O que é busca híbrida?
Dois ou mais métodos de busca. Uma lista classificada.
Abusca híbrida é uma técnica de busca de informações que combina dois ou mais métodos de busca (por exemplo, busca lexical e busca semântica) em uma única lista classificada para melhorar a relevância e a recordação. O emparelhamento mais comum combina a busca léxica de texto completo, que é ótima para combinar palavras e frases exatas, com a busca vetorial semântica, que interpreta o significado por trás de uma consulta. O lado léxico adiciona precisão, e o lado semântico fornece uma compreensão profunda da intenção do usuário.
Esses métodos são executados juntos em uma única consulta e, em seguida, os resultados são combinados em uma classificação coesa usando estratégias de fusão especializadas. Embora léxico + semântica seja a combinação mais usada, a busca híbrida pode unir outras abordagens, como busca geoespacial + semântica ou até busca de texto + imagem, para atender a diferentes necessidades.
Por que a busca híbrida é importante
A busca híbrida mitiga as fraquezas dos métodos individuais de recuperação, mas aproveitando os pontos fortes em um único pipeline. A IA moderna deve processar diversas modalidades, como texto, imagens, áudio, logs e outros, além de conectar a intenção aos dados. A relevância cada vez mais importante. No comércio eletrônico, por exemplo, uma busca pode ter sucesso se ajudar os usuários a filtrar e refinar rapidamente os resultados, mas um agente de IA frequentemente exige uma única resposta altamente relevante para responder a uma pergunta ou realizar uma ação. É por isso que a capacidade de combinar e otimizar técnicas de sondagem é importante hoje, não só nos resultados tradicionais de busca como nos agentes conversacionais, que dão respostas precisas e baseadas em dados.
Antes de nos aprofundarmos na busca híbrida, vamos analisar rapidamente como a busca lexical e a busca semântica diferem e por que elas se complementam.
Busca lexical
A busca lexical é ideal quando você tem dados estruturados e os usuários sabem o que estão procurando. Ela encontra termos exatos, sendo altamente precisa e explicável, dependendo de um algoritmo de pontuação de relevância (como BM25F) para classificar documentos pela frequência e raridade dos termos da consulta. Essa abordagem oferece pontuação transparente e traz relevância ajustada graças a boosts de campo, sinônimos e analisadores. Por não ter sobrecarga de modelo, a busca lexical é rápida e eficiente, com filtros e facetas que funcionam de forma confiável mesmo em larga escala, sem lentidão nem varreduras completas do índice. É particularmente eficaz em consultas estruturadas, termos raros e linguagem específica de domínio.
