Web crawler content extraction rules
editWeb crawler content extraction rules
editExtraction rules enable you to customize how the crawler extracts content from webpages.
Extraction rules are designed to make data extraction more flexible. Add your own rules to supplement standard content extraction like HTML body or title content. For example, you might want to build a search experience based on specific information presented on your website.
To add new extraction rules or modify existing rules, go to the Manage domains tab in Kibana. Find this under Search > Content > Elasticsearch indices > <search-my-crawler-index>. Next, find the Extraction rules tab for your domain.
URL filters
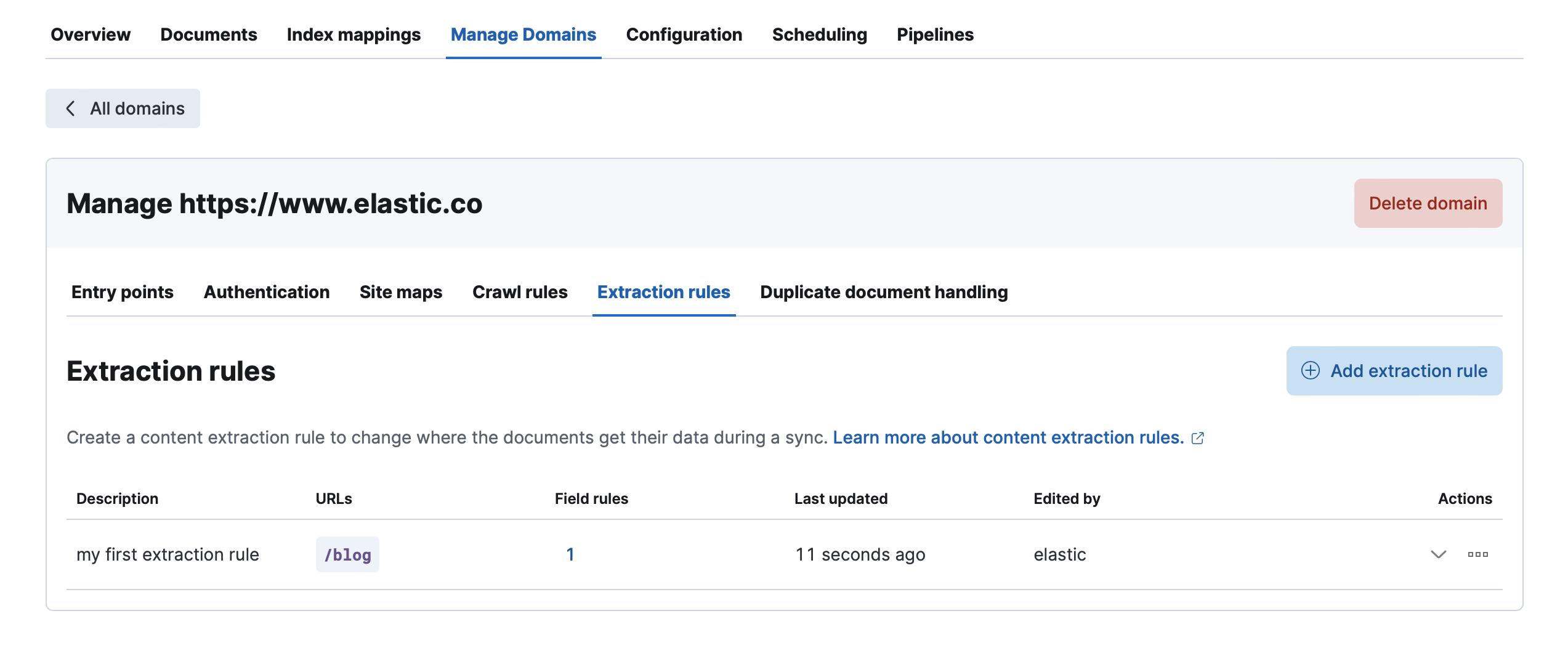
editURL filters enable you to target certain pages or URLs to extract content from. For example, imagine only a subset of HTML pages contain content version and author information. You can create a URL filter that matches only those pages.
URL filters work exactly the same way as crawl rules. Refer to crawl rules for more information.
In the example below, the extraction rules will be applied only on the pages whose URLs start with /blog or contain 2022.
Content fields
editUse content fields to pinpoint which parts of a webpage to pull data from. Each extraction rule can have multiple content fields with different configurations. To create a new content field you need to specify several required options:
-
Field name: The web crawler stores extracted content in Elasticsearch documents under this name.
Be aware that all specified content fields will irretrievably change the Elasticsearch index. You can only add new fields, but you can’t rename or delete them.
You can’t use certain reserved field names:
body_content,domains,headings,meta_description,title,url,url_host,url_path,url_path_dir1,url_path_dir2,url_path_dir3,url_port,url_scheme. Refer to ingest pipelines for Search indices for more information about the reserved fields used by Ingest pipelines. -
Source: The crawler can use either raw HTML or URL as a content source.
