Data tiers
editData tiers
editA data tier is a collection of nodes within a cluster that share the same data node role, and a hardware profile that’s appropriately sized for the role. Elastic recommends that nodes in the same tier share the same hardware profile to avoid hot spotting.
The data tiers that you use, and the way that you use them, depends on the data’s category.
The following data tiers are can be used with each data category:
Content data:
- Content tier nodes handle the indexing and query load for non-timeseries indices, such as a product catalog.
Time series data:
- Hot tier nodes handle the indexing load for time series data, such as logs or metrics. They hold your most recent, most-frequently-accessed data.
- Warm tier nodes hold time series data that is accessed less-frequently and rarely needs to be updated.
- Cold tier nodes hold time series data that is accessed infrequently and not normally updated. To save space, you can keep fully mounted indices of searchable snapshots on the cold tier. These fully mounted indices eliminate the need for replicas, reducing required disk space by approximately 50% compared to the regular indices.
- Frozen tier nodes hold time series data that is accessed rarely and never updated. The frozen tier stores partially mounted indices of searchable snapshots exclusively. This extends the storage capacity even further — by up to 20 times compared to the warm tier.
The performance of an Elasticsearch node is often limited by the performance of the underlying storage and hardware profile. For example hardware profiles, refer to Elastic Cloud’s instance configurations. Review our recommendations for optimizing your storage for indexing and search.
Elasticsearch generally expects nodes within a data tier to share the same hardware profile. Variations not following this recommendation should be carefully architected to avoid hot spotting.
The way data tiers are used often depends on the data’s category:
- Content data remains on the content tier for its entire data lifecycle.
-
Time series data may progress through the descending temperature data tiers (hot, warm, cold, and frozen) according to your performance, resiliency, and data retention requirements.
You can automate these lifecycle transitions using the data stream lifecycle, or custom index lifecycle management.
Available data tiers
editLearn more about each data tier, including when and how it should be used.
Content tier
editData stored in the content tier is generally a collection of items such as a product catalog or article archive. Unlike time series data, the value of the content remains relatively constant over time, so it doesn’t make sense to move it to a tier with different performance characteristics as it ages. Content data typically has long data retention requirements, and you want to be able to retrieve items quickly regardless of how old they are.
Content tier nodes are usually optimized for query performance—they prioritize processing power over IO throughput so they can process complex searches and aggregations and return results quickly. While they are also responsible for indexing, content data is generally not ingested at as high a rate as time series data such as logs and metrics. From a resiliency perspective the indices in this tier should be configured to use one or more replicas.
The content tier is required and is often deployed within the same node grouping as the hot tier. System indices and other indices that aren’t part of a data stream are automatically allocated to the content tier.
Hot tier
editThe hot tier is the Elasticsearch entry point for time series data and holds your most-recent, most-frequently-searched time series data. Nodes in the hot tier need to be fast for both reads and writes, which requires more hardware resources and faster storage (SSDs). For resiliency, indices in the hot tier should be configured to use one or more replicas.
The hot tier is required. New indices that are part of a data stream are automatically allocated to the hot tier.
Warm tier
editTime series data can move to the warm tier once it is being queried less frequently than the recently-indexed data in the hot tier. The warm tier typically holds data from recent weeks. Updates are still allowed, but likely infrequent. Nodes in the warm tier generally don’t need to be as fast as those in the hot tier. For resiliency, indices in the warm tier should be configured to use one or more replicas.
Cold tier
editWhen you no longer need to search time series data regularly, it can move from the warm tier to the cold tier. While still searchable, this tier is typically optimized for lower storage costs rather than search speed.
For better storage savings, you can keep fully mounted indices of searchable snapshots on the cold tier. Unlike regular indices, these fully mounted indices don’t require replicas for reliability. In the event of a failure, they can recover data from the underlying snapshot instead. This potentially halves the local storage needed for the data. A snapshot repository is required to use fully mounted indices in the cold tier. Fully mounted indices are read-only.