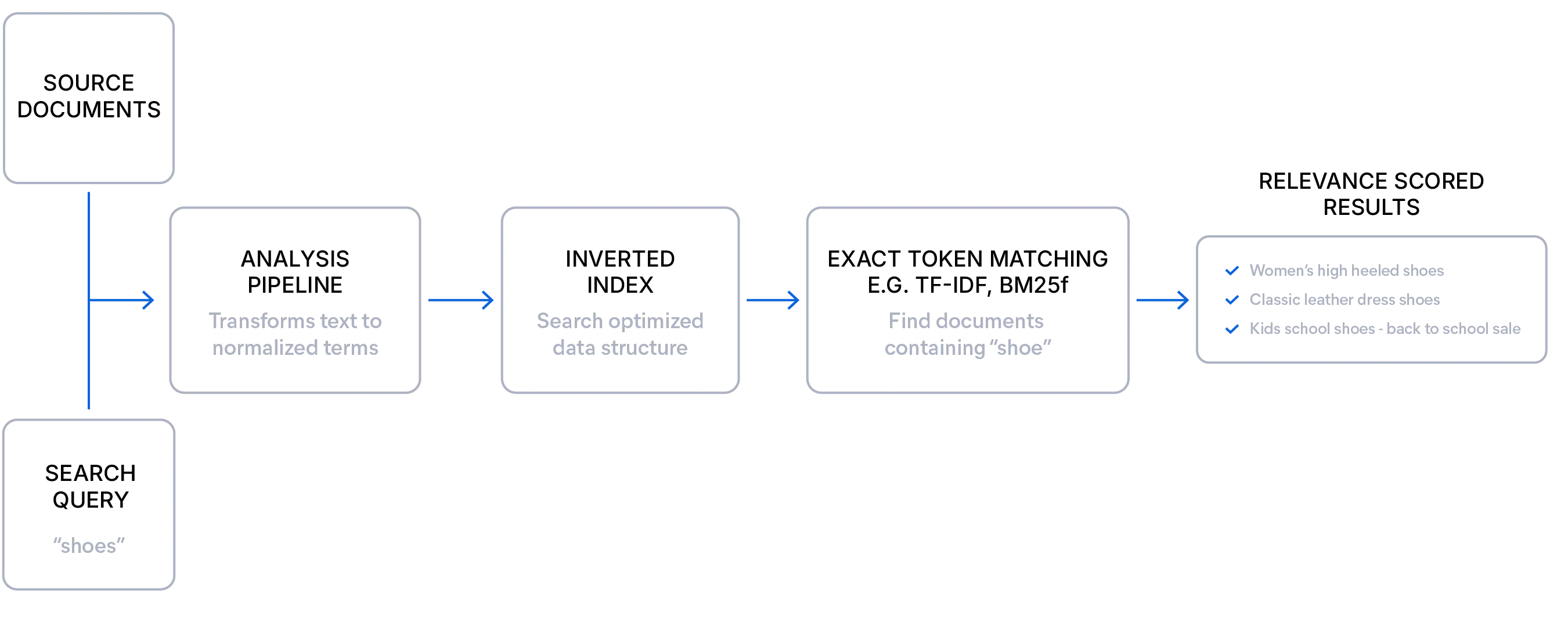
Confira um exemplo simples de uma consulta com busca lexical:
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
Vamos também analisar um exemplo semelhante de busca lexical com a linguagem de consulta Elasticsearch (ES|QL) para um blog de culinária. O blog contém receitas com vários atributos, incluindo conteúdo textual, dados categóricos e avaliações numéricas.
FROM cooking_blog METADATA _score | WHERE description:"panquecas fofas" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
Essa consulta procura no campo descrição documentos que contenham "panquecas" OU "fofas" (ou ambos). Como padrão, o ES|QL usa lógica OR entre termos de busca, encontrando documentos que contenham qualquer uma das palavras especificadas. Você pode especificar exatamente quais campos incluir nos resultados usando o comando KEEP e solicitar os metadados _score para classificar os resultados da busca de acordo com a correspondência à consulta.
Saiba mais sobre busca lexical com este tutorial prático.
Busca semântica
A busca semântica mostra resultados com base na semelhança de significado entre uma consulta e documentos, em vez de apenas encontrar os termos exatos, como na busca lexical.
Um modelo de embedding converte o significado do seu texto ou outro meio em uma representação numérica chamada vetor. Esses vetores — uma lista de números — capturam o contexto e o tópico associados ao texto e ficam guardados em um banco de dados vetorial como o Elasticsearch.
Isso permite que o mecanismo de busca encontre resultados conceitualmente semelhantes, mesmo quando não compartilham palavras exatas com a consulta.
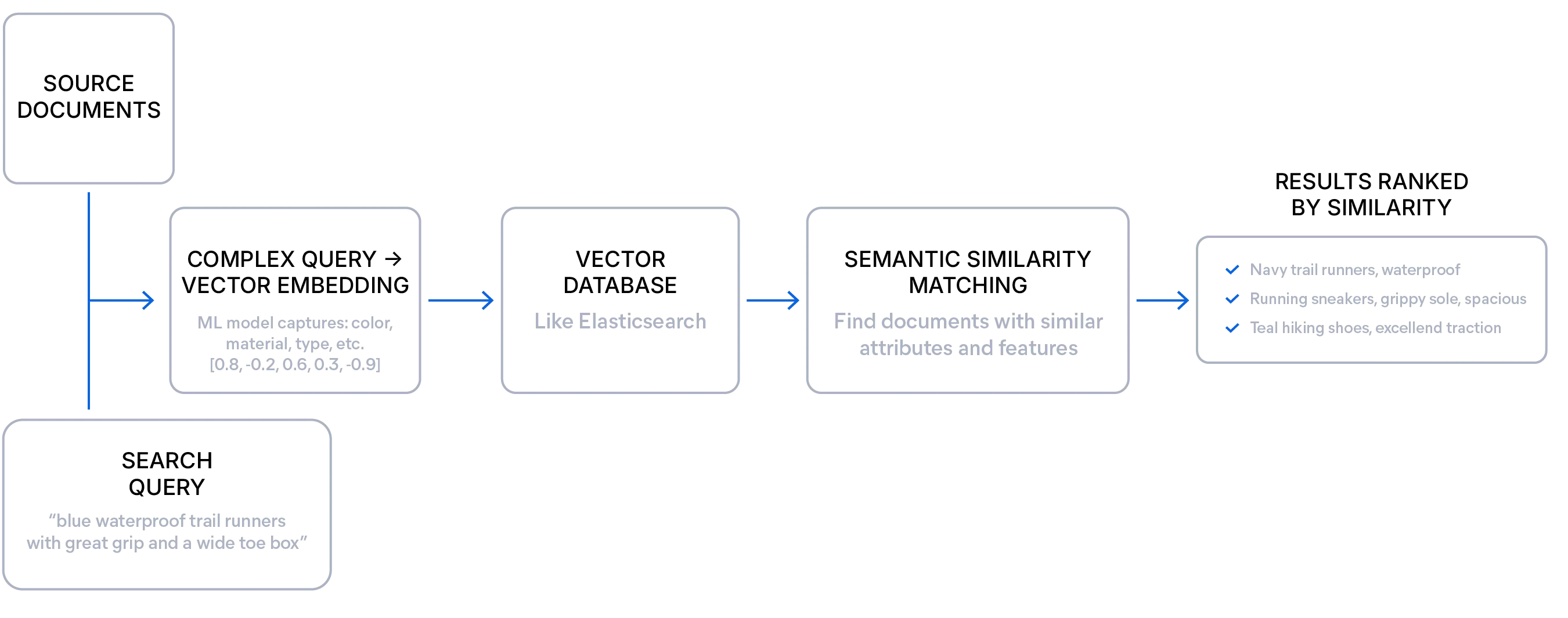
Essa abordagem é útil principalmente nos dados não estruturados, consultas exploratórias e casos em que os usuários podem não saber os termos exatos para usar. Os desenvolvedores podem usar a busca semântica para oferecer resultados mais relevantes e trabalhar com expressões vagas, detalhadas ou ambíguas, sem deixar de encontrar as respostas certas.
