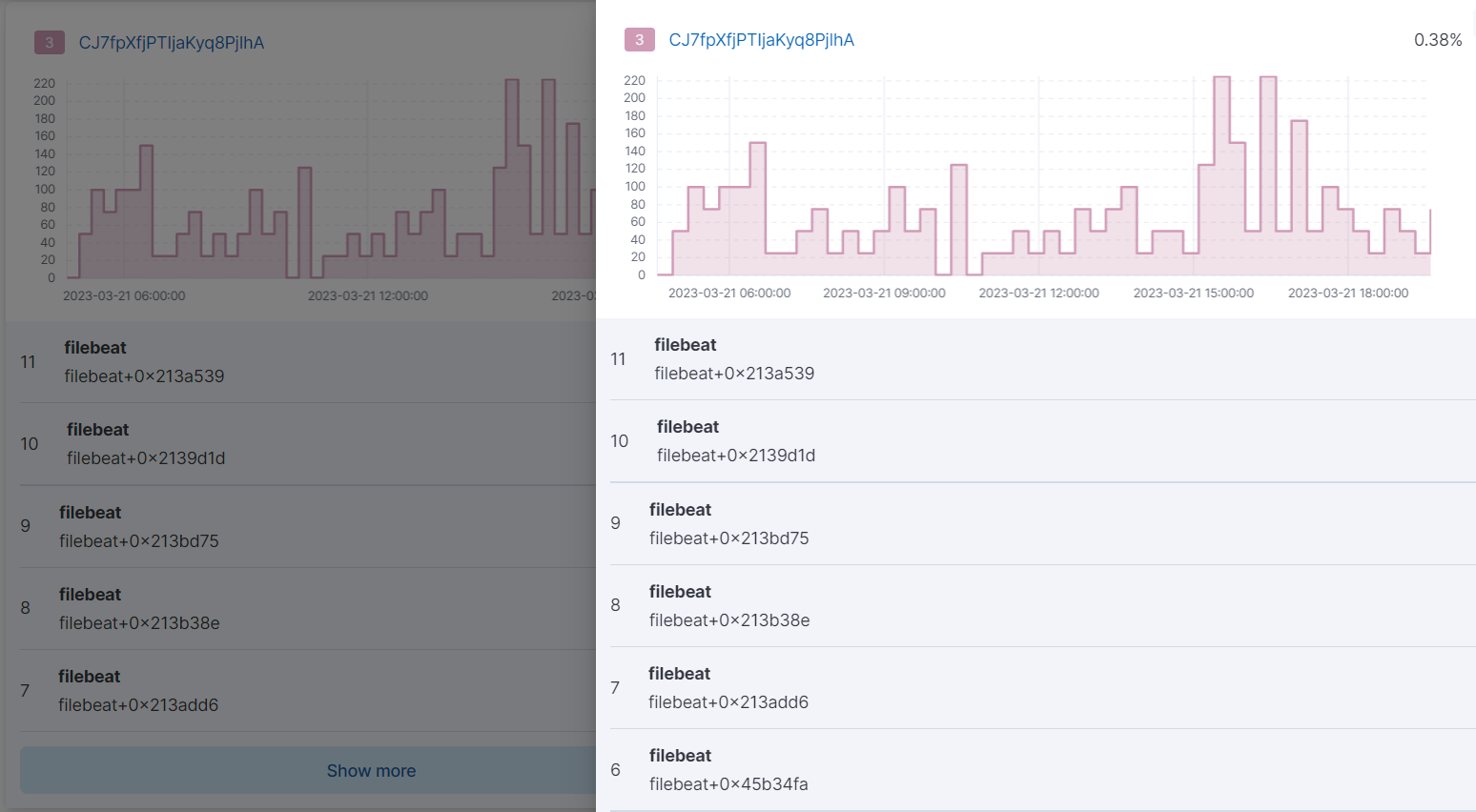
In the Traces tab, clicking Show more at the bottom of one of the individual graphs shows the full stacktrace.
