Monitoramento de aplicativos com a Elasticsearch e Elastic APM
O que é o Application Performance Monitoring (APM)?
Quando falamos do APM, acho interessante falar nele como uma das facetas da “observabilidade”, que também engloba os registros e métricas de infraestrutura. Os três juntos formam o tripé da observabilidade:
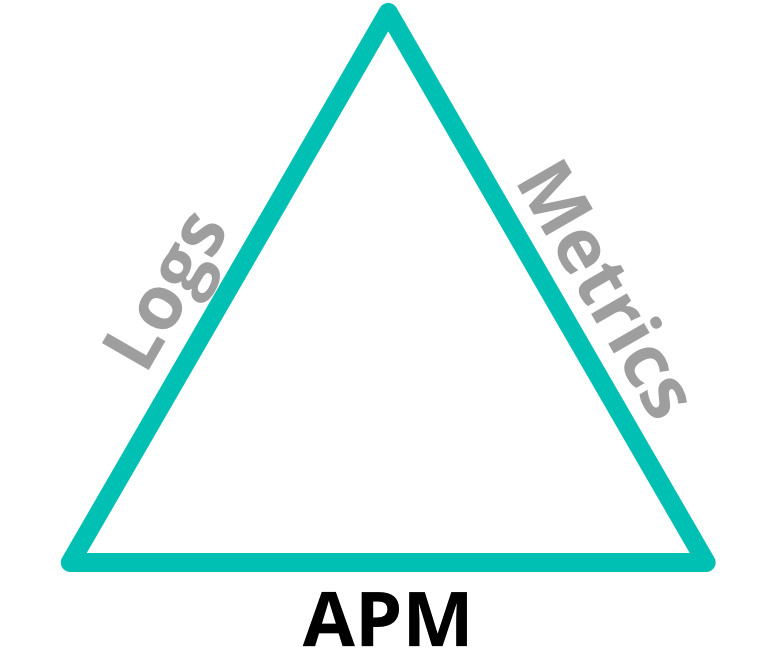
E existem sobreposições nessas áreas, o suficiente para podermos correlacioná-las. Os registros podem indicar que ocorreu um erro, mas não explicar por quê. As métricas podem mostrar que o uso da CPU teve um pico em um servidor, mas não indicar o que o causou. Por isso, quando usamos esses recursos juntos, conseguimos resolver muito mais problemas.
Registros
Primeiro, vamos ver algumas definições. Existe uma diferença sutil entre registros e métricas. No geral, registros são eventos emitidos quando alguma coisa acontece: por exemplo, uma solicitação é recebida e respondida, um arquivo é aberto, um printf é encontrado no código.
Um formato de registro comum, por exemplo, vem do projeto do servidor Apache HTTP (falso e reduzido em tamanho):
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291 264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /intro.m4v HTTP/1.1" 404 7352 264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
Os registros ainda tendem a estar em nível do componente e não do aplicativo como um todo. E eles são bons porque são facilmente entendidos pelas pessoas. Nos exemplos acima, vemos um endereço de IP, um campo que aparentemente não está definido, uma data, a página que o usuário estava acessando (mais o método) e alguns números. Pela minha experiência, sei que os números são o código de resposta (200 é bom, 404 não é bom, mas é melhor do que 500) e a quantidade de dados que retornaram.
Os registros também são úteis porque costumam estar disponíveis no servidor/máquina/contêiner em que o aplicativo ou serviço está sendo executado e, como vemos acima, são compreensíveis. O lado ruim dos registros é a própria natureza deles. Se você não codificá-los, eles poderão ser impressos. É necessário fazer algo equivalente ao puts no Ruby ou system.out.println no Java para que ele possa ser divulgado. Mesmo que você faça isso, é importante formatar. Os registros do Apache acima têm o que parece ser um formato de data estranho. Veja, por exemplo, a data 01/02/2019. Para mim, nos EUA, significa 2 de janeiro de 2019, mas, para um grande número de pessoas, seria 1 de fevereiro. Pense sobre esse tipo de coisa quando estiver formatando enunciados de registro.
Métricas
As métricas, por outro lado, tendem a ser resumos ou contagens periódicas. Nos últimos 10 segundos, a CPU médio foi de 12%, a quantidade de memória usada por um aplicativo foi de 27 MB ou o disco principal estava em 71% da capacidade (o meu, acabei de checar).
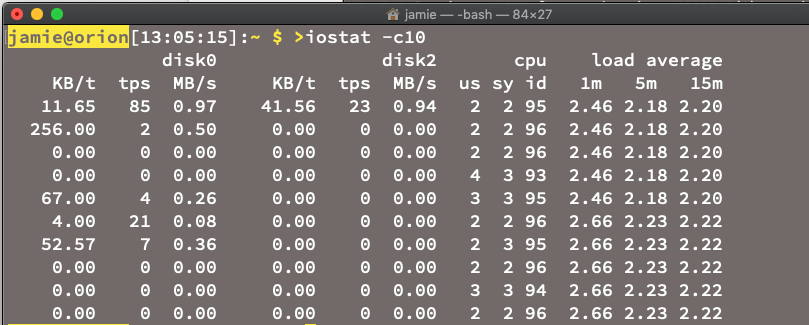
Veja acima uma captura de tela do iostat em um Mac. São muitas métricas. Elas são úteis para mostrar tendências e histórico e excelentes para tentar criar regras simples, previsíveis e confiáveis para pegar incidentes e anomalias. Um dos problemas com as métricas é que elas tendem a monitorar a camada de infraestrutura, obtendo dados em nível do componente, como host, contêiner e rede, em vez de em nível do aplicativo. Como as métricas tendem a ser de um período, é importante que elas sejam breves para manter seu valor.
APM
O Application Performance Monitoring resolve o abismo entre as métricas e os registros. Os registros e métricas têm mais a ver com infraestrutura e componentes, enquanto o APM se concentra nos aplicativos e permite que profissionais de TI e desenvolvedores monitorem a camada da aplicação do stack, incluindo a experiência do usuário final.
Ao adicionar o APM ao seu monitoramento, você vai:
- Entender em que o seu serviço está gastando tempo e por que ele para de funcionar.
- Ver como os serviços interagem uns com os outros e visualizar gargalos.
- Descobrir com antecedência gargalos e erros de performance para corrigi-los.
- Antes que grande parte dos seus clientes sofram as consequências.
- Aumentar a produtividade da equipe de desenvolvimento.
- Monitorar a experiência do usuário final no navegador.
Algo importante a se observar é que a linguagem do APM é o código (vamos falar mais disso mais à frente).
