Multiple deployments writing to the same snapshot repository
editMultiple deployments writing to the same snapshot repository
editMultiple Elasticsearch deployments are writing to the same snapshot repository. Elasticsearch doesn’t support this configuration and only one cluster is allowed to write to the same repository. To remedy the situation mark the repository as read-only or remove it from all the other deployments, and re-add (recreate) the repository in the current deployment:
Fixing the corrupted repository will entail making changes in multiple deployments that write to the same snapshot repository. Only one deployment must be writing to a repository. The deployment that will keep writing to the repository will be called the "primary" deployment (the current cluster), and the other one(s) where we’ll mark the repository read-only as the "secondary" deployments.
First mark the repository as read-only on the secondary deployments:
Use Kibana
- Log in to the Elastic Cloud console.
-
On the Elasticsearch Service panel, click the name of your deployment.
If the name of your deployment is disabled your Kibana instances might be unhealthy, in which case please contact Elastic Support. If your deployment doesn’t include Kibana, all you need to do is enable it first.
-
Open your deployment’s side navigation menu (placed under the Elastic logo in the upper left corner) and go to Stack Management > Snapshot and Restore > Repositories.
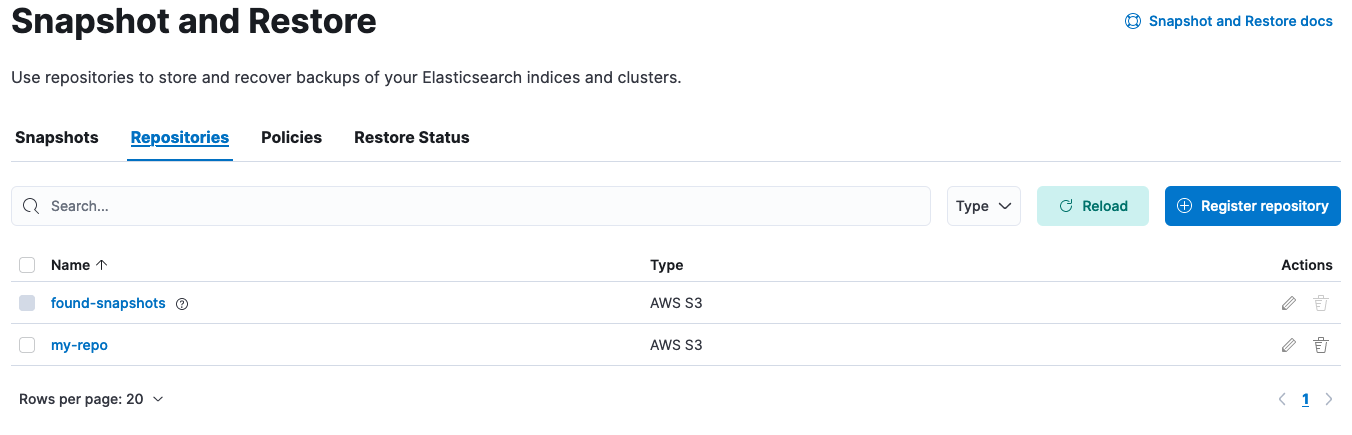
- The repositories table should now be visible. Click on the pencil icon at the right side of the repository to be marked as read-only. On the Edit page that opened scroll down and check "Read-only repository". Click "Save". Alternatively if deleting the repository altogether is preferable, select the checkbox at the left of the repository name in the repositories table and click the "Remove repository" red button at the top left of the table.
At this point, it’s only the primary (current) deployment that has the repository marked as writeable. Elasticsearch sees it as corrupt, so the repository needs to be removed and added back so that Elasticsearch can resume using it:
Note that we’re now configuring the primary (current) deployment.
-
Open the primary deployment’s side navigation menu (placed under the Elastic logo in the upper left corner) and go to Stack Management > Snapshot and Restore > Repositories.
