Lyft의 작업 로깅: Splunk Cloud에서 Amazon ES로, 그리고 자체 관리형 Elasticsearch로 마이그레이션
Splunk에 대한 대안을 찾고 계신가요? Splunk에서 Elastic으로 마이그레이션하면 통합 가시성과 보안 데이터를 단일 플랫폼에 통합하는 동시에 전반적인 비용과 관리 오버헤드를 줄이는 데 어떻게 도움이 되는지 알아보세요.
이 포스팅은 Elastic{ON}{ON} 2018에서 이루어진 커뮤니티 대담을 요약한 것입니다. 이런 대담을 좀더 보고 싶으세요? 컨퍼런스 아카이브를 확인하시거나 Elastic{ON}{ON} 투어가 가까운 도시에서 개최되는지 알아보세요.
Amazon Elasticsearch Service와 Elastic 공식 Elasticsearch Service 간의 차이점에 대해 좀더 알아보고 싶으세요? AWS Elasticsearch 비교 페이지에서 확인해 보세요.
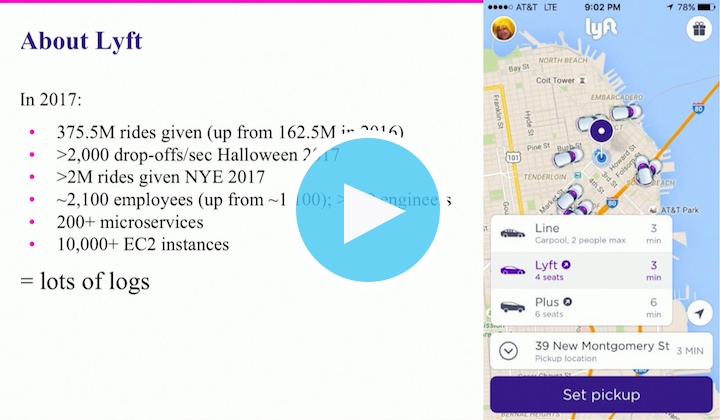
Lyft는 전 세계적으로 매년 수억 건의 승차 서비스(2017년에만 3억 7,500만 건 이상)를 처리하고 모든 고객들이 정확한 목적지까지 도착하도록 하기 위해 강력한 기술 인프라가 필요합니다. 2017년에는 새해 전야(하루에 승차 서비스 2백만 건 이상)와 핼로윈(교통 집중 시간대에 분당 승차 서비스 2천 건 이상)처럼 이용이 급증하는 시간대의 경우 10,000개 이상의 EC2 인스턴스에 걸쳐 200개 이상의 마이크로서비스를 처리해야 한다는 뜻이었습니다. 이 모든 시스템과 승차 서비스가 계속해서 원활하게 굴러가도록 유지하려면 Lyft 엔지니어들이 모든 작업 로그에 액세스하는 것이 중요합니다. Michael Goldsby와 그의 가관측성 팀에게는 로그 파이프라인 서비스가 계속해서 흘러가야 한다는 뜻입니다.
Lyft의 초창기 로깅 분석 시절에는 Splunk Cloud를 서비스 제공자로 이용했습니다. 그러나 계약의 보존 제한, 바쁜 기간 동안에는 최대 30분까지인 수집 백업, 그리고 확장과 관련된 비용으로 인해 Lyft는 Elasticsearch로 전환하기로 결정했습니다.
2016년 말에, 엔지니어 두 명으로 구성된 팀이 약 한 달에 걸쳐 Lyft를 Splunk로부터 AWS의 Amazon Elasticsearch Service로 이행할 수 있었습니다. Elasticsearch를 사용하게 된 것은 훌륭했지만, AWS가 제공하는 서비스 중에 일부는 완전하지 않았습니다. 한 가지 예를 들자면, Goldsby의 팀은 Elasticsearch 5.x로 업그레이드하고 싶었지만, 당시 AWS는 버전 2.3만 제공하고 있었습니다. 또한, 새 인스턴스는 Amazon EBS에만 저장하도록 제한되어 있었는데, 이것은 Lyft의 규모로 볼 때 성능과 안정성 면에서 최적이 아니었습니다. 그리고 모든 Elasticsearch API가 AWS에서 노출되지는 않았습니다. 그러나 AWS의 한계보다는 Splunk Cloud에서 전환할 경우 얻게 되는 혜택이 충분히 더 컸습니다.