Vamos ver como o APM se compara aos registros. Observemos esta entrada de registro:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291
Inicialmente, tudo parece bom. Obtivemos sucesso com a resposta (200) e enviamos de volta 6291 bytes. O que ele não mostra é que levou 16,6 segundos, como vemos nessa captura de tela do APM:
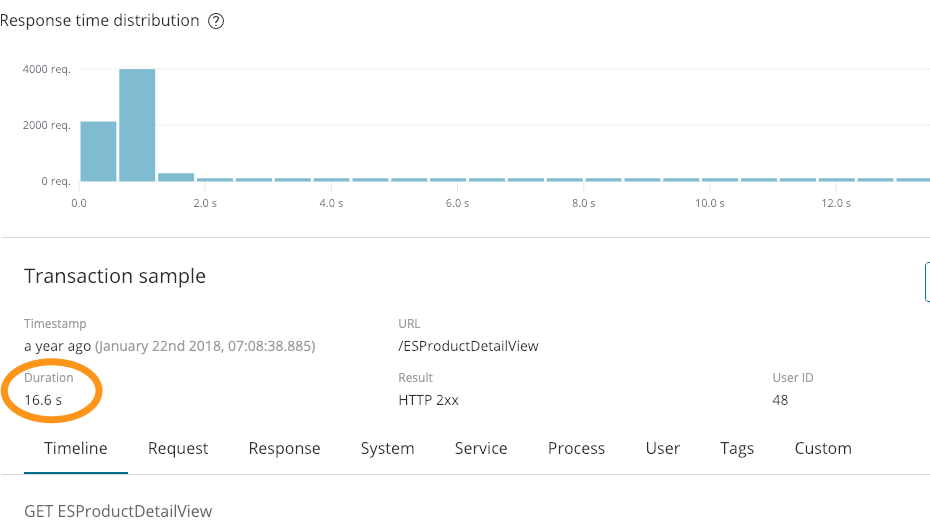
Essa última informação é muito importante. Também tivemos um erro nos registros acima:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
O APM também captura erros para nós:
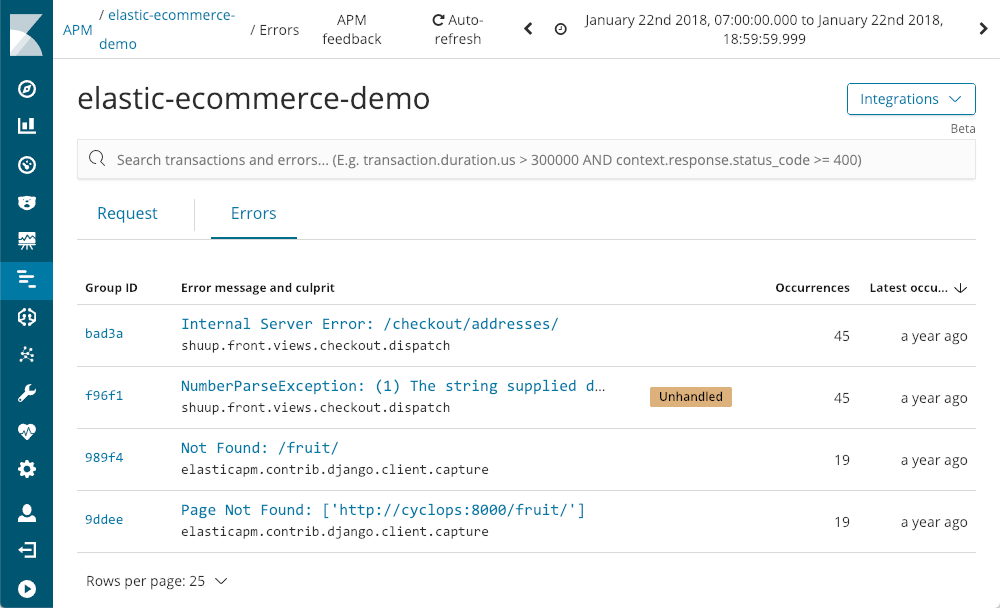
Ele mostra qual foi a última vez em que ele aconteceu, com qual frequência aconteceu e se ele foi ou não resolvido pelo aplicativo. Conforme exploramos em busca de uma exceção, usando o NumberParseException como exemplo, recebemos uma visualização da distribuição do número de vezes em que aquele erro ocorreu na janela:
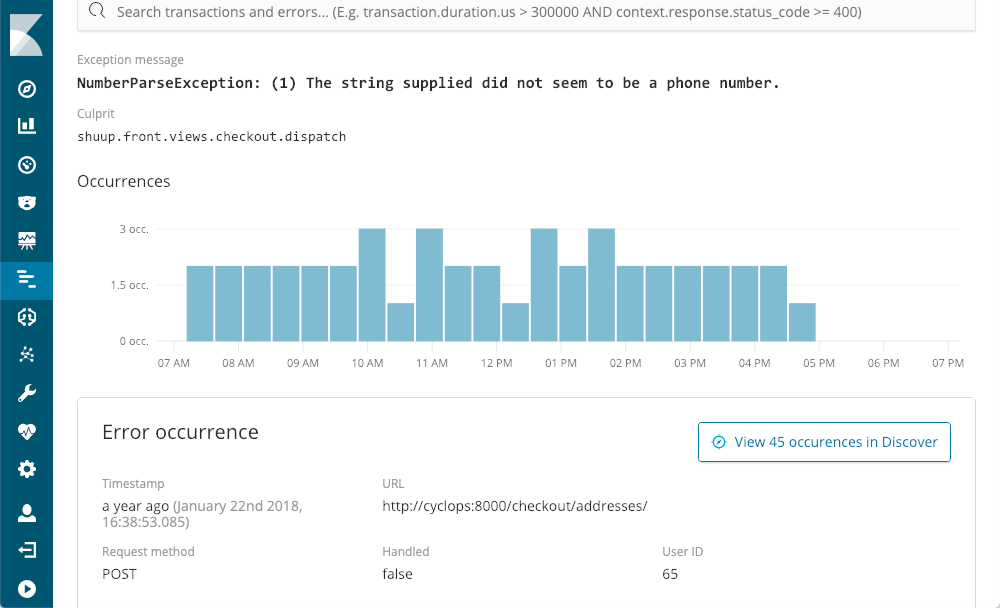
E conseguimos ver imediatamente que aconteceu diversas vezes por período, mas o dia todo. Seria possível encontrar o stack trace correspondente em um dos arquivos de registro, mas provavelmente em contexto e os metadados disponíveis no APM:
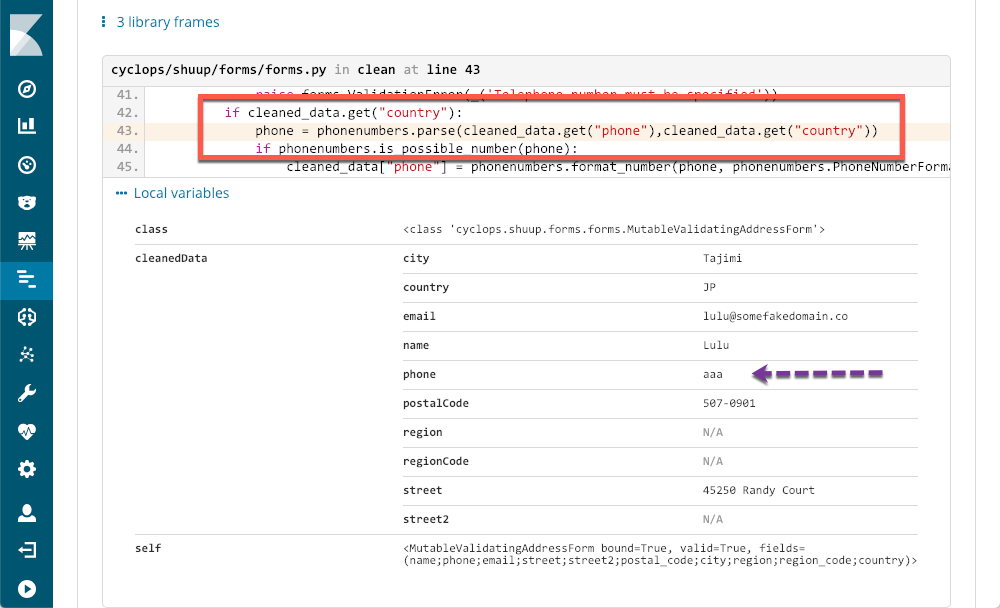
O retângulo vermelho mostra a linha do código que causou a exceção e os metadados informados pelo APM me mostram exatamente qual é o problema. Até mesmo um programador que não seja de phyton como eu consegue ver qual é o problema e ter informações suficientes para abrir um ticket.