Flamegraphs
editThe flamegraph view groups hierarchical data (stacktraces) into rectangles stacked onto or next to each other. The size of each rectangle represents the relative weight of a child compared to its parent.
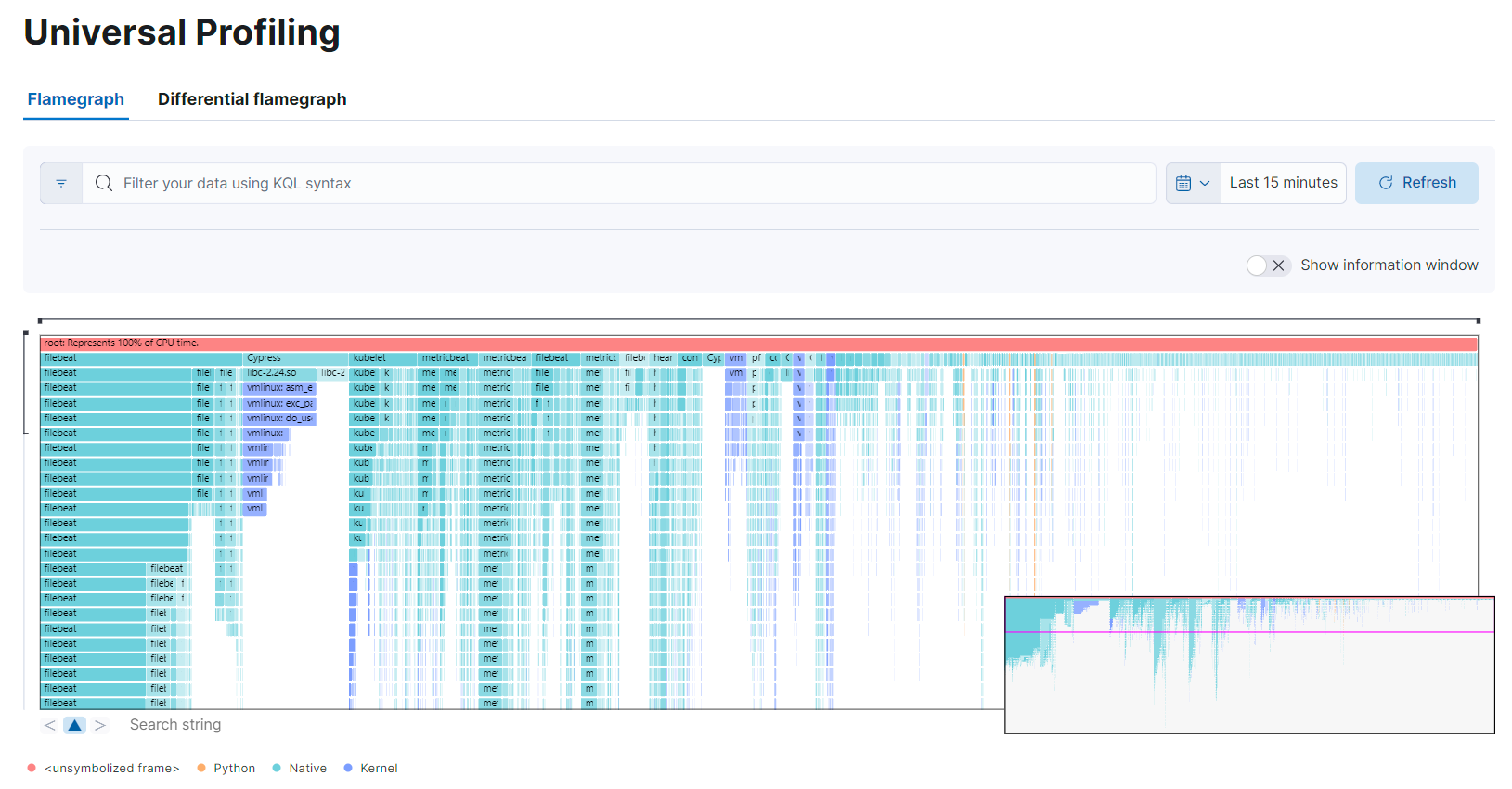
Overview
editFlamegraphs provide immediate feedback on which parts of the software should be searched first for optimization opportunities, highlighting the hottest code paths across your entire infrastructure.