-
Get the details for the repository we’ll recreate later by clicking on the repository name in the repositories table and making note of all the repository configurations that are displayed on the repository details page (we’ll use them when we recreate the repository). Close the details page using the link at the bottom left of the page.
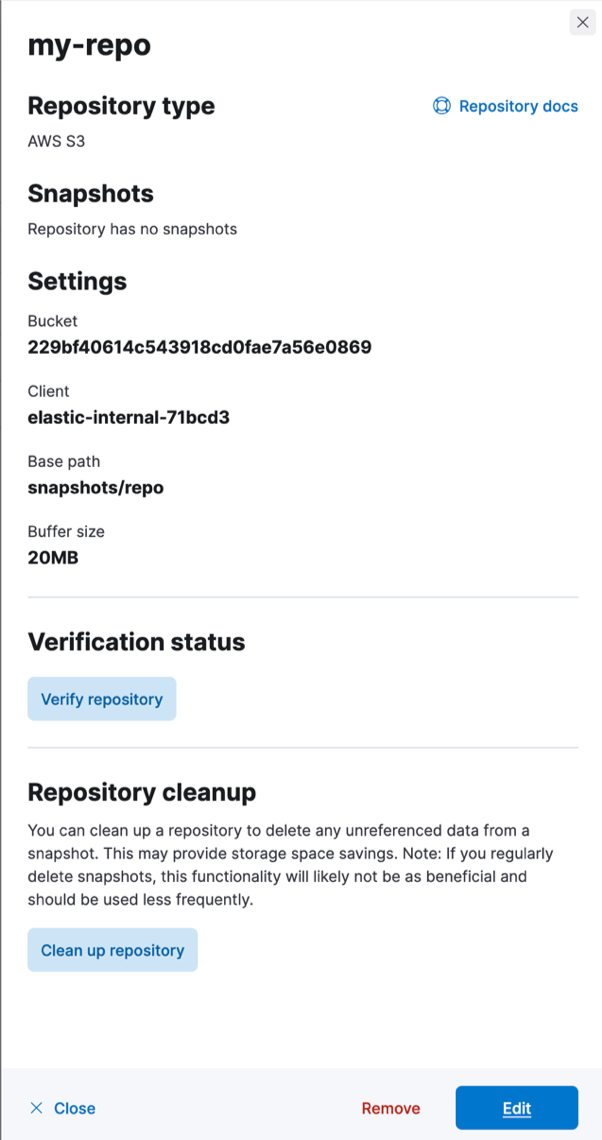
- With all the details above noted, next delete the repository. Select the checkbox at the left of the repository and hit the "Remove repository" red button at the top left of the page.
-
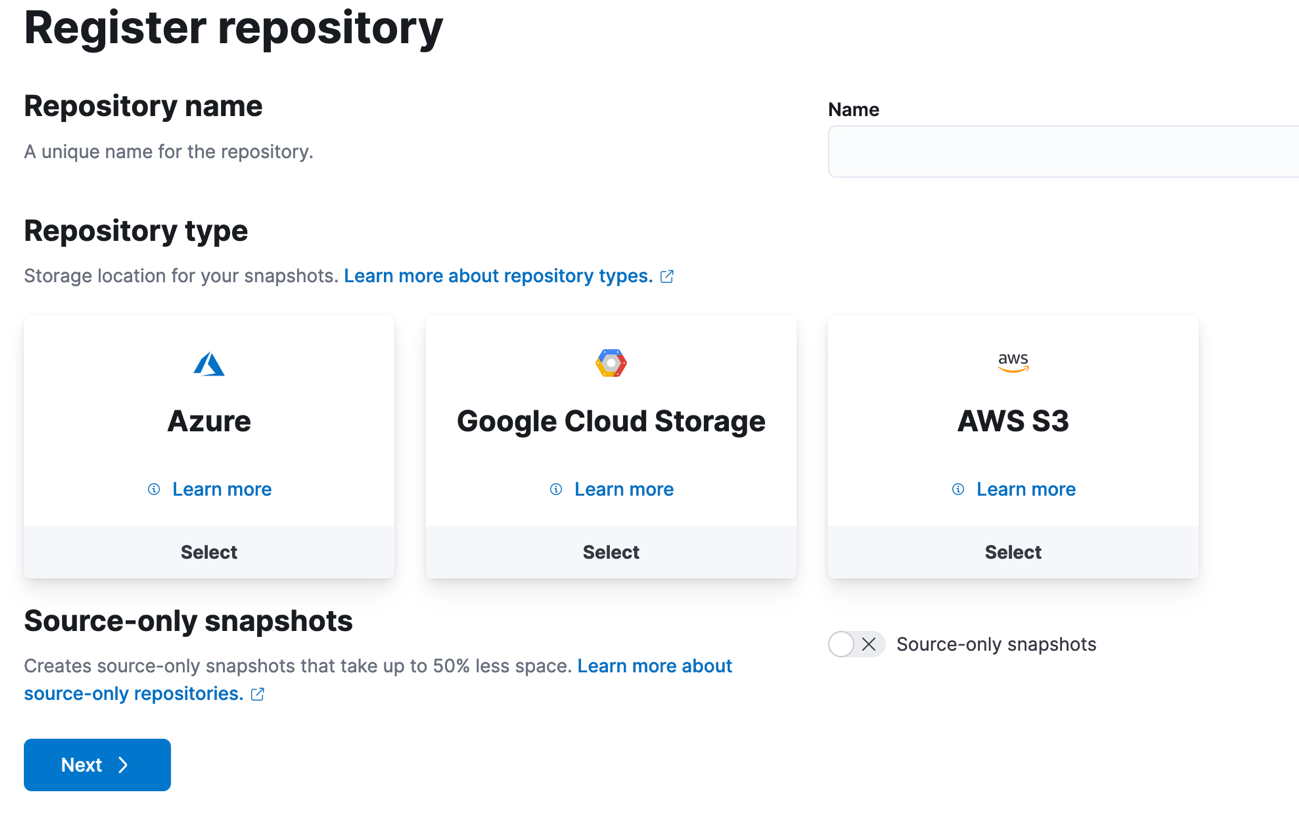
Recreate the repository by clicking the "Register Repository" button at the top right corner of the repositories table.
-
Fill in the repository name, select the type and click "Next".
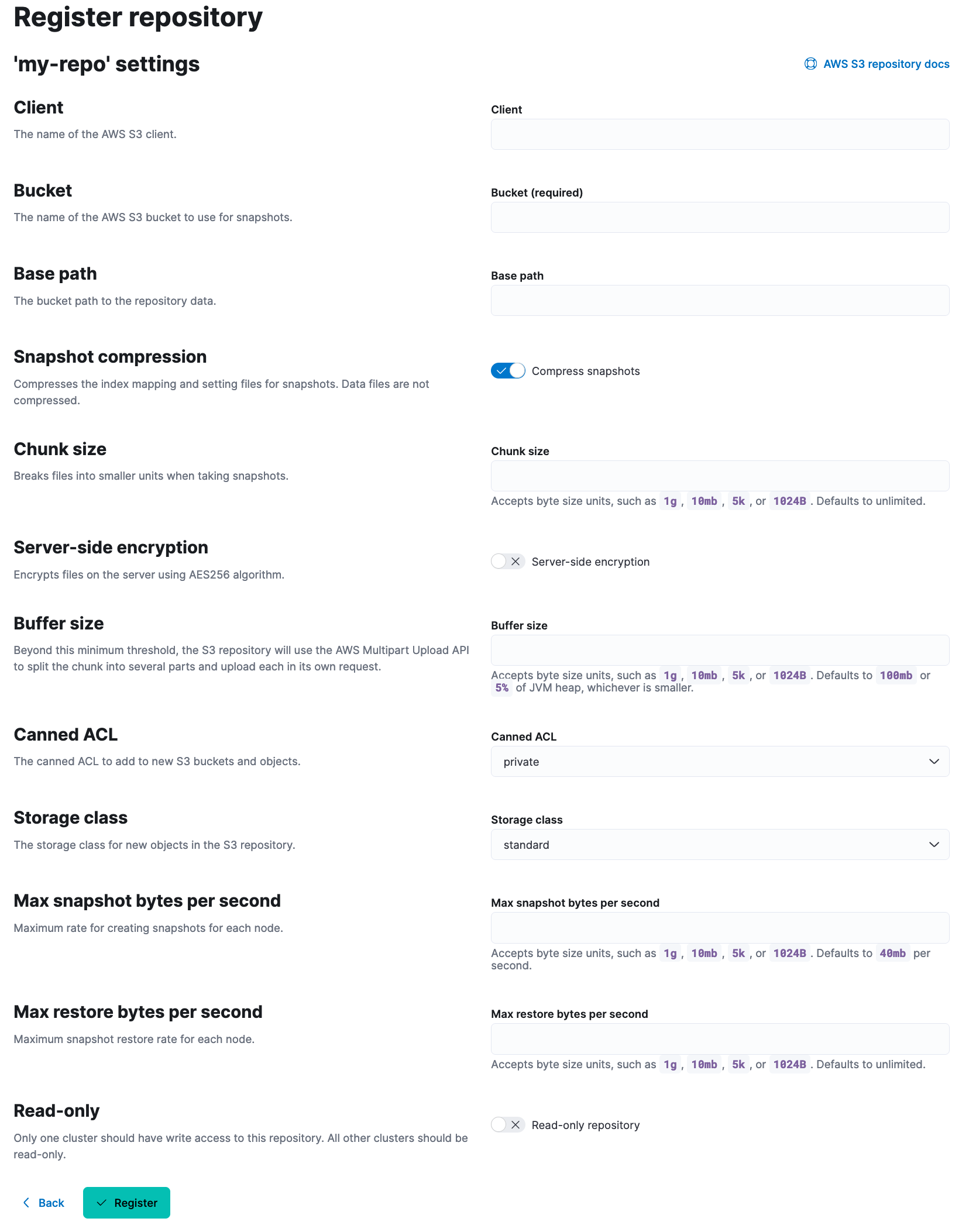
