Implantação de um cluster de logging hot-warm no Elasticsearch Service
Quer aprender sobre as diferenças entre o Amazon Elasticsearch Service e nosso Elasticsearch Service oficial? Visite nossa página de comparação com AWS Elasticsearch.
Adicionamos há pouco tempo inúmeros recursos novos ao Elasticsearch Service na Elastic Cloud que potencializam todos os seus casos de uso — de logging à análise de pesquisa, e muito mais. Uma importante novidade é a adição dos padrões de implantação de arquitetura hot-warm que, combinada com um modelo de preços reduzido, agrega mais valor ao seu serviço ao usar o Elasticsearch Service para os casos de uso de logging.
Neste blog, falamos sobre como usar o novo modelo de implantação hot-warm, além de outros recursos poderosos do Elastic Stack, como machine learning e alertas, para ajudar você a ter mais insights com os dados de logging, tudo isso em 10 minutos. Se você não tiver uma conta Elasticsearch Service, inscreva-se para um teste gratuito de 14 dias
O que é a arquitetura hot-warm?
A arquitetura hot-warm é uma maneira eficaz de separar uma implantação Elasticsearch em nós de dados “hot” e nós de dados “warm”. Os nós de dados hot lidam com todos os novos dados de entrada e apresentam armazenamento mais rápido, para garantir que possam consumir e recuperar dados rapidamente. Os nós warm apresentam densidade de armazenamento maior e também um custo-benefício melhor no armazenamento de dados de registro por períodos de retenção mais longos. Esses dois tipos de nós de dados, quando são usados juntos, permitem que você lide com dados de entrada de maneira eficaz, disponibilizando-os para consultas e retendo-os por períodos mais longos por um custo acessível.