Tour pelos recursos do APM (com capturas de tela)
Eu poderia passar o dia inteiro falando do Elastic APM (quem me acompanha no Twitter sabe), mas acho que vocês vão preferir ver o que ele pode fazer. Vamos fazer um tour.
Abrindo o APM
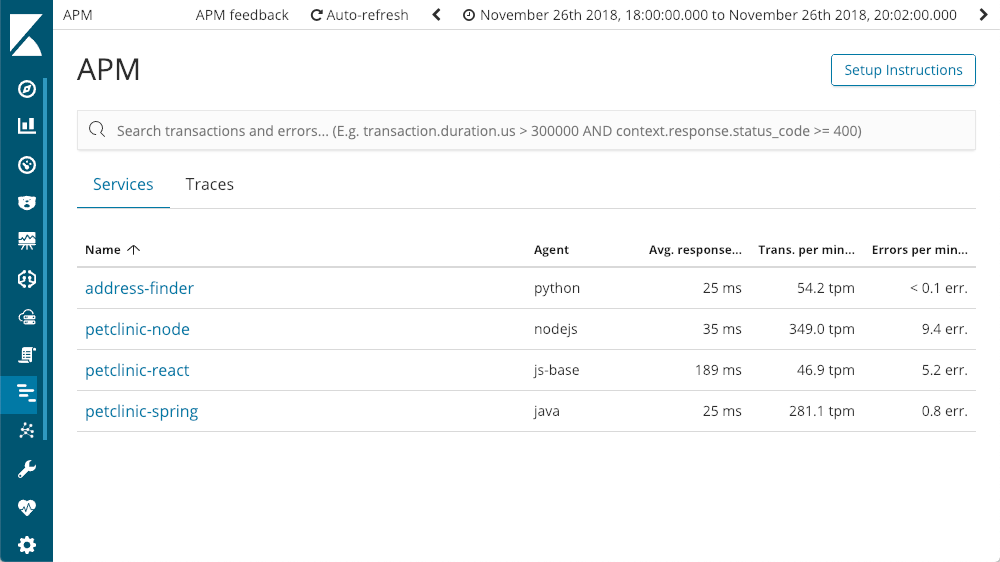
Quando abrimos o APM no Kibana, vemos todos os serviços que já instrumentamos com o Elastic APM:
Mergulhando nos serviços
Podemos mergulhar nos serviços individuais. Vamos tentar o serviço “petclinic-spring”. Cada serviço terá um layout similar:
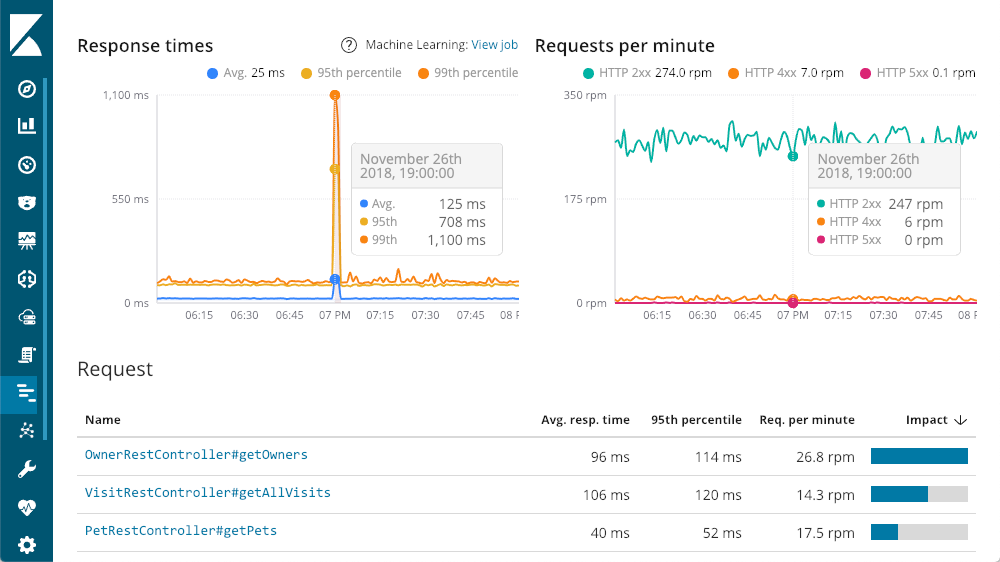
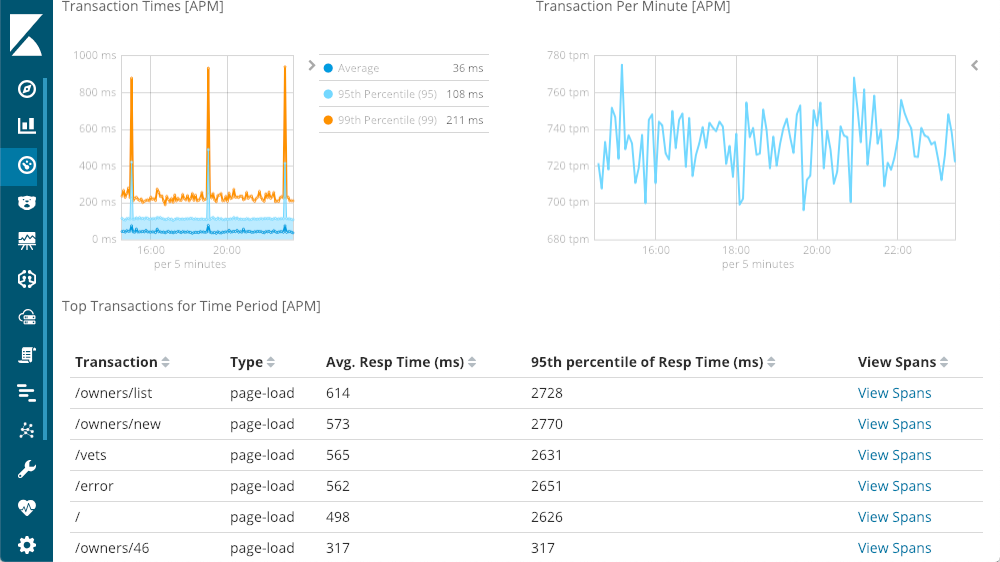
O do canto superior esquerdo me dá tempos de resposta: média, 95º e 99º percentis, para mostrar onde estão meus outliers. Também podemos mostrar ou esconder os diversos elementos de linha para ver com mais clareza qual é o impacto dos outliers sobre o quadro geral. O canto superior direito tem meus códigos de respostas que estão divididos em solicitações por minuto (RPM) em vez de simplesmente quantidade. Ao passar o mouse sobre cada gráfico, você verá uma janela mostrando o resumo daquele momento. Nosso primeiro insight está disponível antes mesmo de começarmos. Aquele grande pico em latência não tem nenhuma resposta 500 (erros do servidor).
