- Elasticsearch Guide: other versions:
- Getting Started
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Secure Settings
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- Important System Configuration
- Upgrading Elasticsearch
- Stopping Elasticsearch
- Set up X-Pack
- Breaking changes
- Breaking changes in 5.6
- Breaking changes in 5.5
- Breaking changes in 5.4
- Breaking changes in 5.3
- Breaking changes in 5.2
- Breaking changes in 5.1
- Breaking changes in 5.0
- Search and Query DSL changes
- Mapping changes
- Percolator changes
- Suggester changes
- Index APIs changes
- Document API changes
- Settings changes
- Allocation changes
- HTTP changes
- REST API changes
- CAT API changes
- Java API changes
- Packaging
- Plugin changes
- Filesystem related changes
- Path to data on disk
- Aggregation changes
- Script related changes
- API Conventions
- Document APIs
- Search APIs
- Aggregations
- Metrics Aggregations
- Avg Aggregation
- Cardinality Aggregation
- Extended Stats Aggregation
- Geo Bounds Aggregation
- Geo Centroid Aggregation
- Max Aggregation
- Min Aggregation
- Percentiles Aggregation
- Percentile Ranks Aggregation
- Scripted Metric Aggregation
- Stats Aggregation
- Sum Aggregation
- Top hits Aggregation
- Value Count Aggregation
- Bucket Aggregations
- Adjacency Matrix Aggregation
- Children Aggregation
- Date Histogram Aggregation
- Date Range Aggregation
- Diversified Sampler Aggregation
- Filter Aggregation
- Filters Aggregation
- Geo Distance Aggregation
- GeoHash grid Aggregation
- Global Aggregation
- Histogram Aggregation
- IP Range Aggregation
- Missing Aggregation
- Nested Aggregation
- Range Aggregation
- Reverse nested Aggregation
- Sampler Aggregation
- Significant Terms Aggregation
- Terms Aggregation
- Pipeline Aggregations
- Avg Bucket Aggregation
- Derivative Aggregation
- Max Bucket Aggregation
- Min Bucket Aggregation
- Sum Bucket Aggregation
- Stats Bucket Aggregation
- Extended Stats Bucket Aggregation
- Percentiles Bucket Aggregation
- Moving Average Aggregation
- Cumulative Sum Aggregation
- Bucket Script Aggregation
- Bucket Selector Aggregation
- Serial Differencing Aggregation
- Matrix Aggregations
- Caching heavy aggregations
- Returning only aggregation results
- Aggregation Metadata
- Returning the type of the aggregation
- Metrics Aggregations
- Indices APIs
- Create Index
- Delete Index
- Get Index
- Indices Exists
- Open / Close Index API
- Shrink Index
- Rollover Index
- Put Mapping
- Get Mapping
- Get Field Mapping
- Types Exists
- Index Aliases
- Update Indices Settings
- Get Settings
- Analyze
- Index Templates
- Shadow replica indices
- Indices Stats
- Indices Segments
- Indices Recovery
- Indices Shard Stores
- Clear Cache
- Flush
- Refresh
- Force Merge
- cat APIs
- Cluster APIs
- Query DSL
- Mapping
- Analysis
- Anatomy of an analyzer
- Testing analyzers
- Analyzers
- Normalizers
- Tokenizers
- Token Filters
- Standard Token Filter
- ASCII Folding Token Filter
- Flatten Graph Token Filter
- Length Token Filter
- Lowercase Token Filter
- Uppercase Token Filter
- NGram Token Filter
- Edge NGram Token Filter
- Porter Stem Token Filter
- Shingle Token Filter
- Stop Token Filter
- Word Delimiter Token Filter
- Word Delimiter Graph Token Filter
- Stemmer Token Filter
- Stemmer Override Token Filter
- Keyword Marker Token Filter
- Keyword Repeat Token Filter