Isso é especialmente útil para casos de uso de logging, nos quais o foco reside, na maioria dos casos, nos logs recentes (por exemplo, das últimas duas semanas), e os logs antigos (que podem ser necessários para conformidade ou outros motivos) podem acomodar tempos de consulta mais lentos.
Criação de uma implantação hot-warm
O Elasticsearch Service facilita muito a implantação da arquitetura hot-warm, e inclui o gerenciamento de diretrizes de curadoria de índices para mover os dados dos nós de dados hot para os nós de dados warm — um recurso que faz do Elastic Cloud um serviço exclusivo se comparado a outros provedores de Elasticsearch hospedado. Mas facilita muito como? Neste blog, teremos um cluster de logging hot-warm totalmente funcional em menos de 5 minutos, incluindo um nó de machine learning de 1GB e um nó Kibana de 1GB gratuitos.
Para começar, no console do Elasticsearch Service clicamos em Create Deployment.
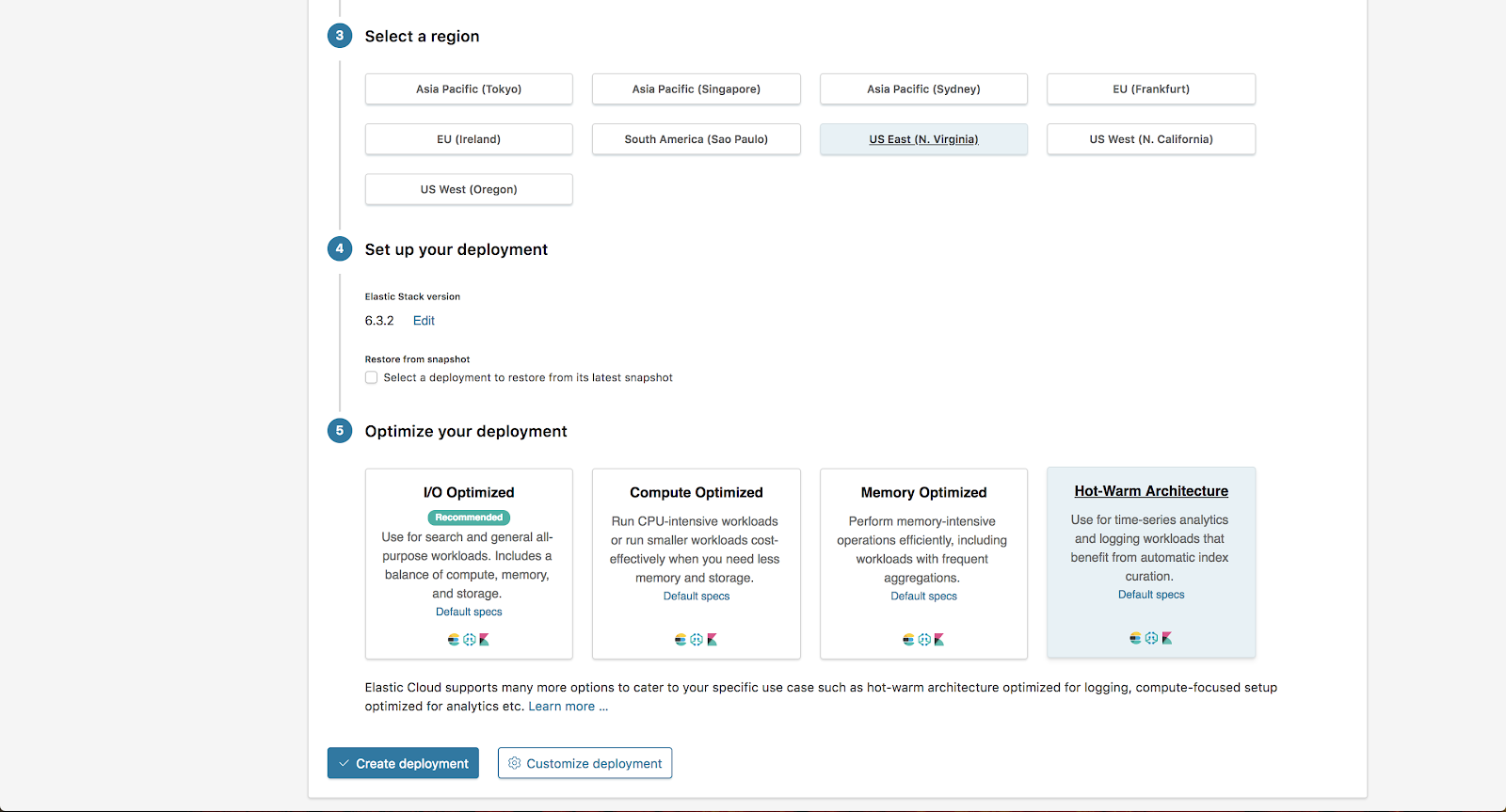
Para este exemplo, escolhemos a região US East com a AWS e selecionamos a opção “Hot-Warm Architecture” na seção “Optimize your deployment”. Daqui, selecionamos Customize Deployment.
Na página Customization, você pode dimensionar de forma independente a configuração da instância hot e da instância warm. Para aprender como dimensionar essas instâncias para suas necessidades específicas, verifique nossa postagem do blog de dimensionamento hot-warm.
Manteremos os valores como padrão neste exemplo.
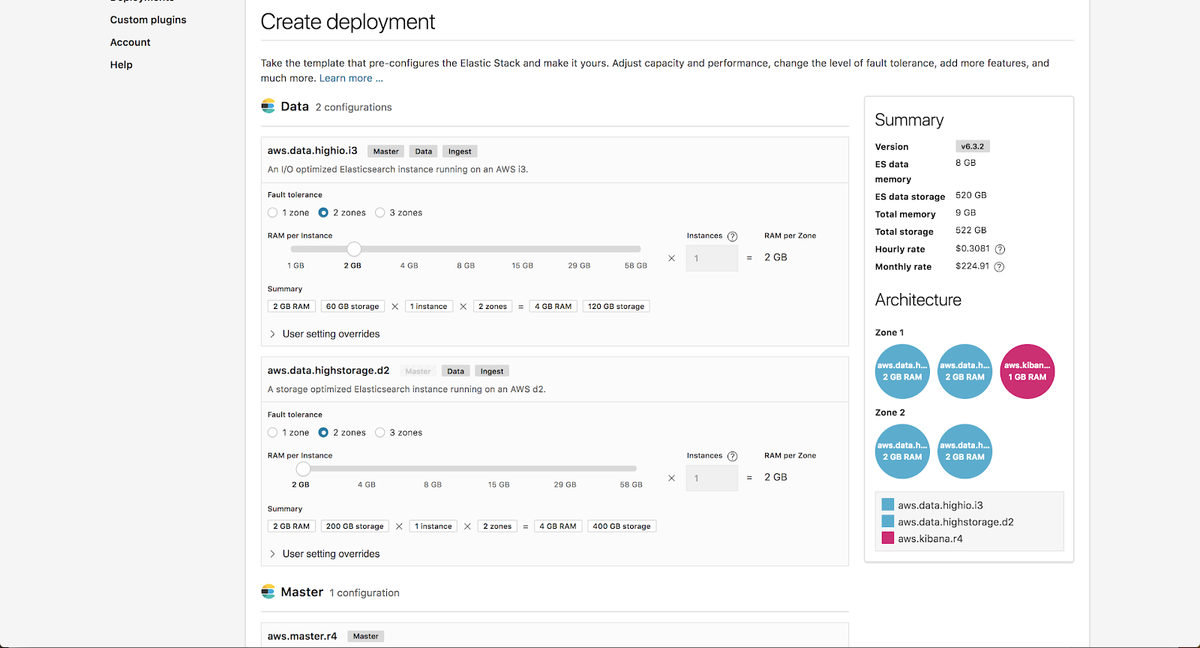
Adicionalmente, habilitaremos a função de machine learning em nossa implantação. Todas as implantações no Elasticsearch Service incluem gratuitamente um nó de machine learning de 1GB e um nó Kibana de 1GB.