Mergulhando nos tempos de resposta da transação
Continuando nossa turnê do resumo das transações, chegamos aos detalhes da solicitação. Cada solicitação é basicamente um endpoint diferente no seu aplicativo (embora seja possível aumentar os padrões usando as diversas APIs de agente). Posso classificar pelo cabeçalho da coluna, mas gosto da coluna “impact”, que leva em consideração a latência e a popularidade de uma solicitação. Nesse caso, nosso “getOwners” parece estar causando o maior problema, mas ainda tem uma latência respeitável de 96ms. Observando os detalhes dessa transação, vemos o mesmo layout que vimos antes:
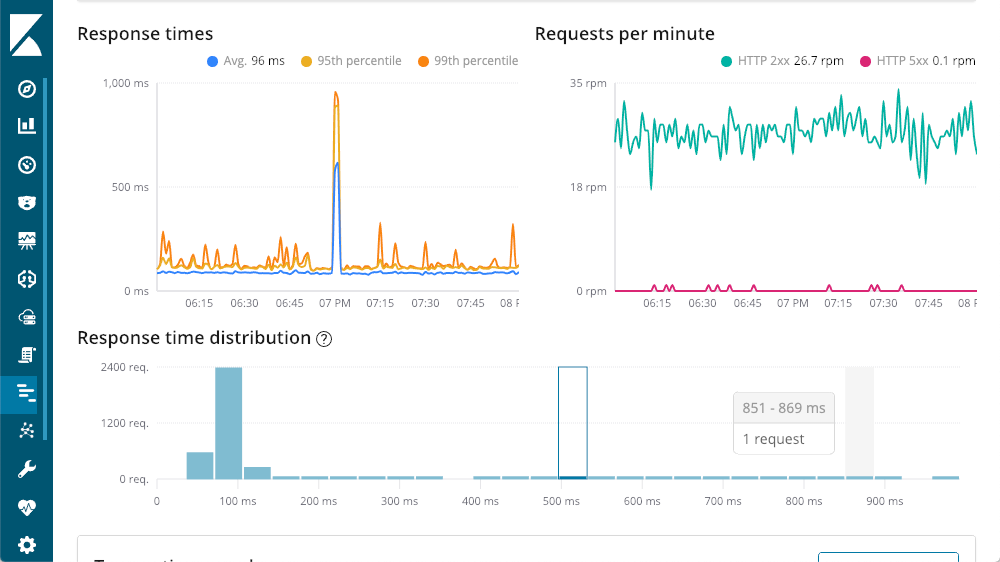
Operação Waterfall
Mesmo as solicitações mais lentas ainda levam menos de 1 segundo. Descendo a tela, temos uma visão de Waterfall das operações na transação:
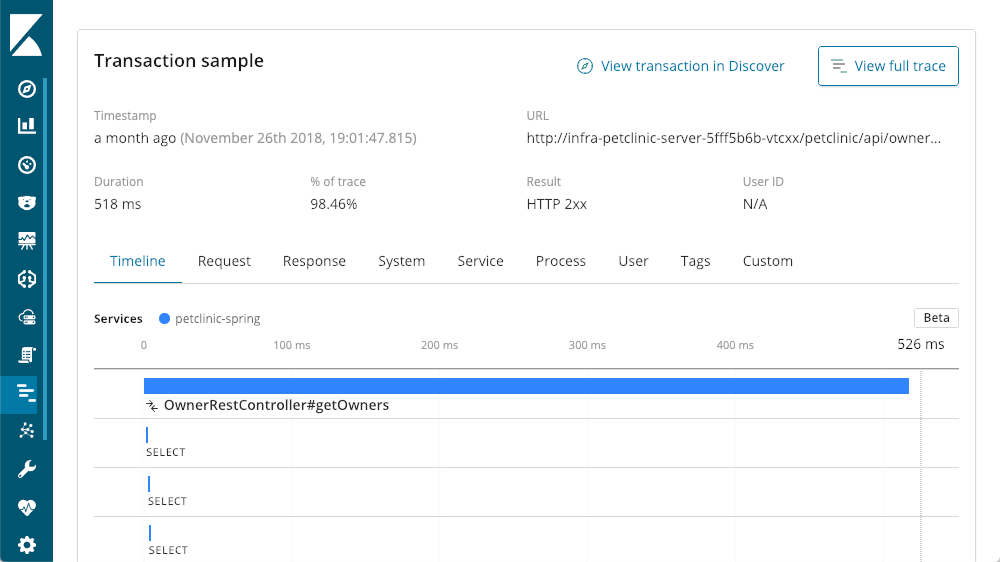
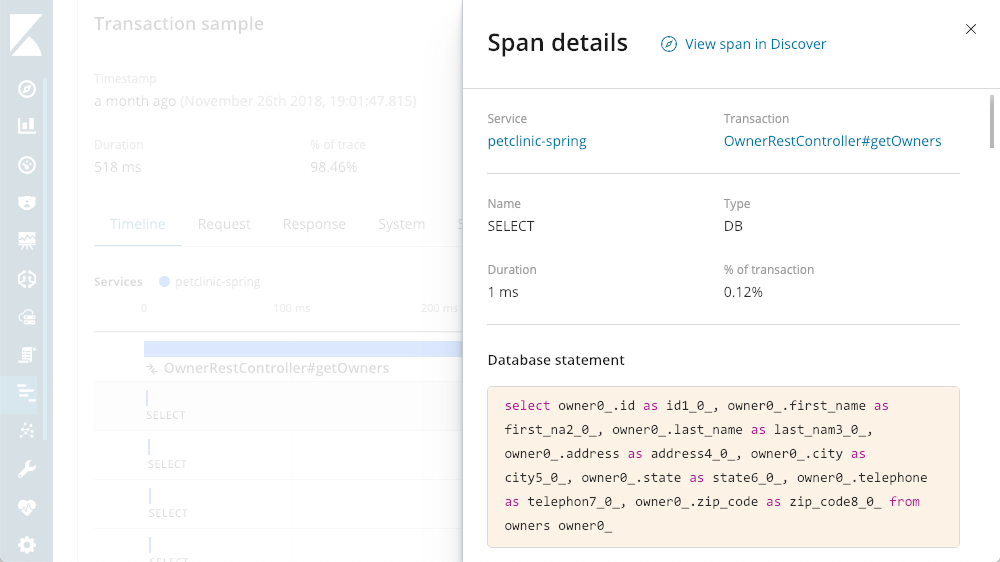
Visualizador de detalhes da consulta
Existem muitos enunciados SELECT acontecendo. Com o APM, consigo ver as consultas atuais sendo executadas.
