Elastic MongoDB connector reference
editElastic MongoDB connector reference
editThe Elastic MongoDB connector is a connector for MongoDB data sources.
Availability and prerequisites
editThis connector is available as a native connector in Elastic versions 8.5.0 and later. To use this connector as a native connector, satisfy all native connector requirements.
This connector is also available as a connector client from the Ruby connectors framework. To use this connector as a connector client, satisfy all connector client requirements.
This connector has no additional prerequisites beyond the shared requirements, linked above.
This connector is available in technical preview. Features in technical preview are subject to change and are not covered by the service level agreement (SLA) of features that have reached general availability (GA).
Usage
editTo use this connector as a native connector, use the use a connector workflow. See Native connectors.
To use this connector as a connector client, use the build a connector workflow. See Connector clients and frameworks.
For additional operations, see Usage.
Example
editAn example is available for this connector. See MongoDB connector tutorial.
Known issues
editExpressions and variables in aggregation pipelines
editIt’s not possible to use expressions like new Date() inside an aggregation pipeline.
These expressions won’t be evaluated by the underlying MongoDB client, but will be passed as a string to the MongoDB instance.
A possible workaround is to use aggregation variables.
Incorrect (new Date() will be interpreted as string):
{
"aggregate": {
"pipeline": [
{
"$match": {
"expiresAt": {
"$gte": "new Date()"
}
}
}
]
}
}
Correct (usage of $$NOW):
{
"aggregate": {
"pipeline": [
{
"$addFields": {
"current_date": {
"$toDate": "$$NOW"
}
}
},
{
"$match": {
"$expr": {
"$gte": [
"$expiresAt",
"$current_date"
]
}
}
}
]
}
}
See Known issues for any issues affecting all connectors.
Troubleshooting
editSee Troubleshooting.
Security
editSee Security.
Compatibility
editThis connector is compatible with MongoDB Atlas and MongoDB 3.6 and later.
The data source and your Elastic deployment must be able to communicate with each other over a network.
Configuration
editEach time you create an index to be managed by this connector, you will create a new connector configuration. You will need some or all of the following information about the data source.
- Host
-
The URI of the MongoDB host. Examples:
-
mongodb+srv://my_username:my_password@cluster0.mongodb.net/mydb?w=majority -
mongodb://127.0.0.1:27017
-
- Direct connection (true/false)
-
Whether to use the direct connection option for the MongoDB client. Examples.
-
true -
false
-
- Username
-
The MongoDB username the connector will use.
The user must have access to the configured database and collection. You may want to create a dedicated, read-only user for each connector.
- Password
- The MongoDB password the connector will use.
- Database
- The MongoDB database to sync. The database must be accessible using the configured username and password.
- Collection
- The MongoDB collection to sync. The collection must exist within the configured database. The collection must be accessible using the configured username and password.
Documents and syncs
editThe following describes the default syncing behavior for this connector. Use sync rules and ingest pipelines to customize syncing for specific indices.
All documents in the configured MongoDB database and collection are extracted and transformed into documents in your Elasticsearch index.
- The connector creates one Elasticsearch document for each MongoDB document in the configured database and collection.
- For each document, the connector transforms each MongoDB field into an Elasticsearch field.
- For each field, Elasticsearch dynamically determines the data type.
This results in Elasticsearch documents that closely match the original MongoDB documents.
The Elasticsearch mapping is created when the first document is created.
Each sync is a "full" sync. For each MongoDB document discovered:
- If it does not exist, the document is created in Elasticsearch.
- If it already exists in Elasticsearch, the Elasticsearch document is replaced and the version is incremented.
- If an existing Elasticsearch document no longer exists in the MongoDB collection, it is deleted from Elasticsearch.
-
Embedded documents are stored as an
objectfield in the parent document.
This is recursive, because embedded documents can themselves contain embedded documents.
Sync rules
editThe following sections describe Sync rules for this connector.
Basic rules
editA single basic rule translates quite cleanly to a mongodb find query.