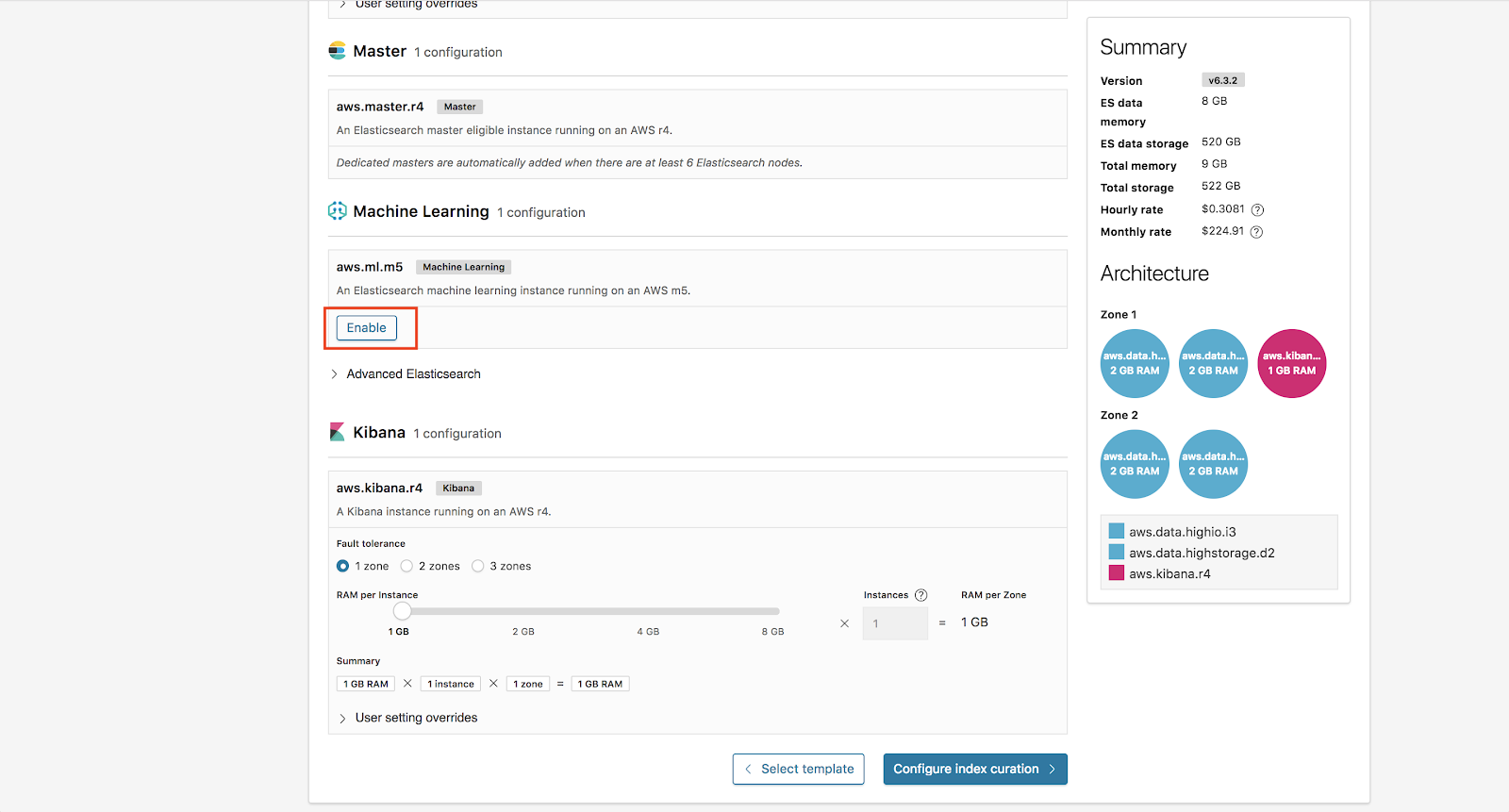
Daqui, clicamos agora em Configure Index Curation.