Confira abaixo um exemplo de consulta de busca semântica:
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
O ES|QL possibilita busca semântica quando seus mapeamentos incluem campos do tipo semantic_text. Uma vez que o documento tenha sido processado pelo modelo associado rodando no endpoint de inferência, você pode realizar uma busca semântica. Segue um exemplo de consulta em linguagem natural ao campo semantic_description:
DE cooking_blog METADADOS _score | WHERE semantic_description: "Quais são refeições à base de plantas fáceis de preparar, mas nutritivas?" | SORT _score DESC | LIMITE 5
Saiba mais sobre a busca semântica ou confira este tutorial prático para se aprofundar.
Algoritmos lexicais, como o BM25F, se destacam em precisão quando os termos da consulta correspondem aos termos do documento, mas falham quando o conteúdo relevante é expresso de forma diferente. (Por exemplo, uma consulta por "calçado esportivo" pode não encontrar documentos que digam apenas "sapatos" ou "tênis de trilha".) A busca vetorial semântica, usando incorporações de alta dimensão e algoritmos de vizinhos mais próximos aproximados (ANN, na sigla em inglês), como o HNSW, encontra documentos conceitualmente semelhantes, independentemente da sobreposição exata de termos — mas pode trazer resultados errados se o contexto for ambíguo.
Como funciona a busca híbrida
E se você pudesse ter o melhor dos dois mundos? É aqui que entra a busca híbrida. Quando bem feita, a busca híbrida é mais do que a soma de suas partes; ela pode produzir resultados muito melhores do que a busca lexical ou semântica sozinha. O modo híbrido oferece a você ambos, com relevância equilibrada, melhor ganho cumulativo descontado normalizado(NDCG) e maior recuperação, sem a necessidade de instalar um segundo sistema de busca.
Confira abaixo um exemplo de consulta de busca híbrida:
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
Você também pode combinar consultas semânticas e de texto completo no ES|QL. Neste exemplo, combinamos a busca por texto completo e a busca semântica com pesos personalizados:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
Executar uma consulta de busca híbrida normalmente envolve realizar pelo menos uma busca lexical e uma busca semântica e, em seguida, combinar os resultados. O principal desafio está em combinar várias listas classificadas em uma única classificação coerente.