You can use flamegraphs to:
- detect unexpected usage of system calls or native libraries linked to your own software: Universal Profiling is able to unwind stacktraces across user-space boundary into kernel-space
- inspect the call stacks of the most CPU-intensive application, detecting hot code paths and scouting for optimization opportunities
- find "deep" call stack, usually hinting areas where there are many indirections across classes or objects
Navigating the flamegraph view
editYou can navigate a flamegraph on both the horizontal and vertical axes:
-
Horizontal axes: every process that is sampled has at least a rectangle under the
rootframe. In Universal Profiling flamegraphs, you will likely discover the existence of processes you don’t control, but that are eating a significant portion of your CPU resources. - Vertical axes: traversing a process' call stack allow to identify which parts of the process are executing most frequently. This allows pinpointing functions or methods that should be negligible but are instead a big portion of your call sites.
You can drag the graph up, down, right, or left to move the visible area.
You can zoom in and out of a subset of stacktraces, by clicking on individual frames or scrolling up in the colored view.
The summary square in the bottom-left corner of the graph lets you shift the visible area of the graph. The position of the summary square in the bottom-right corner adjusts when you drag the flamegraph, and moving the summary square adjusts the visible area in the bigger panel.
Enabling Show information window on the top right opens the Frame information window. Clicking a rectangle in the flamegraph highlights the frame’s detail in the window.
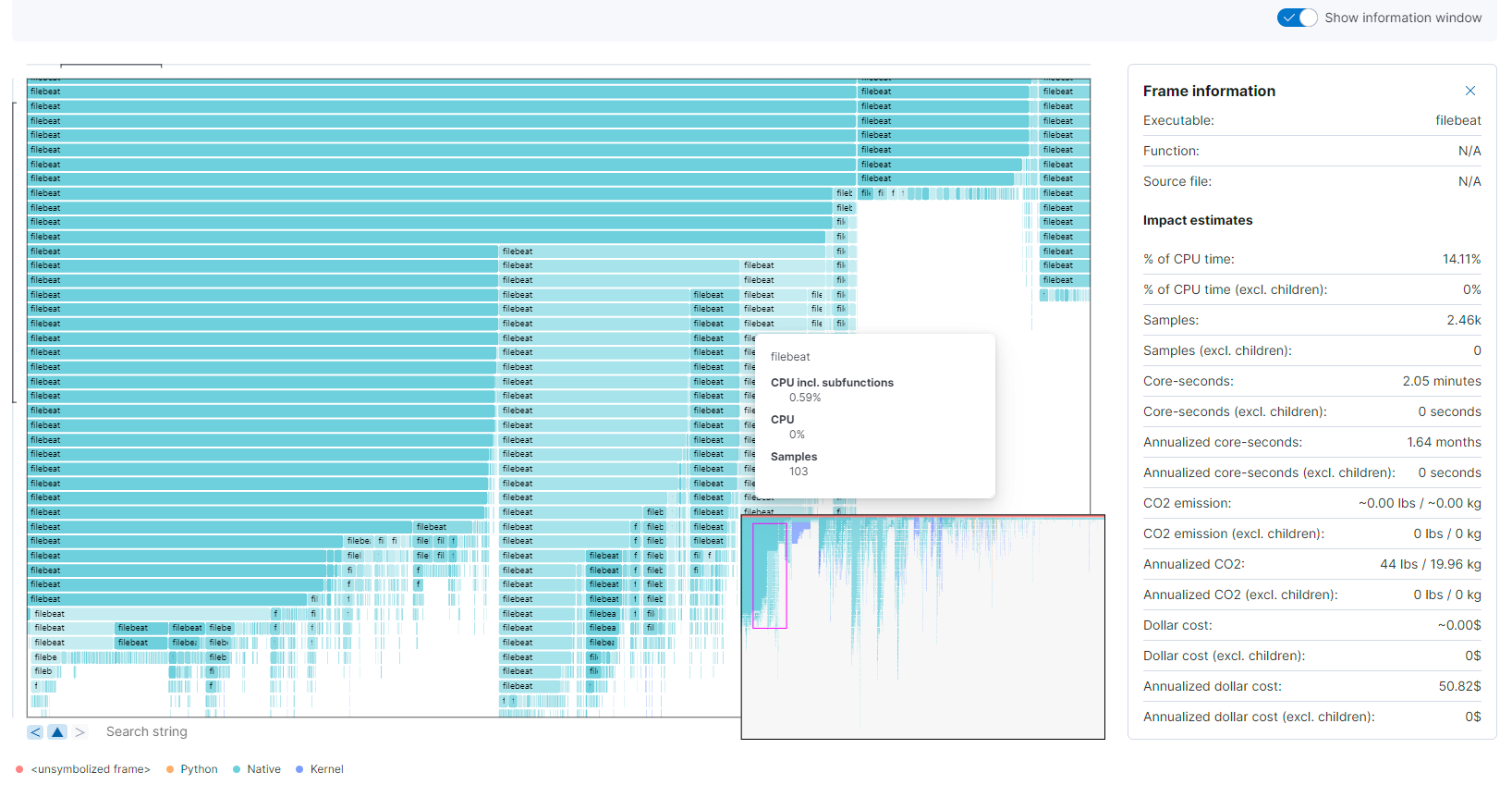
Below the graph area, a search bar allows to highlight specific text in the flamegraph; here you may search binaries, function or file names and move over the occurrences.