Curadoria de índices
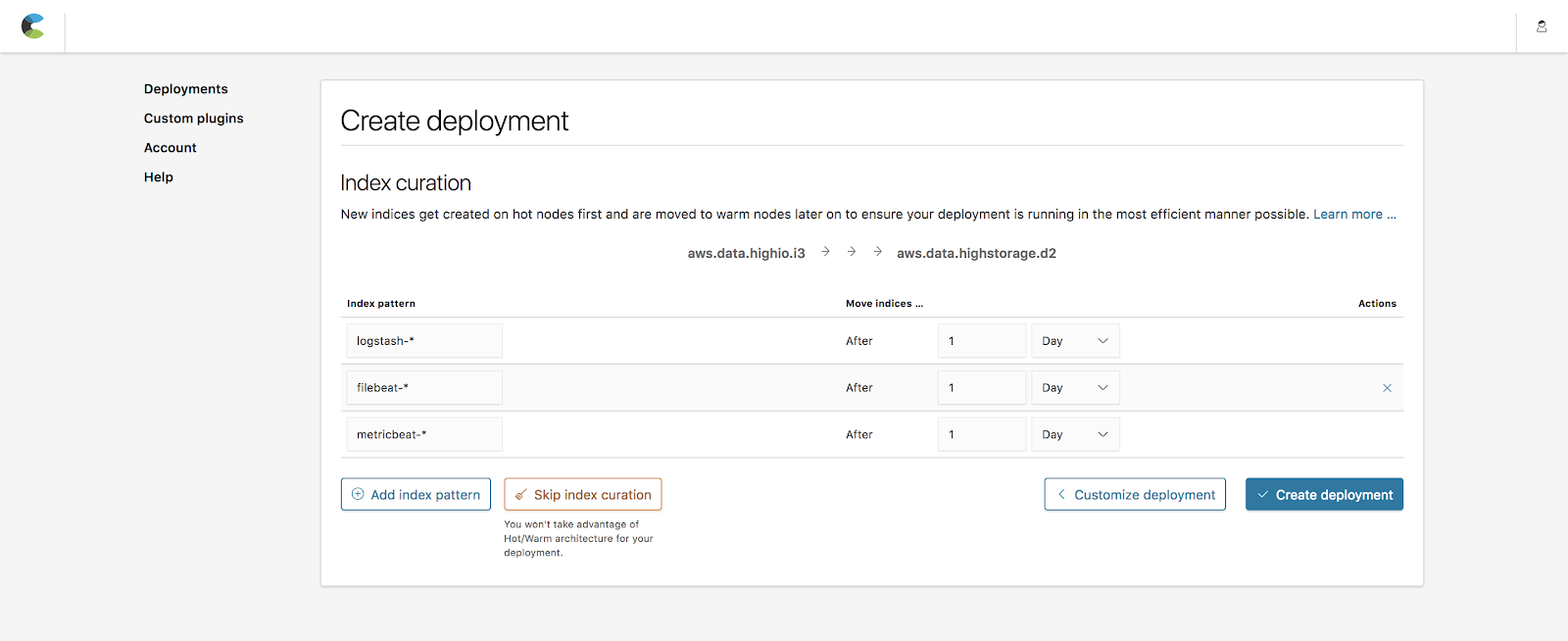
A curadoria de índices permite que você defina por quanto tempo os índices são mantidos nos nós hot antes de serem movidos para os nós warm. Os valores padrão incluem índices populares criados por Beats (metricbeat-*, filebeat-*) e Logstash (logstash-*) com um período de um dia antes de serem movidos. Manteremos esses valores para este exemplo.
Nota: Você sempre pode alterar essas regras depois da implantação na página Operations da implantação do cluster.
Depois de terminar isso, clicamos em Create Deployment.
Parabéns! Agora você é um orgulhoso implantador da poderosa arquitetura hot-warm!