- KStem Token Filter
- Snowball Token Filter
- Phonetic Token Filter
- Synonym Token Filter
- Synonym Graph Token Filter
- Compound Word Token Filters
- Reverse Token Filter
- Elision Token Filter
- Truncate Token Filter
- Unique Token Filter
- Pattern Capture Token Filter
- Pattern Replace Token Filter
- Trim Token Filter
- Limit Token Count Token Filter
- Hunspell Token Filter
- Common Grams Token Filter
- Normalization Token Filter
- CJK Width Token Filter
- CJK Bigram Token Filter
- Delimited Payload Token Filter
- Keep Words Token Filter
- Keep Types Token Filter
- Classic Token Filter
- Apostrophe Token Filter
- Decimal Digit Token Filter
- Fingerprint Token Filter
- Minhash Token Filter
- Character Filters
- Modules
- Index Modules
- Ingest Node
- Pipeline Definition
- Ingest APIs
- Accessing Data in Pipelines
- Handling Failures in Pipelines
- Processors
- Append Processor
- Convert Processor
- Date Processor
- Date Index Name Processor
- Fail Processor
- Foreach Processor
- Grok Processor
- Gsub Processor
- Join Processor
- JSON Processor
- KV Processor
- Lowercase Processor
- Remove Processor
- Rename Processor
- Script Processor
- Set Processor
- Split Processor
- Sort Processor
- Trim Processor
- Uppercase Processor
- Dot Expander Processor
- X-Pack APIs
- Info API
- Explore API
- Machine Learning APIs
- Close Jobs
- Create Datafeeds
- Create Jobs
- Delete Datafeeds
- Delete Jobs
- Delete Model Snapshots
- Flush Jobs
- Get Buckets
- Get Categories
- Get Datafeeds
- Get Datafeed Statistics
- Get Influencers
- Get Jobs
- Get Job Statistics
- Get Model Snapshots
- Get Records
- Open Jobs
- Post Data to Jobs
- Preview Datafeeds
- Revert Model Snapshots
- Start Datafeeds
- Stop Datafeeds
- Update Datafeeds
- Update Jobs
- Update Model Snapshots
- Security APIs
- Watcher APIs
- Migration APIs
- Deprecation Info APIs
- Definitions
- X-Pack Commands
- How To
- Testing
- Glossary of terms
- Release Notes
- 5.6.16 Release Notes
- 5.6.15 Release Notes
- 5.6.14 Release Notes
- 5.6.13 Release Notes
- 5.6.12 Release Notes
- 5.6.11 Release Notes
- 5.6.10 Release Notes
- 5.6.9 Release Notes
- 5.6.8 Release Notes
- 5.6.7 Release Notes
- 5.6.6 Release Notes
- 5.6.5 Release Notes
- 5.6.4 Release Notes
- 5.6.3 Release Notes
- 5.6.2 Release Notes
- 5.6.1 Release Notes
- 5.6.0 Release Notes
- 5.5.3 Release Notes
- 5.5.2 Release Notes
- 5.5.1 Release Notes
- 5.5.0 Release Notes
- 5.4.3 Release Notes
- 5.4.2 Release Notes
- 5.4.1 Release Notes
- 5.4.0 Release Notes
- 5.3.3 Release Notes
- 5.3.2 Release Notes
- 5.3.1 Release Notes
- 5.3.0 Release Notes
- 5.2.2 Release Notes
- 5.2.1 Release Notes
- 5.2.0 Release Notes
- 5.1.2 Release Notes
- 5.1.1 Release Notes
- 5.1.0 Release Notes
- 5.0.2 Release Notes
- 5.0.1 Release Notes
- 5.0.0 Combined Release Notes
- 5.0.0 GA Release Notes
- 5.0.0-rc1 Release Notes
- 5.0.0-beta1 Release Notes
- 5.0.0-alpha5 Release Notes
- 5.0.0-alpha4 Release Notes
- 5.0.0-alpha3 Release Notes
- 5.0.0-alpha2 Release Notes
- 5.0.0-alpha1 Release Notes
- 5.0.0-alpha1 Release Notes (Changes previously released in 2.x)
WARNING: Version 5.6 of Elasticsearch has passed its EOL date.
This documentation is no longer being maintained and may be removed. If you are running this version, we strongly advise you to upgrade. For the latest information, see the current release documentation.