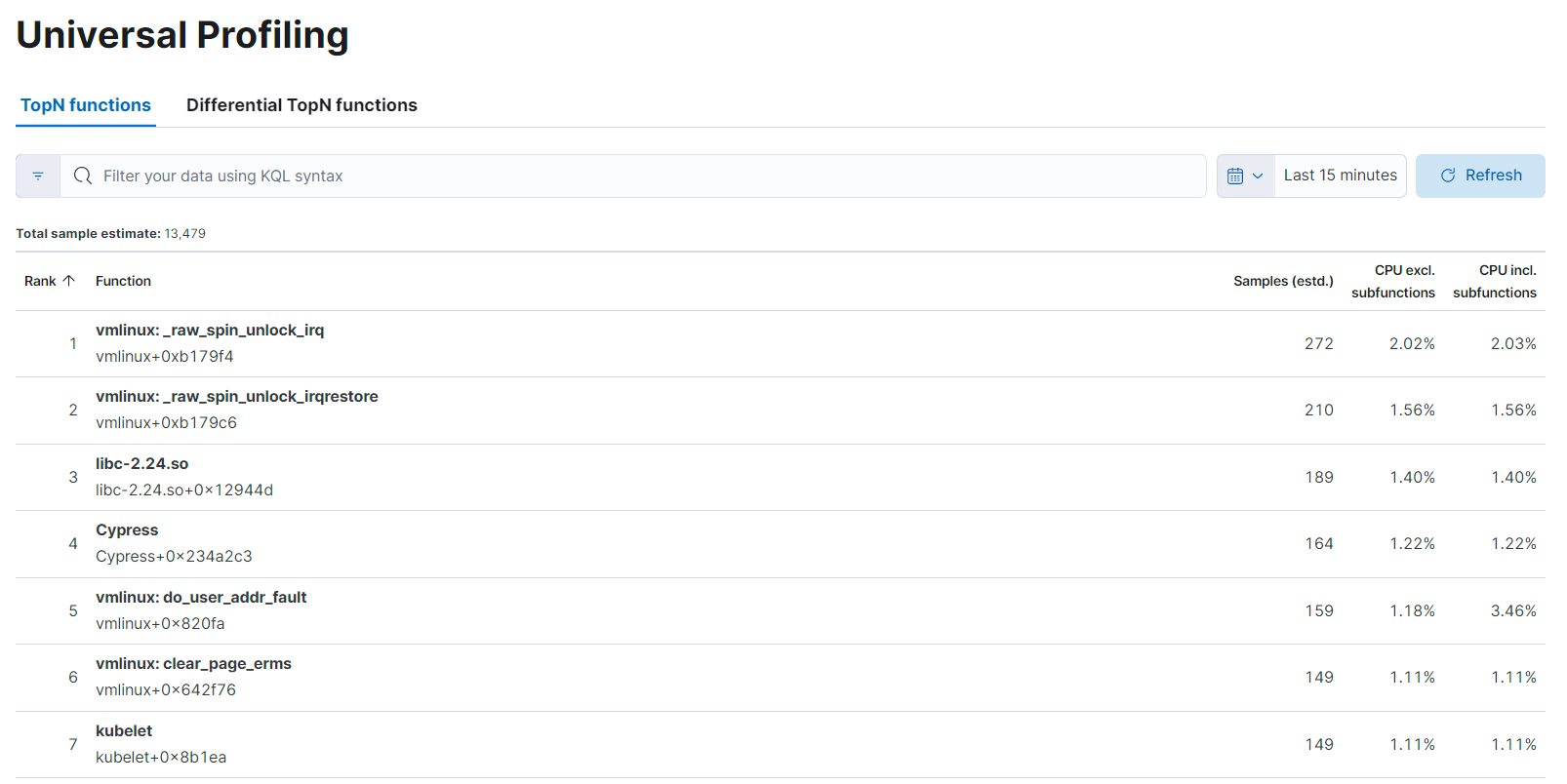
Functions
editThe functions view presents an ordered list of functions that Universal Profiling samples most often. From this view, you can spot the functions that are running the most across your entire infrastructure, applying filters to drill down into individual components.
Filtering
editIn all of the Universal Profiling views, the search bar accepts a filter in the Kibana Query Language (KQL).
Most notably, you may want to filter on:
-
service.name: the corresponding value ofproject-idhost-agent flag, logical group of deployed host-agents -
process.thread.name: the process' thread name, e.g.python,java, orkauditd -
orchestrator.resource.name: the name of the group of the containerized deployment as set by the orchestrator -
container.name: the name of the single container instance, as set by the container engine -