Os resultados da busca lexical, gerados por algoritmos como BM25F ou TF-IDF, podem ser ilimitados, com valores máximos influenciados pela frequência dos termos e pela distribuição dos documentos. Em contraste, as pontuações de busca semântica geralmente se situam dentro de um intervalo fixo, determinado pela função de similaridade (por exemplo, [0, 2] para similaridade de cosseno).
Para combiná-los, você precisa de um método de fusão que mantenha a relevância relativa dos documentos encontrados.
Busca híbrida com o Elasticsearch
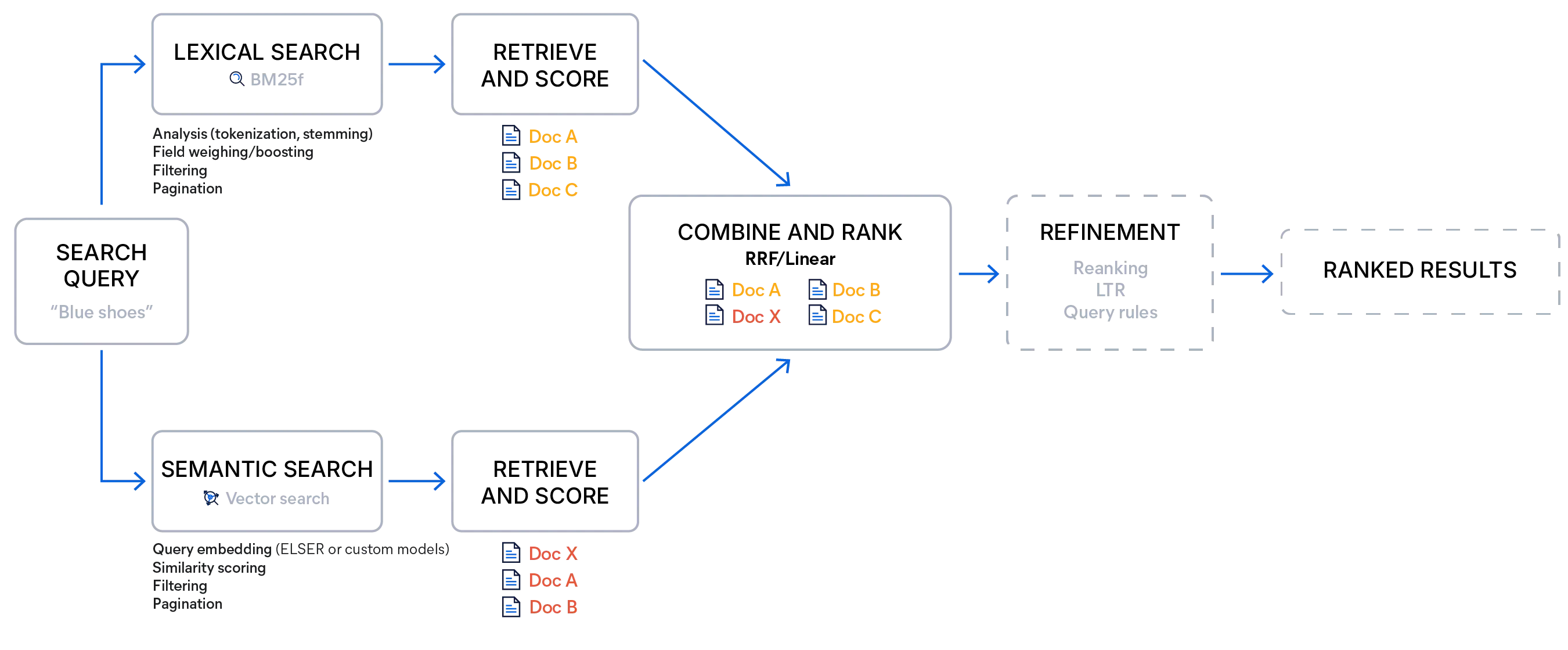
A busca híbrida com o Elasticsearch pode ser implementada combinando uma consulta de palavra-chave padrão com uma consulta vetorial ou usando um buscador — uma opção de busca que executa várias consultas de diferentes tipos e junta os resultados em uma lista classificada usando um método de pontuação escolhido. Isso permite pipelines de coleta com vários estágios em uma única chamada de busca, eliminando a necessidade de várias solicitações ou de lógica extra do lado do cliente para combinar os resultados.
