New to Elasticsearch? Join our getting started with Elasticsearch webinar. You can also start a free cloud trial or try Elastic on your machine now.
Elastic offers many instructor-led, in-person and virtual live trainings, as well as on-demand trainings. Our flagship courses are Elasticsearch Engineer, Data Analysis with Kibana, and Elastic Observability Engineer. All of these courses lead to certifications.
We recently released the latest version of Elasticsearch Engineer training in response to increased demand and new features. This course is designed for both new Elasticsearch users and Elasticsearch professionals. It begins with the basics for getting started with the Elastic Stack, then quickly dives deep into topics ranging from optimizing search performance to building efficient clusters. View the detailed course outline to find out more about what you’ll learn. All lessons include hands-on labs.
During this instructor-led “Elasticsearch Engineer” training, one of the most common questions we get while teaching about snapshots is “how each snapshot is logically independent?” In this blog post, I will explain this in detail.
What is a snapshot?
A snapshot is a backup of a running Elasticsearch cluster. You can use snapshots to:
- Regularly back up a cluster with no downtime
- Recover data after deletion or a hardware failure
- Transfer data between clusters
- Reduce your storage costs by using searchable snapshots in the hot, cold and frozen data tiers
Deduplication of snapshots
To back up an index, a snapshot makes a copy of the index’s segments and stores them in the snapshot repository.
Indices are made up of shards. Each Elasticsearch shard is a Lucene index. Each Lucene index is divided into smaller units called segments. When you add new documents to your index, Lucene creates a new segment and writes to it. From time to time, Lucene merges smaller segments into a larger one.
Since segments are immutable, the snapshot only needs to copy any new segments created since the repository’s last snapshot.
Each snapshot is also logically independent. When you delete a snapshot, Elasticsearch only deletes the segments used exclusively by that snapshot. Elasticsearch doesn’t delete segments that are still used by other snapshots in the repository.
Let’s go through this example to get a better understanding.
- Suppose we take a snapshot (snap1) of a simple index with one shard and two segments.
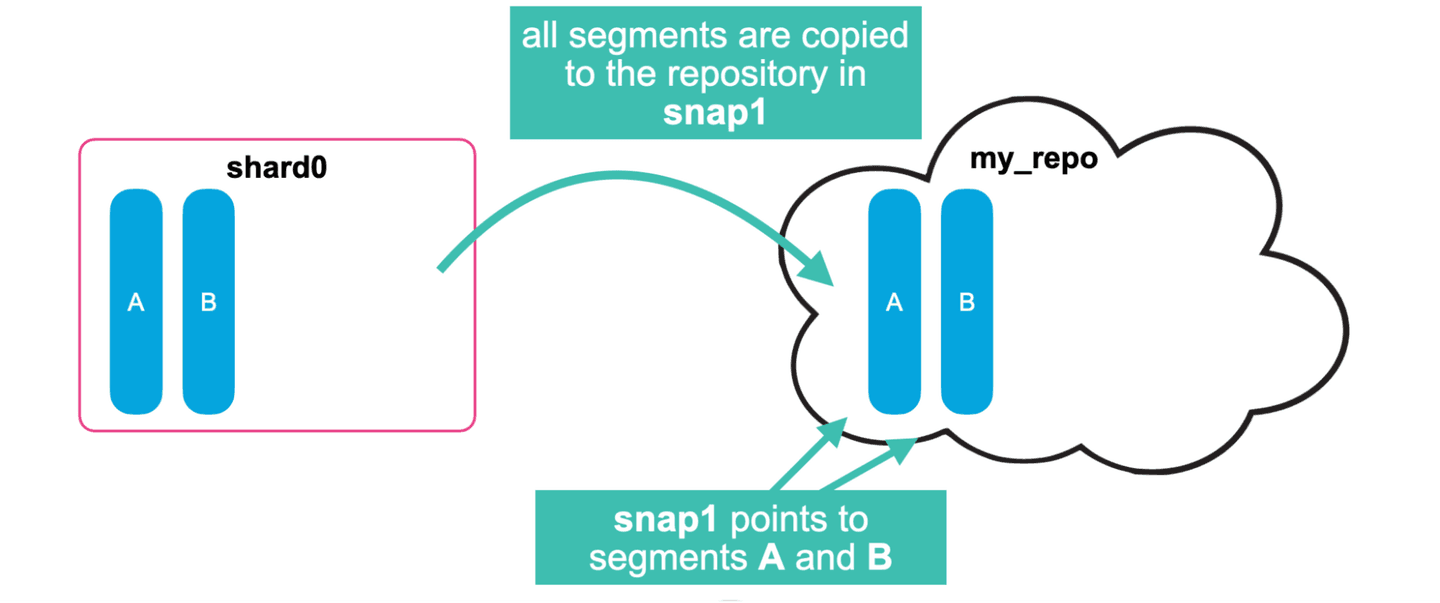
- Some time later as new documents are indexed, a new segment C gets creates in shard0.