host.nameorhost.ipstring: the machine’s hostname or IP address (useful for debugging issues on a single Virtual Machine)
Differential views
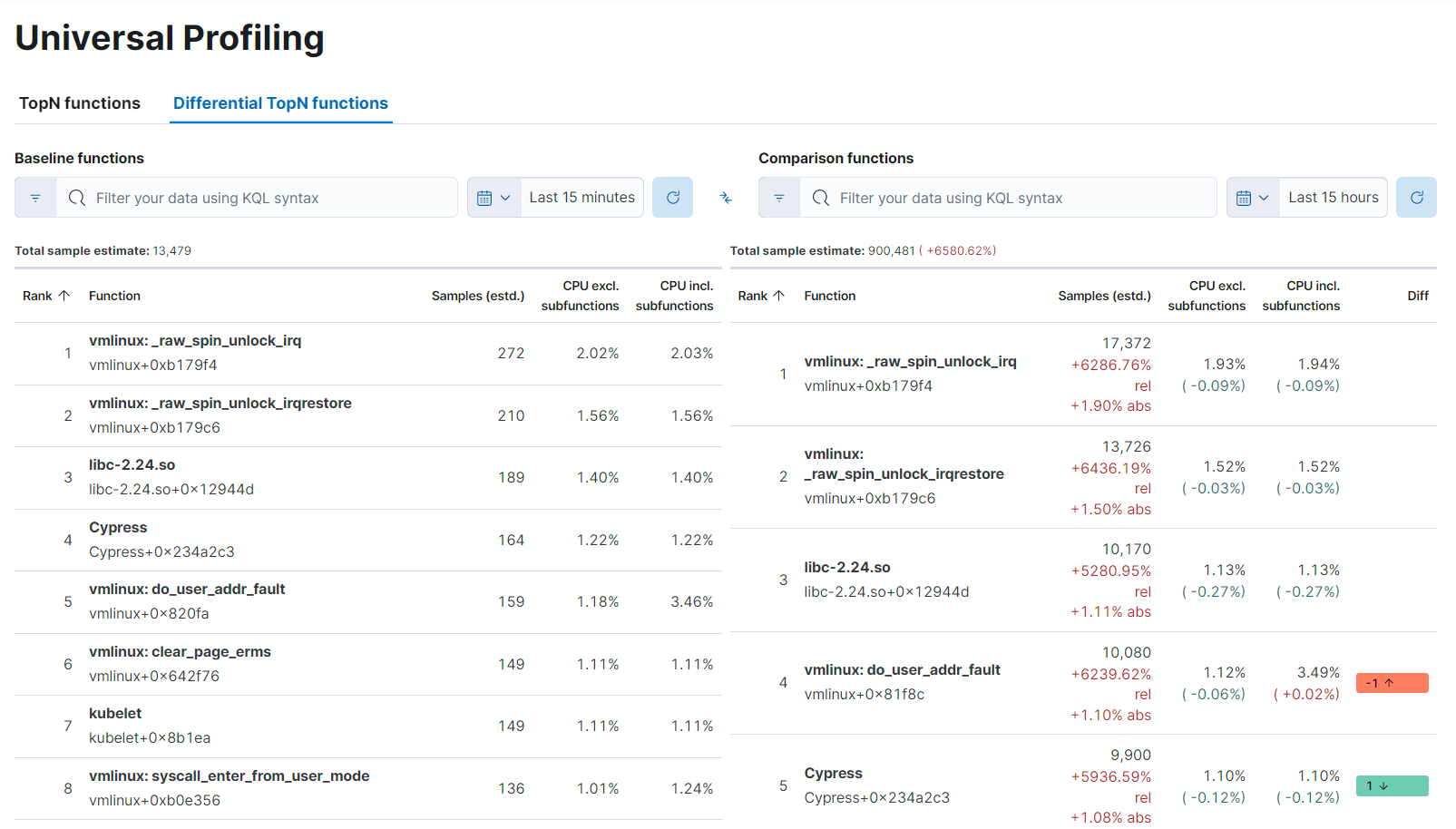
editThe flamegraphs and functions views can be turned into differential views, comparing data from two distinct time ranges or across multiple dimensions.
When switching to Differential flamegraph or Differential TopN functions from the tabs at the top, you see two separate search bars and datetime pickers. The left-most filters represent the data you want to use as baseline for comparison, while the right-most filters represents the data that will be compared against the baseline.
Hitting refresh on each of the data filters triggers a frequency comparison that highlights the CPU usage change.
In differential functions, the right-most column of functions has green or orange score calculator that represents the relative difference of position as the heaviest CPU hitting functions.