O Elasticsearch oferece dois métodos integrados de fusão: fusão de rankings recíprocos (RRF) e combinação linear (frequentemente chamada de busca linear nas APIs). Ambos buscam produzir um ranking unificado que preserve os pontos fortes de cada busca, mas diferem em como tratam as pontuações e quando são mais eficazes.
A fusão de rankings recíprocos ignora totalmente as pontuações brutas e se concentra na altura em que um documento aparece em cada lista. Documentos classificados próximos ao topo de uma lista são fortemente recompensados, e documentos que aparecem em mais de uma lista recebem impulsos aditivos. O método é robusto porque evita problemas nas faixas de pontuação incompatíveis, não requer quase nenhum ajuste além da constante de classificação e, naturalmente, promove a diversidade nos melhores resultados.
A RRF pontua os documentos de acordo com a classificação no conjunto de resultados usando a seguinte fórmula, onde k é uma constante arbitrária para ajustar a importância de documentos de baixa classificação:
![]()
A RRF é útil principalmente quando os buscadores compartilham alguma sobreposição nos principais resultados e quando os desenvolvedores precisam de uma solução plug-and-play sem dados de treinamento rotulados nem calibração complexa.
A combinação linear, por outro lado, combinam diretamente as pontuações reais de cada buscador. Como as pontuações lexicais e semânticas operam em escalas muito diferentes, a normalização linear requer uma abordagem como o redimensionamento min-max para trazer as pontuações para uma faixa comparável.
Depois de normalizadas, as pontuações são combinadas usando pesos que representam a importância relativa de cada buscador. Um peso maior que 1 aumenta a influência de um buscador, enquanto um peso menor que 1 a reduz.
Essa abordagem permite um controle refinado: os desenvolvedores podem enfatizar o BM25F quando a precisão das palavras-chave é importante; inclinar-se para a semelhança semântica quando a intenção e o contexto são essenciais; ou integrar sinais comerciais ou de personalização adicionais às pontuações do buscador. Quando os pesos são cuidadosamente calibrados, a combinação linear pode superar a RRF ao produzir rankings mais precisos e previsíveis, mas requer experimentação e é sensível ao ajuste específico de cada conjunto de dados.
A combinação linear combina resultados de busca léxica e resultados de busca semântica com respectivos pesos e β (onde 0 ≤α, β), de forma que:
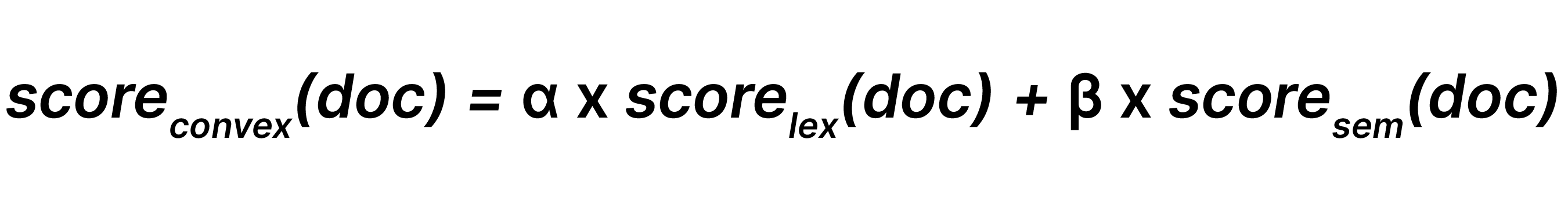
Na prática, a RRF é o melhor ponto de partida para a busca híbrida devido à simplicidade e resiliência a escalas de pontuação incompatíveis. Ela produz resultados sólidos sem ajustes extensos, sendo ideal na prototipagem ou quando os buscadores se sobrepõem. A combinação linear é mais adequada quando diferentes métodos de busca retornam resultados separados ou quando há a necessidade de equilibrar cuidadosamente os sinais lexicais, semânticos e externos. Resumindo, a RRF fornece hibridização rápida e confiável pronta para uso, enquanto o linear oferece maior precisão potencial quando os pesos e os normalizadores são ajustados à aplicação e aos dados.
