Set up a data stream
editSet up a data stream
editTo set up a data stream, follow these steps:
Optional: Configure an ILM lifecycle policy
editWhile optional, we recommend you configure an index lifecycle management (ILM) policy to automate the management of your data stream’s backing indices.
In Kibana, open the menu and go to Stack Management > Index Lifecycle Policies. Click Index Lifecycle Policies.
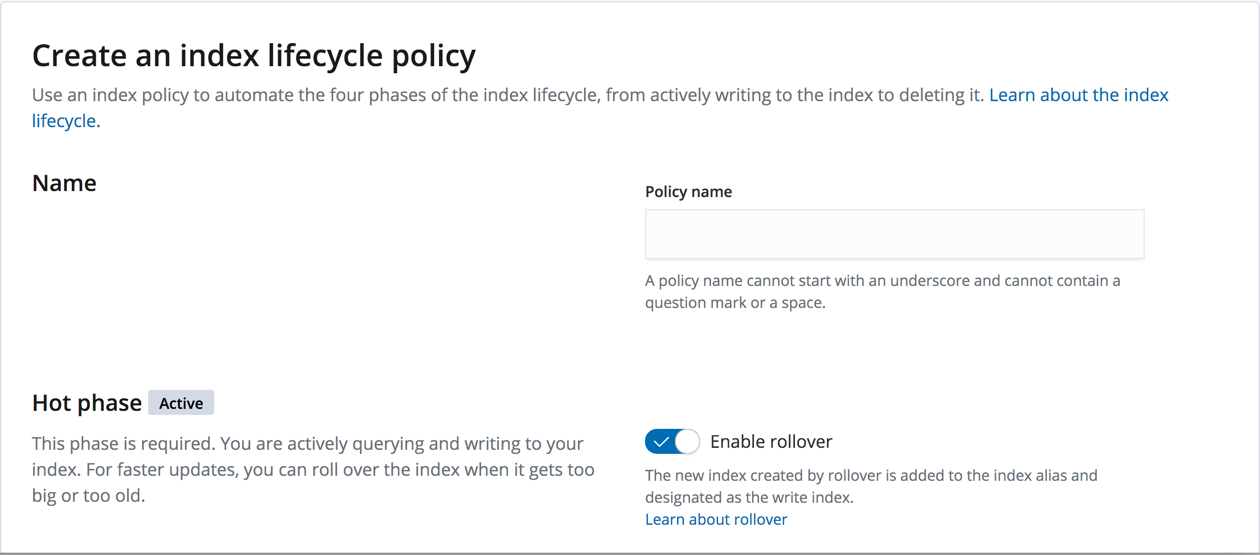
API example
Use the create lifecycle policy API to configure a policy:
PUT /_ilm/policy/my-data-stream-policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "25GB" } } }, "delete": { "min_age": "30d", "actions": { "delete": {} } } } } }
Create an index template
edit- In Kibana, open the menu and go to Stack Management > Index Management.
- In the Index Templates tab, click Create template.
- In the Create template wizard, use the Data stream toggle to indicate the template is used for data streams.
-
Use the wizard to finish defining your template. Specify:
- One or more index patterns that match the data stream’s name.
- Mappings and settings for the stream’s backing indices.
-
A priority for the index template
Elasticsearch has built-in index templates, each with a priority of
100, for the following index patterns:-
logs-*-* -
metrics-*-* -
synthetics-*-*
Elastic Agent uses these templates to create data streams. If you use the Elastic Agent, assign your index templates a priority lower than
100to avoid overriding the built-in templates.Otherwise, to avoid accidentally applying the built-in templates, do one or more of the following:-
To disable all built-in index and component templates, set
stack.templates.enabledtofalseinelasticsearch.yml. - Use a non-overlapping index pattern.
-
Assign templates with an overlapping pattern a
priorityhigher than100. For example, if you don’t use the Elastic Agent and want to create a template for thelogs-*index pattern, assign your template a priority of200. This ensures your template is applied instead of the built-in template forlogs-*-*.
-
Every document indexed to a data stream must contain a @timestamp field,
mapped as a date or date_nanos field type. If the
index template doesn’t specify a mapping for the @timestamp field, Elasticsearch maps
@timestamp as a date field with default options.
If using ILM, specify your lifecycle policy in the index.lifecycle.name
setting.
Carefully consider your template’s mappings and settings. Later changes may require reindexing. See Change mappings and settings for a data stream.

API example
Use the put index template API to create an index
template. The template must include an empty data_stream object, indicating
it’s used for data streams.
PUT /_index_template/my-data-stream-template { "index_patterns": [ "my-data-stream*" ], "data_stream": { }, "priority": 200, "template": { "settings": { "index.lifecycle.name": "my-data-stream-policy" } } }
Create the data stream
editTo automatically create the data stream, submit an indexing request to the stream. The stream’s name must match one of your template’s index patterns.
POST /my-data-stream/_doc/ { "@timestamp": "2020-12-06T11:04:05.000Z", "user": { "id": "vlb44hny" }, "message": "Login attempt failed" }
You can also use the create data stream API to manually create the data stream. The stream’s name must match one of your template’s index patterns.
PUT /_data_stream/my-data-stream
Secure the data stream
editTo control access to the data stream and its data, use Elasticsearch’s security features.
Get information about a data stream
editIn Kibana, open the menu and go to Stack Management > Index Management. In the Data Streams tab, click the data stream’s name.
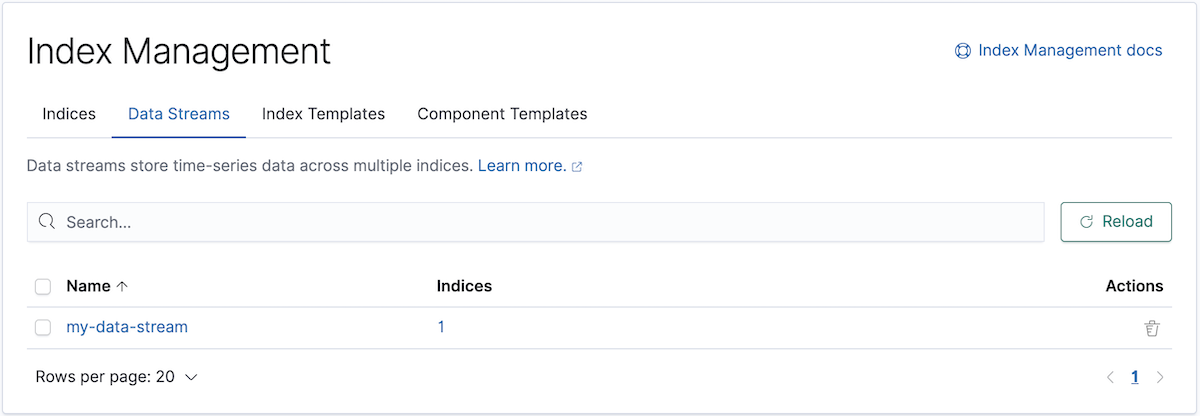
API example
Use the get data stream API to retrieve information about one or more data streams:
GET /_data_stream/my-data-stream
Delete a data stream
editTo delete a data stream and its backing indices, open the Kibana menu and go to Stack Management > Index Management. In the Data Streams tab, click the trash can icon.
API example
Use the delete data stream API to delete a data stream and its backing indices:
DELETE /_data_stream/my-data-stream