- A second snapshot (snap2) will only copy the missing segment(s) to the repository.
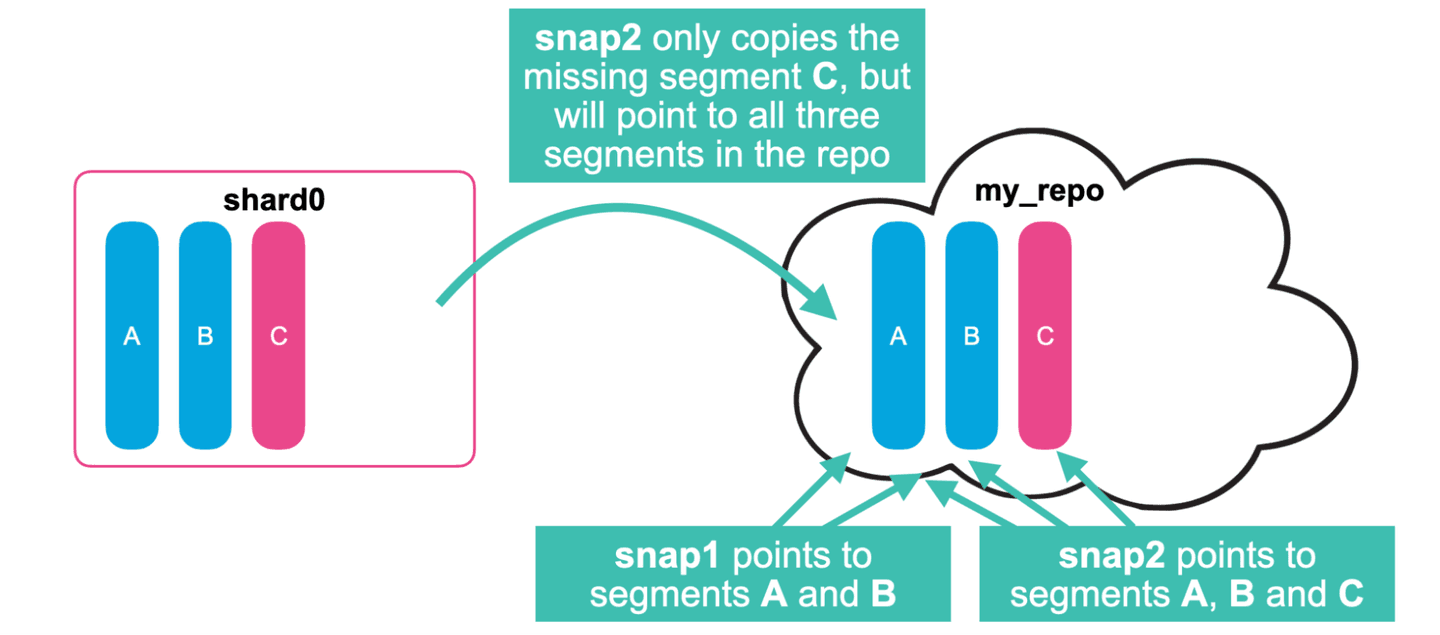
- Some time later, segments A, B, and C are merged, creating a new segment D.