For example, a single rule like:
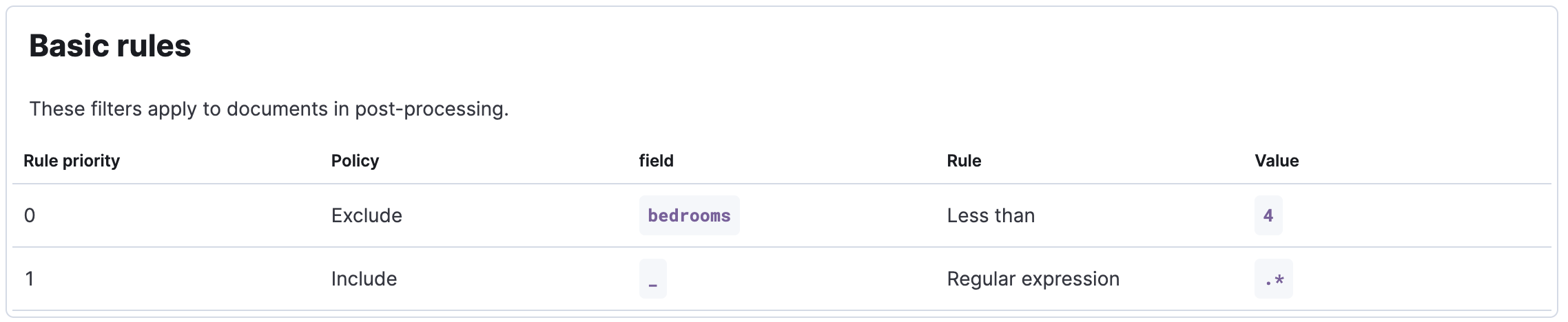
Will translate to a mongodb find query of:
{
"bedrooms" : {
"$gte" : 4.0
}
}
The connector makes a best effort to convert the "value" of the rule to the appropriate type.
For example, true would be coerced into a boolean, and 1234 would be coerced into an integer.
This may cause issues for fields that have mixed types, or unconventional representations.
Multiple basic sync rules are combined with an AND clause, and are executed in a find query.
So for example, if we have the following rules:
-
INCLUDEstateequalsMA -
EXCLUDEIDgreater than1000
This would result in a following mongodb find query:
{
"$and":[
{"state": "MA"},
{"ID": {"$lte": 1000}}
]
}
This differs from how basic sync rules are applied in integration filtering.
In that case, a document is evaluated one rule at a time, in order, for a match, and the specified policy is applied.
This is not possible to mimic in remote filtering, as MongoDB does not offer ordered query-and-break criteria in the find operation.
The more clauses that are added, the more complex the query becomes. We recommend using advanced rules when there are more than a few clauses. This helps make the query more efficient and gives you full control over it.
Advanced rules
editAdvanced rules for MongoDB can be used to express either find queries or aggregation pipelines.
They can also be used to tune options available when issuing these queries/pipelines.
find queries
editFor find queries, the structure of this JSON DSL should look like:
{
"find":{
"filter": {
// find query goes here
},
"options":{
// query options go here
}
}
}
For example:
{
"find":{
"filter": {
"$text": {
"$search" : "garden",
"$caseSensitive" : false
}
},
"options":{
"skip" : 10,
"limit" : 1000
}
}
}
Where the available options are:
-
allowDiskUse(true, false) — When set to true, the server can write temporary data to disk while executing the find operation. This option is only available on MongoDB server versions 4.4 and newer. -
allowPartialResults(true, false) — Allows the query to get partial results if some shards are down. -
batchSize(Integer) — The number of documents returned in each batch of results from MongoDB. -
collation(Object) — The collation to use. -
comment(string) — A user-provided comment to attach to this command. -
cursorType(tailable,tailable_await) — The type of cursor to use. -
limit(Integer) — The max number of docs to return from the query. -
maxTimeMs(Integer) — The maximum amount of time to allow the query to run, in milliseconds. -
modifiers(Object) — A document containing meta-operators modifying the output or behavior of a query. -
noCursorTimeout(true, false) — The server normally times out idle cursors after an inactivity period (10 minutes) to prevent excess memory use. Set this option to prevent that. -
oplogReplay(true, false) — For internal replication use only, applications should not set this option. -
projection(Object) — The fields to include or exclude from each doc in the result set. -
skip(Integer) — The number of docs to skip before returning results. -
sort(Object) — The key and direction pairs by which the result set will be sorted. -
let(Object) — Mapping of variables to use in the command. See the server documentation for details.
Aggregation pipelines
editSimilarly, for aggregation pipelines, the structure of the JSON DSL should look like:
{
"aggregate":{
"pipeline": [
// pipeline elements go here
],
"options": {
// pipeline options go here
}
}
}
Where the available options are:
-
allowDiskUse(true, false) — Set to true if disk usage is allowed during the aggregation. -
batchSize(Integer) — The number of documents to return per batch. -
bypassDocumentValidation(true, false) — Whether or not to skip document level validation. -
collation(Object) — The collation to use. -
comment(String) — A user-provided comment to attach to this command. -
hint(String) — The index to use for the aggregation. -
let(Object) — Mapping of variables to use in the pipeline. See the server documentation for details. -
maxTimeMs(Integer) — The maximum amount of time in milliseconds to allow the aggregation to run.
Framework and source
editThis connector is included in the Ruby connectors framework.
View the source code for this connector (branch 8.6, compatible with Elastic 8.6).