Alternatively, you can use the cold tier to store regular indices with replicas instead of using searchable snapshots. This lets you store older data on less expensive hardware but doesn’t reduce required disk space compared to the warm tier.
Frozen tier
editOnce data is no longer being queried, or being queried rarely, it may move from the cold tier to the frozen tier where it stays for the rest of its life.
The frozen tier requires a snapshot repository. The frozen tier uses partially mounted indices to store and load data from a snapshot repository. This reduces local storage and operating costs while still letting you search frozen data. Because Elasticsearch must sometimes fetch frozen data from the snapshot repository, searches on the frozen tier are typically slower than on the cold tier.
Configure data tiers
editFollow the instructions for your deployment type to configure data tiers.
Elasticsearch Service or Elastic Cloud Enterprise
editThe default configuration for an Elastic Cloud deployment includes a shared tier for hot and content data. This tier is required and can’t be removed.
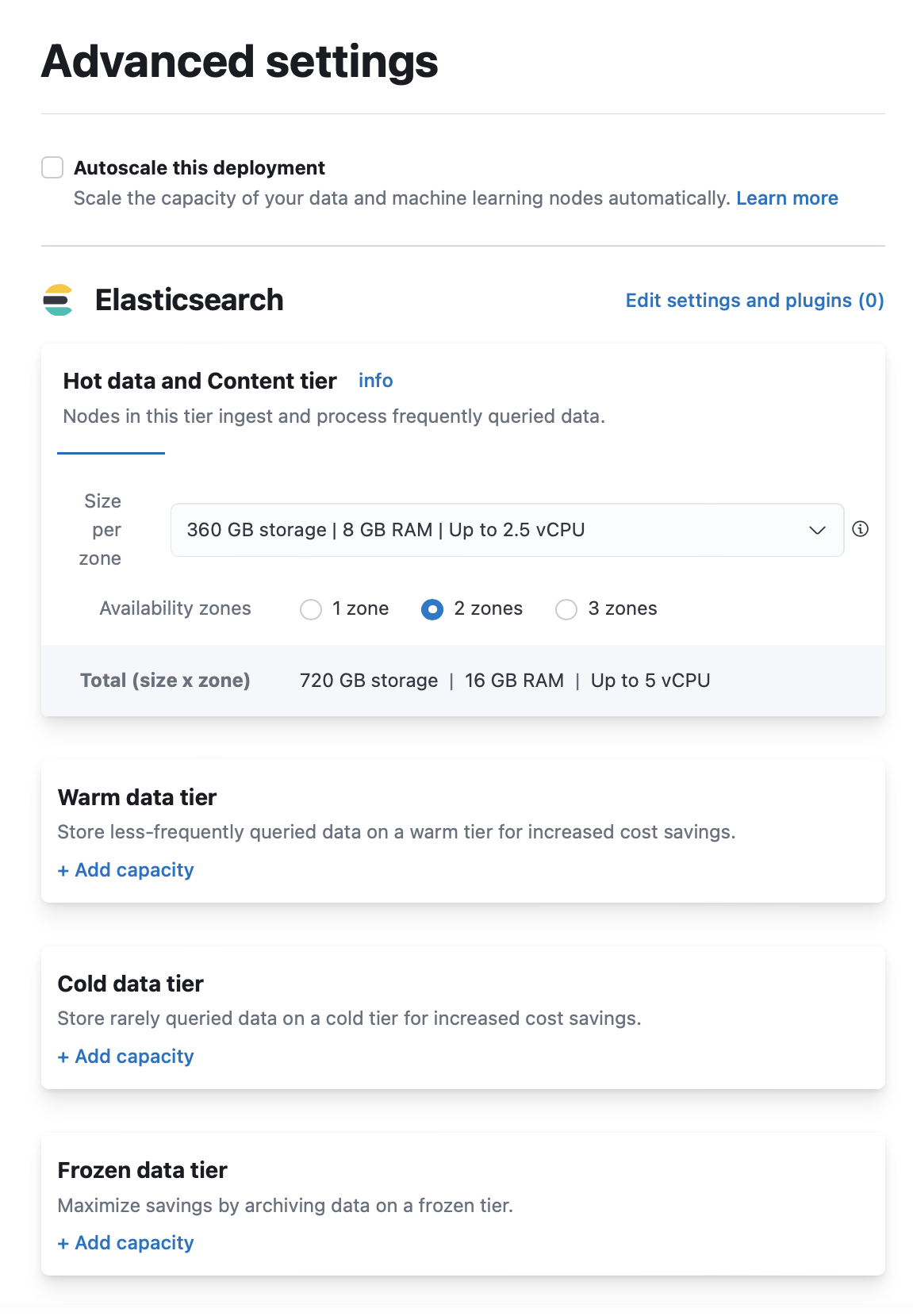
To add a warm, cold, or frozen tier when you create a deployment:
- On the Create deployment page, click Advanced Settings.
