O que são embeddings vetoriais?
Definição de embeddings vetoriais
Embeddings vetoriais são uma forma de converter palavras, frases e outros dados em números que capturam seus significados e relações.Eles representam diferentes tipos de dados como pontos em um espaço multidimensional, onde pontos de dados semelhantes são agrupados mais próximos. Essas representações numéricas ajudam as máquinas a compreender e processar esses dados de maneira mais eficaz.
Embeddings de palavras e frases são dois dos subtipos mais comuns de embeddings vetoriais, mas existem outros. Alguns embeddings vetoriais podem representar documentos inteiros, bem como vetores de imagem projetados para combinar conteúdo visual, vetores de perfil de usuário para determinar as preferências de um usuário, vetores de produto que ajudam a identificar produtos similares e muitos outros. Os embeddings vetoriais ajudam os algoritmos de machine learning a encontrar padrões nos dados e realizar tarefas como análise de sentimentos, tradução de idiomas, sistemas de recomendação e muito mais.
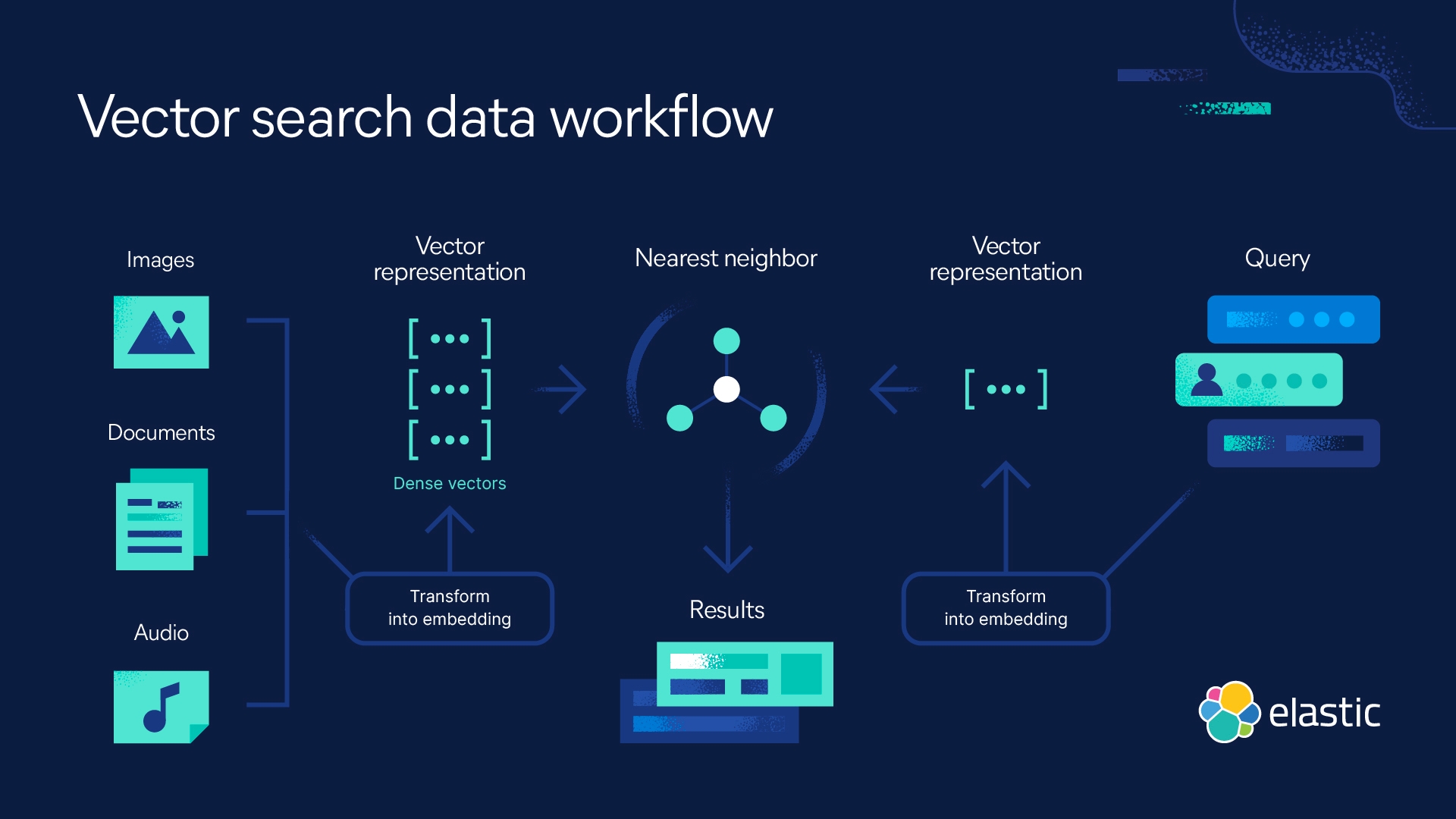
Tipos de embeddings vetoriais
Existem vários tipos diferentes de embeddings vetoriais que são comumente usados em diversas aplicações. Aqui estão alguns exemplos:
Embeddings de palavras representam palavras individuais como vetores. Técnicas como Word2Vec, GloVe e FastText aprendem embeddings de palavras capturando relações semânticas e informações contextuais de grandes corpora de texto.