Envio de dados
Agora que nossa implantação hot-warm está funcionando, vamos começar enviando alguns dados de logging para lá. Para isso, vamos instalar o Beats em nossa máquina local e usar a ID da nuvem Elasticsearch Service e a senha gerada durante nossa implantação para começar a enviar dados. Para obter detalhes completos sobre como instalar o Beats e o Elasticsearch Service, dê uma olhada no nosso blog sobre como usar o Metricbeat como o Elasticsearch Service.
Para encontrar a ID da nuvem, vamos para a página Deployments e depois para Cloud ID:
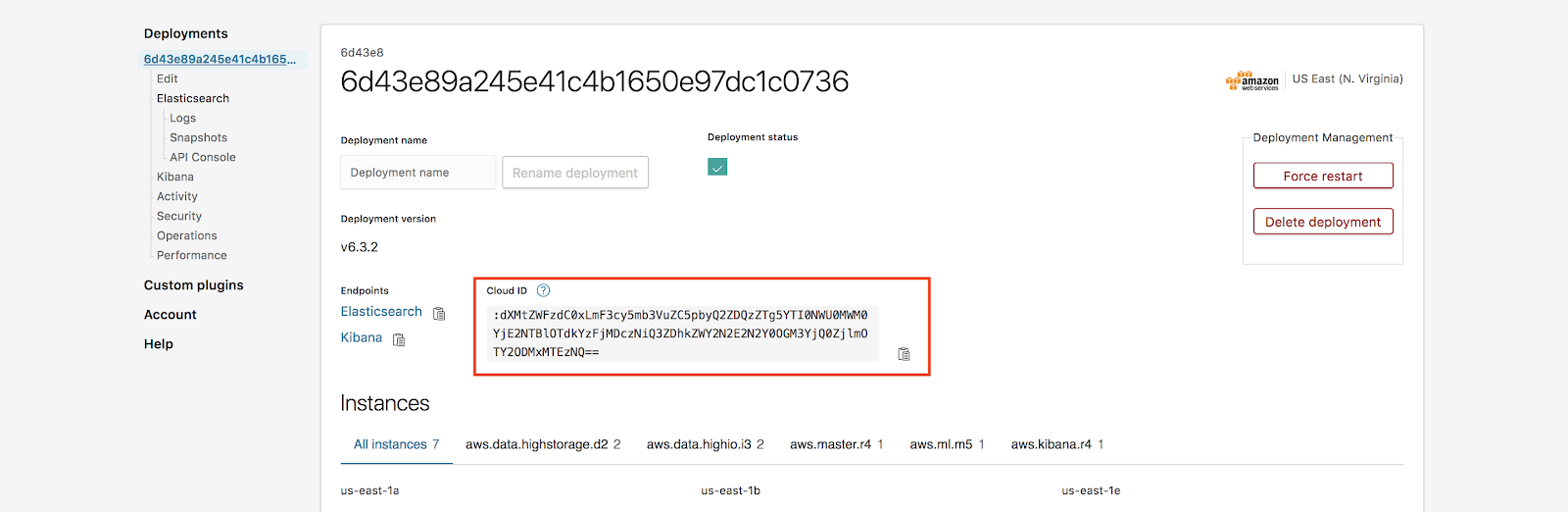
Nota: Esqueceu a senha? Não tem problema! O Elasticsearch Service permite que você redefina a senha de usuário elastic em Deployment -> Security -> Reset password.
Agora que os dados estão fluindo da nossa máquina local, precisamos fazer login no Kibana e verificar o dashboard. À medida que continuamos a obter mais dados, o Elasticsearch Service permanecerá movimentando os dados dos nós hot para os nós warm todos os dias.
Adicionar Machine Learning
Outra função incrível do Elasticsearch Service é a compatibilidade com o machine learning. Além dessa função, todos os usuários poderão adicionar gratuitamente 1 GB de nó de machine learning às suas implantações. Depois de incluir isso em nossa implantação, podemos navegar para o Kibana e abrir a aplicação de machine learning para criar os jobs de machine learning.
Para obter mais informações sobre o machine learning e outros casos de uso, verifique a seguinte página de recursos de Machine Learning da Elastic.
Conclusão
Os novos recursos do Elasticsearch Service facilitam os primeiros passos na poderosa arquitetura hot-warm: bastam apenas alguns cliques. Adicionalmente, com outros recursos do Elastic Stack, como machine learning e segurança, monitorar os seus registros e métricas com o Elasticsearch Service passa a ser uma tarefa mais eficiente do que nunca.
Está curioso? Dê uma olhada em tudo isso com nossa avaliação gratuita de 14 dias.