For both source types you should define
selector: CSS selector or regular expression accordingly. -
Content: Use
Extracted valueif you definedSource. UseA fixed valueto specify a fixed value (string) to inject if the field is found in the source. This will override the extracted content with your fixed value.Extracted data can be stored as
stringor asarray. You can select one of the options when you create an extraction rule. Refer to Storing different kinds of content for more information.
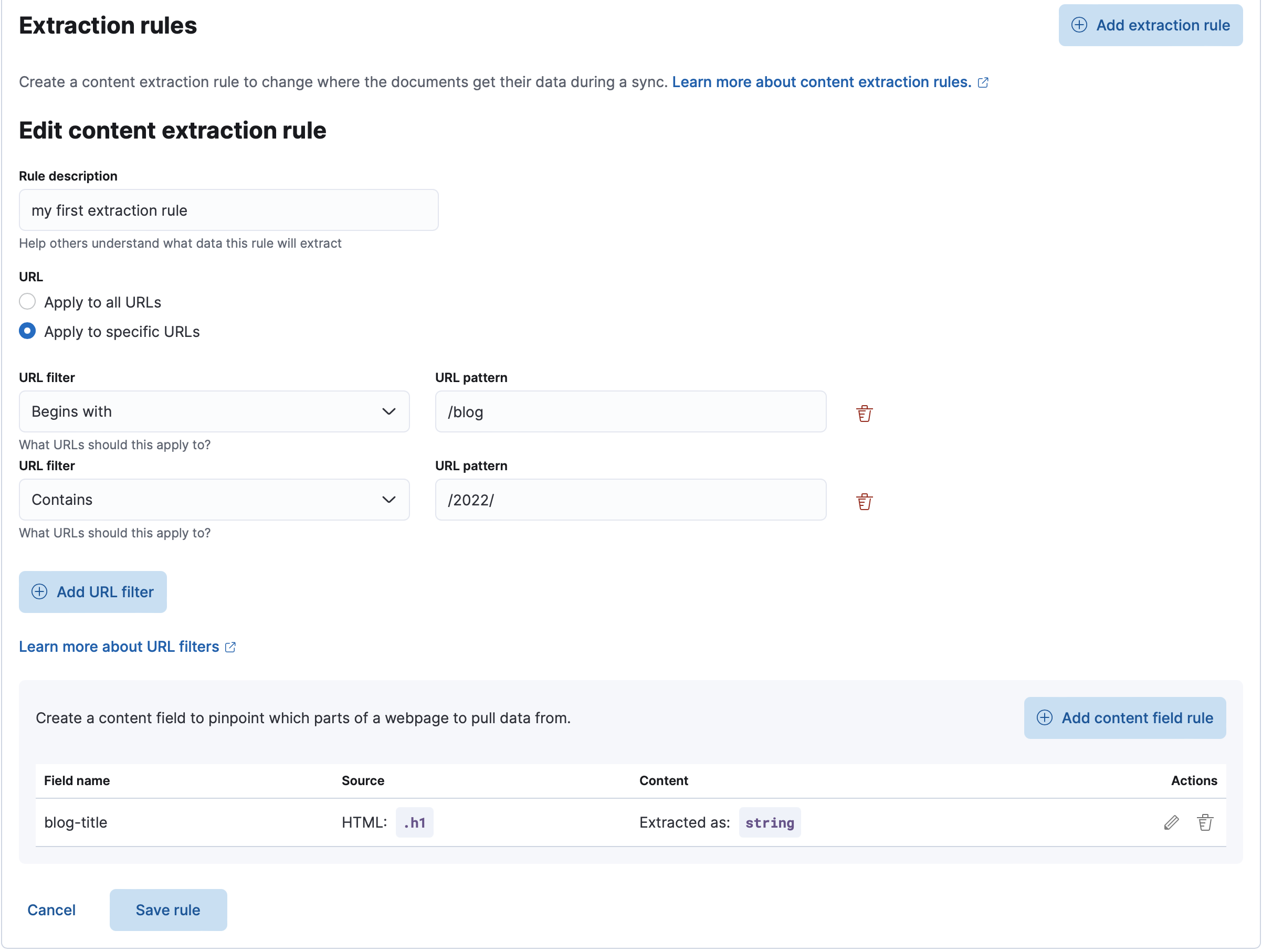
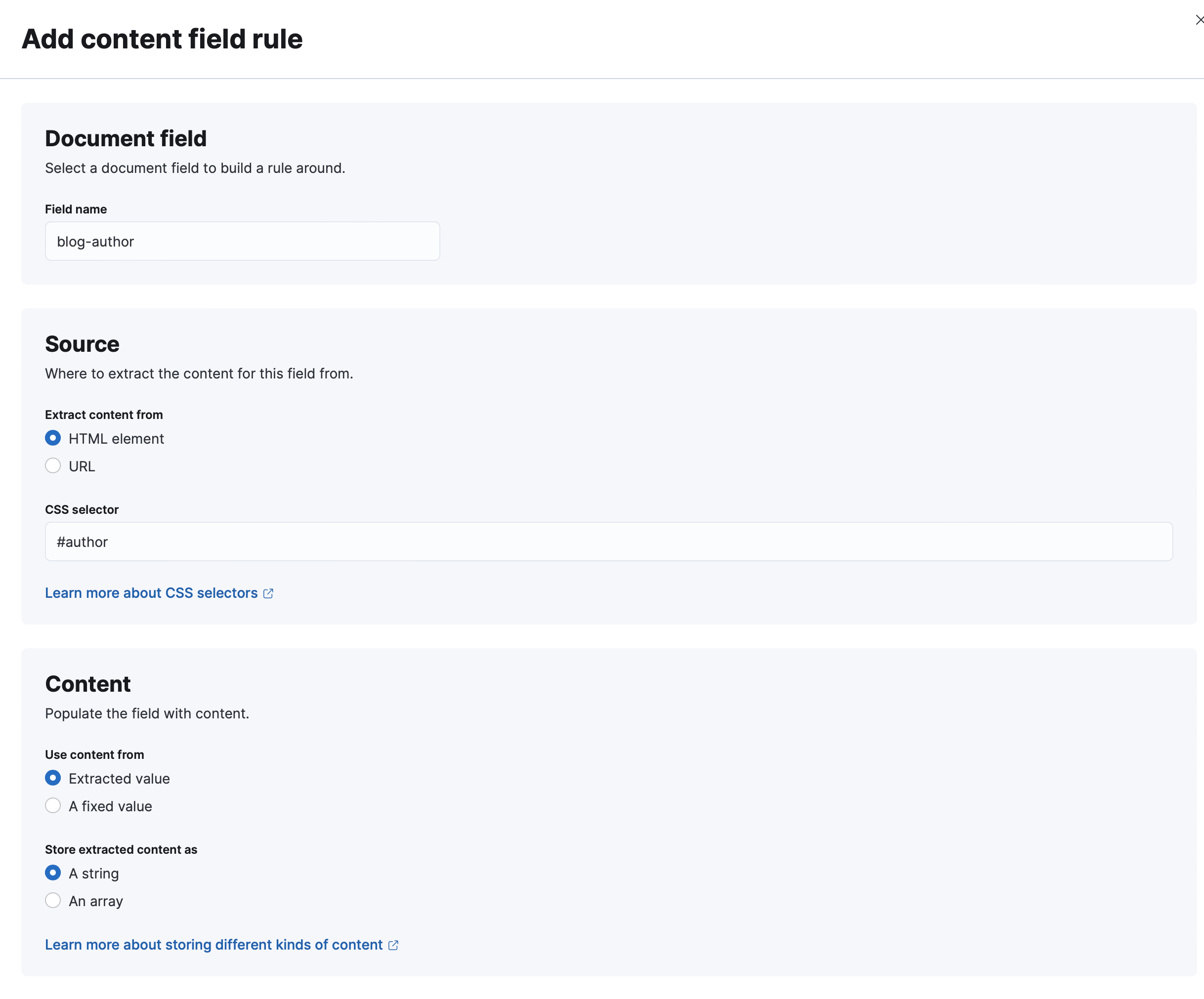
In the screenshot below, we are adding a new field that will be extracted from the HTML pages using the CSS selector #author.
The extracted value will be stored as a string under blog-author.
CSS selectors
editWhen CSS selector is chosen the web crawler will try to apply this during HTML parsing and store the extracted value in an Elasticsearch document. When the web crawler applies selectors, it also strips all HTML tags and returns only inner text. If the selector returns multiple values, the web crawler will either concatenate all the values into a single string, or store it as array of values. See Storing different kinds of content
Extraction rules support CSS Level 3. For more information refer to the official W3C documentation.
XPath selectors
editYou can also use XPath selectors to extract HTML attributes.
In the following example, the Xpath selector extracts the HTML title attribute:
| XPath selector | HTML |
|---|---|
|
|
URL patterns
editTo extract content from URLs you need to use Regex as a selector.
We recommend using capturing groups to explicitly indicate which part of the regular expression needs to stored as a content field.
Here are some examples:
| String | Regex | Match result | Match group (final result) |
|---|---|---|---|
|
|
|
|
|
|
|
|
Storing different kinds of content
editExtracted values can be stored in Elasticseach as a string or an array.
This is useful if your CSS selector or Regex returns multiple values.
If string is selected then the web crawler will combine all the values into a string.
Otherwise all the values will be stored as array items.
If you want to convert the extracted value into a different data type you can use Convert processor
Learn more about Ingest pipelines