- When creating a new snapshot (snap3), the new segment D is copied to the repository.
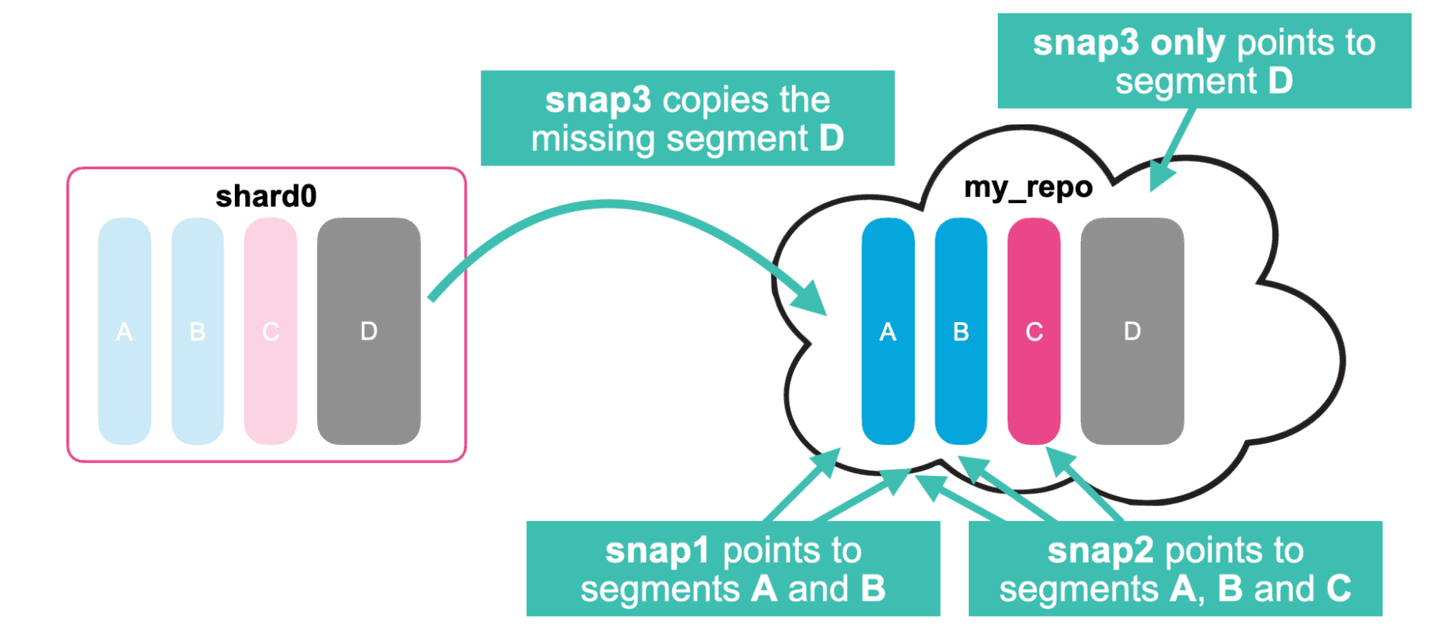
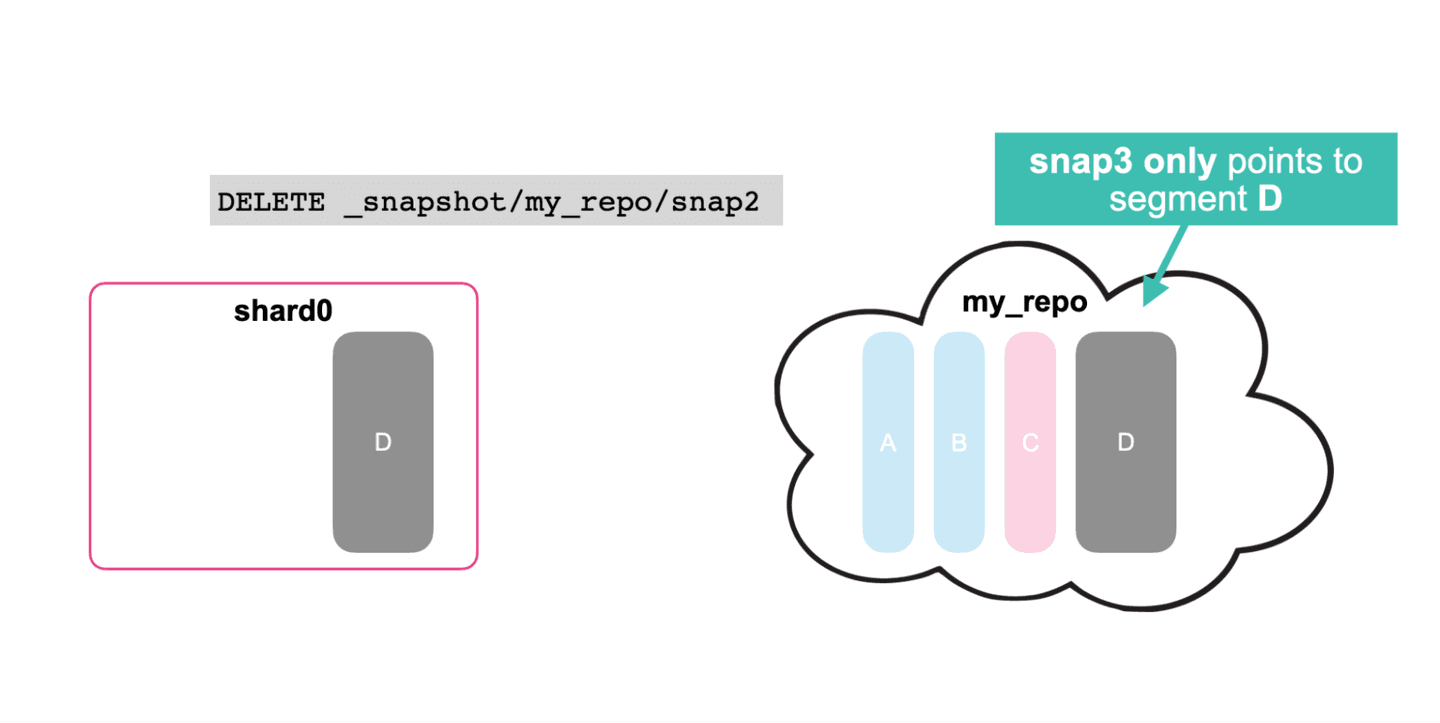
- Deleting a snapshot (snap1) only deletes segments in the repository that are no longer referenced by any other snapshot.
- In this case, no segments are deleted from the repository.