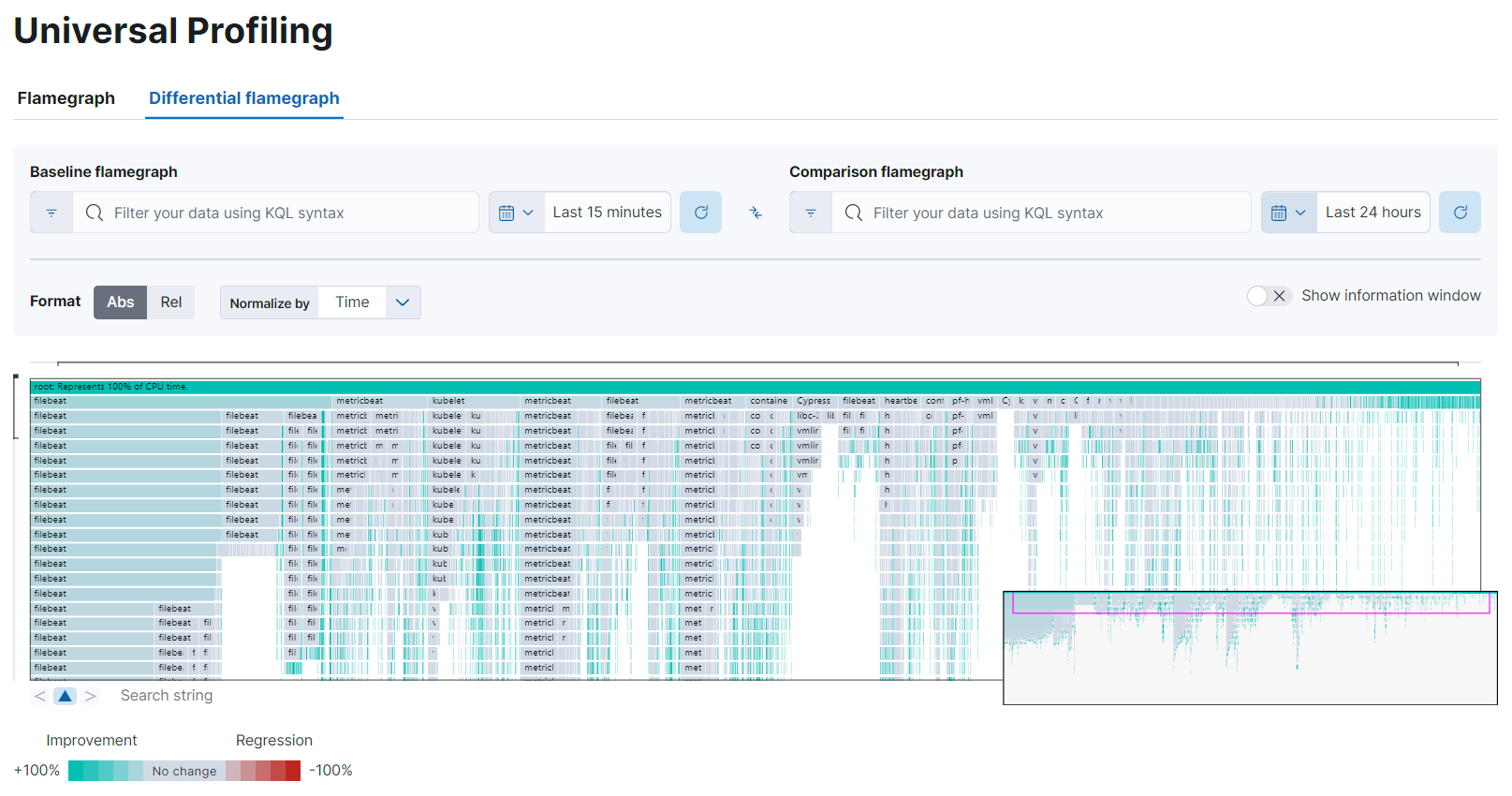
In differentials flamegraphs, the difference with the baseline is highlighted with color and hue. A vivid green colored rectangle indicates that a frame has been seen in less samples compared to the baseline, which means an improvement. A vivid red colored rectangle indicates a frame has been seen in more samples being recorded on CPU, indicating a potential performance regression.
Resource constraints
editOne of the key goals of Universal Profiling is to have net positive cost benefit for users: the cost of profiling and observing applications should not be higher than the savings produced by the optimizations.
In this spirit, both the host-agent and storage are engineered to use as little resources as possible.
Elasticsearch storage
editThe Universal Profiling storage budget is predictable on a per-profiled-core basis. The data we generate, at the fixed sampling frequency of 20 Hz, will be stored in Elasticsearch at the rate of approximately 40 MB per core per day.
Host-agent CPU and memory
editBecause Universal Profiling provides whole-system continuous profiling, the resource usage of host-agent is highly correlated with the number of processes running on the machine.
We have recorded real-world, in-production host-agent deployments to be consuming between 0.5% and 1% of CPU time, with the process' memory being as low as 50 MB, and as high as 250 MB on busier hosts.