Embeddings de frases representam frases inteiras como vetores. Modelos como Universal Sentence Encoder (USE) e SkipThought geram embeddings que capturam o significado geral e o contexto das frases.
Embeddings de documentos representam documentos (desde artigos de jornais e trabalhos acadêmicos até livros) como vetores. Eles capturam as informações semânticas e o contexto de todo o documento. Técnicas como Doc2Vec e Paragraph Vectors são projetadas para aprender embeddings de documentos.
Embeddings de imagens representam imagens como vetores capturando diferentes recursos visuais. Técnicas como redes neurais convolucionais (CNNs) e modelos pré-treinados como ResNet e VGG geram embeddings de imagens para tarefas como classificação de imagens, detecção de objetos e similaridade de imagens.
Embeddings de usuários representam usuários em um sistema ou plataforma como vetores. Eles capturam preferências, comportamentos e características do usuário. Os embeddings de usuários podem ser usados em tudo, desde sistemas de recomendação até marketing personalizado, bem como segmentação de usuários.
Embeddings de produtos representam produtos em e-commerce ou sistemas de recomendação como vetores. Eles capturam os atributos, recursos e qualquer outra informação semântica disponível de um produto. Os algoritmos podem então usar esses embeddings para comparar, recomendar e analisar produtos com base em suas representações vetoriais.
Embeddings e vetores são a mesma coisa?
No contexto de embeddings vetoriais, sim, embeddings e vetores são a mesma coisa. Ambos se referem a representações numéricas de dados, onde cada ponto de dados é representado por um vetor em um espaço de alta dimensão.
O termo “vetor” refere-se apenas a uma sequência de números com uma dimensionalidade específica. No caso dos embeddings vetoriais, esses vetores representam qualquer um dos pontos de dados mencionados acima em um espaço contínuo. Por outro lado, “embeddings” refere-se especificamente à técnica de representar dados como vetores de forma a capturar informações significativas, relações semânticas ou características contextuais. Os embeddings são projetados para capturar a estrutura ou propriedades subjacentes dos dados e normalmente são aprendidos por meio de algoritmos ou modelos de treinamento.
Embora embeddings e vetores possam ser usados indistintamente no contexto de embeddings vetoriais, “embeddings” enfatiza a noção de representação dos dados de uma forma significativa e estruturada, enquanto “vetores” se refere à própria representação numérica.
Como os embeddings vetoriais são criados?
Os embeddings vetoriais são criados por meio de um processo de machine learning no qual um modelo é treinado para converter qualquer um dos dados listados acima (bem como outros) em vetores numéricos. Aqui está uma rápida visão geral de como isso funciona:
- Primeiro, reúna um grande conjunto de dados que represente o tipo de dados para o qual você quer criar embeddings, como texto ou imagens.
- Em seguida, você pré-processará os dados. Isso requer limpeza e preparação dos dados, removendo ruídos, normalizando o texto, redimensionando imagens ou várias outras tarefas, dependendo do tipo de dados com o qual você estiver trabalhando.
- Você selecionará um modelo de rede neural que seja adequado para seus objetivos de dados e alimentará o modelo com os dados pré-processados.
- O modelo aprende padrões e relações dentro dos dados ajustando seus parâmetros internos durante o treinamento. Por exemplo, ele aprende a associar palavras que aparecem juntas com frequência ou a reconhecer características visuais nas imagens.
- À medida que o modelo aprende, gera vetores numéricos (ou embeddings) que representam o significado ou as características dos dados. Cada ponto de dados, como uma palavra ou imagem, é representado por um vetor único.
- A esta altura, você pode avaliar a qualidade e a eficácia dos embeddings medindo seu desempenho em tarefas específicas ou usando humanos para avaliar a similaridade dos resultados fornecidos.
- Depois de avaliar se os embeddings estão funcionando bem, você pode colocá-los para trabalhar analisando e processando seus conjuntos de dados.
Como é o embedding vetorial?