Rastreamento distribuído
Estamos falando de uma arquitetura de microsserviços multinível neste stack de aplicativos. Como temos todas as camadas instrumentadas com o Elastic APM, podemos ver um pouco mais de longe com o botão “View full trace”, que mostra um rastro distribuído de todos os componentes que participaram da transação:
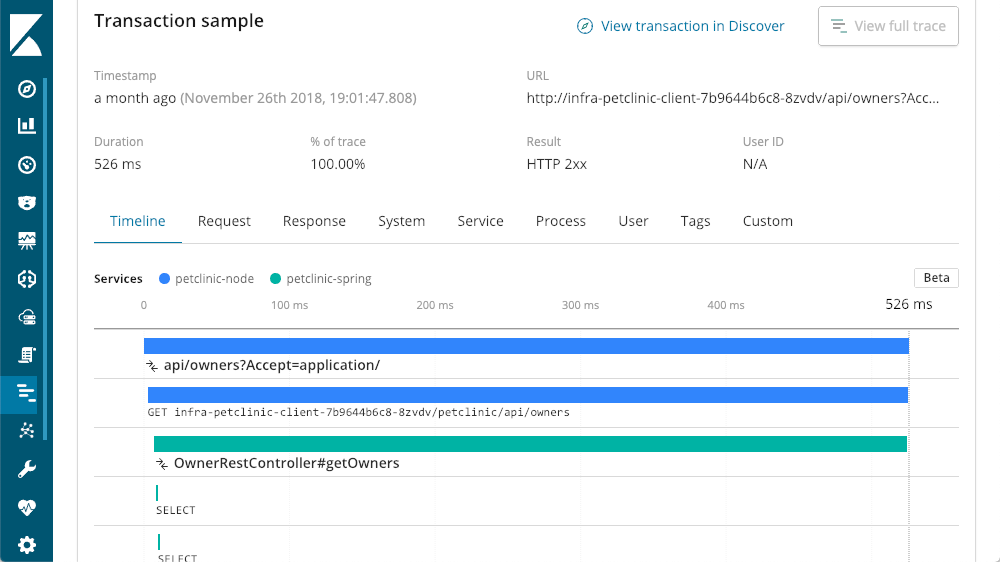
Camadas de rastros
Nesse caso, a camada na qual começamos, a Spring, é um serviço que as outras camadas chamam. Agora conseguimos ver o “petclinic-node” chamado de camada “petclinic-spring”. Essas são duas camadas, mas podemos ver muitas outras. Neste exemplo, temos uma solicitação que começou na camada do navegador (React):
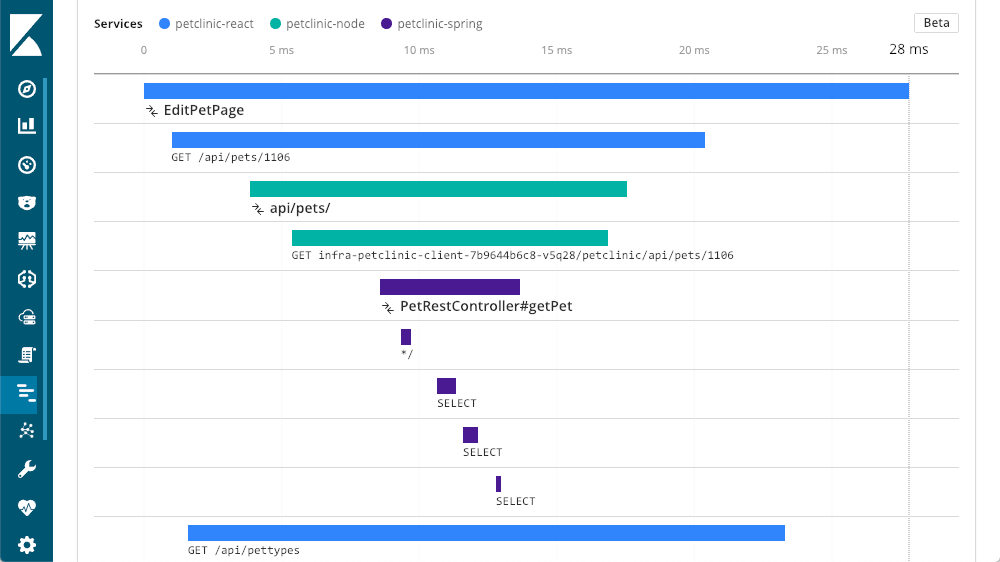
Monitoramento do usuário real
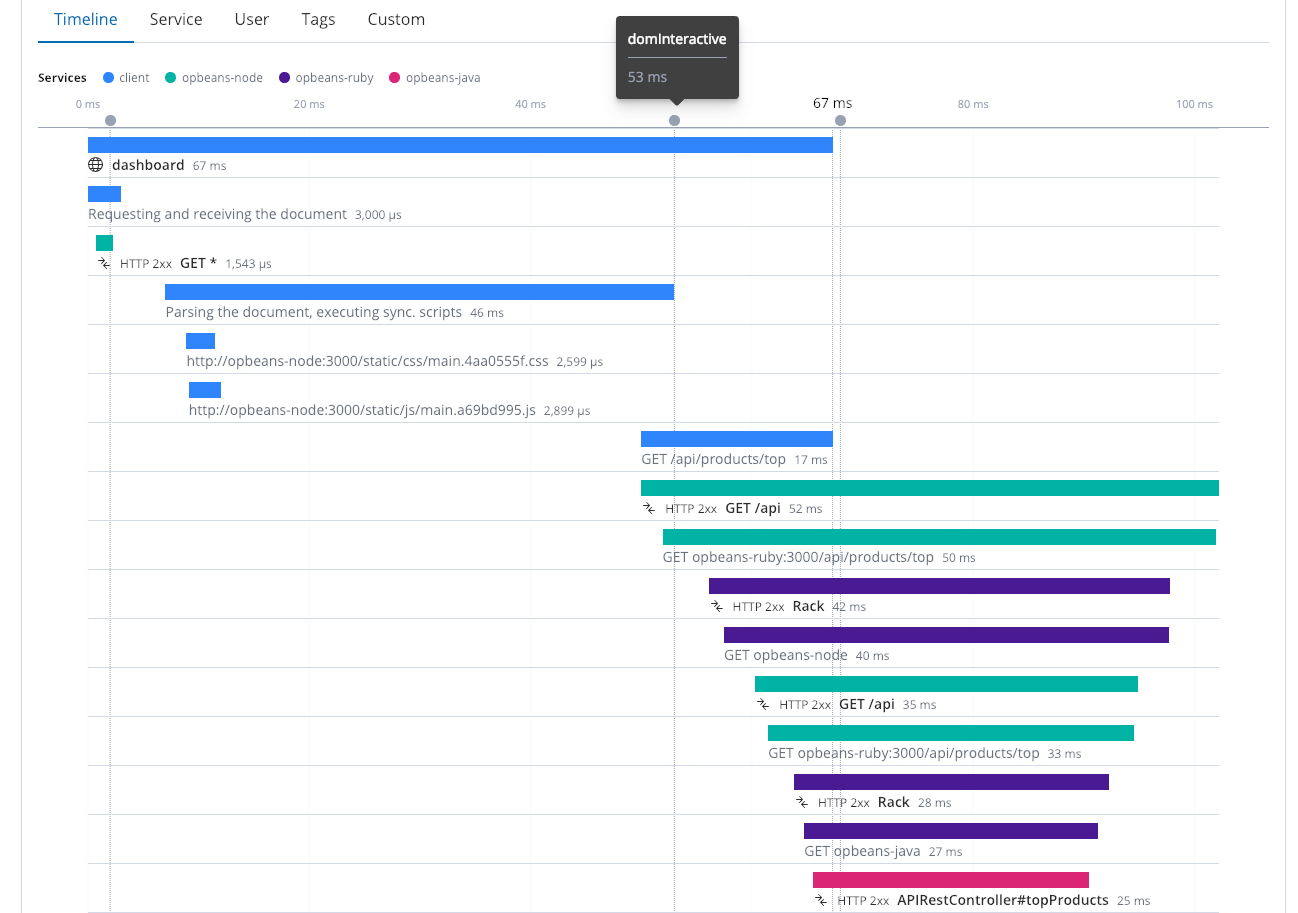
Para obter o máximo de valor dos traces distribuídos, é importante instrumentar o máximo de componentes e serviços possíveis, incluindo o Real User Monitoring (ou RUM). Só porque temos tempos de resposta mais rápidos, não significa que as coisas funcionem de forma rápida no navegador. É importante verificar as experiências dos usuários finais no navegador. O trace distribuído mostra quatro serviços diferentes trabalhando juntos. Ele inclui o navegador web (o cliente), juntamente com uma série de serviços. Aos 53 ms, o dom estava interativo e, aos 67 ms, foi concluído.
