Elasticsearch is packed with new features to help you build the best search solutions for your use case. Learn how to put them into action in our hands-on webinar on building a modern Search AI experience. You can also start a free cloud trial or try Elastic on your local machine now.
In this article, we describe the most impactful storage improvements incorporated in our Elasticsearch time-series data offering and provide insights into the scenarios we expect our system to perform better - and worse - with regard to storage efficiency.
Background
Elasticsearch has recently invested in better support for storing and querying time-series data. Storage efficiency has been a main area of focus, with many projects delivering substantial wins that can lead to savings of up to 60-80%, compared to saving the data in standard indices. In certain scenarios, our system achieves storage efficiency of less than one byte per data point, competing head-to-head with state-of-the-art, specialized TSDB systems. Let's take a look at the recent improvements in storage efficiency for time-series data.
Storage improvements in Elasticsearch time-series data
Synthetic source
Elasticsearch stores the original JSON document body in the _source field by default. This duplication penalizes storage with diminishing returns for metrics, as they are normally inspected through aggregation queries that don’t use this field. To mitigate this, we introduced synthetic _source that reconstructs a flavor of the original _source on demand, using the data stored in the document fields. The caveats are that a limited number of field types are supported and _source synthesizing is slower than retrieving it from a stored field. Still, these restrictions are largely irrelevant for metrics datasets that mostly rely on keyword, numeric, boolean and IP fields and use aggregate queries that don’t take the _source content into account. We’re separately working on eliminating these limitations to make synthetic source applicable to any mapping.
The storage wins are immediate and apparent: enabling synthetic source reduces the size of time series data stream (TSDS) indices by 40-60% (more on performance evaluation below). Synthetic source is thus used by default in TSDS since it was released (v.8.7).
Specialized codecs
TSDB systems make heavy use of specialized codecs that take advantage of the chronological ordering of recorded metrics to reduce the number of bytes per data point. Our offering extends the standard Lucene codecs with support for run-length encoding, delta-of-deltas (2nd derivative), GCD and XOR encoding for numeric values. Codecs are specified at the Lucene segment level, so older indices can take advantage of the latest codecs when indexing fresh data.
To boost the efficiency of these compression techniques, indices get sorted by an identifier calculated over all dimension fields (ascending order), and then by timestamp (descending order, to return the latest data point per time series). This way, dimension fields (mostly keywords) get efficiently compressed with run-length encoding, while numeric values for metrics get clustered per time-series and ordered by time. Since most time-series change slowly over time, with occasional spikes, and Elasticsearch relies on Lucene’s vertically partitioned storage engine, this approach minimizes deltas between successively stored data and boosts storage efficiency.
Metadata trimming
The _id field is a metadata field used to uniquely identify each document in Elasticsearch. It has limited value for metrics applications, since time-series analysis relies on queries aggregating values over time, rather than inspecting individual metric values. To that end, TSDS trims the stored values but keeps the inverted index for this field to still support doc retrieval queries. This leads to 10-20% storage reduction with no loss of functionality.
Lifecycle integration
TSDSs can be integrated with data lifecycle management mechanisms, namely ILM and Data Stream Lifecycle. These tools automate deleting older indexes, while ILM also supports moving indices to tiers with cheaper storage (e.g. using spinning disks or archival cloud storage) as they age. Lifecycle management reduces storage costs, with no compromise on querying performance for frequently-accessed metrics and with minimal user involvement.
Downsampling
In many metrics applications, it’s preferable to keep finely-grained data in the short term only (e.g. per-minute data for the last week), and acceptable to increase granularity for older data to save on storage (e.g. per-hour data for the last month, per-day data for the last 2 years). Downsampling replaces raw metrics data with a statistical representation of pre-aggregated metrics over configurable time periods (e.g. hourly or daily). This improves both storage efficiency, since the size of downsampled indices is a fraction of the raw metrics indices, and querying performance, since aggregation queries scan pre-aggregated results instead of calculating them over raw data on-the-fly.
Downsampling is integrated with ILM and DSL that automate its application and allow for different resolutions of downsampled data as they age.
Test results for TSDS storage efficiency
TSDS storage gains
We track performance, including storage usage and efficiency, for TSDS through nightly benchmarks. The TSDB track (see disk usage visualization) visualizes the impact of our storage improvements. We’ll next present storage usage before TSDS was released, how it improved when TSDS was GA-ed, and what’s the current status.
The TSDB track’s dataset (k8s metrics) has nine dimension fields, with each document containing 33 fields (metrics and dimensions) on average. The index contains a day's worth of metrics over 116,633,696 documents.