O comprimento ou a dimensionalidade do vetor depende da técnica de embedding específica que você está usando e de como você quer que os dados sejam representados. Por exemplo, se você estiver criando embeddings de palavras, eles geralmente terão dimensões que variam de algumas centenas a alguns milhares, algo complexo demais para ser diagramado visualmente por humanos. Os embeddings de frases ou documentos podem ter dimensões maiores porque capturam informações semânticas ainda mais complexas.
O embedding vetorial em si é normalmente representado como uma sequência de números, como [0.2, 0.8, -0.4, 0,6, ...]. Cada número na sequência corresponde a uma característica ou dimensão específica e contribui para a representação geral do ponto de dados. Dito isso, os números reais dentro do vetor não são significativos por si só. São os valores relativos e as relações entre os números que capturam a informação semântica e permitem que os algoritmos processem e analisem os dados de forma eficaz.
Aplicações dos embeddings vetoriais
Os embeddings vetoriais têm uma ampla gama de aplicações em vários campos. Aqui estão alguns exemplos comuns que você pode encontrar:
O processamento de linguagem natural (PLN) usa extensivamente o embedding vetorial para tarefas como análise de sentimentos, reconhecimento de entidade nomeada, classificação de texto, tradução por máquina, resposta a perguntas e similaridade de documentos. Ao usar embeddings, os algoritmos podem compreender e processar dados relacionados a texto de forma mais eficaz.
Mecanismos de busca usam embeddings vetoriais para recuperar informações e ajudar a identificar relações semânticas. Os embeddings vetoriais ajudam o mecanismo de busca a responder a uma consulta do usuário e retornar páginas da web relevantes, recomendar artigos, corrigir palavras com erros ortográficos na consulta e sugerir consultas relacionadas semelhantes que o usuário possa achar úteis. Esta aplicação é frequentemente usada para aprimorar a busca semântica.
Sistemas de recomendação personalizados utilizam embeddings vetoriais para capturar preferências dos usuários e características dos itens. Eles ajudam a corresponder perfis de usuários com itens de que o usuário também pode gostar, como produtos, filmes, músicas ou artigos de notícias, com base em correspondências próximas entre o usuário e os itens dentro do vetor. Um exemplo conhecido é o sistema de recomendação da Netflix. Você já se perguntou como ele seleciona filmes que têm a ver com seus gostos? Ele faz isso usando medidas de similaridade item a item para sugerir conteúdo semelhante ao que o usuário costuma assistir.
Conteúdo visual também pode ser analisado por meio de embeddings vetoriais. Algoritmos treinados nesses tipos de embeddings vetoriais podem classificar imagens, identificar objetos e detectá-los em outras imagens, procurar imagens semelhantes e classificar todos os tipos de imagens (bem como vídeos) em categorias distintas. A tecnologia de reconhecimento de imagem usada pelo Google Lens é uma ferramenta de análise de imagem usada com frequência.
Detecção de anomalias algoritmos usam embeddings vetoriais para identificar padrões incomuns ou outliers em vários tipos de dados. O algoritmo é treinado com embeddings que representam o comportamento normal para que ele consiga aprender a identificar desvios da norma que podem ser detectados com base em distâncias ou medidas de dissimilaridade entre embeddings. Isso é especialmente útil em aplicações de segurança cibernética.
A análise de dados gráficos usa embeddings de gráficos, em que os gráficos são uma coleção de pontos (chamados nós) conectados por linhas (chamadas arestas). Cada nó representa uma entidade, como uma pessoa, uma página da web ou um produto, e cada aresta representa uma relação ou conexão entre essas entidades. Esses embeddings vetoriais podem fazer tudo, desde sugerir amigos em redes sociais até detectar anomalias de segurança cibernética (conforme descrito acima).
Áudio e música também podem ser processados e incorporados. Os embeddings vetoriais capturam características de áudio que permitem aos algoritmos analisar dados de áudio com eficácia. Isso pode ser usado para uma variedade de aplicações, como recomendações de músicas, classificações de gênero, buscas de similaridade de áudio, reconhecimento de fala e verificação de falante.
Comece a usar o embedding vetorial com o Elasticsearch
A plataforma Elasticsearch integra nativamente poderosos recursos de machine learning e IA em soluções, ajudando você a criar aplicativos que beneficiam seus usuários e a realizar o trabalho mais rapidamente. O Elasticsearch é o componente central do Elastic Stack, um conjunto de ferramentas open source para ingestão, enriquecimento, armazenamento, análise e visualização de dados.
O Elasticsearch ajuda você a:
- Melhorar as experiências do usuário e aumentar as conversões
- Possibilitar novos insights, automação, analítica e relatórios
- Aumentar a produtividade dos funcionários em documentos e aplicações internos
Experimente recursos de busca de IA de ponta com seus próprios dados no AI Playground.