Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
When it comes to search use cases, the ability to efficiently ingest and process data from various sources is crucial. Whether you're dealing with a SQL database, CRM, or any custom data sources, choosing the right tool for data ingestion can significantly impact your Elasticsearch experience. In this blog, we will explore three of the Elastic Stack’s data ingest tools for search: Logstash, Client APIs, and our Elastic Native Connectors + the Elastic Connector Framework. We'll delve into their strengths, ideal use cases, and the types of data they handle best.
Data ingestion tools
1. Logstash
Overview
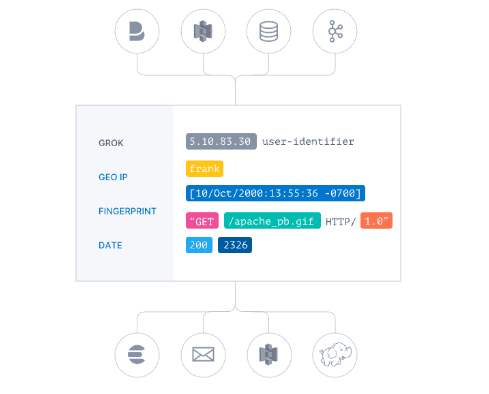
Logstash is a powerful, open-source data processing pipeline that ingests, transforms, and sends data to various outputs. It’s the Swiss Army knife of the Elastic Stack, Logstash has been widely used for log and event data processing, providing a versatile ETL tool for data ingestion.
Key features and strengths
One of Logstash's standout features is its rich plugin ecosystem, which supports a wide array of plugins for input, filter, and output. This extensive plugin library allows for significant customization and flexibility in data processing. Users can define complex data transformation and enrichment pipelines using pipeline configuration files, making it an ideal choice for scenarios where raw data needs substantial preprocessing.
See below for an example of a Logstash pipeline pulling access logs from a file, using filters to enrich the data, and shipping it to Elasticsearch.
One common use case is pulling data from a database. Let's take our previous example and modify it to use Logstash's JDBC input plugin, which allows you to pull data from any database with a JDBC interface (such as an Oracle DB). Using SQL queries, you can define the data you want to ingest.
Another use case for Logstash is using a combination of the Elasticsearch input and output plugins which allow you to pull and migrate data from one Elasticsearch cluster to another.
Best for
Logstash is best suited for use cases where data requires extensive enrichment before indexing into your cluster or if you’re looking to centralize ingest from various sources. One thing to keep in mind however is that Logstash does require you to host and administer it in a VM somewhere in your infrastruction (whether that be on-prem or in a cloud provider). If you're looking for something more lightweight for your use case please read on to learn more about our language clients and Connectors!
2. Elasticsearch clients

Elasticsearch clients are official libraries provided by Elastic that allow developers to interact with Elasticsearch clusters from their preferred programming environments. Available in languages such as Java, JavaScript, Python, Ruby, PHP, and more, these clients offer a consistent and simplified API for communicating with Elasticsearch.
Our Clients offer numerous benefits that simplify and enhance your interaction with your Elasticsearch clusters. Simplified APIs, language-specific libraries, performance optimizations, and comprehensive support make them indispensable tools for developers. This allows developers to build powerful, efficient, and reliable search applications tailored to your specific needs.
We currently offer Language Clients for the following programming languages:
- Java Client
- Java Low Level REST Client
- JavaScript Client
- Ruby Client
- Go Client
- .NET Client
- PHP Client
- Perl Client
- Python Clients
- Rust Client
- Eland Client
3. Native Connectors and the Connector Framework
Overview
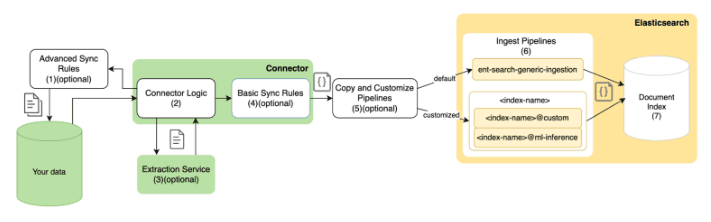
Elastic Native Connectors are built-in integrations within Elasticsearch that facilitate the seamless transfer of data from various sources directly into Elasticsearch indices. These connectors are designed to work out-of-the-box, requiring minimal setup and configuration, and are optimized for performance within the Elastic Stack.
In addition to our Native Connectors we also have the Elastic Connector Framework, which enables developers to customize an existing Elastic connector client or build an entirely new connector to an unsupported 3rd party data source with our Python based framework.
Key features and strengths
One of the most significant advantages of Elastic Native Connectors is the ease of use. All you need to do is go into Kibana and connect the data source with our simple configuration UI (or if you prefer Configuration as Code, you can utilize our Connector APIs).
Another powerful advantage of our Connectors the number of connectors that are supported for variety of 3rd-parties, such as:
- MongoDB
- Various SQL DBMS such as MySQL, PostgreSQL, MSSQL and OracleDB
- Sharepoint Online
- Amazon S3
- And many more. The full list is available here
Our Native Connectors allow for full and incremental syncs as well as sync scheduling, plus the ability to filter what data is ingested into Elastic via sync rules. Another powerful feature is the ability to utilize our Ingest Pipelines in conjunction with Native Connectors, this allows you to perform all kinds of transforms on your data as it is ingested. This also includes the use of Inference Pipelines for those who want to vectorize text in these documents to perform Semantic Search.
Best for
Elastic Native Connectors offer numerous benefits for data ingestion, including seamless integration with the Elastic Stack, simplified setup, a wide range of supported data sources, optimized performance, and robust security features. These advantages make them an excellent choice for organizations looking to streamline their data ingestion processes and enhance their search capabilities. With our Connector Framework you can also further customize the existing Connectors or build out a new one. Though as mentioned above the framework is python based so if you want to use a language you're more familiar with to ingest data we'd recommend checking out the Language Clients.
Summary
Choosing the right tool for data ingestion depends on the specific needs of your use case and where your data live. Logstash shines in scenarios requiring complex data transformations with centralized ingest but does come with administrative overhead and some complexity with its configuration files. Our Elasticsearch Clients give you the most freedom to build out your own ingestion capabilities in the programming language you're most comfortable with. Finally, Elastic Native Connectors offers simplified integration and management for 3rd party data sources, while our Connector Framework allows for custom integration with not yet supported data sources.
By understanding the strengths and best use cases for each tool, you can make informed decisions that can ensure that your data is efficiently ingested, indexed, and ready for search, enabling faster and more accurate insights to solve your use case.
For more in-depth information, check out the official documentation for Logstash, Elastic Native Connectors + Connector Framework, and our official language clients.
Related Content
December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.