- Fill in the repository details (client, bucket, base path etc) with the values you noted down before deleting the repository and click the "Register" button at the bottom.
- Select "Verify repository" to confirm that your settings are correct and the deployment can connect to your repository.
Fixing the corrupted repository will entail making changes in multiple clusters that write to the same snapshot repository. Only one cluster must be writing to a repository. Let’s call the cluster we want to keep writing to the repository the "primary" cluster (the current cluster), and the other one(s) where we’ll mark the repository as read-only the "secondary" clusters.
Let’s first work on the secondary clusters:
-
Get the configuration of the repository:
GET _snapshot/my-repo
The reponse will look like this:
-
Using the settings retrieved above, add the
readonly: trueoption to mark it as read-only: -
Alternatively, deleting the repository is an option using:
DELETE _snapshot/my-repo
The response will look like this:
{ "acknowledged": true }
At this point, it’s only the primary (current) cluster that has the repository marked as writeable. Elasticsearch sees it as corrupt though so let’s remove the repository and recreate it so that Elasticsearch can resume using it:
Note that now we’re configuring the primary (current) cluster.
-
Get the configuration of the repository and save its configuration as we’ll use it to recreate the repository:
GET _snapshot/my-repo
-
Delete the repository:
DELETE _snapshot/my-repo
The response will look like this:
{ "acknowledged": true } -
Using the configuration we obtained above, let’s recreate the repository:
PUT _snapshot/my-repo { "type": "s3", "settings": { "bucket": "repo-bucket", "client": "elastic-internal-71bcd3", "base_path": "myrepo" } }The response will look like this:
{ "acknowledged": true }