Indexing the TSDB track’s dataset before ES version 8.7 required 56.9GB of storage. It is interesting to break this down by metadata fields, the timestamp field, dimension fields and metric fields to gain insight into storage usage:
| Field name | Percentage |
|---|---|
| _id | 5.1% |
| _seq_no | 1.4% |
| _source | 78.0% |
| @timestamp | 1.31% |
| Dimension fields | 2.4% |
| Metric fields | 5.1% |
| Other fields | 9.8% |
The _source metadata field is the largest contributor to the storage footprint by far. Synthetic source was one of the improvements that our metrics effort motivated to improve storage efficiency, as mentioned earlier. This is evident in ES 8.7 that uses synthetic source for TSDS by default. In this case, the storage footprint drops to 6.5GB - a 8.75x improvement in storage efficiency. Breaking this down by field type:
| Field name | Percentage |
|---|---|
| _id | 18.7% |
| _seq_no | 14.1% |
| @timestamp | 12.6% |
| Dimension fields | 3.6% |
| Metric fields | 12.0% |
| Other fields | 50.4% |
The improvement is due to the _source no longer being stored, as well as applying index sorting to store metrics from the same time series sequentially, thus boosting the efficiency of standard Lucene codecs.
Indexing the TSDB track’s dataset with ES 8.13.4 occupies 4.5GB of storage - a further 44% improvement. The breakdown by field type is:
| Field name | Percentage |
|---|---|
| _id | 12.2% |
| _seq_no | 20.6% |
| @timestamp | 14.0% |
| Dimension fields | 1.6% |
| Metric fields | 6.7% |
| Other fields | 58.6% |
This is a substantial improvement, compared to the 8.7.0 version. The main contributing factors to the latest iteration are the _id field taking up less storage space (its stored values get trimmed), while dimension fields and other numeric fields get compressed more efficiently using the latest time-series codecs.
The majority of storage is now attributed to “other fields”, i.e. fields providing context similar to dimensions but are not used in calculating the identifier that’s used for index sorting, so their compression is not as efficient as with dimension fields.
Downsample storage gains
Downsampling trades querying resolution for storage gains, depending on the downsampling interval. Downsampling the metrics in TSDB track’s dataset (with metrics collected every 10 seconds) using a 1-minute interval results in an index of 748MB - a 6x improvement. The downside is that metrics get pre-aggregated on a per-minute granularity, so it’s no longer possible to inspect individual metric recordings or aggregate over sub-minute intervals (e.g. per 5 seconds). Most importantly, aggregation results on the pre-computed statistics (min, max, sum, count, average) are the same as if calculated over the original data, so downsampling doesn’t incur any cost in accuracy.
If lower resolution can be tolerated and metrics get downsampled using an hourly interval, the resulting downsampled index will use just 56MB of storage. Note that the improvement is 13.3x, i.e. lower than 60x that one would expect from switching from a per-minute downsampling interval to a per-hour one. This is due to additional metadata that all indices require to store per segment, a constant overhead that becomes more noticeable as the index size reduces.
Putting everything together
The following graph shows how storage efficiency evolved across versions, as well as what additional savings downsampling can provide. Kindly note that the vertical axis is in logarithmic scale.
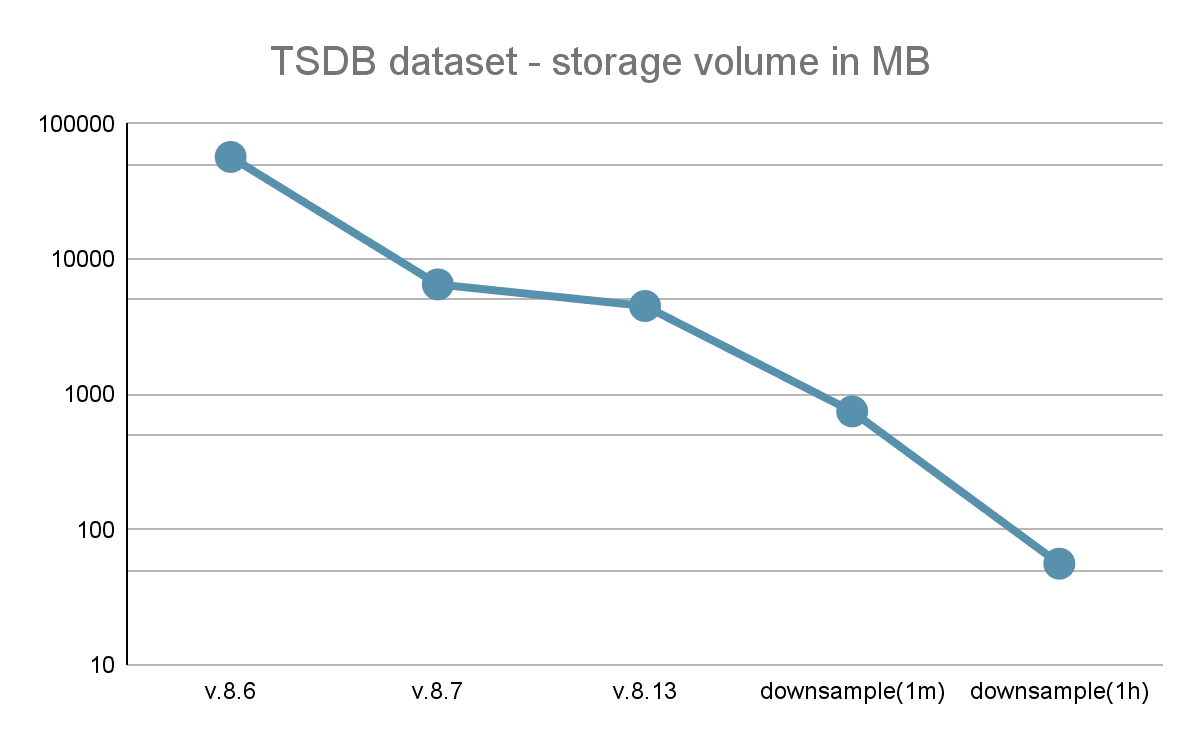
In total, we achieved a 12.5x improvement in storage efficiency for our metrics offering over the past releases. This can even reach 1000x or better, if we trade bucketing resolution for reduced storage footprint through downsampling.