- Click + Add capacity for any data tiers to add.
- Click Create deployment at the bottom of the page to save your changes.
To add a data tier to an existing deployment:
- Log in to the Elastic Cloud console.
- On the Deployments page, select your deployment.
- In your deployment menu, select Edit.
- Click + Add capacity for any data tiers to add.
- Click Save at the bottom of the page to save your changes.
To remove a data tier, refer to Disable a data tier.
Self-managed deployments
editFor self-managed deployments, each node’s data role is configured
in elasticsearch.yml. For example, the highest-performance nodes in a cluster
might be assigned to both the hot and content tiers:
node.roles: ["data_hot", "data_content"]
We recommend you use dedicated nodes in the frozen tier.
Data tier index allocation
editThe index.routing.allocation.include._tier_preference setting determines which tier the index should be allocated to.
When you create an index, by default Elasticsearch sets the _tier_preference
to data_content to automatically allocate the index shards to the content tier.
When Elasticsearch creates an index as part of a data stream,
by default Elasticsearch sets the _tier_preference
to data_hot to automatically allocate the index shards to the hot tier.
At the time of index creation, you can override the default setting by explicitly setting the preferred value in one of two ways:
- Using an index template. Refer to Automate rollover with ILM for details.
- Within the create index request body.
You can override this setting after index creation by updating the index setting to the preferred value.
This setting also accepts multiple tiers in order of preference. This prevents indices from remaining unallocated if no nodes are available in the preferred tier. For example, when index lifecycle management migrates an index to the cold phase, it sets the index _tier_preference to data_cold,data_warm,data_hot.
To remove the data tier preference
setting, set the _tier_preference value to null. This allows the index to allocate to any data node within the cluster. Setting the _tier_preference to null does not restore the default value. Note that, in the case of managed indices, a migrate action might apply a new value in its place.
Determine the current data tier preference
editYou can check an existing index’s data tier preference by polling its
settings for index.routing.allocation.include._tier_preference:
resp = client.indices.get_settings(
index="my-index-000001",
filter_path="*.settings.index.routing.allocation.include._tier_preference",
)
print(resp)
const response = await client.indices.getSettings({
index: "my-index-000001",
filter_path: "*.settings.index.routing.allocation.include._tier_preference",
});
console.log(response);
GET /my-index-000001/_settings?filter_path=*.settings.index.routing.allocation.include._tier_preference
Troubleshooting
editThe _tier_preference setting might conflict with other allocation settings. This conflict might prevent the shard from allocating. A conflict might occur when a cluster has not yet been completely migrated
to data tiers.
This setting will not unallocate a currently allocated shard, but might prevent it from migrating from its current location to its designated data tier. To troubleshoot, call the cluster allocation explain API and specify the suspected problematic shard.
Automatic data tier migration
editILM automatically transitions managed
indices through the available data tiers using the migrate action.
By default, this action is automatically injected in every phase.
You can explicitly specify the migrate action with "enabled": false to disable automatic migration,
for example, if you’re using the allocate action to manually
specify allocation rules.