Para resumir:
| Fusão de rankings recíprocos | Combinação linear |
|---|---|
Comece com a RRF para ter resultados híbridos robustos rapidamente. |
Migre para linear quando estiver pronto para ajustar a relevância. |
Resumindo, a combinação linear oferece maior potencial de precisão quando ajustada, enquanto a RRF é mais fácil de implementar e funciona bem sem dados de treinamento rotulados.
Confira este tutorial para aprender mais sobre busca híbrida.
Como funciona a busca híbrida
- Busca lexical: o BM25F combina termos de consulta com tokens indexados — ótimo para precisão, filtros estruturados e pontuação explicável.
- Busca semântica: vetores (densos ou esparsos) representam o significado do texto; a busca por similaridade encontra conteúdo relacionado mesmo sem palavras em comum.
- Fusão: combine pontuações com RRF, combinação ponderada ou um buscador linear. Filtros e reforços se aplicam de forma consistente em ambas as buscas.
| Tipo de busca | Como funciona | O que acontece | Ideal para quando |
|---|---|---|---|
| Busca lexical Consulta: "tênis de corrida vermelho tamanho 10" | Corresponde palavras exatas na consulta com palavras em documentos (BM25F, TF-IDF, analisadores, sinônimos). | Encontra produtos com esses tokens exatos no título/descrição (por exemplo, "Tênis de corrida Nike masculino vermelho, tamanho 10"). | O comprador sabe exatamente o que quer. Preciso, explicável e eficiente. |
| Busca semântica Consulta: "tênis leves para corrida" | Usa embeddings para capturar significado e contexto, não apenas palavras-chave. Encontra resultados conceitualmente relacionados mesmo que os termos não coincidam. | Retorna "Tênis de corrida Adidas Cloudfoam, tamanho 10", mesmo que "leve" e "para corrida" não apareçam exatamente dessa forma. | Os consumidores descrevem a intenção ou usam linguagem natural. Atende a consultas vagas ou descritivas. |
| Busca híbrida Consulta: "sapatos confortáveis para escritório" | Combina resultados lexicais e semânticos e então funde os rankings (via RRF). | Encontra correspondências exatas como "Sapatos sociais de couro preto, ajuste confortável" e itens semanticamente relacionados como "Mocassins com palmilhas acolchoadas". Ambos aparecem juntos, classificados por relevância. | Consultas misturam termos precisos e intenções. Concilia precisão com descoberta. |
Busca híbrida interna: vetores densos e esparsos
A busca semântica com o Elasticsearch funciona transformando consultas e documentos em representações vetoriais que capturam o significado. A busca híbrida combina recuperação lexical e semântica, seja usando modelos densos ou esparsos.
Vetores densos
Vetores densos são matrizes de números de comprimento fixo produzidas por modelos como o BERT, em que entradas semelhantes (como gato e gatinho) aparecem próximas no espaço vetorial. São ótimos para correspondência semântica, recomendações e busca por similaridade.
Quando o texto é embutido como um vetor denso, ele se apresenta assim:
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
Cada dimensão contém informações significativas, deixando os vetores densos em dados. Conteúdo semelhante produz embeddings próximos uns dos outros no espaço vetorial.
No Elasticsearch, vetores densos são armazenados em um campo dense_vector e consultados com algoritmos aproximados de vizinho mais próximo (ANN), como o HNSW. É ideal para capturar o significado semântico geral de textos, imagens ou outros conteúdos.
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
Aqui está um exemplo de ES|QL:
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESCComo podemos ver acima, uma consulta de busca híbrida simplesmente utiliza o buscador rrf, que combina uma consulta de busca lexical (por exemplo, uma consulta de correspondência) feita com um buscador padrão e uma consulta de busca vetorial especificada no buscador knn. O que essa consulta faz é primeiro recuperar as cinco melhores correspondências vetoriais no nível global, depois combiná-las com as correspondências lexicais e, por fim, retornar os 10 melhores resultados correspondentes. O buscador rrf usa a classificação RRF para combinar correspondências vetoriais e lexicais.
Vetores esparsos e ELSER
Embeddings densos não são a única forma de realizar busca semântica.
Os vetores esparsos contêm principalmente zeros, com alguns valores ponderados vinculados a termos interpretáveis, sendo eficientes em recursos, explicáveis e eficazes em casos de zero-shot.