Cardinality Aggregation
editCardinality Aggregation
editA single-value metrics aggregation that calculates an approximate count of
distinct values. Values can be extracted either from specific fields in the
document or generated by a script.
Assume you are indexing store sales and would like to count the unique number of sold products that match a query:
POST /sales/_search?size=0 { "aggs" : { "type_count" : { "cardinality" : { "field" : "type" } } } }
Response:
{ ... "aggregations" : { "type_count" : { "value" : 3 } } }
Precision control
editThis aggregation also supports the precision_threshold option:
The precision_threshold option is specific to the current internal implementation of the cardinality agg, which may change in the future
POST /sales/_search?size=0 { "aggs" : { "type_count" : { "cardinality" : { "field" : "type", "precision_threshold": 100 } } } }
|
The |
Counts are approximate
editComputing exact counts requires loading values into a hash set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This cardinality aggregation is based on the
HyperLogLog++
algorithm, which counts based on the hashes of the values with some interesting
properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of c, the implementation that we are using requires
about c * 8 bytes.
The following chart shows how the error varies before and after the threshold:
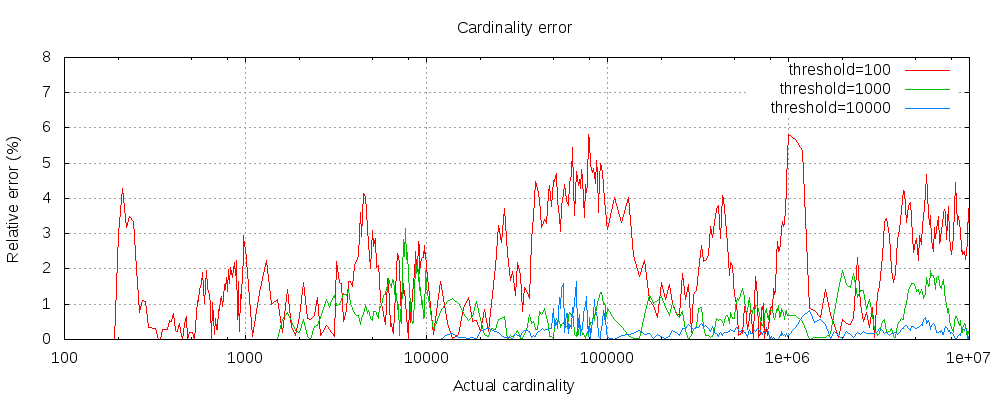
For all 3 thresholds, counts have been accurate up to the configured threshold (although not guaranteed, this is likely to be the case). Please also note that even with a threshold as low as 100, the error remains very low, even when counting millions of items.
Pre-computed hashes
editOn string fields that have a high cardinality, it might be faster to store the
hash of your field values in your index and then run the cardinality aggregation
on this field. This can either be done by providing hash values from client-side
or by letting elasticsearch compute hash values for you by using the
mapper-murmur3 plugin.
Pre-computing hashes is usually only useful on very large and/or high-cardinality fields as it saves CPU and memory. However, on numeric fields, hashing is very fast and storing the original values requires as much or less memory than storing the hashes. This is also true on low-cardinality string fields, especially given that those have an optimization in order to make sure that hashes are computed at most once per unique value per segment.
Script
editThe cardinality metric supports scripting, with a noticeable performance hit
however since hashes need to be computed on the fly.
POST /sales/_search?size=0 { "aggs" : { "type_promoted_count" : { "cardinality" : { "script": { "lang": "painless", "source": "doc['type'].value + ' ' + doc['promoted'].value" } } } } }
This will interpret the script parameter as an inline script with the painless script language and no script parameters. To use a file script use the following syntax:
POST /sales/_search?size=0 { "aggs" : { "type_promoted_count" : { "cardinality" : { "script" : { "file": "my_script", "params": { "type_field": "type", "promoted_field": "promoted" } } } } } }
for indexed scripts replace the file parameter with an id parameter.
Missing value
editThe missing parameter defines how documents that are missing a value should be treated.
By default they will be ignored but it is also possible to treat them as if they
had a value.