Mais do que um rostinho bonito
O Elastic APM não é só uma interface feita para desenvolvedores de aplicativos, e os dados por trás dele não estão ali só para servir a interface. Na verdade, uma das melhores partes do Elastic APM é que ele é só mais um índice. A informação está ali, junto com seus registros, métricas e até os dados da sua empresa, permitindo que você veja como um servidor lento impacta suas receitas, ou aproveite os dados do APM para ajudar a planejar a próxima rodada de aprimoramentos no código (dica: dê uma olhada nas solicitações de maior impacto).
O APM traz visualizações e painéis padrão que permitem combinações com visualizações de registros, métricas e até os dados da sua empresa.
Como começar a usar o Elastic APM
O Elastic APM pode funcionar junto com o Logstash e o Beats, com uma topologia de implementação similar:
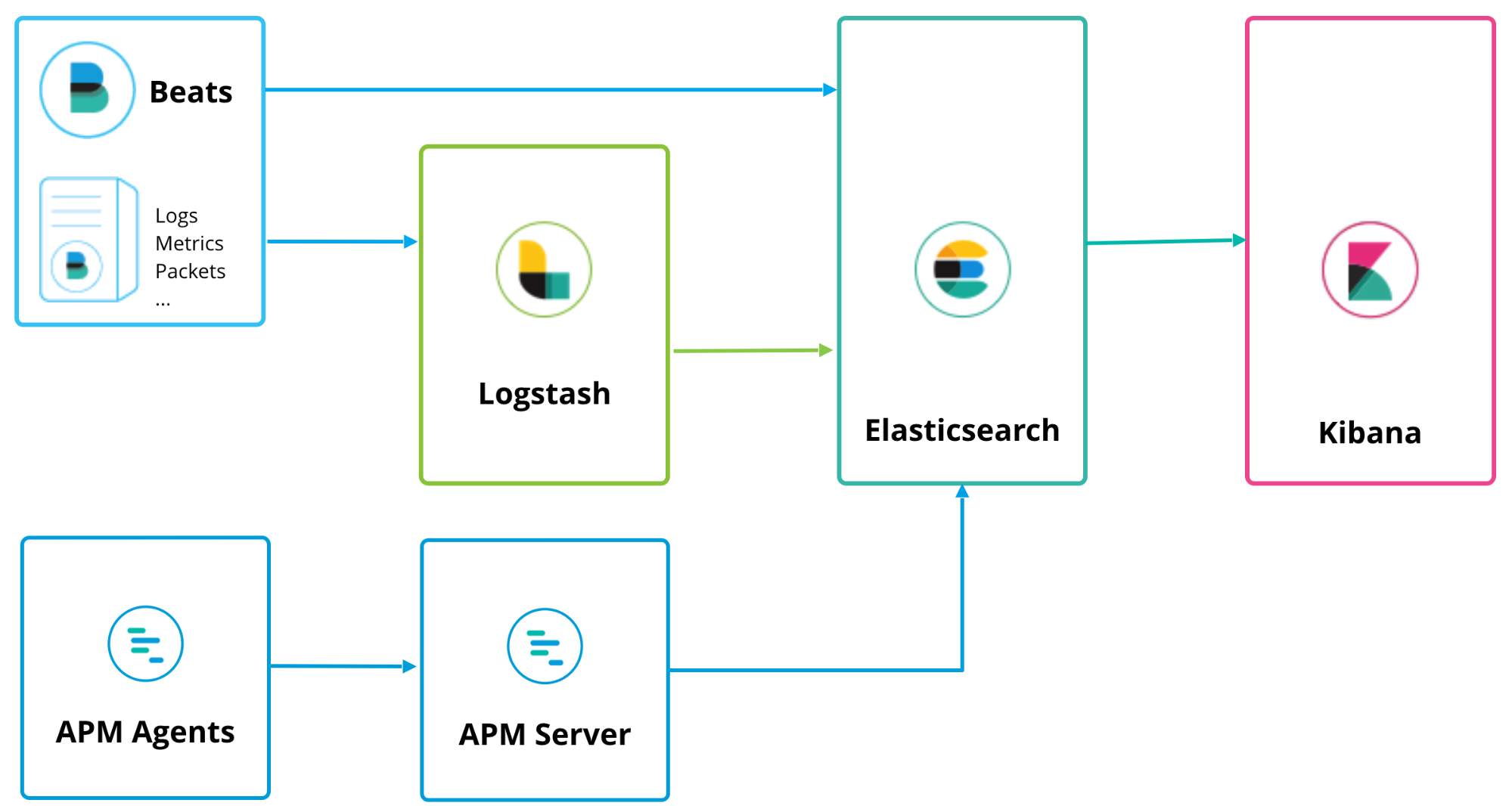
O servidor do APM funciona como um processador de dados, encaminhando os dados do APM dos agentes do APM para a Elasticsearch. A instalação é bem simples e pode ser encontrada na página “install and run” da documentação ou clicando no logo K do Kibana para acessar a tela inicial do serviço onde você verá a opção “Add APM”.
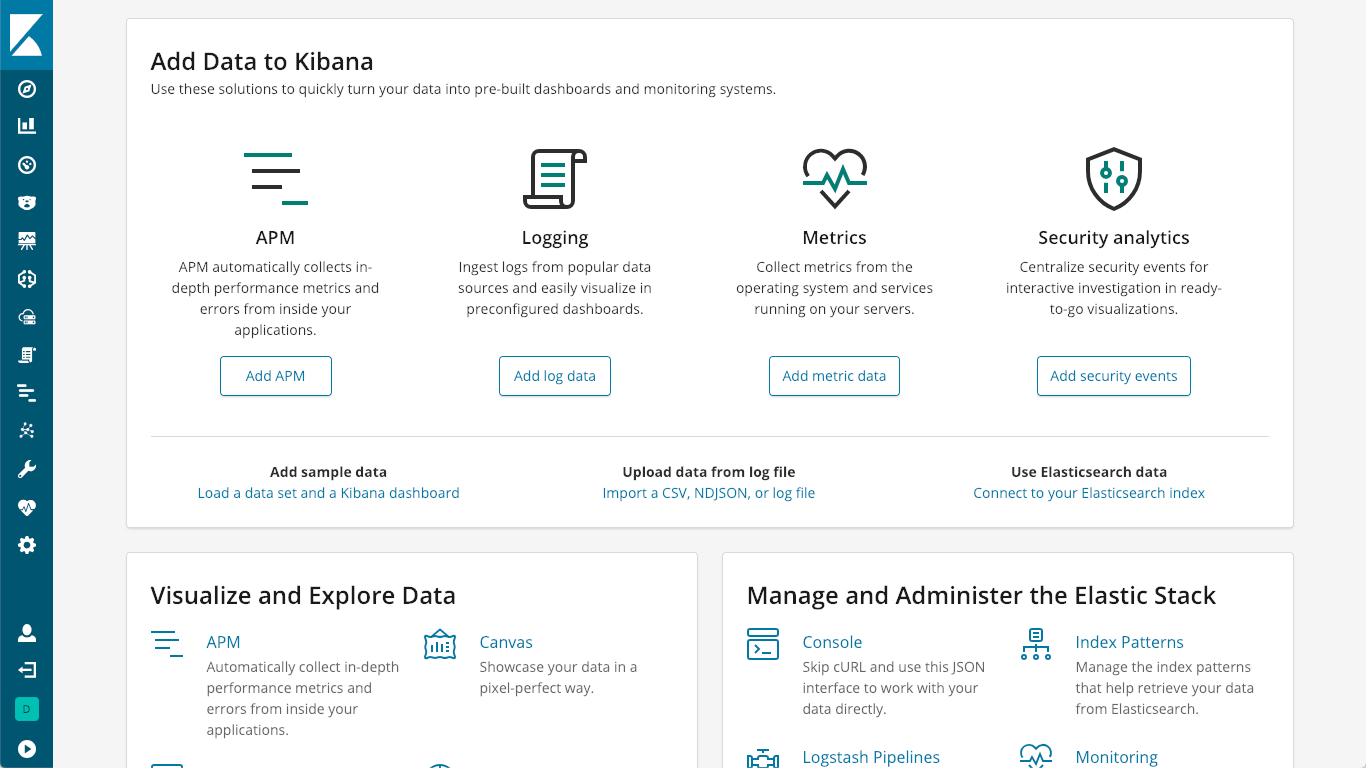
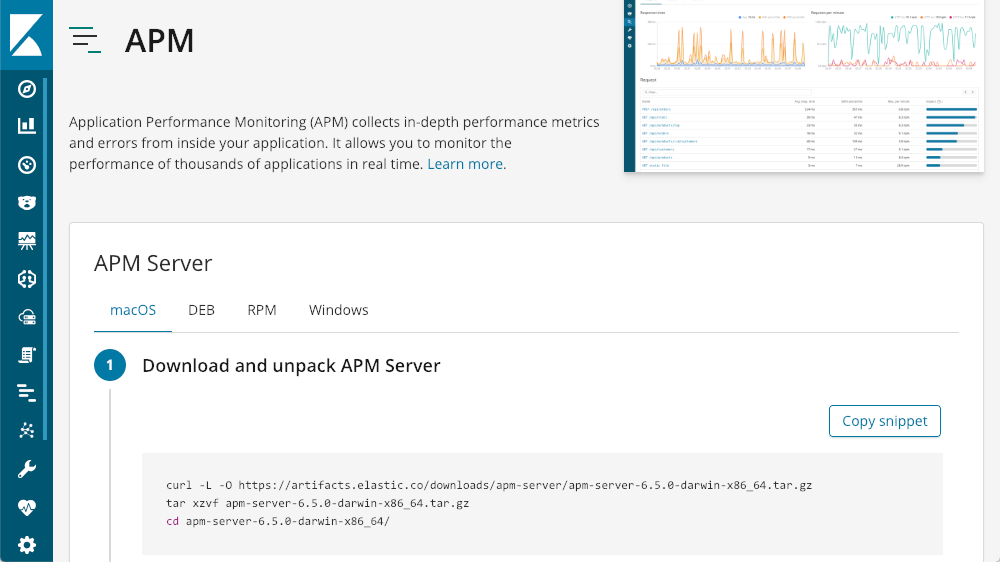