수집 제한이 없어지게 되면서(또는 최소한 극적으로 증가하게 되면서), 가관측성 팀은 수문을 열고 “모든 로그를 전송하라”는 새로운 철학을 채택하기로 결정했습니다. 이로 인해 수집량은 분당 10만 개의 이벤트에서 분당 150만 개의 이벤트로 급증했습니다. 이 새 접근 방식을 통해 약 4달 동안 모든 것이 순조롭게 진행되었습니다. Goldsby의 팀이 수집 시간 제한, 보존 축소 또는 느린 Kibana 대시보드 등의 문제를 겪게 되었을 때, 이에 대한 해결책은 확장뿐이었습니다. 그리고 AWS 노드 제한인 20개에 이르렀을 때, 최대 40개의 노드까지 사용할 수 있도록 특별한 예외 허가를 받았습니다.
그러나 40개의 노드를 사용하더라도 문제가 있었습니다. 빨간색 클러스터 상태가 문제였습니다.
Goldsby의 팀은 빨간색 클러스터 문제를 (재시작, 노드 대체 등) 어떻게 해결해야 하는지 알고 있었습니다. 진짜 문제는 클러스터에 직접 액세스할 수 없다는 것이었습니다. 대신에, Amazon에서 티켓을 열어야 했고, 업무 집중 시간대 중에는 지원을 받기 위해 몇 시간이나 기다려야 할 때도 있었습니다. 그리고 나서도 지원팀에서는 클러스터에 액세스할 수 없다는 답변만 듣게 되고, 티켓은 상부로 이관되어야 했습니다. 결국 Lyft는 상부 이관 절차를 빨리 진행하기 위해 클러스터를 초록색 상태로 복구하는 작업을 처리하는 기술 계정 관리자(TAM)에게 직접 연락할 수 있다는 것을 알게 되었습니다.
어쩔 수 없이 지원팀이 개입해야 하는 상황, 2.3 버전의 한계, EBS 요건, AWS에서 부과하는 여러 제한 사항(라운드 로빈 부하 분산 체계, 60초 시간 제한, API 난독 처리 등) 등으로 인해, 가관측성 팀은 다시 한 번 전환하기로 결정했습니다. 이번에는 자체 관리형 Elasticsearch 배포였습니다. “[AWS에서는] 모든 기능을 사용하지 못합니다. 모든 버튼을 누를 수가 없죠.” Goldsby는 이렇게 말합니다. “우리는 사내에서 Elasticsearch 작업 경험은 충분히 했다고 느꼈습니다...그래서 우리도 해낼 수 있다고 생각했습니다.”
Splunk 마이그레이션을 다뤘던 팀보다 살짝 규모가 큰 팀을 통해, Lyft는 불과 2주 만에 Amazon Elasticsearch Service에서 자체 관리형 Elasticsearch로 마이그레이션할 수 있었습니다. 이제 이들은 자체 배포를 하게 되고, 전에 AWS에서는 제어되었던 모든 기능을 갖추게 되었습니다. 또한 클러스터를 초록색 상태로 유지하고 사용자들(공동 작업자들)을 행복하게 만드는 것을 포함해 Elastic Stack의 모든 작업 측면을 직접 책임진다는 뜻이기도 합니다.
Elastic{ON} 2018의 Lyft의 대담한 승차 사례 - 작업 로그 분석을 위해 Amazon ES에서 자체 관리형 Elasticsearch로 마이그레이션(Lyft's Wild Ride from Amazon ES to Self-Managed Elasticsearch for Operational Log Analytics) 대담을 시청하면서 Lyft가 어떻게 자체 관리형 Elasticsearch 배포를 구현했는지 알아보세요. 왜 서비스 품질 면에서 “모든 것을 로그하기 ≠ 아무 거나 로그하기”인지를 포함해 하드웨어 선택, 인덱스 수명 주기 관리 결정 등에 대해 모두 들어보실 수 있습니다.