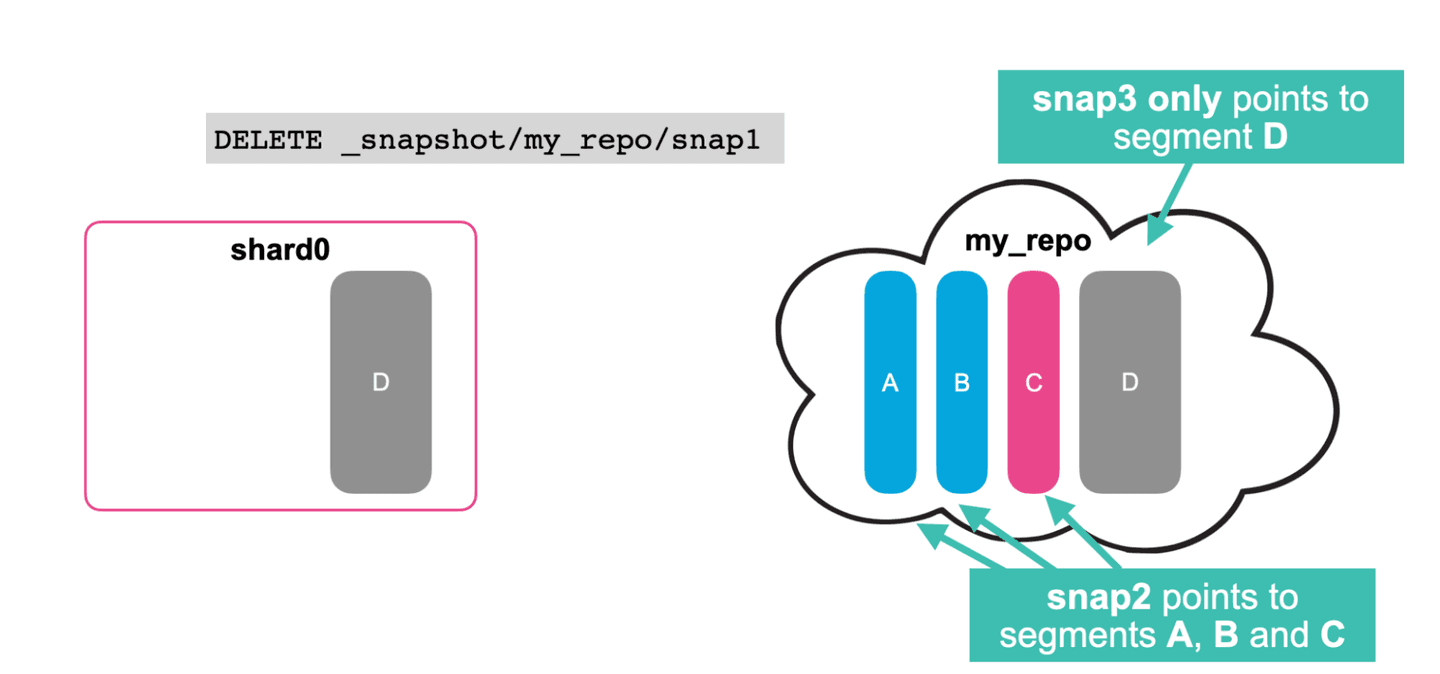
- Only after deleting snap2, segments A, B, and C will also be deleted from the repository.
Summary
In this blog post, I explained how snapshots are automatically deduplicated with the help of some graphics. For more information, please feel free to read through the official documentation.
The Elastic Stack is versatile enough to tackle any use case. Want to learn how to harness the power of that versatility? Become an Elastic expert through free, paid, private, and training subscriptions. Our instructor-led virtual classes are offered globally, in time zones that make learning convenient for you. Enhance your professional visibility and push aside technical boundaries within your company by becoming Elastic certified.
Reach out to us at training@elastic.co with any questions.
Related Content

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.
December 8, 2025
How excessive replica counts can degrade performance, and what to do about it
Learn about the impact of high replica counts in Elasticsearch, and how to ensure cluster stability by right-sizing your replicas.

November 14, 2025
How to deploy Elasticsearch on Azure AKS Automatic
Learn how to deploy Elasticsearch with Kibana on Azure using AKS Automatic and ECK for a partially managed Elasticsearch setup configuration.

November 11, 2025
Configuring recursive chunking for structured documents in Elasticsearch
Learn how to configure recursive chunking in Elasticsearch with chunk size, separator groups, and custom separator lists for optimal structured document indexing.

November 10, 2025
How to deploy Elasticsearch and Kibana on AWS EKS auto mode with ECK
Learn how to deploy Elasticsearch and Kibana on Kubernetes using AWS EKS Auto Mode and ECK in this easy-to-follow guide.