Lá, você verá as instruções de como colocar o servidor do APM para funcionar:
Depois, o Kibana tem tutoriais para cada tipo de agente:
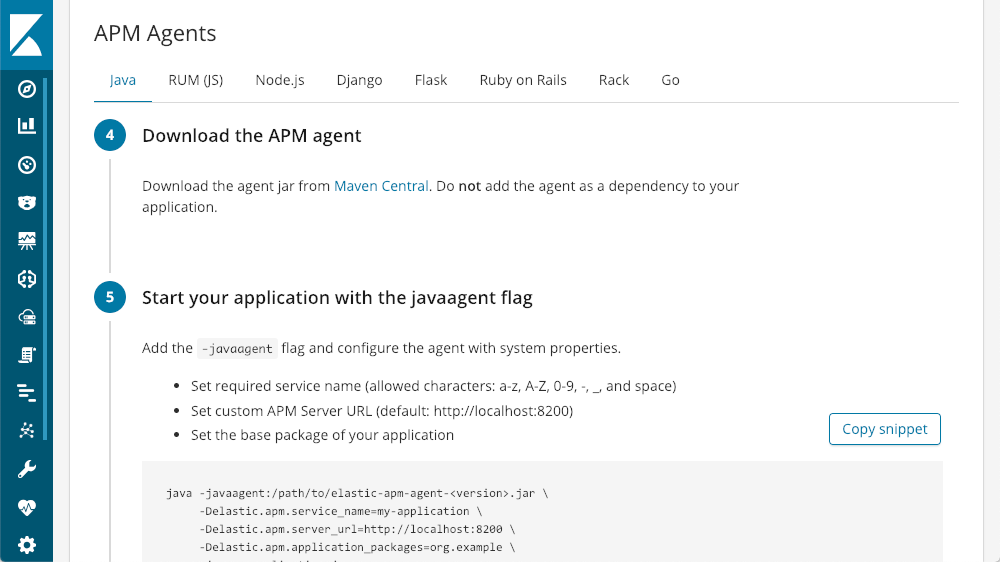
Dá para colocar tudo para funcionar com poucas linhas de código.
Experimente o Elastic APM
Não tem jeito melhor de aprender algo novo do que com a mão na massa, e temos diversas formas de você fazer isso. Se quiser ver a interface, ao vivo e em cores, explore o ambiente de demonstração do APM. Caso prefira trabalhar de forma local, você pode seguir as orientações em nossa página de download do servidor APM.
O caminho mais curto é através do Elastic Service na Elastic Cloud, nossa oferta de SaaS em que você pode ter toda a implantação da Elasticsearch, incluindo o servidor APM (a partir da versão 6.6), uma instância do Kibana e um nó de aprendizado de máquina, feita em minutos (e com um período de teste de duas semanas). A melhor parte é que mantemos sua infraestrutura de implantação para você.
Como habilitar o APM no serviço Elasticsearch
Para criar seu cluster com o APM (ou adicionar o APM a um cluster existente, basta descer até a seção de configuração do APM do seu cluster, clicar em “Enable” e ou “Save changes” (se estiver atualizando uma implantação existente) ou “Create deployment” (ao criar uma implantação nova).