Configuration hints for TSDS
In this section, we explore best practices for configuring a TSDS with storage efficiency in mind.
Favor many metrics per document
While Elasticsearch uses vertical partitioning to store each field separately, fields are still grouped logically in docs. Since metrics share dimensions that are included in the same doc, the storage overhead for dimensions and metadata gets better amortized when we include as many metrics as possible in each indexed doc. On the flip side, storing a single metric in each doc, along with its associated dimensions, maximizes the overhead of dimensions and metadata and bloats storage.
More concretely, we used synthetic datasets to quantify the impact of the number of metrics per document. When we included all metrics (20) in each indexed doc, TSDS used as little as 0.9 bytes per data point - approximating the performance of state-of-the-art, purpose-built metrics systems (0.7 bytes per data point) that lack the rich indexing and querying capabilities of Elasticsearch for unstructured data. Conversely, when each indexed doc had a single metric, TSDS required 20 bytes per data point, a substantial increase in the storage footprint. It therefore pays off to group together as many metrics as possible in each indexed doc, sharing the same dimensions values.
Trim unnecessary dimensions
The Elasticsearch architecture allows our metrics offering to scale far better than competing systems, when it comes to the number of time series per metric (i.e. the product of the dimension cardinalities) in the order of millions or more, at a manageable performance cost. Still, dimensions do take considerable space and high cardinalities reduce the efficiency of our compression techniques for TSDS. It’s therefore important to carefully consider what fields are included in indexed documents for metrics and aggressively prune dimensions to the minimum required set for dashboards and troubleshooting.
One interesting example here was an Observability mapping including an IP field that turned out to contain up to 16 IP ( v4, v6) addresses of the hosting machine. It had a substantial impact on both storage footprint and indexing throughput and was hardly used. Replacing it with a machine label led to a sizable storage improvement with no loss of debuggability.
Use lifecycle management
ILM facilitates moving older, infrequently-accessed data to cheaper storage options, and both ILM and Data Stream Lifecycle can handle deleting metrics data as they age. This fully-automated approach reduces storage costs without changing index mappings or configuration and is thus highly encouraged.
More so, it is worth considering trading metrics resolution for storage through downsampling, as data ages. This technique leads to both substantial storage wins and more responsive dashboards, assuming that the reduction in bucketing resolution is acceptable for older data - a common case in practice, as it’s fairly rare to inspect months-old data at a per-minute granularity, for instance.
Next steps
We’ve achieved a significant improvement in the storage footprint for metrics over the past years. We intend to apply these optimizations to additional data types beyond metrics, and specifically logs data. While some features are metrics-specific, such as downsampling, we still hope to see reductions in the order of 2-4x using a logs-specific index configuration.
Despite reducing the storage overhead of metadata fields that all Elasticsearch indices require, we plan to trim them more aggressively. Good candidates are the _id and _seq_no fields. Furthermore, there are opportunities to apply more advanced indexing techniques, such as sparse indices, to timestamps and other fields supporting range queries.
The downsampling mechanism has a big potential for improved querying performance, if a small storage penalty is acceptable. One idea is to support multiple downsampling resolutions (e.g. raw, per-hour and per-day) on overlapping time periods, with the query engine automatically picking the most appropriate resolution for each query. This would allow users to spec downsampling to match their dashboard time scaling and make them more responsive, as well as kick off downsampling within minutes after indexing. It would also unlock keeping raw data along with downsampled, potentially using a slower/cheaper storage layer.
Try it out
- Sign up for Elastic Cloud, if you don’t have an account yet
- Configure a TSDS and use it for storing and querying metrics
- Explore downsampling to see if it fits your use case
- Enjoy the storage savings
Related Content

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.
December 8, 2025
How excessive replica counts can degrade performance, and what to do about it
Learn about the impact of high replica counts in Elasticsearch, and how to ensure cluster stability by right-sizing your replicas.

Improving Kibana dashboard interactivity with variable controls
Discover how to use variable controls in Kibana 8.18+ to filter individual visualizations, adjust time intervals, and group by different fields in Kibana dashboards.

November 14, 2025
How to deploy Elasticsearch on Azure AKS Automatic
Learn how to deploy Elasticsearch with Kibana on Azure using AKS Automatic and ECK for a partially managed Elasticsearch setup configuration.

November 11, 2025
Configuring recursive chunking for structured documents in Elasticsearch
Learn how to configure recursive chunking in Elasticsearch with chunk size, separator groups, and custom separator lists for optimal structured document indexing.