Uma representação vetorial esparsa se apresenta assim:
{"f1":1.2,"f2":0.3,… }
No Elasticsearch, o Elastic Learned Sparse EncodeR (ELSER) é um modelo de processamento de linguagem natural (NLP) esparso fora do domínio que expande o texto em termos semanticamente relacionados e aloca pesos, permitindo correspondências além das palavras-chave exatas, preservando a interpretabilidade.
Além disso, o campo semantic_text deixa a busca semântica tão fácil quanto a busca de texto tradicional, lidando com a geração de embedding e inferência automaticamente na ingestão. Você pode indexar documentos como um campo de texto e executar uma consulta match simples — mesmo em índices onde o tipo de campo difere — para ter correspondências lexicais e semânticas sem lógica de consulta extra. Para controle avançado, use uma consulta knn ou sparse_vector no mesmo campo.
Exemplo com ELSER:
- Pré-treinado com aprox. 30 mil termos
- Armazenado como sparse_vector (pares de termo/peso)
- Gerado automaticamente no momento da ingestão com semantic_text ou no tempo de índice com o processador de ingestão de inferência
- Consultado via índice invertido (como busca lexical), sendo eficiente, fácil de filtrar e explicável
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Juntos, vetores densos e esparsos oferecem flexibilidade: os vetores densos são excelentes para capturar significados sutis, enquanto os vetores esparsos oferecem transparência e escalabilidade nas buscas no mundo real.
Veja como a expansão de texto com ELSER ajuda você a ter resultados melhores:
Vetores esparsos x densos na prática
| Vetores esparsos (ELSER) | Vetores densos | |
|---|---|---|
| Como funciona | Expande o texto em termos semanticamente relacionados e ponderados. Cada dimensão corresponde a um token com peso associado. | Codifica conteúdo (texto, imagens, etc.) em vetores de ponto flutuante de comprimento fixo. Significado semelhante = posições próximas no espaço vetorial. |
| Pontos fortes |
|
|
| Exemplos de casos de uso |
|
|
| Ideal para | Quando você precisa de aprimoramento semântico e transparência, ou quando os termos específicos do domínio são mais importantes | Quando você quer descoberta e semelhança baseadas no significado, não em palavras exatas, entre diferentes tipos de dados |
Busca híbrida com modelos densos e esparsos
Até agora, vimos duas formas diferentes de conduzir uma busca híbrida, dependendo se um espaço vetorial denso ou esparso estava sendo procurado. Podemos combinar dados densos e esparsos dentro do mesmo índice.
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
Indo além: busca híbrida com vetores densos, esparsos e BM25F
Este exemplo combina três buscadores e funde as listas classificadas com RRF:
- BM25F(correspondência no texto): correspondências precisas de palavra-chave/frase ("montanha nevada")
- kNN (image_vector): similaridade visual usando o embedding de imagem fornecido (k resultados de num_candidates)
- Semântico (texto_semântico): correspondências de conceitos por meio da expansão semântica da consulta
rank_window_size controla quantos resultados são fundidos; rank_constant balanceia as contribuições de cada lista.
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
Vejamos também um exemplo semelhante com ES|QL:
FROM my-index METADATA _score
| FORK (WHERE match(text, "montanha nevada") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "montanha nevada") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // 60 is the default anyway?
| SORT _score DESC
| LIMIT 50Conclusão
A busca híbrida une a precisão da busca de texto completo com o alcance contextual da busca semântica, entregando resultados mais precisos e relevantes em diversos conteúdos. Ao viabilizar modelos densos e esparsos e oferecer métodos flexíveis de fusão como combinação linear e fusão de rankings recíprocos, você pode adaptar a recuperação ao seu caso de uso — seja emparelhando consultas e vetores diretamente ou simplificando a recuperação multiestágio com um buscador. Graças a essa flexibilidade, a busca híbrida é uma ótima abordagem para consultas complexas, dados variados e exigências exigentes de relevância.
Confira este blog para saber o que é busca híbrida, os tipos de consulta que o Elasticsearch aceita e como construí-los.
Quer ir além dos vetores? Confira a busca híbrida inteligente com agentes LLM no Elasticsearch.
Pronto para colocar a mão na massa? Siga nosso tutorial de busca híbrida para combinar resultados de texto completo e kNN; ou consulte o tutorial ES|QL para realizar buscas e filtragens usando ES|QL.