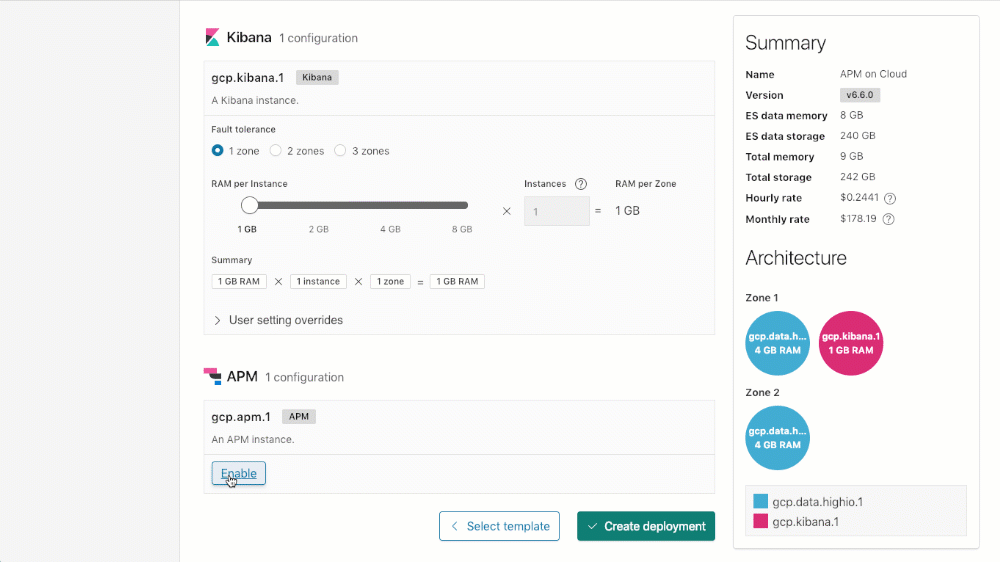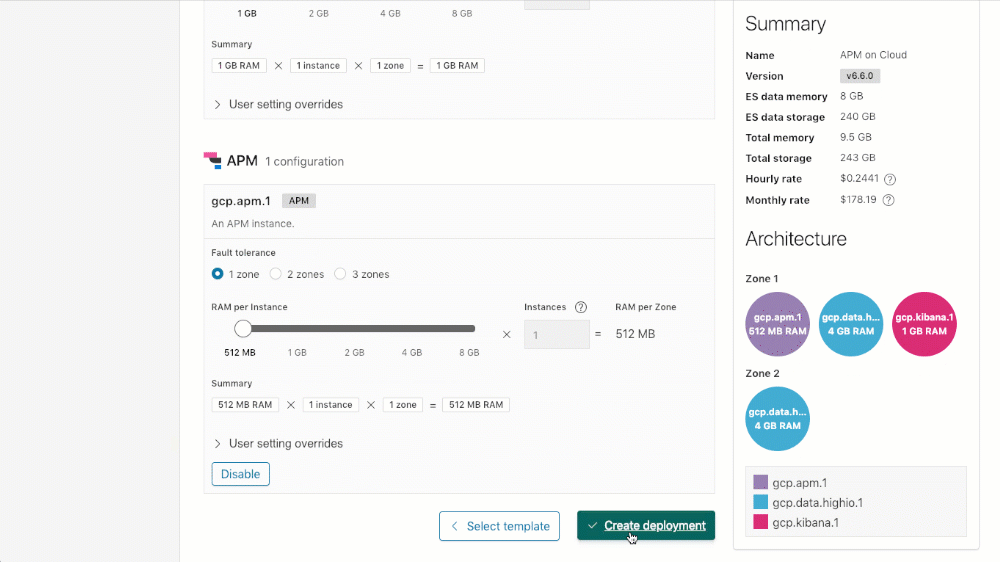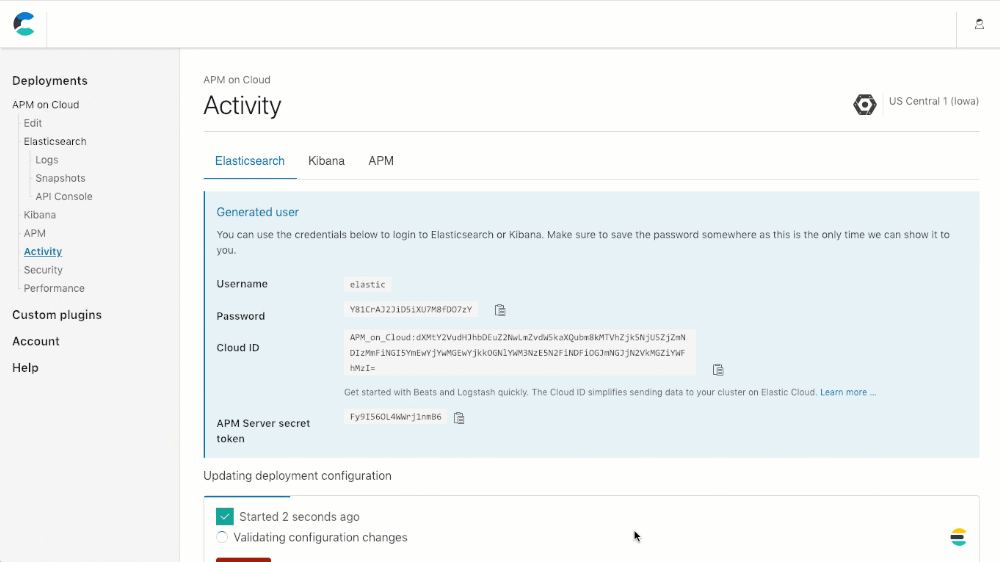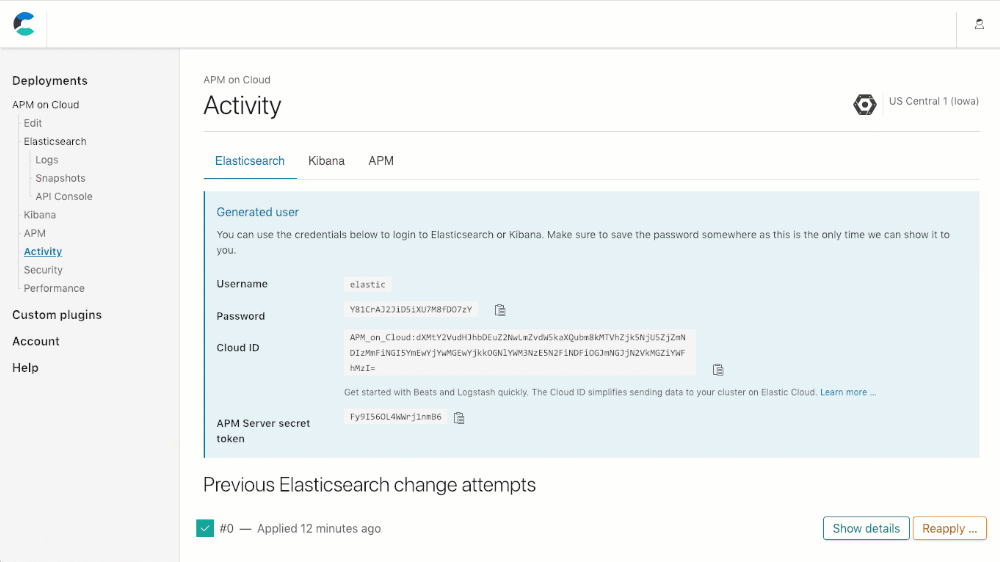
Licenciamento
O servidor APM e todos os agentes APM da Elastic são open source, e a IU do APM está incluída na distribuição padrão do Elastic Stack na licença básica. As integrações de que falamos (alertas e aprendizado de máquina) estão ligadas à licença do recurso de base: Gold para alerta e Platinum para aprendizado de máquina.
Resumo
O APM nos permite ver o que está acontecendo em nossos aplicativos, em todas as camadas. Com as integrações com o aprendizado de máquina e os alertas e o poder da busca, o Elastic APM adiciona uma outra camada de visibilidade à sua infraestrutura de aplicativos. Podemos usá-lo para visualizar transações, traces, erros e exceções, tudo no contexto de uma interface de usuário preparada do APM. Mesmo quando não temos problemas, podemos aproveitar os dados do Elastic APM para ajudar a priorizar as correções, melhorar o desempenho dos aplicativos e resolver gargalos.
Se quiser saber mais sobre o Elastic APM e observabilidade, veja nossos webinars:
- Instrument and Monitor Java Applications using Elastic APM
- Using the Elastic Stack for Application Performance Monitoring
- Using Elasticsearch, Beats and Elastic APM to monitor your OpenShift Data
- Unifying APM, Logs, and Metrics for Deeper Operational Visibility
- Tracking your Infrastructure Logs & Metrics in the Elastic Stack (ELK Stack)
Experimente hoje mesmo! Venha conversar sobre o APM no fórum de discussão ou envie um tíquete ou uma solicitação de recurso nos APM GitHub repos.